
Sự bùng nổ của các mô hình thị giác DeepSeek đang tái định nghĩa cách chúng ta xây dựng các hệ thống AI đa phương thức nhờ hiệu suất vượt trội và khả năng tùy biến linh hoạt. Từ việc hiểu tài liệu phức tạp đến nhận diện đối tượng chính xác, DeepSeek mang đến những giải pháp đột phá cho lĩnh vực thị giác máy tính hiện đại. Để khám phá trọn bộ sức mạnh và cách triển khai hiệu quả dòng mô hình này, hãy cùng TOT tìm hiểu chi tiết qua bài viết sau đây.
>>> Tham khảo thêm:
- Các công cụ thị giác máy tính không cần code hàng đầu
- Inference In Computer Vision: Suy luận trong thị giác máy tính là gì?
- Các mô hình ngôn ngữ thị giác chạy cục bộ tốt nhất
Mở đầu
AI trọng số mã nguồn mở (Open-weight AI) đã thay đổi cách các nhà phát triển xây dựng các hệ thống Trí tuệ nhân tạo. Trước đây, việc sử dụng một mô hình nền tảng (Foundation Model) có năng lực mạnh mẽ thường đồng nghĩa với việc phải phụ thuộc vào quyền truy cập API trả phí và làm việc với một hệ thống đóng.
Giờ đây, các nhà phát triển đã có thể tải xuống trọng số mô hình, kiểm tra kiến trúc, chạy suy luận trên phần cứng của riêng họ và tinh chỉnh mô hình trên dữ liệu cá nhân.
DeepSeek đã đóng vai trò quan trọng trong sự chuyển dịch này bằng cách phát hành một loạt các mô hình nền tảng được xây dựng với kiến trúc Hỗn hợp chuyên gia (Mixture-of-Experts – MoE), học tăng cường và các phương pháp huấn luyện hiệu quả.
Bài viết này tập trung vào các khả năng thị giác của các mô hình DeepSeek. Chúng bao gồm các mô hình có khả năng hiểu hình ảnh, đọc tài liệu, thực hiện nhận dạng ký tự quang học (OCR), trả lời câu hỏi thị giác, xác định vị trí đối tượng và tạo hình ảnh.
Chúng ta sẽ đi qua các mô hình thị giác và mô hình đa phương thức chính của DeepSeek, giải thích mục đích thiết kế của từng mô hình và trình bày cách chúng có thể được sử dụng trong các quy trình thị giác thực tế thông qua thư viện Roboflow Supervision.
>> Xem thêm:
- API Testing là gì? Thông tin chi tiết về kiểm thử API cho người mới
- Phân tích hình ảnh bằng AI: Cách hoạt động & ứng dụng thực tế
DeepSeek là gì?
DeepSeek là một công ty nghiên cứu AI đến từ Trung Quốc bắt đầu hoạt động từ năm 2023. Công ty này đã trở nên nổi tiếng rộng rãi nhờ việc phát hành các mô hình nền tảng trọng số mở mạnh mẽ với hiệu năng cao và cách huấn luyện hiệu quả.
Một lý do chính khiến các nhà phát triển chú ý đến DeepSeek là các mô hình của họ được phát hành công khai, vì vậy mọi người có thể nghiên cứu kiến trúc, tải xuống trọng số, chạy suy luận cục bộ và tinh chỉnh chúng cho các trường hợp sử dụng riêng.
DeepSeek hoạt động trên ba lĩnh vực chính, gồm:
- Mô hình ngôn ngữ chung (general language models)
- Mô hình suy luận (reasoning models)
- Mô hình ngôn ngữ thị giác (vision language models)
Theo thời gian, họ đã phát hành các mô hình cho trò chuyện, lập trình, suy luận ngữ cảnh dài, hiểu đa phương thức, OCR, phân tích tài liệu, xác định vị trí thị giác (phrase grounding) và tạo hình ảnh.
Trong đó, hệ sinh thái mô hình DeepSeek bao gồm các bản phát hành quan trọng như: DeepSeek-LLM, DeepSeek Coder, DeepSeek-V2, DeepSeek-V3, DeepSeek-R1, DeepSeek-VL, DeepSeek-VL2 và dòng Janus.
Các mô hình thị giác DeepSeek
DeepSeek đã phát hành nhiều dòng mô hình có khả năng thị giác riêng biệt kể từ năm 2024, mỗi dòng được thiết kế cho một mục đích khác nhau. Cụ thể:
1. DeepSeek-VL
DeepSeek-VL là mô hình ngôn ngữ thị giác đầu tiên của DeepSeek, được thiết kế để hiểu cả hình ảnh và văn bản cùng nhau. Nó tập trung vào các tác vụ đa phương thức trong thế giới thực như tài liệu, trang web, biểu đồ và hình ảnh tự nhiên thay vì chỉ tập trung vào các bộ dữ liệu đánh giá tiêu chuẩn.
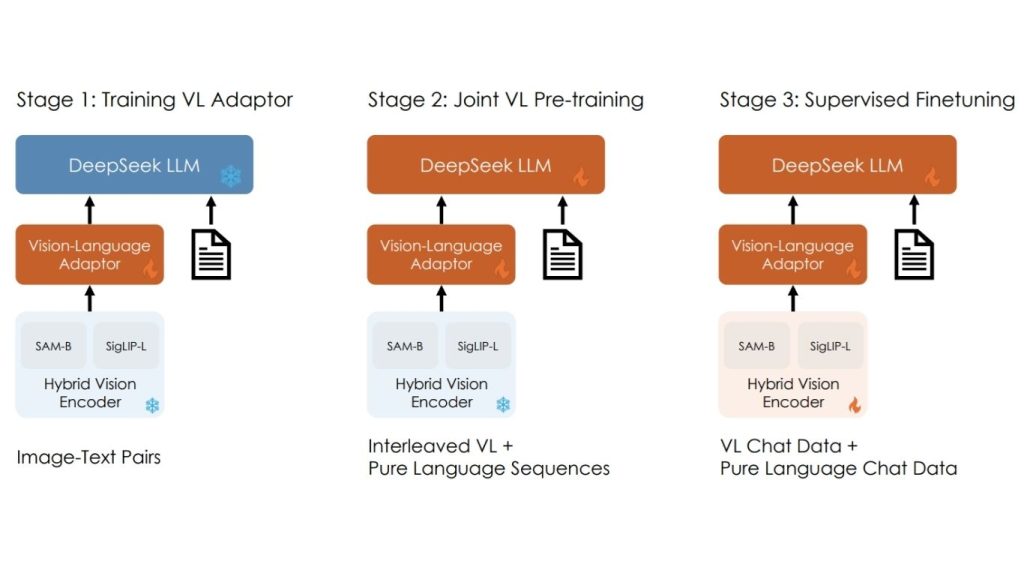
Kiến trúc của mô hình DeepSeek-VL:
DeepSeek-VL sử dụng một bộ mã hóa thị giác lai (hybrid vision encoder), kết hợp SigLIP-L để hiểu ngữ nghĩa tổng thể và SAM-B để nắm bắt các chi tiết hình ảnh. Điều này cho phép mô hình xử lý hình ảnh độ phân giải cao trong khi vẫn bảo tồn được cả ngữ cảnh toàn cục và các yếu tố nhỏ như văn bản và cấu trúc.
Các đặc trưng thị giác sau đó được đưa qua một bộ thích nghi ngôn ngữ thị giác (vision-language adaptor), bộ phận này giúp chuyển chiếu chúng vào không gian đầu vào của mô hình ngôn ngữ để mô hình có thể suy luận đồng thời trên cả hình ảnh và văn bản.
Các khả năng chính của mô hình DeepSeek-VL:
- Trả lời câu hỏi thị giác (Visual Question Answering) trên hình ảnh và tài liệu.
- OCR và đọc văn bản từ hình ảnh.
- Hiểu sơ đồ và biểu đồ.
- Hiểu trang web và ảnh chụp màn hình.
- Hiểu nội dung có cấu trúc như bảng biểu và bố cục.
- Suy luận đa phương thức trên cả hình ảnh và văn bản.
>> Tham khảo:
- Top 7 công cụ theo dõi đối tượng mã nguồn mở tốt nhất
- AI Data Labeling: Hướng dẫn gán nhãn dữ Liệu AI
2. Janus
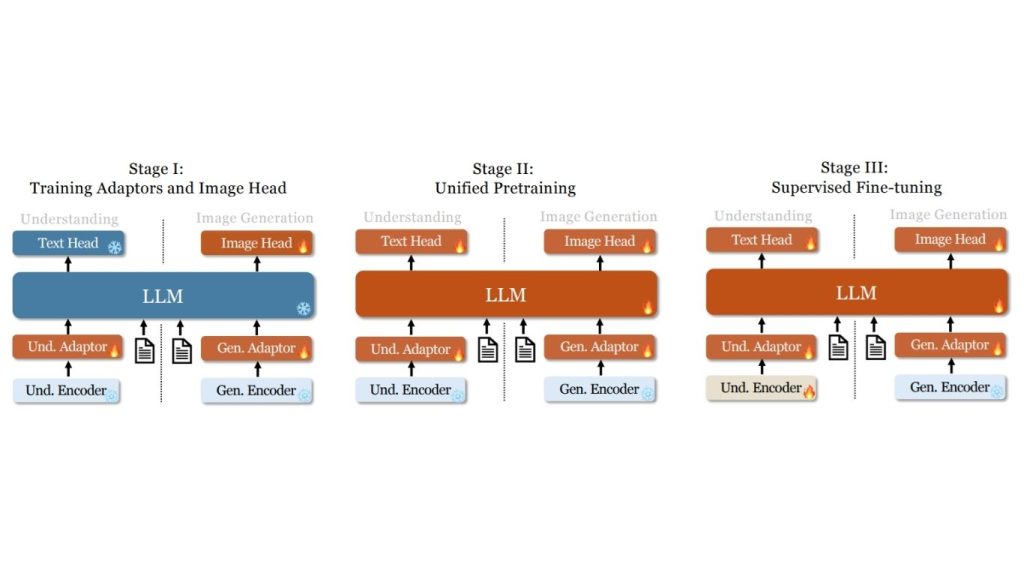
Janus là mô hình ngôn ngữ thị giác thống nhất của DeepSeek, có thể vừa hiểu hình ảnh vừa tạo ra hình ảnh trong cùng một kiến trúc.
Không giống như các mô hình trước đây sử dụng một bộ mã hóa thị giác duy nhất cho cả hai tác vụ, Janus tách biệt các đường dẫn mã hóa thị giác cho việc hiểu và việc tạo, trong khi cả hai đều được điều hướng qua một bộ biến đổi tự hồi quy dùng chung.
Kiến trúc của mô hình Janus:
Janus sử dụng một khung làm việc tự hồi quy thống nhất việc hiểu và tạo đa phương thức trong một kiến trúc transformer duy nhất, đồng nhất. Nó tách biệt việc mã hóa thị giác thành các đường dẫn riêng biệt cho việc hiểu và tạo, trong khi cả hai vẫn được kết nối thông qua một xương sống ngôn ngữ (backbone) dùng chung.
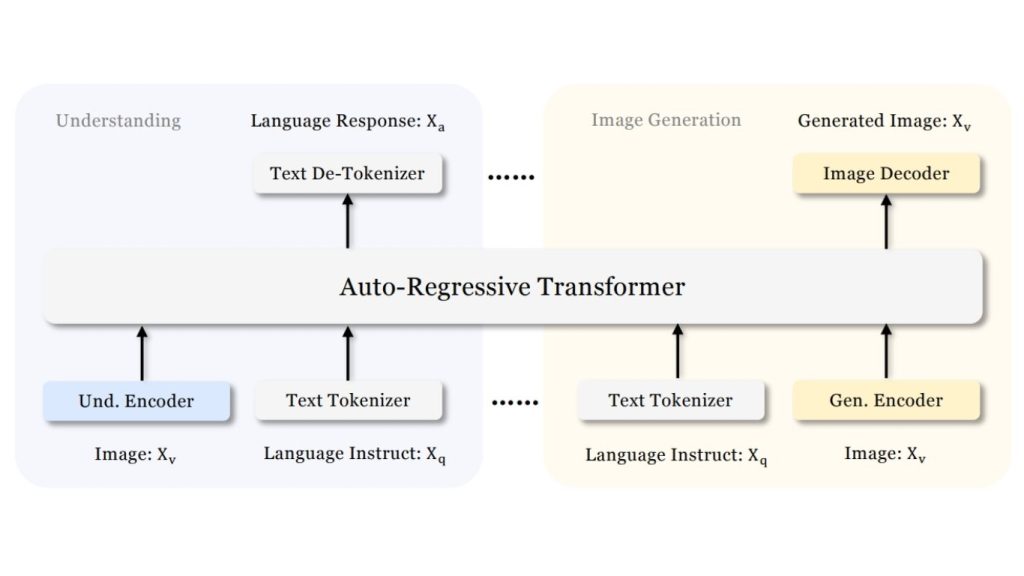
Để hiểu hình ảnh, Janus sử dụng bộ mã hóa thị giác SigLIP để trích xuất các đặc trưng ngữ nghĩa và ánh xạ chúng vào không gian đầu vào của mô hình ngôn ngữ. Để tạo hình ảnh, nó sử dụng một bộ mã hóa mã (VQ tokenizer) để chuyển đổi hình ảnh thành các ID rời rạc, sau đó chúng được mô hình hóa theo phương pháp tự hồi quy bởi cùng một transformer để tạo ra hình ảnh từ các câu lệnh văn bản.
Thiết kế này cho phép Janus xử lý cả hai hướng:
- Hình ảnh → văn bản (hiểu)
- Văn bản → hình ảnh (tạo)
Các khả năng chính của mô hình Janus:
- Hiểu hình ảnh và trả lời câu hỏi thị giác.
- Tạo hình ảnh từ văn bản.
- Suy luận đa phương thức trên hình ảnh và văn bản.
- Tạo hình ảnh dựa trên các câu lệnh ngôn ngữ tự nhiên.

3. JanusFlow (Tháng 11 năm 2024)
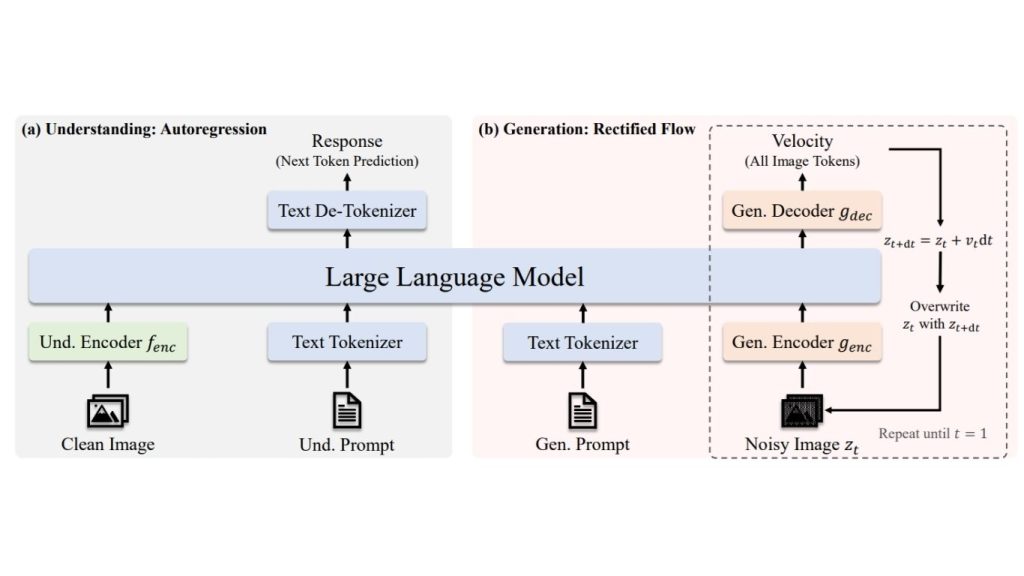
JanusFlow là một mô hình đa phương thức thống nhất từ DeepSeek, kết hợp khả năng hiểu hình ảnh và tạo hình ảnh trong một khung làm việc duy nhất.
Khác với các phương pháp sử dụng các mô hình hoàn toàn tách biệt cho mỗi tác vụ, JanusFlow tích hợp cả hai khả năng thông qua một xương sống ngôn ngữ tự hồi quy dùng chung, giúp việc xử lý nhận thức và tạo hình ảnh có thể thực hiện được trong cùng một mô hình.
Kiến trúc của mô hình JanusFlow
JanusFlow kết hợp một xương sống mô hình ngôn ngữ lớn (LLM backbone) tự hồi quy dùng chung, các bộ mã hóa thị giác tách biệt và việc tạo hình ảnh dựa trên dòng hiệu chỉnh trong một mô hình.
Xương sống LLM dùng chung đóng vai trò là công cụ suy luận cốt lõi cho cả việc hiểu và tạo, trong khi các bộ mã hóa thị giác tách biệt cho phép mỗi tác vụ sử dụng đường dẫn thị giác chuyên biệt của riêng mình.
Thay vì tạo hình ảnh dưới dạng các mã (tokens) rời rạc, JanusFlow tích hợp dòng hiệu chỉnh vào khung làm việc LLM, giúp việc tạo hình ảnh trở nên tự nhiên và hiệu quả hơn mà không yêu cầu các sửa đổi kiến trúc phức tạp. Nó được huấn luyện với sự căn chỉnh biểu diễn để các nhánh hiểu và tạo duy trì tính nhất quán về mặt ngữ nghĩa và hoạt động tốt cùng nhau.
Các khả năng chính:
- Hiểu hình ảnh.
- Trả lời câu hỏi thị giác.
- Tạo hình ảnh từ văn bản.
- Thống nhất nhận thức và tạo hình ảnh trong một mô hình duy nhất.

>> Xem thêm:
- Mẹo tạo prompt cho LLM trong thị giác máy tính để tăng độ chính xác
- Đếm Đối Tượng Bằng Thị Giác Máy Tính
4. Janus-Pro
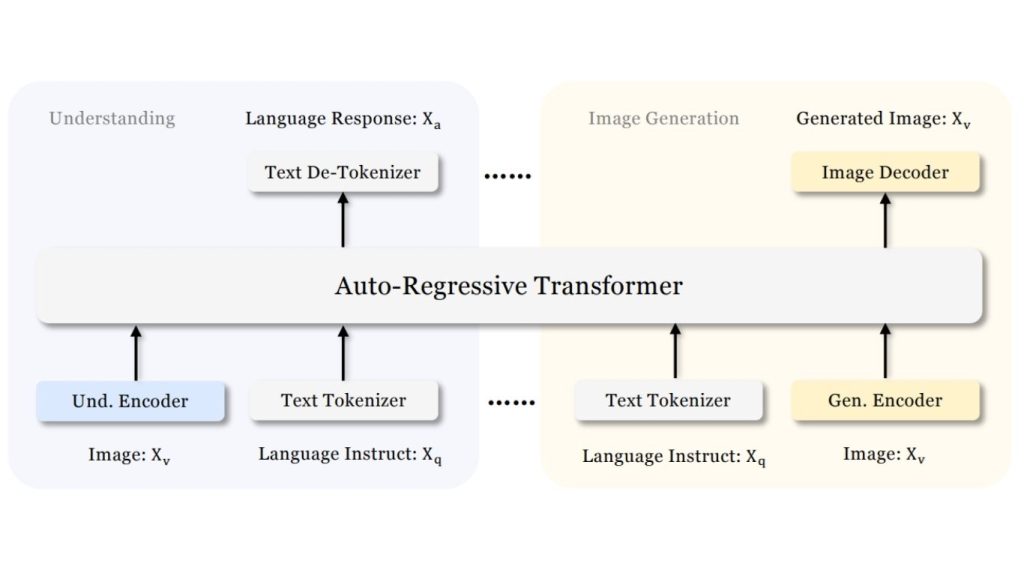
Janus-Pro là một phiên bản nâng cao của Janus được xây dựng cho cả việc hiểu hình ảnh và tạo hình ảnh. Nó giữ nguyên thiết kế đa phương thức thống nhất nhưng cải thiện mô hình bằng chiến lược huấn luyện tối ưu hóa, dữ liệu huấn luyện mở rộng và kích thước mô hình lớn hơn, dẫn đến hiệu suất mạnh mẽ hơn trên cả hai tác vụ hiểu và tạo ảnh.
Kiến trúc của mô hình Janus-Pro
Janus-Pro duy trì cùng một khung làm việc tự hồi quy thống nhất như Janus, sử dụng việc mã hóa thị giác tách biệt để việc hiểu hình ảnh và tạo hình ảnh được xử lý qua các đường dẫn thị giác riêng biệt bên trong một xương sống ngôn ngữ dùng chung.
Để hiểu hình ảnh, nó sử dụng SigLIP-L làm bộ mã hóa thị giác. Để tạo hình ảnh, nó sử dụng một bộ mã hóa mã VQ (VQ tokenizer) để chuyển đổi hình ảnh thành các mã rời rạc. Điều này cho phép mô hình hỗ trợ hiểu đa phương thức và tạo hình ảnh từ văn bản trong một hệ thống. Janus-Pro cũng cải thiện quy trình huấn luyện trên ba phương diện:
- Một chiến lược huấn luyện được tối ưu hóa.
- Dữ liệu huấn luyện được mở rộng cho cả việc hiểu và tạo.
- Và mở rộng quy mô lên các kích thước mô hình lớn hơn (1B và 7B).
Những thay đổi này dẫn đến khả năng hiểu đa phương thức mạnh mẽ hơn, tuân thủ hướng dẫn tạo hình ảnh từ văn bản tốt hơn và tạo hình ảnh ổn định hơn so với phiên bản Janus gốc.
Các khả năng chính của Janus-Pro
- Hiểu hình ảnh.
- Trả lời câu hỏi thị giác.
- Tạo hình ảnh từ văn bản.
- Suy luận đa phương thức trên hình ảnh và văn bản.
5. DeepSeek-VL2
DeepSeek-VL2 là mô hình ngôn ngữ thị giác thế hệ thứ hai của DeepSeek được xây dựng để hiểu đa phương thức mạnh mẽ hơn. Nó cải thiện mô hình DeepSeek-VL trước đó với khả năng xử lý hình ảnh độ phân giải cao tốt hơn, xương sống ngôn ngữ MoE hiệu quả hơn và hiệu suất mạnh mẽ hơn trong các tác vụ như OCR, hiểu tài liệu, hiểu biểu đồ và suy luận thị giác.

Kiến trúc của DeepSeek-VL2
DeepSeek-VL2 sử dụng kiến trúc kiểu LLaVA với ba phần chính: một bộ mã hóa thị giác, một bộ thích nghi ngôn ngữ thị giác và một mô hình ngôn ngữ Hỗn hợp chuyên gia.
Nâng cấp kiến trúc chính của nó là lát gạch động (dynamic tiling), trong đó một hình ảnh độ phân giải cao được thay đổi kích thước thành một độ phân giải ứng viên phù hợp, chia thành nhiều ô cục bộ kích thước 384 × 384 và kết hợp với một ô hình thu nhỏ toàn cục. Tất cả các ô đều được xử lý bởi một bộ mã hóa thị giác SigLIP-SO400M-384 dùng chung, giúp mô hình bảo tồn các chi tiết nhỏ trong tài liệu, biểu đồ và văn bản dày đặc.
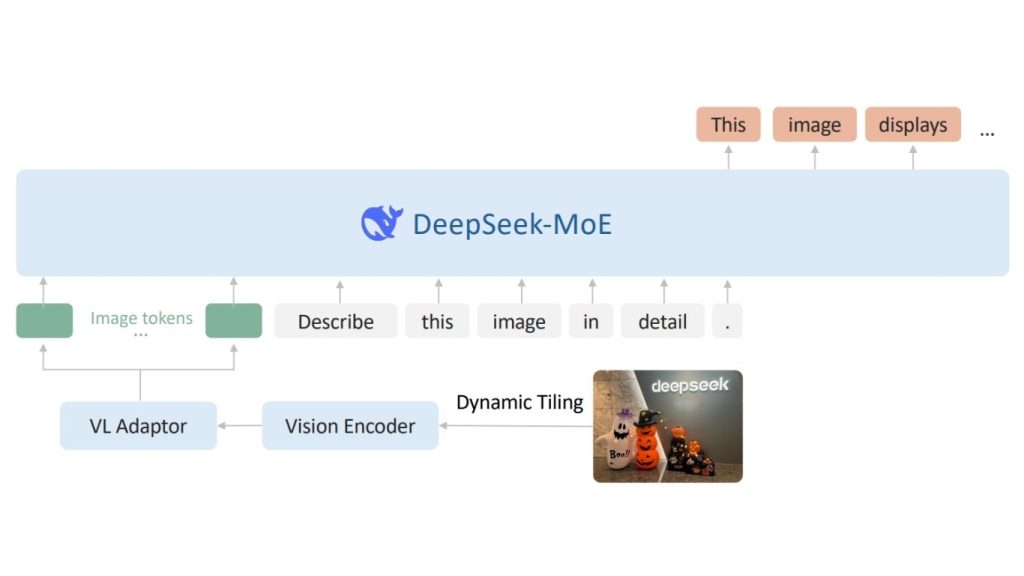
Sau khi các đặc trưng thị giác được trích xuất, mô hình sử dụng một bộ thích nghi ngôn ngữ thị giác để nén các mã thị giác của mỗi ô bằng phương pháp xáo trộn pixel 2 × 2.
Chuỗi thị giác hoàn chỉnh sau đó được chuyển chiếu vào không gian nhúng của mô hình ngôn ngữ bằng một bộ Perceptron đa lớp (Multi-layer Perceptron – MLP) hai lớp.
Về phía ngôn ngữ, DeepSeek-VL2 sử dụng DeepSeekMoE với Cơ chế chú ý tiềm ẩn đa đầu (Multi-head Latent Attention – MLA), giúp nén bộ nhớ đệm Key-Value thành một vectơ tiềm ẩn và cải thiện hiệu suất suy luận cho các chuỗi đa phương thức dài.
Các khả năng chính của DeepSeek-VL2
- Trả lời câu hỏi thị giác.
- OCR.
- Hiểu tài liệu.
- Hiểu bảng biểu và biểu đồ.
- Suy luận thị giác.
- Xác định vị trí thị giác (Visual grounding).
- Hiểu đa hình ảnh (Multi-image understanding).
Dòng mô hình DeepSeek-VL2 cung cấp khả năng hiểu đa phương thức có thể mở rộng quy mô tùy theo nhu cầu triển khai tại biên, tầm trung và sản xuất như được hiển thị trong bảng dưới đây:
| Mô hình | Tổng tham số | Tham số kích hoạt | Khả năng thị giác chính | Phù hợp nhất cho |
| DeepSeek-VL2-Tiny | ~3B MoE | 1.0B | VQA, OCR, grounding | Thiết bị biên, GPU thấp |
| DeepSeek-VL2-Small | ~16B MoE | 2.8B | VQA, biểu đồ, OCR, grounding | GPU tầm trung |
| DeepSeek-VL2 | ~27B MoE | 4.5B | Mọi tác vụ, đa hình ảnh, grounding | Sản xuất |
>> Xem thêm: Transfer Learning là gì? Cách hoạt động và ví dụ thực tế về học chuyển giao
6. DeepSeek-OCR
DeepSeek-OCR là một mô hình thị giác chuyên dụng được phát triển dành riêng cho nhận dạng ký tự quang học (OCR) và việc hiểu các tài liệu dài. Ý tưởng chính của mô hình là xem nội dung tài liệu như một bài toán nén hình ảnh, nhờ đó mô hình có thể giữ lại thông tin hữu ích trên trang trong khi sử dụng số lượng token thị giác ít hơn nhiều so với các chuỗi xử lý VLM tài liệu thông thường.
Bài báo giới thiệu mô hình này như một nghiên cứu ban đầu về việc nén các bối cảnh dài thông qua ánh xạ quang học 2D.
Kiến trúc của DeepSeek-OCR
DeepSeek-OCR có hai phần chính:
- DeepEncoder (bộ mã hoá)
- DeepSeek3B-MoE-A570M đóng vai trò là bộ giải mã (Decoder).
DeepEncoder được thiết kế để duy trì mức kích hoạt thấp dưới đầu vào độ phân giải cao trong khi vẫn đạt được tỷ lệ nén cao, để số lượng mã thị giác cuối cùng vẫn ở mức có thể quản lý được.
Nói một cách đơn giản, bộ mã hóa cố gắng ép một trang tài liệu lớn thành một biểu diễn thị giác nhỏ gọn trước khi bộ giải mã đọc nó.
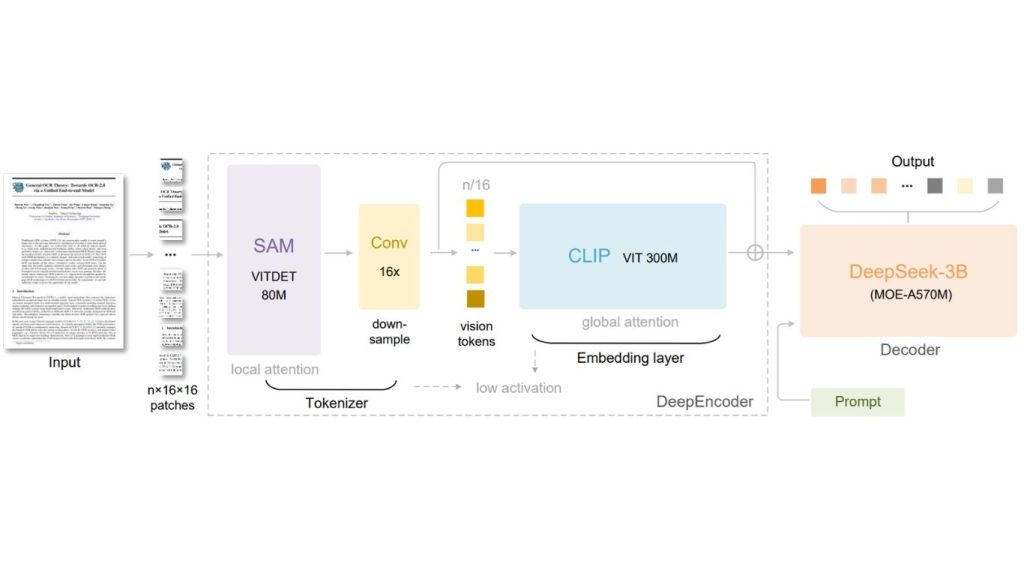
Kiến trúc này dành cho các trường hợp mà các trang dài và bố cục dày đặc thông thường sẽ tạo ra nhiều mã. Bằng cách nén ngữ cảnh thị giác trước, DeepSeek-OCR có thể xử lý các tài liệu dài hiệu quả hơn trong khi vẫn bảo tồn thông tin OCR hữu ích. Bản tóm tắt cũng nhấn mạnh tính hiệu quả thực tế của nó trong xử lý tài liệu ở quy mô sản xuất.
>> Tìm hiểu:
- Deep Learning là gì? Tổng quan về cách hoạt động và ứng dụng thực tế
- AI hỗ trợ lập trình ảnh hưởng đến kỹ năng code như thế nào?
Các khả năng chính của mô hình DeepSeek-OCR
- OCR trên các tài liệu dài và dày đặc.
- Nén thị giác cao để hiểu trang.
- Phân tích tài liệu hiệu quả với ít mã thị giác hơn.
- Tạo dữ liệu huấn luyện quy mô lớn cho các quy trình LLM và VLM.
- Hiệu suất mạnh mẽ trên các bài kiểm tra OCR tài liệu như OmniDocBench.
7. DeepSeek-OCR 2 (Tháng 1 năm 2026)
DeepSeek-OCR 2 là phiên bản tiếp theo của DeepSeek-OCR. Nó tập trung vào việc cải thiện khả năng hiểu tài liệu bằng cách thay đổi cách sắp xếp các mã thị giác trước khi chúng được gửi đến mô hình ngôn ngữ. Thay vì đọc một hình ảnh theo thứ tự cố định từ trái sang phải, từ trên xuống dưới, nó cố gắng tuân theo một thứ tự quét có ý nghĩa về mặt ngữ nghĩa và nhân quả hơn, đặc biệt là đối với các bố cục phức tạp.
Kiến trúc của DeepSeek-OCR 2
DeepSeek-OCR 2 giới thiệu DeepEncoder V2, một bộ mã hóa mới được thiết kế để sắp xếp lại các mã thị giác một cách động dựa trên ngữ nghĩa hình ảnh. Bài báo giải thích rằng hầu hết các mô hình ngôn ngữ thị giác xử lý các mã thị giác theo thứ tự quét mảng (raster-scan) cứng nhắc, nhưng DeepSeek-OCR 2 thay đổi điều này bằng cách cho phép bộ mã hóa tổ chức lại các mã trước khi mô hình ngôn ngữ đọc chúng.
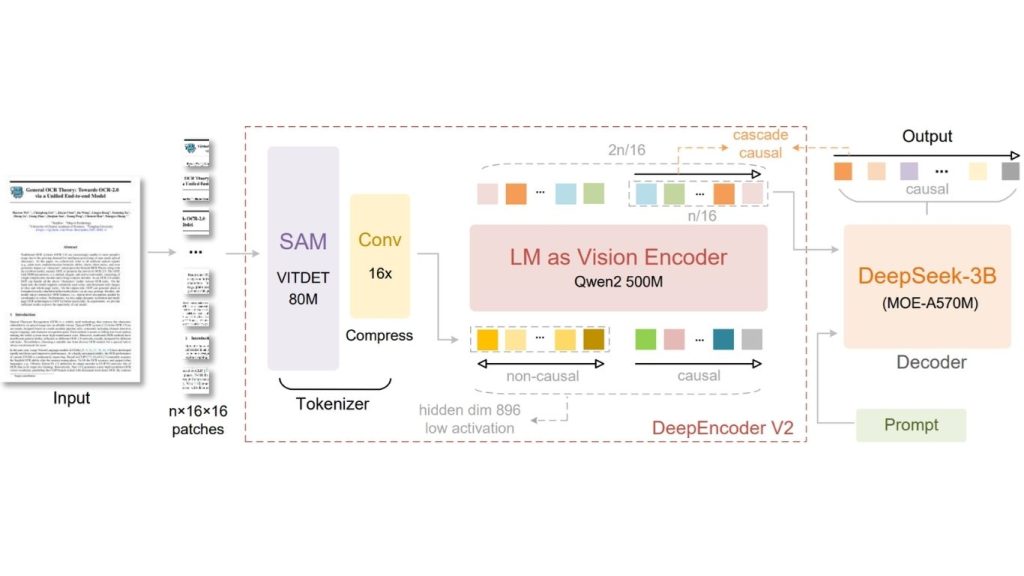
Ý tưởng cốt lõi được gọi là Luồng nhân quả trực quan (Visual Causal Flow). Nó được lấy cảm hứng từ cách thị giác con người tuân theo các cấu trúc logic trong một trang thay vì quét mọi thứ theo một thứ tự cố định.
DeepEncoder V2 được xây dựng để thêm loại khả năng suy luận nhân quả này vào giai đoạn mã hóa thị giác, để mô hình có thể hiểu tốt hơn các bố cục có cấu trúc và nội dung tài liệu phức tạp. Công trình này khám phá liệu việc hiểu hình ảnh 2D có thể được xử lý thông qua hai cấu trúc suy luận nhân quả 1D xếp chồng hay không.
Các khả năng chính của DeepSeek-OCR 2
- OCR với việc sắp xếp mã thị giác nhận biết bố cục.
- Hiểu tốt hơn các cấu trúc tài liệu phức tạp.
- Sắp xếp lại mã thị giác theo ngữ nghĩa trước khi giải mã.
- Suy luận mạnh mẽ hơn trên các trang có bố cục phi tuyến tính.
- Một kiến trúc mới cho việc hiểu thị giác tập trung vào tài liệu.
Bảng sau đây cung cấp tóm tắt về dòng mô hình DeepSeek cho các tác vụ thị giác.
| Mô hình | Loại thị giác | Khả năng thị giác chính |
| DeepSeek-VL-1.3B / 7B | Hiểu | VQA, OCR, sơ đồ, ảnh chụp màn hình web |
| Janus-1.3B | Hiểu + Tạo | Thống nhất hiểu đa phương thức và tạo hình ảnh từ văn bản |
| JanusFlow-1.3B | Hiểu + Tạo | Mô hình dựa trên Janus với dòng hiệu chỉnh để thống nhất hiểu và tạo hình ảnh |
| DeepSeek-VL2-Tiny | Hiểu | MoE VLM, 1.0B tham số kích hoạt, OCR, VQA, hiểu tài liệu |
| DeepSeek-VL2-Small | Hiểu | MoE VLM, 2.8B tham số kích hoạt, OCR mạnh, hiểu biểu đồ và bảng biểu |
| DeepSeek-VL2 | Hiểu | MoE VLM, 4.5B tham số kích hoạt, OCR, grounding, suy luận đa hình ảnh |
| Janus-Pro-1B / 7B | Hiểu + Tạo | Cải thiện hiểu đa phương thức và tạo hình ảnh |
| DeepSeek-OCR | OCR chuyên dụng | Nén quang học ngữ cảnh cho OCR tài liệu dài |
| DeepSeek-OCR-2 | OCR chuyên dụng | Mô hình OCR dựa trên Visual Causal Flow |
>> Tham khảo thêm:
- Top 5 thư viện Python cho thị giác máy tính
- Vertex AI là gì? Nền tảng học máy của Google Cloud
Cách sử dụng DeepSeek-VL2 với thư viện Roboflow Supervision
DeepSeek-VL2 có thể được sử dụng với thư viện Supervision của Roboflow khi bạn muốn chuyển đổi đầu ra văn bản (text output) của mô hình thành các đối tượng phát hiện tiêu chuẩn (standard detection objects) với các khung bao (bounding boxes) và nhãn (labels).
Supervision hỗ trợ sv.VLM.DEEPSEEK_VL_2 bên trong hàm Detections.from_vlm(), và đối với DeepSeek-VL2, đầu vào yêu cầu là chuỗi kết quả thô của mô hình cộng với độ phân giải hình ảnh gốc. Tài liệu của Roboflow cũng hiển thị kiểu câu lệnh nhắc (prompt style) được khuyến nghị cho việc xác định vị trí đối tượng (object localization) và định vị (grounding) của DeepSeek-VL2.
Những gì DeepSeek-VL2 cung cấp cho bạn
DeepSeek-VL2 là một mô hình ngôn ngữ thị giác (VLM), vì vậy nó không trực tiếp trả về các kết quả phát hiện theo cùng định dạng như một trình phát hiện như mô hình YOLO. Thay vào đó, nó tạo ra một phản hồi văn bản.Đối với các tác vụ định vị, phản hồi đó chứa các mã thông báo đặc biệt chẳng hạn như <|ref|> cho cụm từ đối tượng và <|det|> cho tọa độ khung bao. Các ví dụ chính thức của DeepSeek-VL2 cho thấy các đầu ra như:
<|ref|>The giraffe at the back.<|/ref|><|det|>[[580, 270, 999, 900]]<|/det|>Đây chính xác là loại phản hồi mà Supervision có thể phân tích cú pháp thành các khung và nhãn.
>> Xem thêm: Object Detection là gì? Tìm hiểu về phát hiện đối tượng
Bước 1. Chạy DeepSeek-VL2 trên một hình ảnh
Đầu tiên, bạn chạy DeepSeek-VL2 trên hình ảnh và câu lệnh nhắc của mình. Hướng dẫn bắt đầu nhanh chính thức trên GitHub sẽ tải một mô hình chẳng hạn như deepseek-ai/deepseek-vl2-tiny, chuẩn bị hình ảnh và cuộc hội thoại, tạo các bản nhúng hình ảnh, và sau đó gọi hàm language.generate() để nhận chuỗi phản hồi.
Kho lưu trữ của DeepSeek cũng lưu ý rằng <|ref|> và <|/ref|> được sử dụng để xác định vị trí đối tượng, trong khi <|grounding|> có thể được thêm vào cho các câu lệnh nhắc kiểu chú thích có định vị.
Ví dụ, một câu lệnh nhắc xác định vị trí có thể trông như thế này:
<image>
<|ref|>The giraffe at the front<|/ref|>Và để định vị nhiều đối tượng, Roboflow khuyến nghị một câu lệnh nhắc như:
<image>
<|grounding|>Detect the giraffesCác kiểu câu lệnh nhắc này giúp DeepSeek-VL2 trả về tọa độ phát hiện theo định dạng <|det|>.
Bước 2. Lưu kết quả DeepSeek-VL2 thô
Khi mô hình phản hồi, hãy giữ nguyên chuỗi đầu ra thô chính xác như hiện tại. Trong ví dụ của bạn, chuỗi đó là:
deepseek_vl2_result = (
"<|ref|>The giraffe at the back<|/ref|>"
"<|det|>[[580, 270, 999, 904]]<|/det|>"
"<|ref|>The giraffe at the front<|/ref|>"
"<|det|>[[26, 31, 632, 998]]<|/det|>"
"<|end▁of▁sentence|>"
)Chuỗi này chứa cả các cụm từ đối tượng và tọa độ. Supervision đọc định dạng này và trích xuất các kết quả phát hiện một cách tự động. Tài liệu của Roboflow sử dụng cùng một ý tưởng này trong ví dụ về DeepSeek-VL2 của họ.
Bước 3. Chuyển đổi kết quả thành sv.Detections
Đây là lúc Roboflow Supervision trở nên hữu ích. Bạn truyền đầu ra DeepSeek-VL2 thô vào hàm sv.Detections.from_vlm() cùng với kích thước hình ảnh gốc:
detections = sv.Detections.from_vlm(
vlm=sv.VLM.DEEPSEEK_VL_2,
result=deepseek_vl2_result,
resolution_wh=image.size
)Sau đó, Supervision sẽ phân tích cú pháp các khung <|det|> và xây dựng một đối tượng phát hiện tiêu chuẩn. Theo tài liệu, điều này cung cấp cho bạn các đầu ra có cấu trúc như detections.xyxy, detections.class_id, và detections.data[“class_name”].
Bước 4. Kiểm tra những gì Supervision đã phân tích cú pháp
Sau khi phân tích cú pháp, mã của bạn sẽ in ra:
print(detections.xyxy)
print(detections.data)Điều này cho phép bạn kiểm tra xem các tọa độ và nhãn đã được trích xuất chính xác hay chưa. Ví dụ của Roboflow cho thấy rằng các kết quả phát hiện của DeepSeek-VL2 trở thành các mảng khung bao bình thường, và tên đối tượng được lưu trữ trong class_name.
Trong thực tế, bước này rất quan trọng vì DeepSeek-VL2 vẫn là một mô hình ngôn ngữ thị giác (VLM), không phải là một trình phát hiện chuyên dụng. Vì vậy, bạn nên xác nhận rằng mô hình đã hiểu câu lệnh nhắc của bạn một cách chính xác và trả về đúng các đối tượng được định vị.
Bước 5. Vẽ các khung và nhãn lên hình ảnh
Khi các kết quả phát hiện đã ở định dạng Supervision, bạn có thể sử dụng các công cụ chú thích thông thường. Mã của bạn sử dụng BoxAnnotator() và LabelAnnotator():
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()Sau đó, nó vẽ các khung và nhãn lên hình ảnh OpenCV và lưu kết quả. Đây là một phần thú vị trong luồng công việc của Roboflow, bởi vì sau khi phân tích cú pháp, DeepSeek-VL2 hoạt động giống như bất kỳ nguồn phát hiện nào khác bên trong Supervision. Bạn có thể trực quan hóa nó, theo dõi nó, lọc nó hoặc chuyển nó xuống các logic thị giác máy tính khác.
Dưới đây là mã đầy đủ:
from PIL import Image
import cv2
import supervision as sv
from IPython.display import display
image_path = "giraffe.png"
# PIL for size
image = Image.open(image_path)
# OpenCV for drawing
image_cv = cv2.imread(image_path)
deepseek_vl2_result = (
"<|ref|>The giraffe at the back<|/ref|>"
"<|det|>[[580, 270, 999, 904]]<|/det|>"
"<|ref|>The giraffe at the front<|/ref|>"
"<|det|>[[26, 31, 632, 998]]<|/det|>"
"<|end▁of▁sentence|>"
)
detections = sv.Detections.from_vlm(
vlm=sv.VLM.DEEPSEEK_VL_2,
result=deepseek_vl2_result,
resolution_wh=image.size
)
print(detections.xyxy)
print(detections.data)
# labels from parsed class names
labels = detections.data["class_name"].tolist()
# annotators
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
# draw boxes
annotated = box_annotator.annotate(
scene=image_cv.copy(),
detections=detections
)
# draw labels
annotated = label_annotator.annotate(
scene=annotated,
detections=detections,
labels=labels
)
# display in notebook
display(Image.open("giraffe_boxed.png"))Khi bạn chạy mã, bạn sẽ thấy đầu ra tương tự như sau:

>> Xem thêm:
- Phát hiện đối tượng trong video với RF-DETR
- Vision Inspection Systems: Hệ thống kiểm tra thị giác là gì?
Khả năng thị giác của DeepSeek-VL2
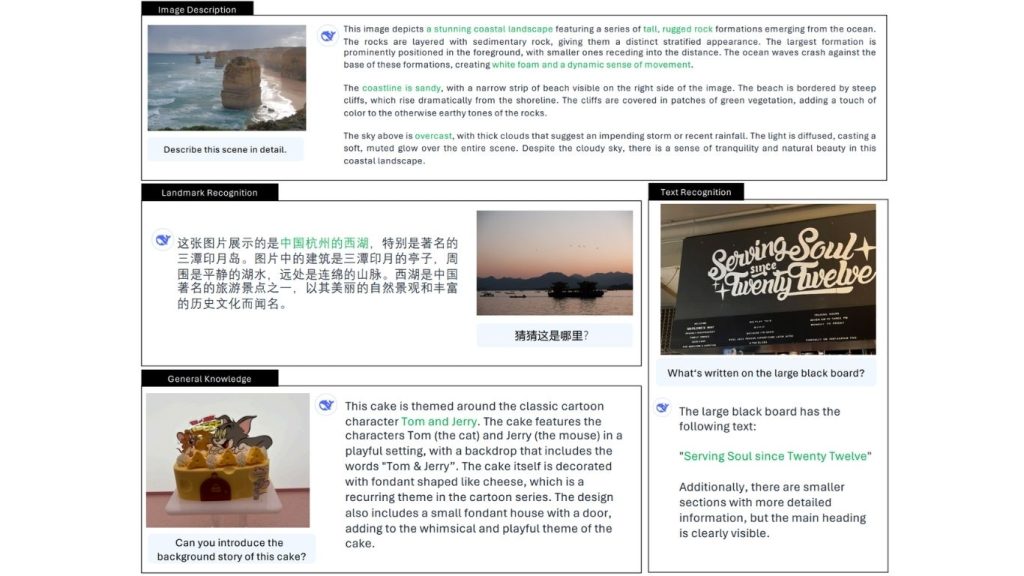
DeepSeek-VL2 là một mô hình ngôn ngữ thị giác đa năng có thể xử lý một loạt các tác vụ thị giác bằng cách sử dụng các câu lệnh nhắc bằng ngôn ngữ tự nhiên. Bạn cung cấp một hình ảnh và mô tả những gì bạn muốn, và mô hình sẽ phản hồi bằng văn bản hoặc đầu ra có cấu trúc. Dưới đây là các khả năng chính mà bạn có thể thử nghiệm:
1. Visual Question Answering (VQA)
Trả lời câu hỏi thị giác (Visual Question Answering) là khả năng tổng quát nhất của DeepSeek-VL2. Bạn cung cấp một hình ảnh, đặt một câu hỏi bằng ngôn ngữ tự nhiên, và mô hình sẽ trả về câu trả lời bằng ngôn ngữ tự nhiên. Điều này làm cho nó trở thành điểm khởi đầu tốt cho bất kỳ ứng dụng thị giác mới nào. Nó có thể xử lý:
- Các câu hỏi ở cấp độ bối cảnh
- Đếm đối tượng
- Mối quan hệ giữa các đối tượng
- Suy luận trên ngữ cảnh thị giác
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\nWhat is happening in this image?",
"images": ["street.jpg"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Phân tích kệ hàng bán lẻ.
- Báo cáo kiểm tra chất lượng.
- Tìm kiếm dựa trên hình ảnh.
- Hỗ trợ khách hàng bằng hình ảnh.
2. Nhận dạng ký tự quang học (OCR)
DeepSeek-VL2 có thể đọc và trích xuất văn bản từ hình ảnh, bao gồm cả tài liệu và các bối cảnh thực tế. Nó hoạt động tốt trên các bố cục có cấu trúc nơi cả văn bản và định dạng đều quan trọng. Nó có thể xử lý:
- Các tài liệu và biểu mẫu in sẵn.
- Văn bản trong bối cảnh tự nhiên (nhãn, bảng hiệu).
- Các bảng biểu dày đặc và bố cục có cấu trúc.
- Văn bản và đồ họa hỗn hợp.
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\nExtract all text from this document.",
"images": ["invoice.png"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Xử lý hóa đơn.
- Số hóa tài liệu.
- Trích xuất dữ liệu biểu mẫu.
- Đọc nhãn sản phẩm.
>> Xem thêm: Top 5 thư viện Python cho thị giác máy tính – So sánh sự khác nhau
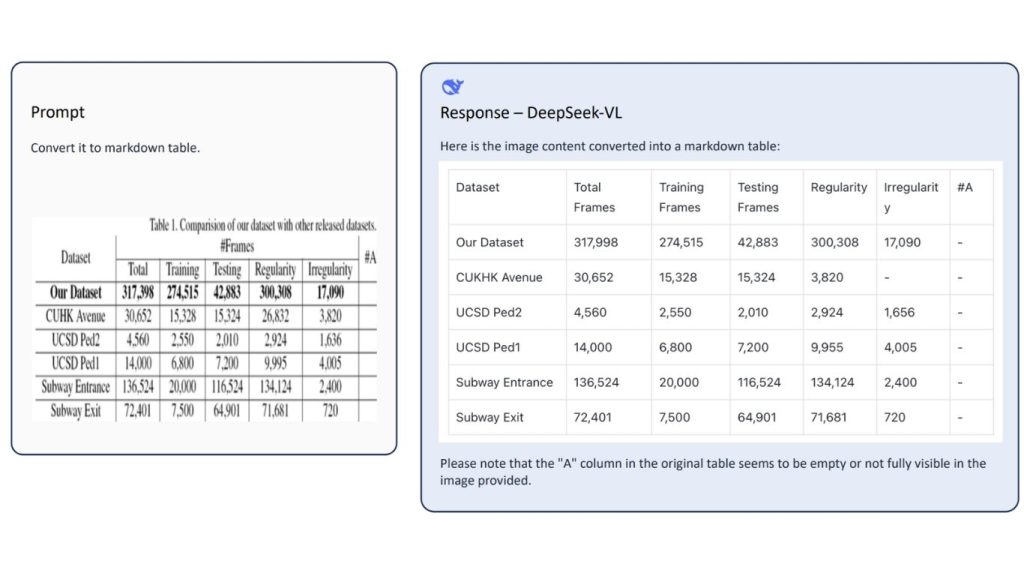
3. Hiểu tài liệu, bảng biểu và biểu đồ
Bên cạnh việc đọc văn bản, DeepSeek-VL2 có thể diễn giải các nội dung thị giác có cấu trúc như bảng biểu, biểu đồ và báo cáo. Nó có thể xử lý:
- Hiểu và truy vấn bảng biểu
- Diễn giải biểu đồ (đường, cột,…)
- Trích xuất thông tin khóa-giá trị
- Tóm tắt các tài liệu có cấu trúc
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\nWhat trend is shown in this chart?",
"images": ["chart.png"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Phân tích báo cáo tài chính.
- Diễn giải bảng điều khiển.
- Hiểu các số liệu khoa học.
- Trích xuất dữ liệu tự động.
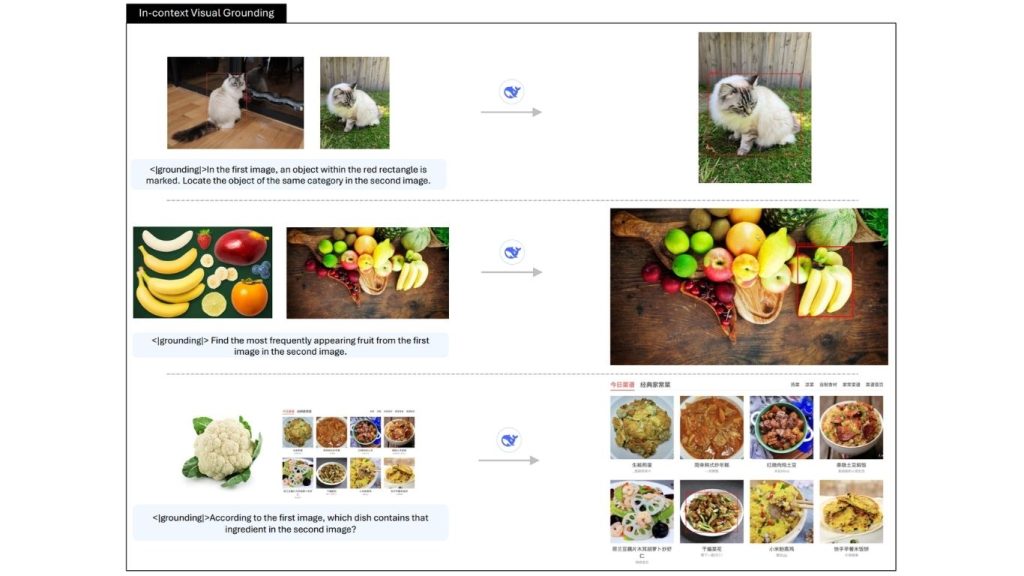
4. Định vị thị giác (Phát hiện dựa trên ngôn ngữ)
Định vị thị giác cho phép bạn tìm vị trí các đối tượng trong một hình ảnh bằng ngôn ngữ tự nhiên. Mô hình trả về tọa độ khung bao cho đối tượng được mô tả. Nó có thể xử lý:
- Xác định vị trí đối tượng bằng mô tả văn bản.
- Định vị nhiều đối tượng.
- Phát hiện không cần huấn luyện (không yêu cầu huấn luyện trước).
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\n<|ref|>The red fire extinguisher<|/ref|>",
"images": ["factory.jpg"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Các hệ thống tìm kiếm thị giác.
- Robot (xác định đối tượng mục tiêu).
- Các công cụ tự động chú thích (Auto-annotation tools).
- Các quy trình phát hiện không cần huấn luyện (Zero-shot detection pipelines).
>> Xem thêm: Object Detection Models: Các mô hình phát hiện đối tượng tốt nhất
5. Hiểu đa hình ảnh
DeepSeek-VL2 có thể xử lý và suy luận trên nhiều hình ảnh trong một lần tương tác duy nhất. Nó có thể xử lý:
- So sánh các hình ảnh.
- Phát hiện các điểm khác biệt.
- Suy luận qua các chuỗi hình ảnh.
- Hiểu thị giác với ít mẫu.
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\n<image>\nWhich product has more quantity?",
"images": ["before.png", "after.png"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Phân tích trước/sau (Before/after analysis).
- So sánh chất lượng.
- Quy trình kiểm tra.
- Phát hiện thay đổi thị giác.
6. Chú thích hình ảnh
DeepSeek-VL2 có thể tạo ra các mô tả bằng ngôn ngữ tự nhiên chi tiết về hình ảnh mà không cần một câu hỏi cụ thể. Nó có thể xử lý:
- Mô tả bối cảnh.
- Liệt kê đối tượng.
- Tóm tắt nhận biết ngữ cảnh.
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\nDescribe this image in detail.",
"images": ["scene.jpg"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Chú thích bộ dữ liệu.
- Khả năng tiếp cận (tạo văn bản thay thế – alt-text).
- Lập chỉ mục và tìm kiếm hình ảnh.
>> Tham khảo thêm: Cách so sánh các mô hình thị giác máy tính một cách trực quan
7. Hiểu ở cấp độ vùng
DeepSeek-VL2 có thể trả lời các câu hỏi về các phần cụ thể của hình ảnh, thay vì chỉ toàn bộ bối cảnh. Nó có thể xử lý:
- Các truy vấn được khoanh vùng.
- Đọc các vùng cụ thể.
- Phân tích chi tiết.
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\nWhat is written on the signboard in the top left corner?",
"images": ["street.jpg"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Phân tích giao diện người dùng (UI) và màn hình.
- Kiểm tra công nghiệp.
- Trích xuất văn bản được khoanh vùng.
>> Xem thêm: AI trong thiết kế UI/UX: Sức mạnh của Generative AI
8. Chú thích có định vị
Đây là sự kết hợp giữa phát hiện đối tượng và mô tả. Mô hình có thể mô tả các đối tượng cùng với vị trí của chúng. Nó có thể xử lý:
- Mô tả đối tượng kèm theo khung bao.
- Hiểu bối cảnh đa đối tượng.
- Tạo đầu ra có cấu trúc.
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\n<|grounding|>Describe all objects in the image.",
"images": ["scene.jpg"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Tự động dán nhãn bộ dữ liệu.
- Hiểu bối cảnh.
- Tạo dữ liệu huấn luyện.
>> Tìm hiểu thêm: Data Annotation Platforms: Nền tảng gán nhãn dữ liệu cho thị giác máy tính tốt nhất
9. Hiểu giao diện người dùng GUI và màn hình
DeepSeek-VL2 có thể diễn giải các yếu tố giao diện người dùng có cấu trúc và bố cục màn hình. Nó có thể xử lý:
- Phát hiện nút bấm, menu và bố cục.
- Hiểu bảng điều khiển.
- Suy luận giao diện người dùng có cấu trúc.
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\nWhat are the main sections in this dashboard?",
"images": ["dashboard.png"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Tự động hóa quy trình bằng robot (Robotic Process Automation – RPA).
- Kiểm thử giao diện người dùng (UI testing).
- Tự động hóa luồng công việc.
10. Tuân thủ hướng dẫn thị giác
Bạn có thể đưa ra các hướng dẫn dựa trên nội dung hình ảnh và mô hình sẽ thực hiện chúng. Nó có thể xử lý:
- Suy luận dựa trên tác vụ.
- Đầu ra theo hướng dẫn.
- Báo cáo có cấu trúc.
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\nFind all damaged parts and list them.",
"images": ["machine.jpg"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Kiểm tra sản xuất.
- Kiểm soát chất lượng.
- Báo cáo tự động.
11. Suy luận thị giác ít mẫu
DeepSeek-VL2 có thể sử dụng các hình ảnh ví dụ để hướng dẫn suy luận trên các đầu vào mới. Nó có thể xử lý:
- Khớp mẫu (Pattern matching).
- Suy luận dựa trên ví dụ.
- Các tác vụ tương đồng thị giác.
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\n<image>\nFind objects similar to the first image in the second image.",
"images": ["example.jpg", "target.jpg"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Tìm kiếm thị giác.
- Phát hiện khiếm khuyết.
- Nhận dạng mẫu.
12. Suy luận không gian và bối cảnh
Mô hình có thể hiểu các mối quan hệ không gian và cấu trúc logic trong hình ảnh. Nó có thể xử lý:
- Suy luận về khoảng cách và sự gần kề.
- Mối quan hệ giữa các đối tượng.
- Logic ở cấp độ bối cảnh.
Ví dụ:
conversation = [
{
"role": "<|User|>",
"content": "<image>\nWhich object is closest to the door?",
"images": ["room.jpg"],
},
{"role": "<|Assistant|>", "content": ""}
]Các trường hợp sử dụng thực tế:
- Robot và điều hướng.
- Trợ lý thông minh.
- Phân tích bối cảnh.
DeepSeek-VL2 không bị giới hạn ở một tác vụ duy nhất như OCR hay phát hiện đối tượng. Nó là một hệ thống đa phương thức (multimodal system) thống nhất, hỗ trợ một loạt các tác vụ thị giác thông qua tương tác bằng ngôn ngữ tự nhiên. Điều này làm cho nó cực kỳ linh hoạt cho các ứng dụng thực tế nơi các yêu cầu thay đổi theo thời gian.
>>> Tham khảo thêm:
- So sánh giữa mô hình ngôn ngữ thị giác và phát hiện đối tượng
- Những trình soạn thảo mã cho thị giác máy tính tốt nhất
- Các công cụ thị giác máy tính tốt nhất
Kết luận về các mô hình thị giác DeepSeek
Sự tích hợp của DeepSeek với Roboflow Supervision đặc biệt hữu ích cho các nhà phát triển và các đội ngũ đang xây dựng các hệ thống thị giác máy tính sẵn sàng cho sản xuất, cho phép người dùng sử dụng các mô hình này cho các tác vụ ngôn ngữ thị giác nâng cao.
Điều này giúp dễ dàng chuyển đổi từ các phản hồi thô của mô hình sang các kết quả phát hiện có cấu trúc, các đầu ra được chú thích và các quy trình ứng dụng thực tế.
>>> Hãy khám phá thêm hiệu suất của các mô hình về OCR, phát hiện đối tượng và nhiều hơn thế nữa trong Roboflow Playground.
>>> Nguồn tham khảo: DeepSeek Vision Models
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com🏢 Địa chỉ:31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam







