Trong lĩnh vực thị giác máy tính hiện đại, mô hình ngôn ngữ thị giác và phát hiện đối tượng đang trở thành hai hướng tiếp cận quan trọng nhưng rất khác biệt. Trong khi mô hình phát hiện đối tượng mạnh về tốc độ, tính xác định và khả năng xử lý thời gian thực. Thì mô hình ngôn ngữ thị giác lại nổi bật với khả năng suy luận ngữ cảnh và hiểu đa phương thức.
Vậy đâu mới là lựa chọn phù hợp cho hệ thống của bạn? Bài viết dưới đây từ TOT sẽ giúp bạn phân tích rõ ưu – nhược điểm và đưa ra quyết định dựa trên các yếu tố thực tiễn trong môi trường sản xuất.
>>> Tìm hiểu thêm:
- Các công cụ thị giác máy tính không cần code hàng đầu
- Những trình soạn thảo mã cho thị giác máy tính tốt nhất
- Đếm Đối Tượng Bằng Thị Giác Máy Tính
- Hướng dẫn cách sử dụng Google AI Studio hiệu quả, nhanh chóng
Tìm hiểu về mô hình ngôn ngữ thị giác và phát hiện đối tượng
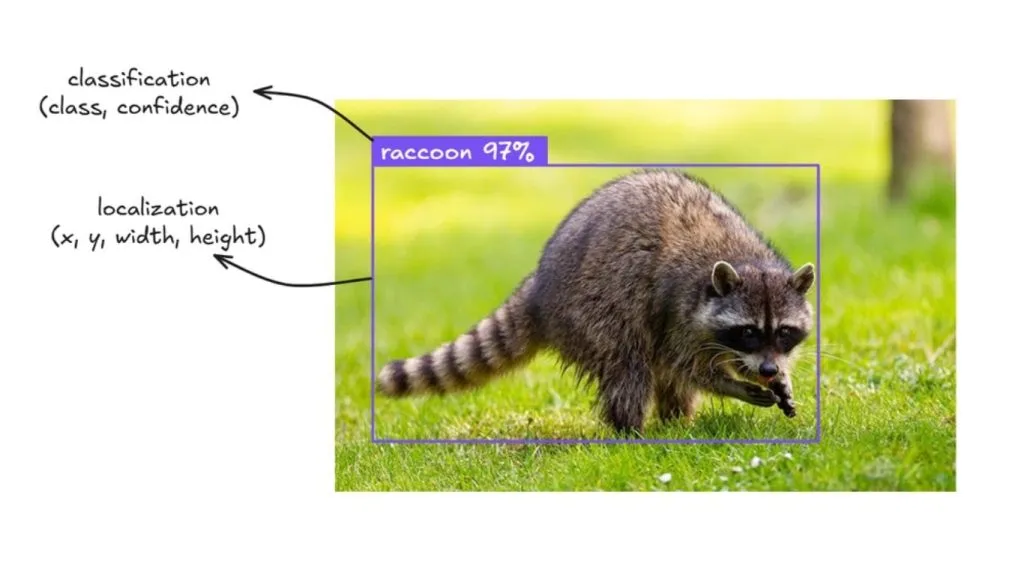
Các mô hình phát hiện đối tượng (Object Detective Models) là các mạng nơ-ron chuyên biệt được huấn luyện để nhận diện và định vị vị trí của các đối tượng cụ thể trong hình ảnh. Các kiến trúc phổ biến bao gồm mô hình YOLO (You Only Look Once), Faster R-CNN, EfficientDet và các mô hình mới hơn như RF-DETR. Những mô hình này xuất ra các hộp giới hạn, kèm theo nhãn lớp và điểm tin cậy. Cách chúng hoạt động: Bạn đưa một hình ảnh vào mô hình, và nó trả về dữ liệu có cấu trúc như sau:
"predictions": [
{
"x": 36,
"y": 65,
"width": 436,
"height": 269,
"confidence": 0.92,
"class": "raccoon",
"class_id": 1,
"detection_id": "c929d3d0-b78f-4064-96a9-9f072df7ca34"
}
]
Ví dụ, khi sử dụng RF-DETR, bạn có thể triển khai một mô hình được huấn luyện tùy chỉnh để xử lý hình ảnh và trả về các hộp giới hạn chính xác trong vài mili giây. Các mô hình này mang tính xác định, nghĩa là cùng một hình ảnh sẽ cho ra kết quả gần như giống hệt nhau sau mỗi lần chạy.
Các mô hình ngôn ngữ thị giác là các hệ thống AI đa phương thức có khả năng hiểu cả hình ảnh và văn bản. Chúng có thể trả lời câu hỏi về hình ảnh, mô tả cảnh vật và thực hiện tác vụ thông qua các chỉ dẫn bằng ngôn ngữ tự nhiên. Ví dụ bao gồm GPT-5, Claude, Google Gemini, Florence-2 và LLaVA.
>> Xem thêm: Khả năng thị giác của Chat GPT-5 và Cách Prompt hiệu quả

Cách chúng hoạt động:
Bạn cung cấp một hình ảnh và một câu lệnh văn bản (text prompt). Với các tác vụ mô tả, bạn có thể hỏi “con vật nào trong hình ảnh?” và mô hình sẽ trả lời bằng ngôn ngữ tự nhiên:
“Con vật được hiển thị trong hình ảnh là một con gấu mèo.”
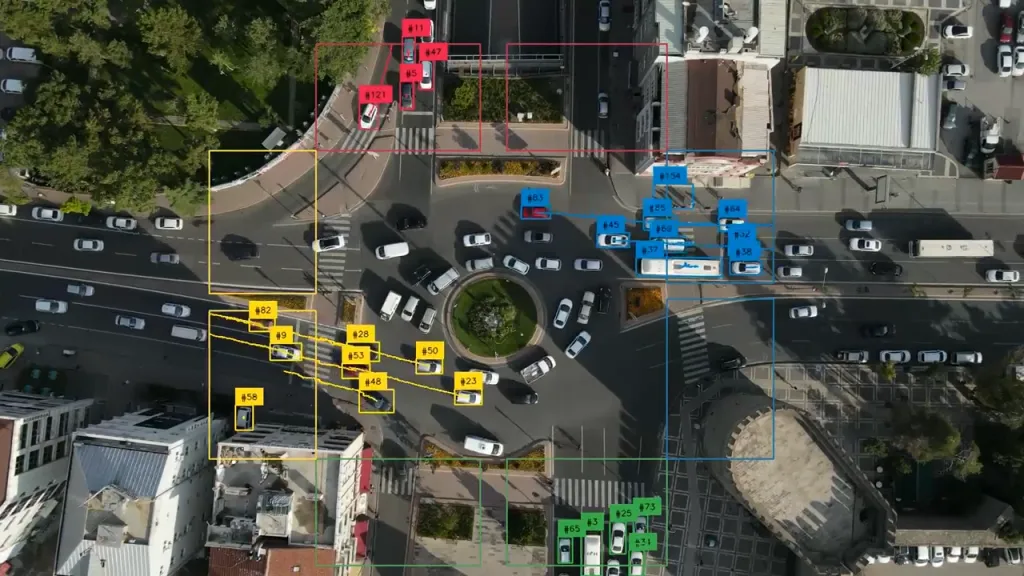
Điều thú vị là một số mô hình ngôn ngữ thị giác như Google Gemini 3 Pro cũng có thể tìm và định vị đối tượng bằng các hộp giới hạn khi được yêu cầu cụ thể. Ví dụ, trong Playground của Roboflow, hãy thử tải lên một hình ảnh để phát hiện đối tượng, và bạn có thể thấy đầu ra tương tự như sau:
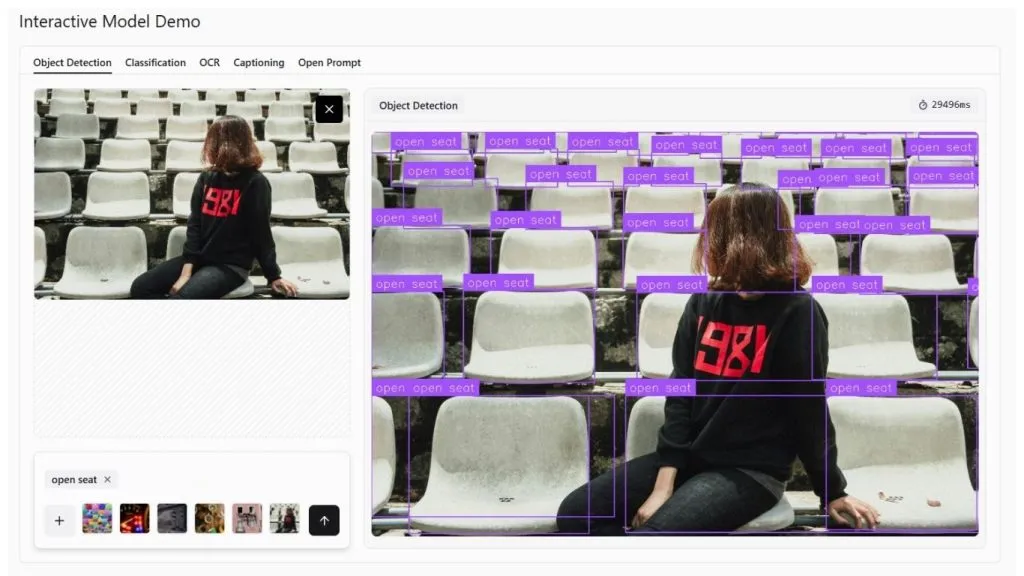
Tuy nhiên, các mô hình ngôn ngữ thị giác thường không mang tính xác định, đôi khi có thể đưa ra các câu trả lời hơi khác nhau cho cùng một câu lệnh trong nhiều lần chạy.
>> Tìm hiểu thêm:
- Object Detection là gì? Cách hoạt động & Ứng dụng trong thực tế
- Neural Network là gì? Tổng quan về mạng nơ-ron nhân tạo
- AI Data Labeling: Hướng dẫn gán nhãn dữ Liệu AI
Khung ra quyết định
Việc lựa chọn giữa phát hiện đối tượng và mô hình ngôn ngữ thị giác là một quyết định thực tiễn. Điều này phụ thuộc vào cách hệ thống của bạn cần vận hành, mà không phụ thuộc vào mô hình nào mới hơn hay phổ biến hơn. Dưới đây, chúng ta sẽ xem qua các yếu tố chính cần xem xét khi đưa ra quyết định.
Yếu tố 1: Các danh mục đối tượng của bạn có được biết trước và cố định không?
Đây có lẽ là câu hỏi quan trọng nhất.
Chọn Phát hiện Đối tượng nếu:
- Bạn biết chính xác những gì cần phát hiện (ví dụ: “người đi bộ”, “phương tiện”, “biển báo giao thông”)
- Các danh mục của bạn sẽ không thay đổi thường xuyên
- Bạn làm việc trong một lĩnh vực được xác định rõ với các đối tượng tiêu chuẩn
- Bạn cần phát hiện lặp đi lặp lại cùng một đối tượng ở quy mô lớn
Hãy xem xét một ví dụ: một dây chuyền đóng gói dược phẩm sử dụng RF-DETR để phát hiện các thành phần cụ thể như chai, nắp, nhãn và hộp. Các thành phần đóng gói được tiêu chuẩn hóa và sẽ không thay đổi trong nhiều năm. Hệ thống xử lý 100 chai mỗi phút, phát hiện nắp bị thiếu hoặc nhãn lệch với độ chính xác 99,5%. Các danh mục là cố định, khối lượng cao và tính nhất quán là yếu tố then chốt để tuân thủ quy định.
Chọn Mô hình Ngôn ngữ thị giác (VLM) nếu:
- Bạn cần sự linh hoạt để đặt nhiều câu hỏi khác nhau về hình ảnh
- Yêu cầu của bạn có thể thay đổi mà không cần huấn luyện lại
- Bạn đang xử lý các đối tượng hiếm hoặc thuộc nhóm từ khoá dài (long-tail)
- Bạn cần hiểu đa phương thức (nhận diện đối tượng + OCR (Optical Character Recognition) + mối quan hệ không gian + ngữ cảnh)
Ví dụ:
Một cơ sở chế biến thực phẩm sử dụng Google Gemini để kiểm tra chất lượng các sản phẩm bánh nướng. Mô hình ngôn ngữ thị giác cần phải: Nhận diện các loại sản phẩm thay đổi theo mùa, đọc số lô in và ngày hết hạn, xác định nhiều loại lỗi khác nhau, hiểu các vấn đề theo ngữ cảnh như “chiếc bánh quy này quá sậm màu đối với bánh quy đường nhưng chấp nhận được đối với bánh quy socola chip”, và định vị các lỗi cụ thể bằng hộp giới hạn để phục vụ tài liệu hóa.
Yếu tố 2: Yêu cầu về Độ trễ
Độ trễ rất quan trọng trong nhiều hệ thống thị giác, và hai cách tiếp cận này có hành vi rất khác nhau về hiệu năng và thời gian phản hồi.
Hiệu năng của Phát hiện Đối tượng:
Các mô hình phát hiện đối tượng được xây dựng để đạt tốc độ cao và độ trễ thấp.
Chúng có thể:
- Xử lý video theo thời gian thực
- Trả về kết quả với độ trễ rất nhỏ sau khi hình ảnh được chụp
- Chạy trực tiếp trên các thiết bị biên (edge devices) như camera hoặc hệ thống nhúng
Vì mỗi khung hình được xử lý nhanh và quyết định được đưa ra gần như ngay lập tức, phát hiện đối tượng hoạt động tốt trong các hệ thống cần phản hồi tức thì.
Ví dụ, một nhà máy ô tô sử dụng mô hình phát hiện đối tượng để kiểm tra các điểm hàn trên khung xe đang di chuyển trên băng chuyền. Các camera chụp hình liên tục khi xe đi qua dây chuyền sản xuất. Mỗi khung hình được phân tích gần như ngay sau khi được ghi lại.
Nếu phát hiện lỗi hàn, hệ thống sẽ phát cảnh báo ngay lập tức. Độ trễ thấp này cho phép dây chuyền sản xuất dừng lại trước khi bộ phận lỗi chuyển sang trạm tiếp theo. Các mô hình chậm hơn, phân tích từng hình ảnh một sẽ gây ra độ trễ và có nguy cơ bỏ lỡ những thời điểm quan trọng.
Đối với các ứng dụng như lái xe tự động, phân tích video theo thời gian thực, robotics hoặc kiểm tra công nghiệp tốc độ cao, phát hiện đối tượng là lựa chọn thực tiễn vì nó cung cấp cả tốc độ xử lý nhanh và phản hồi tức thì.
>> Xem thêm: Phát hiện đối tượng trong video với RF-DETR
Hiệu năng của Mô hình ngôn ngữ thị giác:
Các mô hình ngôn ngữ thị giác được thiết kế cho phân tích sâu, không phải cho độ trễ thấp. Cụ thể hiệu năng của Mô hình ngôn ngữ thị giác:
- Mất nhiều thời gian hơn để xử lý từng hình ảnh
- Có thời gian phản hồi cao hơn từ lúc chụp ảnh đến khi có kết quả
- Yêu cầu nhiều tài nguyên tính toán hơn, thường ở trên đám mây
Độ trễ cao hơn này khiến chúng không phù hợp với luồng video thời gian thực. Thay vào đó, chúng hoạt động tốt nhất trong xử lý theo lô hoặc quy trình có sự tham gia của con người, nơi việc chờ vài giây cho mỗi hình ảnh có thể chấp nhận được.
Ví dụ, một nhà máy dệt may sử dụng mô hình ngôn ngữ thị giác để kiểm tra cuối cùng quần áo trước khi xuất xưởng. Hình ảnh sản phẩm hoàn thiện được chụp và gửi đến mô hình cùng với hướng dẫn kiểm tra các lỗi như chỉ thừa, vết bẩn, sai lệch màu sắc hoặc lỗi đường may.
Quá trình phân tích mất vài giây cho mỗi hình ảnh, nhưng độ trễ không phải là vấn đề ở giai đoạn này. Mô hình cung cấp các quan sát chi tiết giúp nhân viên kiểm tra đưa ra quyết định cuối cùng. Vì đây không phải là quy trình yêu cầu thời gian gấp, nên phản hồi chậm hơn vẫn có thể chấp nhận được.
>> Xem thêm:
- Phát hiện chuyển động bằng thị giác máy tính – Cách hoạt động và logic phát hiện
- Các mô hình ngôn ngữ thị giác chạy cục bộ tốt nhất
Yếu tố 3: Đánh đổi giữa độ chính xác và tính xác định
Yếu tố này nhấn mạnh sự khác biệt quan trọng trong cách các mô hình này hoạt động trong hệ thống thực tế. Vấn đề không chỉ là mô hình chính xác đến mức nào, mà còn là mức độ nhất quán khi nó tạo ra cùng một kết quả.
Phát hiện đối tượng:
Các mô hình phát hiện đối tượng có tính nhất quán đáng kinh ngạc. Chạy cùng một hình ảnh qua mô hình 100 lần, bạn sẽ nhận được kết quả gần như giống hệt nhau. Tính xác định này rất hữu ích đối với:
- Hệ thống kiểm soát chất lượng tự động
- Ứng dụng pháp lý hoặc tuân thủ yêu cầu khả năng tái tạo
- Các hệ thống mà tính nhất quán quan trọng hơn tính linh hoạt
Tuy nhiên, độ chính xác của chúng bị giới hạn bởi dữ liệu huấn luyện. Một mô hình phát hiện đối tượng được huấn luyện trên 80 danh mục từ bộ dữ liệu COCO sẽ không bao giờ phát hiện được danh mục thứ 81 nếu không huấn luyện lại. Nó có thể phân loại sai các đối tượng chưa biết thành danh mục đã biết gần nhất, dẫn đến các dự đoán sai.
Ví dụ, một nhà máy đóng chai đồ uống sử dụng RF-DETR để phát hiện mức chiết rót. Mô hình được huấn luyện với ba lớp: “chiết rót đúng chuẩn”, “chiết rót thiếu” và “chiết rót quá mức”. Trong hơn 10.000 lần chạy, nó tạo ra các hộp giới hạn và phân loại giống hệt nhau cho cùng một hình ảnh chai – điều này rất quan trọng để đáp ứng yêu cầu tài liệu theo quy định. Kiểm toán viên có thể xác minh rằng hệ thống đưa ra các quyết định nhất quán. Tuy nhiên, khi một thiết kế chai mới được giới thiệu, mô hình phải được huấn luyện lại.
Mô hình ngôn ngữ thị giác (VLM):
Các mô hình ngôn ngữ thị giác thường cung cấp khả năng hiểu phong phú và linh hoạt hơn, nhưng đầu ra của chúng kém nhất quán hơn.
Mô hình ngôn ngữ thị giác có thể:
- Hiểu ngữ cảnh và mối quan hệ trong hình ảnh
- Mô tả các đối tượng hiếm hoặc bất thường mà chúng chưa được huấn luyện cụ thể
- Đọc văn bản trong hình ảnh
- Giải thích vì sao điều gì đó trông có vẻ sai
- Xử lý các tình huống không rõ ràng hoặc mơ hồ
Chúng thậm chí có thể phát hiện các lỗi chưa từng thấy trước đó và đánh dấu vị trí xuất hiện của vấn đề. Sự đánh đổi ở đây là tính xác định. Cùng một hình ảnh có thể tạo ra mô tả hoặc hộp giới hạn hơi khác nhau qua nhiều lần chạy. Các mô hình ngôn ngữ thị giác đôi khi cũng có thể báo cáo những thứ thực tế không tồn tại.
Ví dụ, một nhà sản xuất thiết bị điện tử sử dụng mô hình ngôn ngữ thị giác để kiểm tra bảng mạch in (PCB – Printed Circuit Board). Mô hình kiểm tra linh kiện bị thiếu, lỗi hàn, linh kiện sai bằng cách đọc nhãn và các lỗi bất thường.
VLM có thể phát hiện các vấn đề ngoài dự kiến như mảnh vụn hoặc vết xước nhỏ, đồng thời đánh giá ngữ cảnh, chẳng hạn liệu một lỗi có nghiêm trọng hay có thể chấp nhận được. Kết quả có thể thay đổi nhẹ giữa các lần chạy, nhưng điều này chấp nhận được vì có con người xem xét lại các phát hiện. Trong trường hợp này, tính linh hoạt có giá trị hơn sự nhất quán tuyệt đối.
>> Tham khảo thêm:
- AI nhận diện ảnh là gì? Thuật toán và ứng dụng phổ biến
- Phân tích hình ảnh bằng AI là gì? Cách AI hiểu và diễn giải hình ảnh
Yếu tố 4: Cân nhắc về chi phí
Sự khác biệt chi phí lớn nhất giữa phát hiện đối tượng và mô hình ngôn ngữ thị giác nằm ở cách chi phí tăng theo thời gian.
Chi phí của Phát hiện Đối tượng:
Phát hiện đối tượng có phần lớn chi phí ở giai đoạn đầu. Bạn thường phải chi trả sớm cho:
- Thu thập và gán nhãn dữ liệu
- Huấn luyện mô hình
- Thiết lập hạ tầng để vận hành
Sau khi hệ thống được triển khai:
- Việc chạy mô hình có chi phí thấp
- Chi phí trên mỗi hình ảnh duy trì ở mức rất thấp
- Xử lý nhiều hình ảnh hơn không làm chi phí tăng đáng kể
Điều này có nghĩa là phát hiện đối tượng trở nên kinh tế hơn khi khối lượng tăng lên. Khi hệ thống đã được thiết lập, bạn có thể xử lý lượng lớn hình ảnh hoặc video mà chi phí không tăng đáng kể.
Chi phí của Mô hình ngôn ngữ thị giác:
Mô hình ngôn ngữ thị giác hoạt động theo cách khác. Chúng thường:
- Không yêu cầu huấn luyện hoặc thiết lập ban đầu
- Không cần quản lý hạ tầng
- Tính phí theo mỗi hình ảnh hoặc mỗi yêu cầu
Điều này giúp việc bắt đầu rất dễ dàng. Tuy nhiên:
- Mỗi hình ảnh đều phát sinh chi phí
- Xử lý video trở nên tốn kém nhanh chóng
- Chi phí tăng trực tiếp theo mức sử dụng
Các mô hình ngôn ngữ thị giác thường hiệu quả về chi phí ở mức khối lượng thấp hoặc trung bình, nhưng sẽ trở nên đắt đỏ khi sử dụng liên tục hoặc ở quy mô lớn.
Yếu tố 5: Mức độ phức tạp trong phát triển và bảo trì
Khi triển khai thực tế, lượng công việc kỹ thuật và độ phức tạp trong phát triển và bảo trì sẽ khác nhau đáng kể giữa các giải pháp.
Mô hình Phát hiện Đối tượng:
Xây dựng một hệ thống phát hiện đối tượng yêu cầu:
- Thu thập và gán nhãn dữ liệu (thường là nút thắt lớn nhất)
- Lựa chọn mô hình và hạ tầng huấn luyện
- Tinh chỉnh và tối ưu hoá siêu tham số (hyperparameter tuning)
- Thiết lập quy trình triển khai
- Quy trình giám sát và huấn luyện lại
- Quản lý phiên bản mô hình
Điều này thường đòi hỏi một đội ngũ có chuyên môn về học máy (Machine Learning) và mất nhiều thời gian cho lần triển khai ban đầu. Tuy nhiên, sau khi được xây dựng, hệ thống tương đối ổn định.
Mô hình Ngôn ngữ thị giác (VLM):
Sử dụng VLM thông qua API (Application Programming Interface) yêu cầu:
- Tích hợp với nhà cung cấp API (tính bằng giờ, không phải tuần)
- Thiết kế và thử nghiệm câu lệnh (prompt engineering)
- Xử lý lỗi cơ bản
Một nhà phát triển có thể tích hợp VLM vào ứng dụng trong vài ngày. Tuy nhiên, đánh đổi là sự phụ thuộc liên tục vào dịch vụ bên ngoài và ít quyền kiểm soát hơn đối với hành vi của mô hình.
Phương pháp VLM giúp đưa sản phẩm vào môi trường sản xuất nhanh hơn với ít tài nguyên hơn. Tuy nhiên, công ty có thể có ít quyền kiểm soát hơn. Nếu API của VLM thay đổi hành vi hoặc giá cả, họ phải thích nghi. Với mô hình phát hiện đối tượng, họ sở hữu toàn bộ hệ thống.
>> Có thể bạn quan tâm:
- Foundation Model là gì? Các loại mô hình nền tảng và ứng dụng trong AI
- Convolutional Neural Network là gì? Tổng quan về mạng nơ-ron tích chập
- Ứng dụng AI trong bán hàng online: TOP 10 công cụ AI & cách triển khai hiệu quả
Cây quyết định: Cách chọn giữa phát hiện đối tượng và mô hình ngôn ngữ thị giác
Dưới đây là quy trình ra quyết định từng bước.
Bước 1: Bạn có thể liệt kê tất cả các đối tượng cần phát hiện không?
CÓ -> Tiếp tục Bước 2
KHÔNG -> Sử dụng Mô hình Ngôn ngữ Thị giác (VLMs)
Bước 2: Bạn có cần xử lý thời gian thực hoặc gần thời gian thực không?
CÓ -> Sử dụng Phát hiện Đối tượng
KHÔNG -> Tiếp tục Bước 3
Bước 3: Bạn có xử lý hơn 100.000 hình ảnh mỗi tháng không?
CÓ -> Sử dụng Phát hiện Đối tượng (tiết kiệm chi phí hơn)
KHÔNG -> Tiếp tục Bước 4
Bước 4: Đầu ra mang tính xác định có quan trọng đối với ứng dụng của bạn không?
CÓ -> Sử dụng Phát hiện Đối tượng
KHÔNG -> Tiếp tục Bước 5
Bước 5: Bạn có nguồn lực kỹ sư học máy (ML) và thời gian để thiết lập không?
CÓ -> Phát hiện Đối tượng có thể tốt hơn về lâu dài
KHÔNG -> Sử dụng Mô hình Ngôn ngữ Thị giác (VLMs)
Bước 6: Bạn có cần hiểu ngữ cảnh vượt ngoài việc định vị đối tượng không?
CÓ -> Sử dụng Mô hình Ngôn ngữ Thị giác (VLMs)
KHÔNG -> Sử dụng Phát hiện Đối tượng
>>> Xem thêm: Low Code là gì? Giải pháp phát triển phần mềm và xu hướng tương lai
Cách tiếp cận kết hợp (Hybrid): Sử dụng phát hiện đối tượng và mô hình ngôn ngữ thị giác cùng nhau
Đôi khi giải pháp tốt nhất không phải là chọn giữa mô hình ngôn ngữ thị giác và phát hiện đối tượng, mà là sử dụng cả phát hiện đối tượng và mô hình ngôn ngữ thị giác cùng nhau. Dưới đây là ba cách phổ biến và thực tiễn mà các đội ngũ đã áp dụng trong hệ thống thực tế.
Cách 1: Sử dụng phát hiện đối tượng để lọc và VLM để phân tích
Sử dụng phát hiện đối tượng để lọc nhanh hình ảnh, sau đó áp dụng VLM cho các trường hợp đáng chú ý.
Ví dụ: Hệ thống camera an ninh
- Một mô hình phát hiện đối tượng như RF-DETR giám sát luồng video theo thời gian thực.
- Khi một người bước vào khu vực hạn chế, hệ thống chụp một hình ảnh rõ nét.
- Hình ảnh được gửi đến một VLM như Google Gemini.
- VLM kiểm tra ngữ cảnh (ví dụ: “nhân viên bảo trì có đeo thẻ ID hiển thị” so với “cá nhân không xác định”).
- Hệ thống phản hồi dựa trên phân tích này.
Cách 2: Sử dụng VLM để gán nhãn dữ liệu và phát hiện Đối tượng cho sản xuất
Sử dụng VLM để nhanh chóng gán nhãn dữ liệu huấn luyện, sau đó huấn luyện mô hình phát hiện đối tượng cho môi trường sản xuất.
Ví dụ: Phát hiện sản phẩm tùy chỉnh
- Hình ảnh sản phẩm được gán nhãn bằng VLM.
- Các nhãn được chuyển đổi thành dữ liệu huấn luyện.
- Một mô hình phát hiện đối tượng được huấn luyện và triển khai.
Cách 3: Sử dụng phát hiện đối tượng cho tác vụ chính và VLM cho trường hợp ngoại lệ
Xử lý các trường hợp phổ biến bằng phát hiện đối tượng và chuyển các tình huống bất thường sang VLM.
Ví dụ về xử lý tài liệu:
- Phát hiện đối tượng phân loại các tài liệu phổ biến.
- Các trường hợp không chắc chắn được gửi đến VLM để phân tích.
- Các loại tài liệu mới được bổ sung lại vào dữ liệu huấn luyện theo thời gian.
>> Tìm hiểu thêm:
- Top 7 Công Cụ Theo Dõi Đối Tượng Mã Nguồn Mở
- Inference In Computer Vision: Suy luận trong thị giác máy tính là gì?
Những lỗi sai thường gặp cần lưu ý
Việc lựa chọn giữa phát hiện đối tượng và mô hình ngôn ngữ thị giác không chỉ xoay quanh năng lực. Nhiều nhóm gặp vấn đề vì cách họ áp dụng các công cụ này. Dưới đây là một số lỗi phổ biến nhất trong các dự án thực tế và cách tránh chúng.
Sử dụng mô hình ngôn ngữ thị giác cho tác vụ cố định, khối lượng lớn
Mô hình ngôn ngữ thị giác mang lại cảm giác rất mạnh mẽ, nên dễ bị cám dỗ sử dụng chúng ở mọi nơi. Nhưng sử dụng API của VLM để xử lý hàng triệu hình ảnh cho cùng một tập đối tượng cố định thường là một sai lầm. Nếu bạn đang phát hiện lặp đi lặp lại cùng 10 hoặc 20 loại đối tượng, các mô hình phát hiện đối tượng sẽ nhanh hơn, rẻ hơn và đáng tin cậy hơn. Trong những trường hợp này, VLM thường tốn kém hơn nhiều mà không mang lại lợi ích thực sự.
Quá trình thiết kế hệ thống phát hiện đối tượng quá phức tạp cho các yêu cầu thay đổi
Sai lầm ngược lại cũng xảy ra. Một số nhóm dành nhiều tháng xây dựng quy trình phát hiện đối tượng tùy chỉnh cho những bài toán liên tục thay đổi. Nếu danh mục của bạn thay đổi thường xuyên, hoặc bạn không thể xác định rõ chúng ngay từ đầu, phát hiện đối tượng sẽ trở nên chậm và tốn kém để bảo trì. Trong những tình huống này, VLM cho phép lặp lại (iteration) và khám phá nhanh hơn nhiều.
Bỏ qua độ trễ cho đến khi hệ thống đã hoàn thành
Vấn đề về độ trễ rất khó khắc phục sau khi triển khai. Các nhóm đôi khi thiết kế hệ thống xoay quanh VLM và chỉ sau đó mới nhận ra họ cần phản hồi thời gian thực hoặc gần thời gian thực. Các mô hình dựa trên đám mây hiếm khi phù hợp với yêu cầu độ trễ nghiêm ngặt. Các ràng buộc về hiệu năng nên được kiểm tra từ sớm, không phải sau khi kiến trúc đã được cố định.
Kỳ vọng về tính nhất quán hoàn hảo từ mô hình ngôn ngữ thị giác
VLM rất mạnh mẽ, nhưng chúng không mang tính xác định. Cụ thể, cùng một hình ảnh, VLM có thể tạo ra kết quả hơi khác nhau tùy thuộc vào câu lệnh, ngữ cảnh hoặc các bản cập nhật mô hình. Nếu quy trình làm việc của bạn giả định rằng kết quả đầu ra của mỗi lần luôn giống hệt nhau, bạn sẽ sớm gặp phải lỗi ngoài dự kiến. VLM hoạt động tốt nhất khi hệ thống được thiết kế để xử lý sự không chắc chắn.
Quên rằng phát hiện đối tượng cần bảo trì
Các mô hình phát hiện đối tượng ổn định, nhưng không phải “huấn luyện một lần rồi quên”. Thế giới thực luôn thay đổi. Ánh sáng, môi trường, sản phẩm, thậm chí phong cách quần áo đều thay đổi theo thời gian. Các mô hình được huấn luyện trên dữ liệu cũ có thể dần mất độ chính xác. Các nhóm thành công luôn lên kế hoạch giám sát và huấn luyện lại định kỳ như một phần của vòng đời hệ thống.
Phần lớn các thất bại của ứng dụng thị giác máy tính đều xuất phát từ việc sử dụng đúng mô hình nhưng sai cách. Hiểu các lỗi phổ biến này sẽ giúp bạn xây dựng hệ thống có thể mở rộng, duy trì độ tin cậy và tồn tại vượt qua giai đoạn thử nghiệm.
>> Xem thêm:
- Cách so sánh các mô hình thị giác máy tính một cách trực quan
- Top 5 thư viện Python cho thị giác máy tính – So sánh sự khác nhau
Các công nghệ này đang phát triển theo hướng nào?
Thị giác máy tính đang phát triển rất nhanh. Dù các lựa chọn hiện tại đã quan trọng, việc hiểu xu hướng của phát hiện đối tượng và mô hình ngôn ngữ thị giác sẽ giúp bạn đưa ra quyết định bền vững hơn. Dưới đây là một số xu hướng rõ ràng đang định hình sự phát triển của các công nghệ này.
Mô hình ngôn ngữ thị giác nhỏ gọn và nhanh hơn
Các mô hình ngôn ngữ thị giác đang trở nên nhanh hơn và hiệu quả hơn. Những tác vụ hiện tại mất vài giây cho mỗi hình ảnh có thể sớm chạy trong chưa đầy một giây. Điều này sẽ mở rộng phạm vi ứng dụng của VLM, đặc biệt trong các ứng dụng tương tác và gần thời gian thực. Tuy nhiên, VLM vẫn có tốc độ thấp hơn so với mô hình phát hiện đối tượng trong các hệ thống yêu cầu tốc độ khung hình cao hoặc thời gian thực.
Phát hiện đối tượng từ vựng mở
Một lớp mô hình mới đang bắt đầu làm mờ ranh giới giữa phát hiện đối tượng và VLM. Các mô hình này cho phép phát hiện đối tượng bằng mô tả văn bản, kể cả đối với các danh mục chưa từng xuất hiện trong quá trình huấn luyện. Điều này mang lại một phần tính linh hoạt của mô hình ngôn ngữ thị giác vào quy trình phát hiện đối tượng. Đánh đổi là kết quả vẫn phụ thuộc nhiều vào cách viết câu lệnh và hiệu năng có thể thay đổi giữa các kịch bản.

Triển khai tại biên cho cả hai phương pháp
Cả mô hình phát hiện đối tượng và mô hình ngôn ngữ thị giác đều đang trở nên nhỏ gọn và hiệu quả hơn. Điều này cho phép chạy chúng gần nơi dữ liệu được tạo ra hơn, chẳng hạn trên camera, cổng kết nối (gateway) hoặc thiết bị biên (edge devices).
Khi triển khai biên được cải thiện, chi phí giảm và độ trễ cũng được cải thiện. Điều này cũng mở ra các trường hợp sử dụng mới trong môi trường nơi truy cập đám mây bị hạn chế hoặc không ổn định.
>> Xem thêm: Edge AI là gì? Ưu điểm, cách hoạt động & ứng dụng thực tế
Mô hình ngôn ngữ thị giác theo lĩnh vực
Thay vì một mô hình tổng quát cho mọi thứ, chúng ta có thể tinh chỉnh VLM cho các lĩnh vực cụ thể như:
- Chẩn đoán hình ảnh y khoa
- Kiểm tra sản xuất
- Ảnh vệ tinh
Các mô hình tập trung theo lĩnh vực này thường chính xác hơn và nhất quán hơn so với VLM đa dụng. Trong các ngành chuyên biệt, chúng có thể làm thay đổi cán cân theo hướng mô hình ngôn ngữ thị giác cho một số tác vụ nhất định.
Đọc các hướng dẫn dưới đây để tìm hiểu thêm cách bạn có thể tinh chỉnh VLM trên dữ liệu tùy chỉnh:
- Cách tinh chỉnh Florence-2 cho tác vụ phát hiện đối tượng
- Cách tinh chỉnh Claude 3.7 Sonnet với Roboflow
- Cách tinh chỉnh PaliGemma 2
- Cách tinh chỉnh mô hình SmolVLM2 trên bộ dữ liệu tùy chỉnh
- Tinh chỉnh Moondream2 cho các tác vụ thị giác máy tính
Tương lai không phải là một mô hình thay thế hoàn toàn mô hình kia. Đó là sự chồng lấn nhiều hơn, công cụ tốt hơn và các đánh đổi rõ ràng hơn. Phát hiện đối tượng sẽ tiếp tục là nền tảng cho các hệ thống nhanh, đáng tin cậy và quy mô lớn. Mô hình ngôn ngữ thị giác sẽ tiếp tục cải thiện tính linh hoạt và khả năng hiểu sâu. Những nhóm thiết kế hệ thống dựa trên thế mạnh này sẽ sẵn sàng hơn khi cả hai công nghệ tiếp tục phát triển.
>>> Tìm hiểu thêm:
- Visual Question Answering là gì? Mô hình và Phương pháp hoạt động
- Deep Learning là gì? Tổng quan về cách hoạt động và ứng dụng thực tế
- Phrase Grounding là gì? Mô hình và cách hoạt động
Kết luận: Cách chọn giữa phát hiện đối tượng và mô hình ngôn ngữ thị giác
Việc lựa chọn giữa mô hình ngôn ngữ thị giác và phát hiện đối tượng không phải là công nghệ nào “tốt hơn”. Mà là công nghệ nào phù hợp với bài toán của bạn.
Phát hiện đối tượng hoạt động tốt nhất khi bạn cần kết quả nhanh, nhất quán cho các danh mục đã biết ở quy mô lớn. Mô hình ngôn ngữ thị giác phù hợp hơn khi yêu cầu chưa rõ ràng, thay đổi liên tục hoặc cần hiểu sâu về ngữ cảnh.
Khi cả hai công nghệ tiếp tục phát triển, các điểm quyết định sẽ thay đổi, nhưng khung tư duy nền tảng vẫn giữ nguyên. Bạn cần khớp lựa chọn kỹ thuật với yêu cầu cụ thể về tốc độ, tính linh hoạt, chi phí và độ chính xác.
Trường hợp sử dụng (use case) của bạn là gì? Hãy áp dụng khung ra quyết định, bạn sẽ tìm được câu trả lời – hoặc trao đổi với chuyên gia AI nếu bạn còn câu hỏi bổ sung.
>>> Nguồn tham khảo: Object Detection vs Vision-Language Models: When Should You Use Each?
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.