Transfer Learning là gì? Đây là câu hỏi thường gặp khi bạn cần xây dựng mô hình thị giác máy tính (computer vision) nhưng lại chỉ có rất ít dữ liệu hình ảnh để huấn luyện. Trong nhiều trường hợp, việc chờ thu thập thêm dữ liệu là không khả thi, đặc biệt với những đặc trưng hiếm hoặc khó ghi nhận như động vật hoang dã trong tự nhiên hay các lỗi rất nhỏ trên sản phẩm. Thay vì huấn luyện mô hình từ đầu với chi phí cao và thời gian dài, Transfer Learning cho phép tận dụng tri thức từ các mô hình đã được huấn luyện sẵn để giải quyết bài toán mới nhanh hơn và chính xác hơn.
Trong bài viết này, TOT sẽ cùng bạn tìm hiểu Transfer Learning là gì, cách phương pháp này hoạt động và những tình huống thực tế nên áp dụng để tối ưu hiệu quả phát triển mô hình.
>>> Tìm hiểu thêm:
- Deep Learning là gì? Tổng quan về cách hoạt động và ứng dụng thực tế
- Vision AI Agents là gì? Cách xây dựng Vision AI Agents với Roboflow
- Những trình soạn thảo mã cho thị giác máy tính tốt nhất 2026
Transfer Learning là gì?
Ttransfer Learning (còn gọi là học chuyển giao), là một kỹ thuật trong thị giác máy tính, trong đó một mô hình mới được xây dựng dựa trên một mô hình đã có sẵn. Mục đích của kỹ thuật này là khuyến khích mô hình mới học các đặc trưng từ mô hình cũ, từ đó mô hình mới có thể được đào tạo nhanh hơn và với ít dữ liệu hơn để đạt được mục tiêu của nó.
Tên gọi “transfer learning” đã thể hiện rõ ý nghĩa của kỹ thuật này: bạn chuyển giao kiến thức mà một mô hình đã học được sang một mô hình mới, nơi kiến thức đó có thể mang lại lợi ích. Điều này tương tự như việc bạn chuyển kiến thức hội họa của mình sang vẽ tranh như lý thuyết màu sắc, gu thẩm mỹ, dù cho hai nhiệm vụ này khác nhau.
Hãy cùng xem một ví dụ minh họa cho học chuyển giao trong thực tế ngay sau đây.
Ví dụ về Transfer Learning trong thực tế
Ví dụ về học chuyển giao trong thực tế bằng cách dạy bạn bè chơi trượt ván:
Hãy tưởng tượng bạn có hai người bạn và bạn đang cố gắng dạy họ trượt ván. Cả hai đều chưa từng trượt ván trước đây. Người bạn A, gọi là Anna, từng chơi trượt tuyết và đã thử lướt sóng. Người bạn B, gọi là Brian, chưa từng tham gia bất kỳ môn thể thao sử dụng ván nào. Theo bạn, ai sẽ học trượt ván nhanh hơn?
Nếu không biết thêm thông tin gì về Brian và Anna, rất có thể bạn sẽ chọn Anna. Mặc dù Anna chưa từng trượt ván cụ thể, nhưng cô ấy đã tham gia các môn thể thao dùng ván khác, những lĩnh vực liên quan như trượt tuyết. Chúng ta có thể kỳ vọng rằng khả năng giữ thăng bằng mà Anna học được từ trượt tuyết sẽ giúp cô ấy làm quen với trượt ván nhanh hơn. Thậm chí, Anna không chỉ học nhanh hơn mà còn có thể trở thành một người trượt ván giỏi hơn Brian.
Nói cách khác, chúng ta đặt cược vào Anna vì tin rằng cô ấy có thể chuyển giao những gì đã học từ trượt tuyết để thử thách trượt ván thành công.
>> Xem thêm:
- Phrase Grounding là gì? Mô hình và cách hoạt động
- Vertex AI là gì? Nền tảng học máy của Google Cloud
Transfer Learning trong học máy
Trong học máy (machine learning), học chuyển giao cũng không quá khác biệt. Về bản chất, học chuyển giao là việc sử dụng những gì một mô hình đã học được từ một miền dữ liệu để áp dụng vào việc học một bài toán liên quan khác.
Hãy tưởng tượng chúng ta đang cố gắng dạy một mô hình nhận diện các giống chó cụ thể: Labrador, Pug, Corgi,… Nếu chúng ta có sẵn một mô hình học máy đã biết cách nhận diện chó trong ảnh (nhưng chưa phân biệt được giống chó cụ thể) và một mô hình khác hoàn toàn chưa biết gì, thì ta có thể kỳ vọng rằng mô hình đã biết “con chó trông như thế nào” sẽ học cách phân biệt giống chó nhanh hơn và thực tế thường đúng như vậy.
Hãy nhớ rằng, trong học máy, chúng ta đang tinh chỉnh trọng số của mô hình. Các trọng số này có thể được khởi tạo ngẫu nhiên hoàn toàn hoặc được khởi tạo từ một tập giá trị đã có trước. Khi huấn luyện mô hình từ đầu (tức là không có dữ liệu hay kiến thức trước đó), các trọng số sẽ được khởi tạo ngẫu nhiên.
Khi sử dụng học chuyển giao, các trọng số này đã mang những giá trị được học từ bài toán miền dữ liệu trước đó. Vì vậy, mô hình sẽ cần ít điều chỉnh hơn để học một miền dữ liệu mới. Thậm chí, mô hình còn có thể chứa những kiến thức “ngầm” mà một mô hình huấn luyện từ đầu sẽ không bao giờ học được.
Ví dụ về học chuyển giao trong học máy
Hãy tưởng tượng bạn có các hình ảnh động vật được thu thập trong một chuyến safari ở châu Phi. Tập dữ liệu bao gồm hình ảnh của hươu cao cổ và voi. Bây giờ, giả sử bạn muốn xây dựng một mô hình có thể phân biệt hươu cao cổ và voi dựa trên những hình ảnh này, như một phần của hệ thống đếm số lượng động vật hoang dã trong một khu vực.
Điều đầu tiên bạn có thể nghĩ đến là xây dựng một mô hình nhận dạng hình ảnh từ đầu. Tuy nhiên, do bạn chỉ chụp được rất ít ảnh, nên khả năng đạt được độ chính xác cao là rất thấp.
Vì vậy, bạn quyết định tìm thêm hình ảnh để mở rộng tập dữ liệu, gán nhãn cho các ảnh mới, rồi huấn luyện mô hình từ đầu. Cách này có thể thực hiện được, nhưng giả sử bạn tìm được ảnh phù hợp với miền dữ liệu của mình, thì quá trình này sẽ tốn rất nhiều thời gian.
Nhưng giả sử bạn đã có một mô hình được huấn luyện trên hàng triệu hình ảnh và có khả năng phân biệt chó và mèo.
Khi đó, bạn có thể sử dụng mô hình đã được huấn luyện sẵn này và tận dụng những gì nó đã học để dạy nó phân biệt các loài động vật khác (trong trường hợp này là hươu cao cổ và voi), mà không cần huấn luyện một mô hình lại từ đầu, điều này đòi hỏi không chỉ lượng dữ liệu lớn mà chúng ta không có, mà còn đòi hỏi mức độ tính toán rất cao.
Việc khai thác kiến thức từ một mô hình đã được huấn luyện để tạo ra một mô hình mới chuyên biệt cho một nhiệm vụ khác chính là học chuyển giao (transfer learning).
>> Xem thêm:
- Mẹo tạo prompt cho LLM trong thị giác máy tính để tăng độ chính xác
- Vision Inspection Systems: Hệ thống kiểm tra thị giác là gì?
Cách sử dụng Transfer Learning trong thị giác máy tính
Điều cốt lõi của học chuyển giao là đảm bảo rằng hai bài toán bạn đang làm việc đủ giống nhau để những gì mô hình học được ở bài toán thứ nhất có thể áp dụng cho bài toán thứ hai. Tuy nhiên, việc xác định “đủ giống nhau” là một vấn đề không hoàn toàn chính xác. Nói chung, điều này phụ thuộc vào mức độ mô hình ban đầu đã được tinh chỉnh cho miền dữ liệu đầu tiên.
Nếu bài toán mới là một miền con (subdomain) của bài toán ban đầu, thì học chuyển giao là một lựa chọn rất phù hợp. Ví dụ như trường hợp nhận diện giống chó ở trên: nếu bạn muốn học một giống chó cụ thể và đã có một mô hình biết con chó trông như thế nào, thì khả năng cao học chuyển giao sẽ mang lại hiệu quả lớn hơn.
Nếu hai bài toán có hình ảnh trong những ngữ cảnh tương tự, học chuyển giao có thể rất hữu ích. Ví dụ, nếu bạn muốn nhận diện một đối tượng trong ảnh chụp đời thực và đã có một mô hình được huấn luyện trên tập dữ liệu COCO, bạn có thể sử dụng các trọng số từ tập COCO để học bài toán miền dữ liệu mới.
Nếu bài toán mới là phần mở rộng của bài toán cũ, học chuyển giao cũng sẽ phát huy tác dụng. Ví dụ, nếu bạn huấn luyện một mô hình với 5.000 hình ảnh và sau đó thu thập thêm 3.000 hình ảnh, bạn có thể sử dụng các trọng số từ mô hình đầu tiên (5.000 ảnh) cho mô hình thứ hai (3.000 ảnh). Ta có thể kỳ vọng mô hình sẽ tiếp tục cải thiện hiệu suất ở mức độ nhất định.
>> Tìm hiểu thêm: Data Annotation Platforms: Nền tảng gán nhãn dữ liệu cho thị giác máy tính tốt nhất
Cơ chế hoạt động của học chuyển giao trong thị giác máy tính
Đặt trường hợp thực tế: Làm thế nào mà một mô hình có thể nhận diện mèo và chó lại có thể được sử dụng để nhận diện hươu cao cổ và voi?
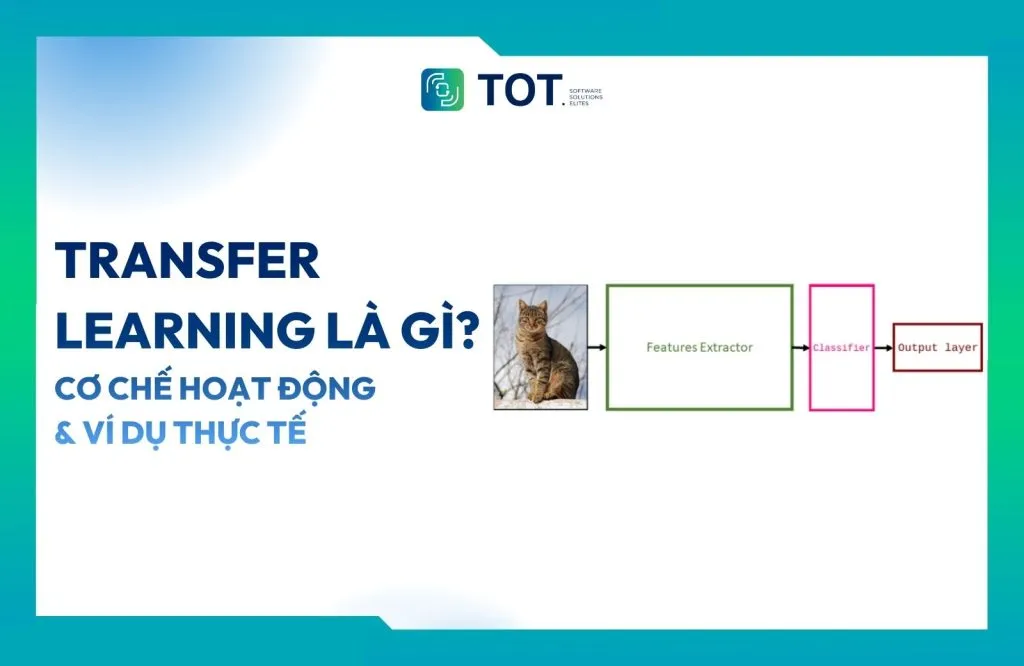
Các mạng nơ-ron tích chập (Convolutional Neural Network – CNN) trích xuất đặc trưng từ hình ảnh ở nhiều mức độ. Các lớp đầu tiên của CNN học cách nhận diện các đặc trưng chung như cạnh dọc, các lớp tiếp theo học cạnh ngang, sau đó các đặc trưng này được kết hợp để nhận diện các góc, hình tròn,…
Những đặc trưng cấp cao này không phụ thuộc vào loại thực thể cụ thể cần nhận diện. Các mô hình thị giác máy tính không chỉ “học” chính xác một đối tượng trông như thế nào (ví dụ: con mèo). Thay vào đó, mô hình phân tách hình ảnh thành các thành phần nhỏ và học cách những thành phần đó kết hợp lại để tạo nên các đặc trưng gắn liền với một khái niệm cụ thể.
Việc nhận diện thực thể (trong trường hợp này là động vật) diễn ra ở các lớp tuyến tính (linear layers), nơi nhận đầu vào là các đặc trưng được trích xuất từ các lớp tích chập và học cách phân loại vào lớp cuối cùng (hươu cao cổ hoặc voi).
Để áp dụng học chuyển giao, chúng ta loại bỏ các lớp tuyến tính của mô hình đã được huấn luyện sẵn (vì các lớp này được huấn luyện để nhận diện các lớp khác) và thêm vào các lớp mới. Sau đó, huấn luyện lại các lớp mới này sao cho chúng chuyên biệt trong việc nhận diện các lớp mà chúng ta quan tâm.
Cách áp dụng học chuyển giao
Để áp dụng học chuyển giao, trước tiên hãy chọn một mô hình đã được huấn luyện trên một tập dữ liệu lớn để giải quyết một bài toán tương tự. Một phương pháp phổ biến là sử dụng các mô hình nổi tiếng trong tài liệu thị giác máy tính như VGG, ResNet và MobileNet.
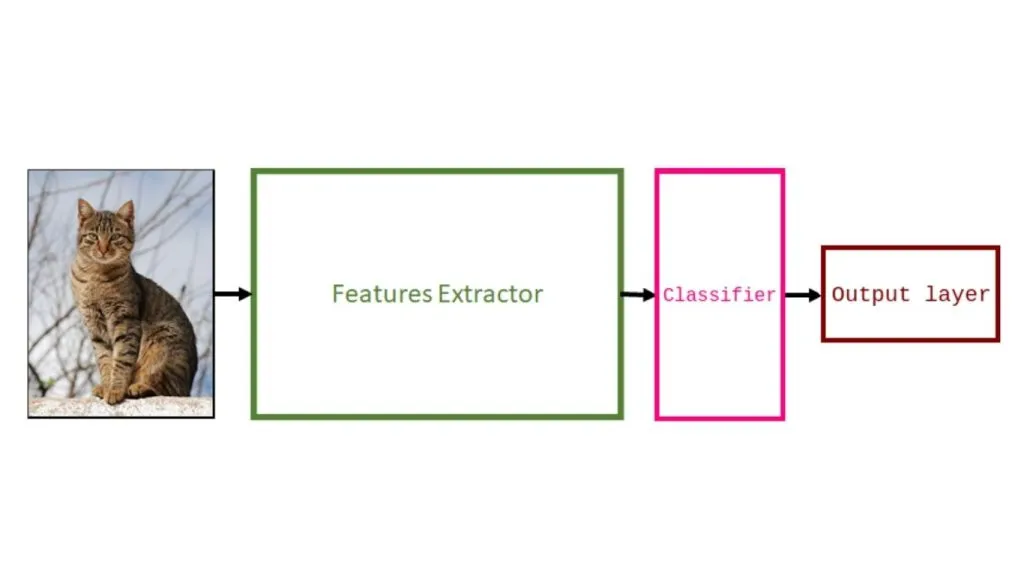
Tiếp theo, loại bỏ bộ phân loại (classifier) và lớp đầu ra (output layer) cũ.
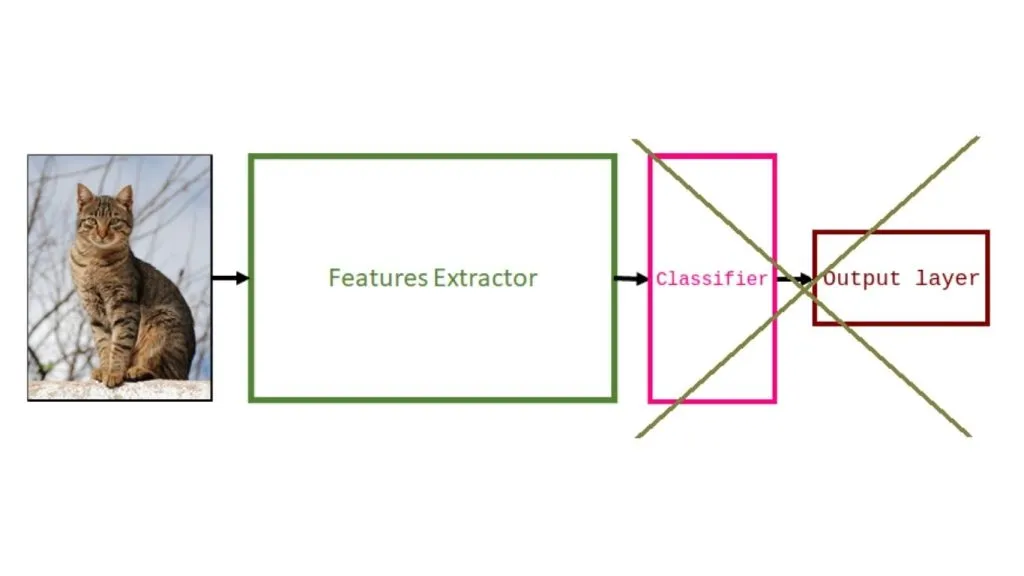
Sau đó, thêm một bộ phân loại mới. Bước này bao gồm việc điều chỉnh kiến trúc để giải quyết tác vụ mới. Thông thường, giai đoạn này là thêm một lớp tuyến tính mới, được khởi tạo ngẫu nhiên (được biểu diễn bằng khối màu xanh lam bên dưới) và một lớp khác với số neuron bằng số lượng lớp trong tập dữ liệu của bạn (được biểu diễn bằng khối màu hồng).
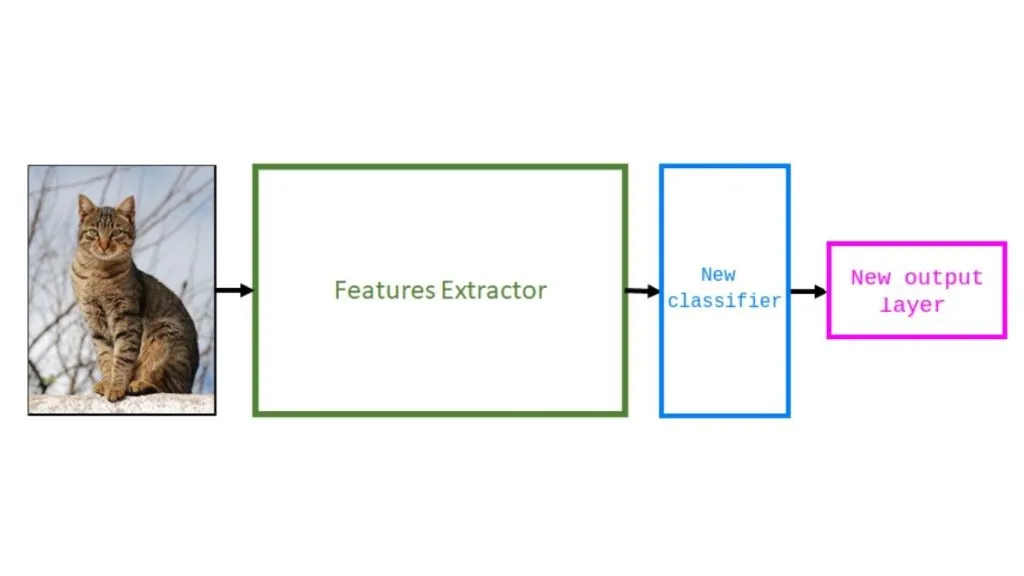
Tiếp theo, cần đóng băng các lớp trích xuất đặc trưng (feature extractor) từ mô hình đã được huấn luyện sẵn. Đây là một bước rất quan trọng vì nếu bạn không đóng băng các lớp này, mô hình sẽ khởi tạo lại chúng. Nếu điều này xảy ra thì toàn bộ kiến thức mô hình đã học trước đó sẽ bị mất, không khác gì việc huấn luyện mô hình từ đầu.
Bước cuối cùng là huấn luyện các lớp mới. Bạn chỉ cần huấn luyện bộ phân loại mới trên tập dữ liệu mới.
Sau khi hoàn thành các bước trên, bạn sẽ có một mô hình có thể đưa ra dự đoán trên tập dữ liệu của mình. Ngoài ra, bạn có thể cải thiện hiệu suất thông qua tinh chỉnh. Tinh chỉnh là quá trình giải phóng một phần các lớp của mô hình đã được huấn luyện sẵn và tiếp tục huấn luyện trên tập dữ liệu mới để dữ liệu mới có thể thích ứng các tính năng đã được huấn luyện trước đó. Để tránh việc quá khớp, bạn chỉ nên thực hiện bước này khi tập dữ liệu mới đủ lớn và sử dụng tốc độ học thấp hơn.
>> Tìm hiểu thêm:
Trường hợp nên và không nên học chuyển giao
Để hiểu rõ hơn về học chuyển giao (transfer learning), chúng ta hãy cùng thảo luận những trường hợp nên sử dụng và những tình huống không nên áp dụng phương pháp này trong thực tế.
Trường hợp nên học chuyển giao
Nên sử dụng học chuyển giao khi bạn thuộc các điều kiện sau:
- Lượng dữ liệu hạn chế: Khi làm việc với lượng dữ liệu quá ít, mô hình học máy thường cho hiệu suất kém và khó đạt độ chính xác mong muốn. Trong trường hợp này, việc sử dụng mô hình đã được huấn luyện sẵn sẽ giúp tạo ra các mô hình chính xác hơn. Đồng thời, quá trình triển khai mô hình cũng diễn ra nhanh hơn vì bạn không cần phải dành thêm thời gian để thu thập dữ liệu mới.
- Bị giới hạn thời gian: Huấn luyện một mô hình học máy từ đầu có thể tiêu tốn rất nhiều thời gian. Khi bạn không có nhiều thời gian, chẳng hạn như cần xây dựng một nguyên mẫu để xác thực ý tưởng, việc cân nhắc sử dụng học chuyển giao là một lựa chọn hợp lý và đáng xem xét.
- Khả năng tính toán hạn chế: Việc đào tạo mô hình học máy với hàng triệu hình ảnh yêu cầu nguồn tài nguyên tính toán rất lớn. Tuy nhiên, với học chuyển giao, phần công việc nặng nề này đã được thực hiện sẵn thông qua các mô hình được huấn luyện trước. Bạn có thể tận dụng bộ trọng số đã được tối ưu hóa để áp dụng cho tác vụ của mình, từ đó giảm đáng kể nhu cầu về tài nguyên tính toán và thiết bị cần thiết trong quá trình huấn luyện mô hình.
Trường hợp không nên học chuyển giao
Ngược lại, học chuyển giao không phù hợp khi:
- Miền dữ liệu không tương thích: Trong hầu hết các trường hợp, học chuyển giao không hiệu quả nếu dữ liệu huấn luyện của mô hình có sẵn quá khác biệt so với dữ liệu dùng để học chuyển giao. Hai tập dữ liệu cần tương đồng về nội dung dự đoán (ví dụ: huấn luyện bộ phân loại lỗi sản phẩm dựa trên tập dữ liệu chứa các sản phẩm tương tự có chú thích vết xước và vết lõm).
- Cần sử dụng tập dữ liệu rất lớn: Học chuyển giao có thể không mang lại hiệu quả như mong đợi với các bài toán yêu cầu tập dữ liệu lớn. Khi lượng dữ liệu tăng lên, hiệu suất của mô hình huấn luyện sẵn có thể giảm do độ nhiễu tăng. Mô hình có thể bị “kẹt” ở điểm cực tiểu cục bộ và không thích nghi tốt với dữ liệu mới. Trong trường hợp này, nên cân nhắc huấn luyện mô hình từ đầu để mô hình có thể học các đặc trưng cốt lõi trực tiếp từ tập dữ liệu của bạn.
>> Tham khảo thêm:
- Visual Question Answering là gì? Mô hình và Phương pháp hoạt động
- Inference In Computer Vision: Suy luận trong thị giác máy tính là gì?
Mức độ tương đồng giữa các chủ đề quan trọng như thế nào đối với học chuyển giao?
Việc sử dụng học chuyển giao để khởi tạo mô hình thị giác máy tính từ các trọng số đã được huấn luyện sẵn thay vì huấn luyện từ đầu (khởi tạo ngẫu nhiên) đã được chứng minh là giúp tăng hiệu suất và giảm thời gian huấn luyện. Điều này hoàn toàn hợp lý, bởi khi cung cấp cho mô hình kiến thức nền tảng về các khái niệm cơ bản như đường thẳng, đường cong, kết cấu bề mặt và các “đối tượng” nói chung, mô hình sẽ có khả năng học nhanh hơn về những đối tượng cụ thể trong tập dữ liệu tùy chỉnh.
Tuy nhiên, một câu hỏi thường được đặt ra là: liệu học chuyển giao có luôn mang lại kết quả tốt hơn so với việc huấn luyện mô hình từ đầu với khởi tạo ngẫu nhiên hay không? Điều gì sẽ xảy ra nếu miền dữ liệu ban đầu hoàn toàn khác với miền dữ liệu mới? Và yếu tố nào quan trọng hơn: việc mô hình ban đầu được huấn luyện trên dữ liệu có mức độ tương đồng cao, hay việc nó được huấn luyện trên một tập dữ liệu cực kỳ lớn?
Để làm rõ những vấn đề này, một thí nghiệm đã được thực hiện nhằm tìm ra câu trả lời.
The Task
Một tập dữ liệu về việc đeo khẩu trang (Mask Wearing dataset) được lựa chọn làm đối tượng thử nghiệm, nhằm quan sát ảnh hưởng của việc sử dụng các checkpoint khởi tạo khác nhau đến hiệu suất của các mô hình phát hiện đối tượng (Object Detection).

>> Tham khảo thêm:
- Object Detection Models: Các mô hình phát hiện đối tượng tốt nhất
- Phát hiện đối tượng trong video
Thiết lập thí nghiệm
YOLOv5 được lựa chọn làm kiến trúc mô hình cho các thử nghiệm này. Mô hình đã được chứng minh là có khả năng khái quát hóa tốt và hỗ trợ học chuyển giao. Quan trọng hơn, YOLOv5 dễ sử dụng, cho phép huấn luyện toàn bộ các mô hình cần thiết cho thí nghiệm chỉ trong một ngày. Quá trình huấn luyện YOLOv5 trên tập dữ liệu tùy chỉnh được thực hiện theo hướng dẫn này, nhằm huấn luyện cả các checkpoint khởi tạo ban đầu lẫn các mô hình cuối cùng.
Phiên bản YOLOv5s được sử dụng với các thiết lập mặc định, bao gồm kích thước đầu vào 640×640 và các kỹ thuật tăng cường dữ liệu (augmentations) tích hợp sẵn. Các mô hình được thiết lập huấn luyện cho đến khi giá trị loss trên tập validation không còn cải thiện trong 50 epoch liên tiếp. Trên thực tế, quá trình này mất khoảng 1 giờ trên GPU V100 và mức độ chênh lệch giữa các lần huấn luyện là không đáng kể.
>> Xem thêm: Tìm hiểu về các phiên bản và quá trình phát triển của mô hình YOLO
Các điểm khởi tạo cho học chuyển giao
Sau đây là bốn mô hình được huấn luyện từ bốn checkpoint khác nhau trên tập dữ liệu Mask Wearing, sau đó tiến hành so sánh hiệu suất giữa chúng. Các điểm khởi tạo được lựa chọn bao gồm:
Trọng số khởi tạo ngẫu nhiên
Được sử dụng nhằm thiết lập một mức chuẩn trong trường hợp không áp dụng học chuyển giao. Đây là thiết lập mặc định khi không truyền vào bất kỳ bộ trọng số nào để sử dụng làm checkpoint khởi tạo.
Microsoft COCO
Đây là tiêu chuẩn phổ biến trong học chuyển giao, được huấn luyện trên hàng triệu hình ảnh chứa rất nhiều loại đối tượng quen thuộc khác nhau. Đáng chú ý, khuôn mặt (faces) không phải là một trong các lớp của COCO, do đó mặc dù mô hình có kiến thức nền rộng về các khái niệm tổng quát, nó không sở hữu kiến thức nào đặc biệt liên quan trực tiếp đến tác vụ phát hiện khẩu trang.
WIDER FACE
Một tập dữ liệu gồm 16.000 hình ảnh có gán nhãn khuôn mặt. Tập dữ liệu này được lựa chọn một cách có chủ đích vì có mức độ tương đồng cao với tác vụ phát hiện việc đeo khẩu trang. Mô hình trước hết cần xác định khuôn mặt để có thể suy ra liệu chúng có đang đeo khẩu trang hay không.
Mối quan tâm chính ở đây là liệu mức độ đặc thù cao hơn của kiến thức nền có bù đắp được thực tế rằng mô hình này chỉ được huấn luyện trên số lượng hình ảnh ít hơn khoảng 100 lần so với mô hình được huấn luyện trên COCO hay không.
BCCD
Một tập dữ liệu gồm các hình ảnh tế bào máu được chụp từ kính hiển vi. Tập dữ liệu này được lựa chọn như một ví dụ mang tính đối nghịch rõ rệt, bởi nội dung của nó gần như xa nhất có thể so với bài toán phát hiện khẩu trang trên khuôn mặt.
Việc đưa tập dữ liệu này vào nhằm kiểm tra liệu học chuyển giao có luôn mang lại lợi ích (hoặc ít nhất là không gây tác động tiêu cực), hay trong một số trường hợp, nó có thể làm suy giảm hiệu suất do mô hình bị “khóa chặt” bởi các thiên lệch từ kiến thức đã học trước đó.
>> Xem thêm:
- Xây dựng ứng dụng phát hiện đối tượng bằng Python chỉ trong vài phút với Roboflow
- Phát hiện chuyển động bằng thị giác máy tính – Cách hoạt động và logic phát hiện
Kết quả
Kết quả trên tập dữ liệu kiểm tra được giữ lại như sau:
| Điểm khởi tạo | mAP ban đầu | mAP | Độ chính xác (Precision) | Độ bao phủ (Recall) |
| Ngẫu nhiên | N/A | 76,9% | 33,1% | 84,7% |
| COCO | 55,8% | 83,6% | 50,8% | 90,0% |
| WIDER Face | 65,6% | 87,5% | 64,3% | 88,3% |
| BCCD | 90,9% | 75,9% | 41,6% | 83,0% |
Nguồn: Roboflow
Việc hình dung ý nghĩa thực tế của các con số này không hề dễ, vì vậy dưới đây là ví dụ dự đoán từ mỗi mô hình đã huấn luyện trên hai hình ảnh trong tập kiểm tra (hiển thị ở mức độ tin cậy 50%).

Trong các ví dụ này, có thể thấy rằng các mô hình khởi tạo từ huấn luyện từ đầu, BCCD và COCO đã bỏ sót hoàn toàn một số khẩu trang (người quay mặt sang phải trong ảnh đầu tiên và mô hình BCCD bỏ sót hoàn toàn một người trong ảnh thứ hai), trong khi mô hình khởi tạo từ WIDER FACE cho kết quả tốt hơn.
Tuy nhiên, cũng có những trường hợp mô hình COCO hoạt động tốt hơn. Đáng chú ý, mô hình dựa trên COCO có thể nhận diện khẩu trang trong một bức ảnh mà người đàn ông đeo khẩu trang che kín toàn bộ khuôn mặt, trong khi mô hình dựa trên WIDER FACE thì không nhận diện được.

Kết luận từ thí nghiệm
Checkpoint mà bạn chọn làm điểm khởi tạo cho học chuyển giao có ảnh hưởng trực tiếp đến chất lượng của mô hình cuối cùng. Việc chọn một checkpoint gần với bài toán thực tế sẽ cho kết quả tốt hơn, ngay cả khi checkpoint đó được huấn luyện trên ít hình ảnh hơn. Ngược lại, việc chọn một checkpoint không phù hợp thậm chí có thể kém hơn cả việc khởi tạo ngẫu nhiên, dù mức độ suy giảm thường không quá lớn.
>>> Có thể bạn quan tâm:
- Mô hình ngôn ngữ thị giác là gì? Các mô hình phổ biến hiện nay
- Các công cụ thị giác máy tính không cần code hàng đầu năm 2026
- Phân tích hình ảnh bằng AI là gì? Cách AI hiểu và diễn giải hình ảnh
Kết luận: Những điểm rút ra từ học chuyển giao trong thị giác máy tính
Học chuyển giao trong thị giác máy tính tập trung vào việc lưu trữ và tái sử dụng kiến thức thu được từ một bài toán để áp dụng cho một bài toán khác có liên quan. Thay vì huấn luyện mạng nơ-ron (neural network) từ đầu, các mô hình đã được huấn luyện sẵn có thể được sử dụng làm điểm khởi tạo, giúp rút ngắn thời gian huấn luyện và tiết kiệm đáng kể tài nguyên tính toán.
Trong thực tế, học chuyển giao đặc biệt phù hợp khi lượng dữ liệu huấn luyện còn hạn chế, thời gian triển khai ngắn, hoặc khả năng tính toán bị giới hạn. Ngược lại, phương pháp này không phải lúc nào cũng là lựa chọn tối ưu, nhất là khi miền dữ liệu của bài toán mới quá khác biệt so với dữ liệu mà mô hình đã được huấn luyện trước đó, hoặc khi bạn sở hữu một tập dữ liệu rất lớn đủ để huấn luyện mô hình từ đầu.
Trong hai trường hợp này, việc huấn luyện mô hình từ đầu thường mang lại kết quả tốt hơn và giúp mô hình học được các đặc trưng phù hợp hơn với bài toán cụ thể. Với những kiến thức đã được tổng hợp, hy vọng bạn đã có cái nhìn đầy đủ về transfer learning là gì, cũng như biết rõ khi nào nên và không nên áp dụng kỹ thuật này trong thị giác máy tính. Chúc bạn xây dựng và triển khai mô hình thành công.
>>> Nguồn tham khảo: What Is Transfer Learning?
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.