
Phát hiện đối tượng là một kỹ thuật thị giác máy tính cơ bản giúp nhận diện và xác định vị trí các đối tượng trong hình ảnh, video hoặc luồng trực tiếp bằng cách sử dụng nhãn và tọa độ hộp giới hạn. Nó hỗ trợ một loạt các ứng dụng trong nhiều ngành công nghiệp, tự động hóa các tác vụ thị giác như giám sát, kiểm tra chất lượng, an toàn xây dựng và lái xe tự động. Trong bài viết này, chúng ta sẽ tìm hiểu cách tích hợp liền mạch khả năng phát hiện đối tượng bằng Python vào hệ thống của bạn thông qua gói Roboflow Inference.
Hình ảnh dưới đây minh họa kết quả phát hiện đối tượng mà chúng ta sẽ đạt được trong bài viết này bằng cách sử dụng mô hình RF-DETR và mô hình RF-DETR được tinh chỉnh từ Roboflow Universe:

Tương tự, video dưới đây minh họa kết quả phát hiện đối tượng trên video sử dụng các mô hình tương tự:
>> Xem thêm:
- Trí tuệ nhân tạo (AI) là gì? Hiểu đúng về khái niệm & ứng dụng
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow
- Cách ứng dụng AI tối ưu trải nghiệm khách hàng
Phát hiện đối tượng bằng Python sử dụng Roboflow Inference
Roboflow Inference là một thư viện Python cho phép bạn chạy và triển khai các mô hình thị giác máy tính một cách cục bộ, trên thiết bị edge hoặc trên cloud.
Nó hỗ trợ nhiều tác vụ như phát hiện đối tượng, phân đoạn và phân loại thông qua các quy trình làm việc mô-đun có khả năng xử lý hình ảnh, video hoặc luồng trực tiếp.
Phát hiện đối tượng trên ảnh với mô hình RF-DETR qua Roboflow Inference
Thực hiện các bước dưới đây để xây dựng script Python phát hiện đối tượng cho hình ảnh sử dụng mô hình RF-DETR. Bạn cũng có thể tìm thấy script hoàn chỉnh cho code được minh họa trong các bước dưới đây tại đây.
Bước 1: Cài đặt gói Inference
Bắt đầu bằng cách cài đặt gói inference:
pip install inferenceBước 2: Tải mô hình phát hiện đối tượng được huấn luyện trước
Tiếp theo, tạo một lệnh Python mới, và trong đó, import và tải mô hình RF-DETR:
from inference import get_model
model = get_model("rfdetr-base")RF-DETR là một mô hình phát hiện đối tượng dựa trên transformer theo thời gian thực được phát triển bởi Roboflow, được thiết kế để đạt được hiệu suất tiên tiến với độ chính xác cao và độ trễ thấp.
Bước 3: Thực hiện suy luận trên một hình ảnh
Trong cùng một lệnh đó, sử dụng mô hình đã tải để chạy inference trên hình ảnh của bạn:
from PIL import Image
image = Image.open("YOUR_TEST_IMAGE.jpg")
# Define which coco classes to detect (empty = all)
class_filter = ["person"]
# Run inference on the image
predictions = model.infer(image, confidence=0.5, class_filter=class_filter)[0]
print(predictions)class_filter là một danh sách các lớp COCO mà mô hình RF-DETR nên phát hiện; nếu danh sách trống, mô hình sẽ phát hiện tất cả các lớp COCO có trong hình ảnh.
Bước 4: Chuyển đổi dự đoán thành các phát hiện của Supervision
Supervision là một gói Python cho phép chúng ta trực quan hóa đầu ra của mô hình một cách hiệu quả. Để sử dụng nó, cài đặt gói qua:
pip install supervisionSau khi cài đặt, thêm code sau vào đoạn lệnh của bạn để chuyển đổi dự đoán mô hình thành Detections của Supervision. Supervision yêu cầu dự đoán mô hình dưới dạng Detections để trực quan hóa:
import supervision as sv
# Convert predictions into Supervision's Detections
detections = sv.Detections.from_inference(predictions)
print(detections)Bước 5: Tạo Annotators để trực quan hóa
Supervision cung cấp các annotator để vẽ khung giới hạn và gắn nhãn cho chúng. Thiết lập các annotator này trong đoạn lệnh của bạn để thêm khung và nhãn vào hình ảnh:
# Create a BoxAnnotator to draw bounding boxes around detected objects
box_annotator = sv.BoxAnnotator(
color=sv.ColorPalette.ROBOFLOW,
thickness=4
)
# Create a LabelAnnotator to draw text labels on the image
label_annotator = sv.LabelAnnotator(
color=sv.ColorPalette.from_matplotlib('viridis', 5),
text_scale=1
)Bước 6: Chú thích và hiển thị hình ảnh
Bây giờ sử dụng các annotator này để phủ lớp khung giới hạn và nhãn lớp, trực quan hóa các phát hiện của bạn:
# Prepare labels for each detection in the format: "class_name confidence"
labels = [
f"{prediction.class_name} {prediction.confidence:.2f}"
for prediction in predictions.predictions
]
print(labels)
# Make a copy of the image to draw annotations
annotated_image = image.copy()
# Annotate the image with bounding boxes
annotated_image = box_annotator.annotate(annotated_image, detections)
# Annotate the image with labels
annotated_image = label_annotator.annotate(annotated_image, detections, labels)
# Display the final annotated image
sv.plot_image(annotated_image)Đoạn lệnh của bạn giờ đã hoàn thành. Chạy lệnh trên một hình ảnh thử nghiệm.
Đầu ra hình ảnh được chú thích
Đầu ra dưới đây cho thấy kết quả trên một hình ảnh thử nghiệm sử dụng đoạn lệnh code trên. Vì chúng ta chỉ chỉ định ‘person’ trong class_filter, mô hình chỉ phát hiện được người.

>> Xem thêm:
- Top 20 công ty thiết kế app uy tín, chuyên nghiệp
- Cách ứng dụng AI trong phát triển phần mềm: Trường hợp ứng dụng & công cụ AI
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
Phát hiện đối tượng trong video với mô hình RF-DETR qua Roboflow Inference
Thực hiện các bước dưới đây để xây dựng đoạn lệnh phát hiện đối tượng bằng Python cho video sử dụng mô hình RF-DETR. Bạn cũng có thể tìm thấy đoạn lệnh hoàn chỉnh cho code được minh họa trong các bước dưới đây tại đây.
Bước 1: Khởi tạo Inference Pipeline
Đảm bảo rằng gói inference đã được cài đặt, như đã minh họa trước đó. Sau đó, tạo một đoạn lệnh mới và khởi tạo quy trình suy luận RF-DETR, cho phép bạn xử lý video và nhận dự đoán cho mỗi khung hình thông qua một hàm callback:
from inference import InferencePipeline
def callback(predictions, video_frame):
print("Predictions:", predictions)
print("Video Frame:", video_frame)
# Source of the video — Video file path, stream URL, or device ID (e.g., 0 for a webcam)
video_path = "test_video.mp4"
# Initialize the pipeline
pipeline = InferencePipeline.init(
model_id="rfdetr-base",
video_reference=video_path,
on_prediction=callback,
api_key="YOUR_ROBOFLOW_KEY",
confidence=0.5,
)
# Start pipeline
pipeline.start()
pipeline.join()Quy trình này xử lý từng khung hình riêng lẻ, gọi hàm callback cho mỗi khung hình và cung cấp các dự đoán phát hiện đối tượng tương ứng từ mô hình RF-DETR.
>> Xem thêm:
- Cách tạo ứng dụng AI với vibe coding trên Google AI Studio đơn giản
- TOP 15+ công ty lập trình phần mềm lớn, uy tín hàng đầu Việt Nam
Bước 2: Chuyển đổi dự đoán thành Detections của Supervision
Tiếp theo, cập nhật hàm callback để chuyển đổi dự đoán của mô hình thành Detections của Supervision sử dụng thư viện Supervision:
from inference import InferencePipeline
# Import Supervision
import supervision as sv
def callback(predictions, video_frame):
# Print Prediction and Video Frame Code
# Convert Predictions to Detections
detections = sv.Detections.from_inference(predictions)
print("Detections:", detections)
video_path = "test_video.mp4"
pipeline = InferencePipeline.init(
model_id="rfdetr-base",
video_reference=video_path,
on_prediction=callback,
api_key="YOUR_ROBOFLOW_KEY",
confidence=0.5,
)
pipeline.start()
pipeline.join()Bước 3: Thêm Byte Tracker
Giữ nguyên code đã thêm trước đó, tích hợp theo dõi đối tượng qua các khung hình sử dụng Byte Tracker để duy trì danh tính đối tượng nhất quán trong suốt video:
from inference import InferencePipeline
import supervision as sv
# Create BYTETracker instance
byte_tracker = sv.ByteTrack()
def callback(predictions, video_frame):
# Print Prediction and Video Frame Code
# Convert Predictions to Detections Code
# Integrate Byte Tracker
detections = byte_tracker.update_with_detections(detections)
video_path = "test_video.mp4"
pipeline = InferencePipeline.init(
model_id="rfdetr-base",
video_reference=video_path,
on_prediction=callback,
api_key="YOUR_ROBOFLOW_KEY",
confidence=0.5,
)
pipeline.start()
pipeline.join()ByteTracker là một thuật toán theo dõi đối tượng gán ID duy nhất cho các đối tượng được phát hiện, cho phép theo dõi liên tục của chúng qua các khung hình video và duy trì danh tính nhất quán trong suốt video.
>> Xem thêm:
- Dịch vụ viết phần mềm theo yêu cầu tại Hà Nội chuyên nghiệp
- Phân tích hình ảnh bằng AI là gì? Cách AI hiểu và diễn giải hình ảnh
Bước 4: Định nghĩa và lọc các lớp phát hiện đối tượng
Bây giờ, lọc các phát hiện theo các lớp đối tượng cụ thể (ví dụ: một lớp COCO như ‘person’) để tập trung vào các đối tượng có liên quan trong video được phát hiện cuối cùng:
from inference import InferencePipeline
import supervision as sv
# Define which coco classes to detect (empty = all)
class_filter = ["person"]
byte_tracker = sv.ByteTrack()
def callback(predictions, video_frame):
# Print Prediction and Video Frame Code
# Convert Predictions to Detections Code
# Integrate Byte Tracker code
# Filter Classes
keep_indices = (
[i for i, class_name in enumerate(detections.data.get('class_name', [])) if class_name in class_filter]
if class_filter else list(range(len(detections))) # keep all if no filter
)
filtered_detections = (
sv.Detections(
xyxy=detections.xyxy[keep_indices],
confidence=detections.confidence[keep_indices],
class_id=detections.class_id[keep_indices],
data={k: v[keep_indices] for k, v in detections.data.items()}
) if keep_indices else sv.Detections.empty()
)
video_path = "test_video.mp4"
pipeline = InferencePipeline.init(
model_id="rfdetr-base",
video_reference=video_path,
on_prediction=callback,
api_key="YOUR_ROBOFLOW_KEY",
confidence=0.5,
)
pipeline.start()
pipeline.join()Bước 5: Chú thích và lưu từng khung hình với hộp giới hạn và nhãn
Bây giờ chúng ta sử dụng các annotator của Supervision để vẽ khung giới hạn và nhãn lớp trên mỗi khung hình, sau đó lưu tất cả các khung hình đã chú thích theo thứ tự vào một thư mục có tên annotated_frames:
from inference import InferencePipeline
import supervision as sv
# Import OpenCV, Numpy, OS
import cv2
import numpy as np
import os
# Create folder to save annotated frames
output_folder = "annotated_frames"
os.makedirs(output_folder, exist_ok=True)
# Maintain a frame counter
frame_counter = {"count": 0}
# Utilize Video path for extracting total frames
video_path = "test_video.mp4"
# Get total frames to measure progress
video_info = sv.VideoInfo.from_video_path(video_path)
total_frames = video_info.total_frames
# Define annotators
box_annotator = sv.BoxAnnotator(
color=sv.ColorPalette.ROBOFLOW,
thickness=4
)
label_annotator = sv.LabelAnnotator(
color=sv.ColorPalette.from_matplotlib('viridis', 5),
text_scale=0.6
)
class_filter = ["person"]
byte_tracker = sv.ByteTrack()
def callback(predictions, video_frame):
# Print Prediction and Video Frame Code
# Convert Predictions to Detections Code
# Integrate Byte Tracker Code
# Filter Classes Code
# Generate labels
labels = [
f"{class_name} {conf:.2f}"
for class_name, conf in zip(
filtered_detections.data.get('class_name', []),
getattr(filtered_detections, 'confidence', [])
)
]
# Convert VideoFrame to NumPy array and annotate
frame_array = cv2.cvtColor(np.array(video_frame.image), cv2.COLOR_RGB2BGR)
annotated_frame = box_annotator.annotate(frame_array, filtered_detections)
annotated_frame = label_annotator.annotate(annotated_frame, filtered_detections, labels)
# Save annotated frame
idx = frame_counter["count"]
frame_filename = os.path.join(output_folder, f"frame_{idx:05d}.jpg")
cv2.imwrite(frame_filename, cv2.cvtColor(annotated_frame, cv2.COLOR_RGB2BGR))
# Count the number of processed frames
frame_counter["count"] += 1
print(f"Processing frame {idx + 1} / {total_frames}")
pipeline = InferencePipeline.init(
model_id="rfdetr-base",
video_reference=video_path,
on_prediction=callback,
api_key="YOUR_ROBOFLOW_KEY",
confidence=0.5,
)
pipeline.start()
pipeline.join()Bây giờ, chạy đoạn lệnh trên, nó sẽ xử lý từng khung hình video, phát hiện đối tượng trong mỗi khung hình, và lưu các khung hình đã chú thích vào một thư mục có tên annotated_frames, sau đó có thể được hợp nhất để tạo video phát hiện đối tượng cuối cùng.
>> Xem thêm:
- AI nhận diện ảnh là gì? Thuật toán và ứng dụng phổ biến
- 18 cách ứng dụng AI cho ecommerce hiệu quả, sáng tạo
Bước 6: Hợp nhất tất cả các khung hình đã chú thích thành một video duy nhất
Cuối cùng, tạo một đoạn lệnh mới trong cùng thư mục với lệnh trước đó để kết hợp tất cả các khung hình đã chú thích đã lưu thành một video duy nhất sử dụng OpenCV, giữ nguyên độ phân giải và tốc độ khung hình gốc, như hiển thị dưới đây:
import cv2
import os
import supervision as sv
# Paths
frames_folder = "annotated_frames"
output_video_path = "annotated_video.mp4"
video_path = "test_video.mp4"
# Get video info using Supervision
video_info = sv.VideoInfo.from_video_path(video_path)
fps = video_info.fps
width = video_info.width
height = video_info.height
# Prepare video writer
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_video_path, fourcc, fps, (width, height))
# Write frames to video
for frame_file in os.listdir(frames_folder):
if frame_file.endswith(".jpg"):
frame_path = os.path.join(frames_folder, frame_file)
frame = cv2.imread(frame_path)
out.write(frame)
out.release()
print(f"Video saved to {output_video_path}")Kết quả video có chú thích
Phần đầu ra bên dưới hiển thị kết quả trên một video thử nghiệm khi sử dụng đoạn script ở trên. Do chúng ta chỉ định ‘person’ trong tham số class_filter, nên mô hình chỉ phát hiện các đối tượng là con người.
Tìm kiếm các mô hình được tinh chỉnh trên Roboflow Universe
Trong các ví dụ phát hiện đối tượng ở trên, một mô hình RF-DETR được sử dụng trong lĩnh vực xây dựng. Hạn chế của nó là nó chỉ nhận diện các lớp dựa trên COCO mà nó đã được huấn luyện, nhưng việc tinh chỉnh mô hình trên các bộ dữ liệu tùy chỉnh có thể khắc phục hạn chế này.
Roboflow Universe cung cấp một kho lưu trữ mở về các bộ dữ liệu, mô hình và dự án từ các nhà phát triển và nhà nghiên cứu trên toàn thế giới. Nó lưu trữ các RF-DETR được tinh chỉnh và các mô hình khác được tối ưu hóa cho các tác vụ trong các lĩnh vực như xây dựng, phân tích thể thao và nghiên cứu không gian địa lý, giúp dễ dàng tìm và sử dụng các mô hình được điều chỉnh theo nhu cầu của bạn.
Video dưới đây minh họa các mô hình được tinh chỉnh khác nhau, bộ dữ liệu và dự án có sẵn trên Roboflow Universe.
>> Xem thêm:
- Character AI là gì? Trò chuyện cùng nhân vật ảo trên mô hình mới
- Hướng dẫn thiết kế trang web bằng AI miễn phí, chuẩn SEO, hiệu quả
Bạn có thể tìm kiếm mô hình bằng mô hình cơ sở mà chúng được tinh chỉnh, như hình dưới đây, hoặc theo loại dự án của chúng:
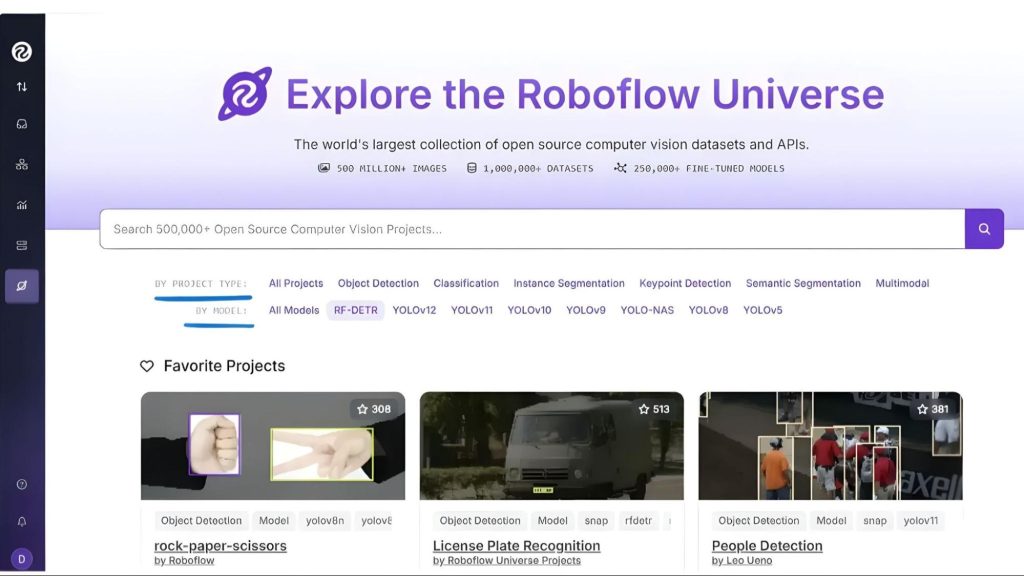
Ví dụ, để tìm kiếm các mô hình được tinh chỉnh dựa trên RF-DETR, nhấp vào “RF-DETR” trong giao diện người dùng ở trên, và bạn sẽ thấy một cái gì đó như thế này:
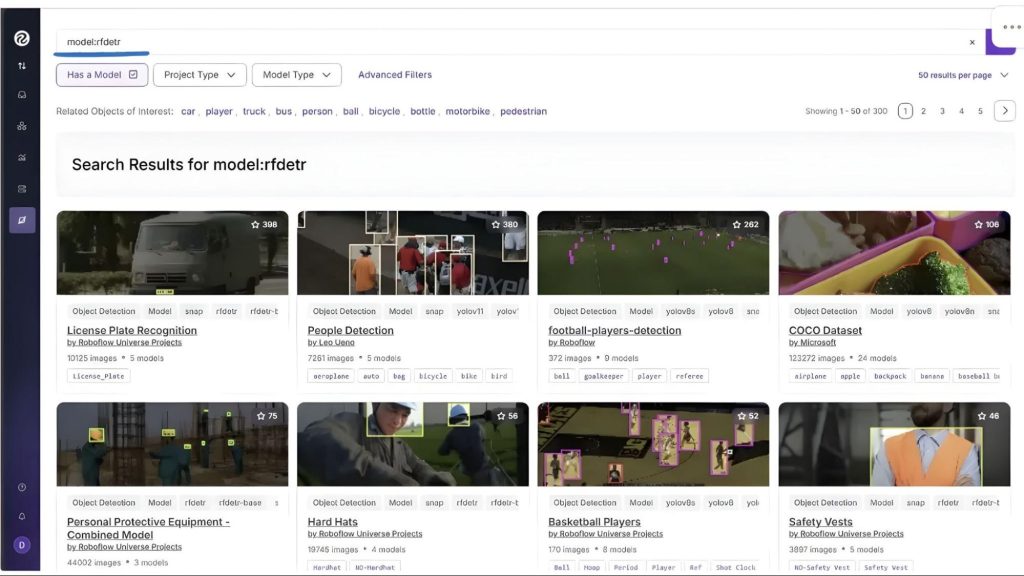
Tất cả các dự án hiển thị ở trên đều dựa trên RF-DETR. Tương tự, bạn có thể tìm kiếm các mô hình được điều chỉnh cho đối tượng quan tâm cụ thể của bạn. Trong trường hợp này, chúng ta muốn phát hiện xem một người trên công trường có đang đội mũ cứng hay không. Vì “mũ cứng” không phải là một lớp COCO, chúng ta cần một mô hình đã được tinh chỉnh cụ thể cho tác vụ này.
Tìm kiếm dưới đây là cho Hardhats (mũ cứng), trả về một số mô hình được tinh chỉnh có khả năng phát hiện mũ cứng:
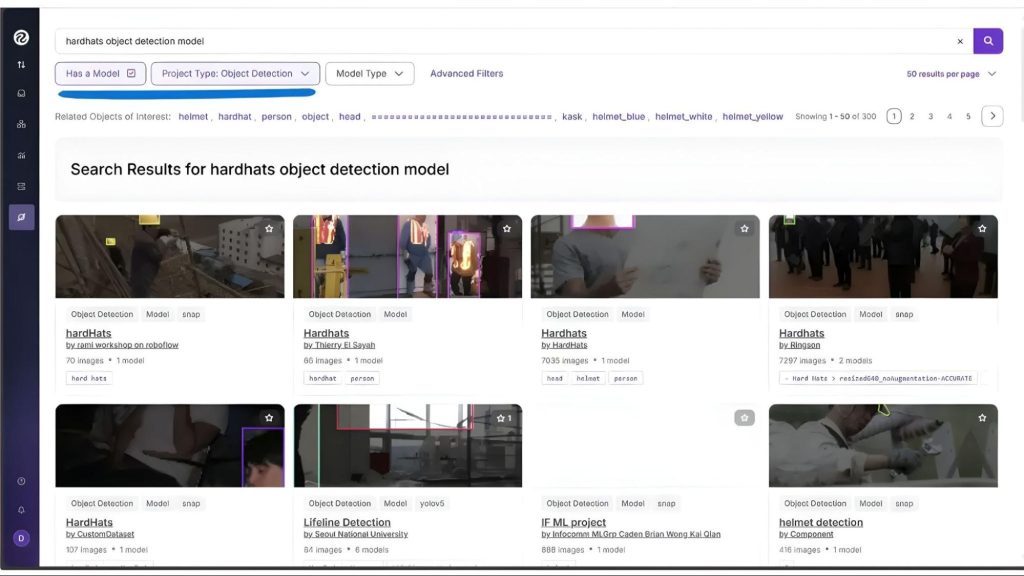
Trong số đó, chúng ta đã chọn mô hình hiển thị dưới đây, đã được tinh chỉnh trên bộ dữ liệu mũ cứng sử dụng mô hình RF-DETR làm nền tảng:
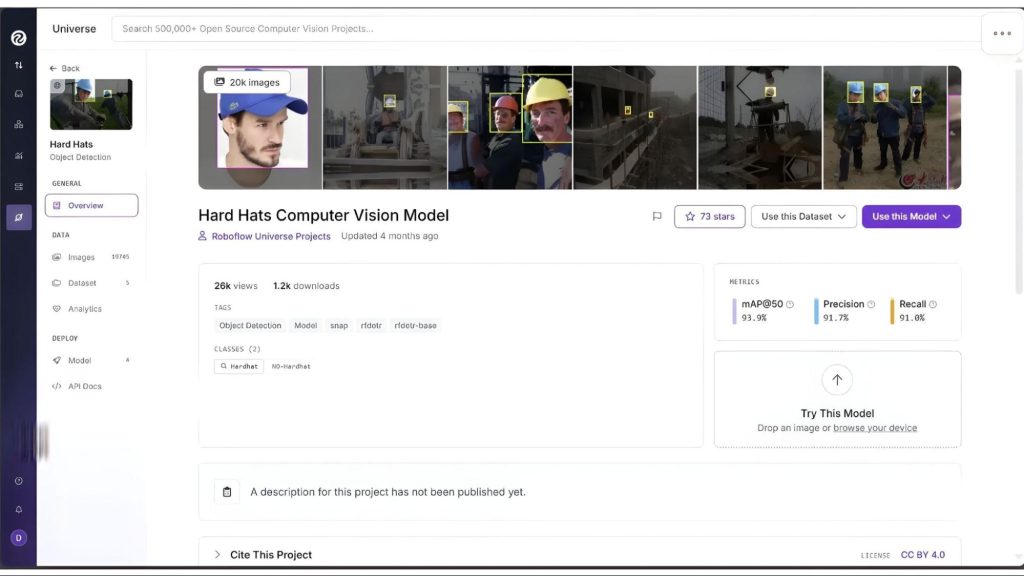
Chúng ta sẽ chọn mô hình này sau khi kiểm tra trực tiếp thông qua giao diện người dùng Roboflow Universe. Bằng cách vào phần “Model” trong thanh bên trái, bạn có thể kiểm tra mô hình trên hình ảnh và video:
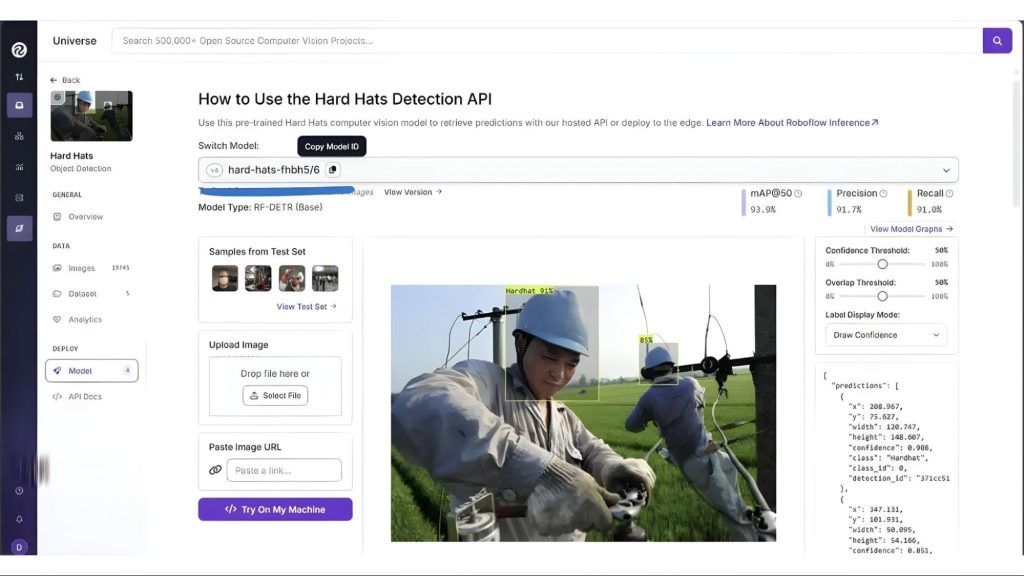
Nó đã được tinh chỉnh để phân loại chính xác hai lớp, ‘Hardhat’ và ‘No-Hardhat’, như hiển thị khi bạn nhấp vào “View Model Graphs” trong phần “Model” ở thanh bên trái:
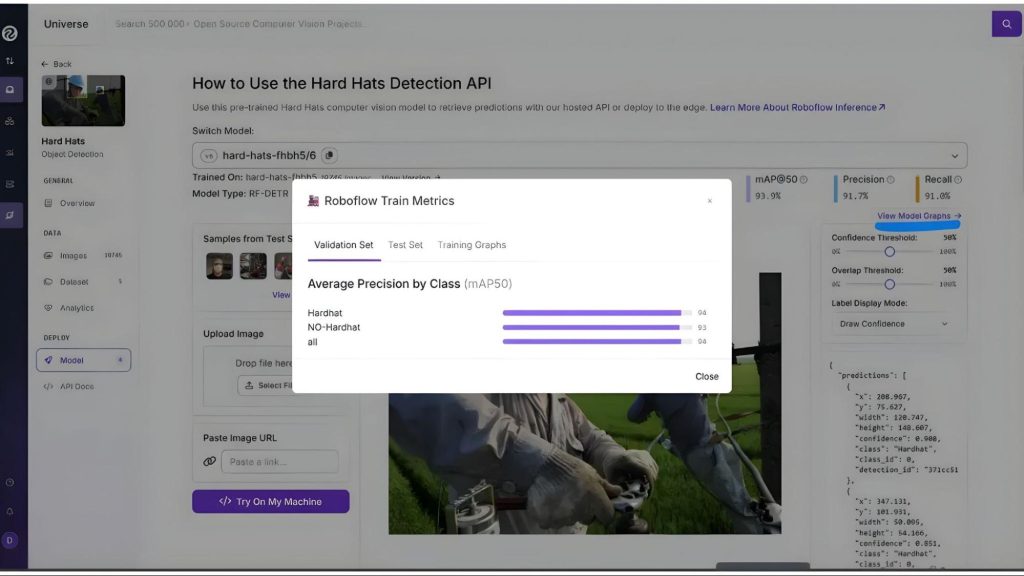
Bằng cách tận dụng phiên bản được tinh chỉnh này của RF-DETR, chúng ta có thể xác định chính xác xem một cá nhân có đang đội mũ cứng hay không.
>> Xem thêm:
- TOP 10 công cụ AI thiết kế website miễn phí, trả phí, hiệu quả
- Dịch vụ thiết kế website trọn gói theo yêu cầu, uy tín, chuyên nghiệp
Tích hợp các mô hình từ Roboflow Universe
Tương tự như code ở trên, nơi chúng ta tích hợp mô hình RF-DETR để phát hiện đối tượng, chúng ta có thể sử dụng bất kỳ mô hình Roboflow Universe nào bằng cách tham chiếu ID mô hình của nó thông qua Roboflow Inference.
Bạn có thể tìm thấy ID của mô hình trong phần “Model” của thanh bên trái trong Roboflow Universe, như hiển thị dưới đây:
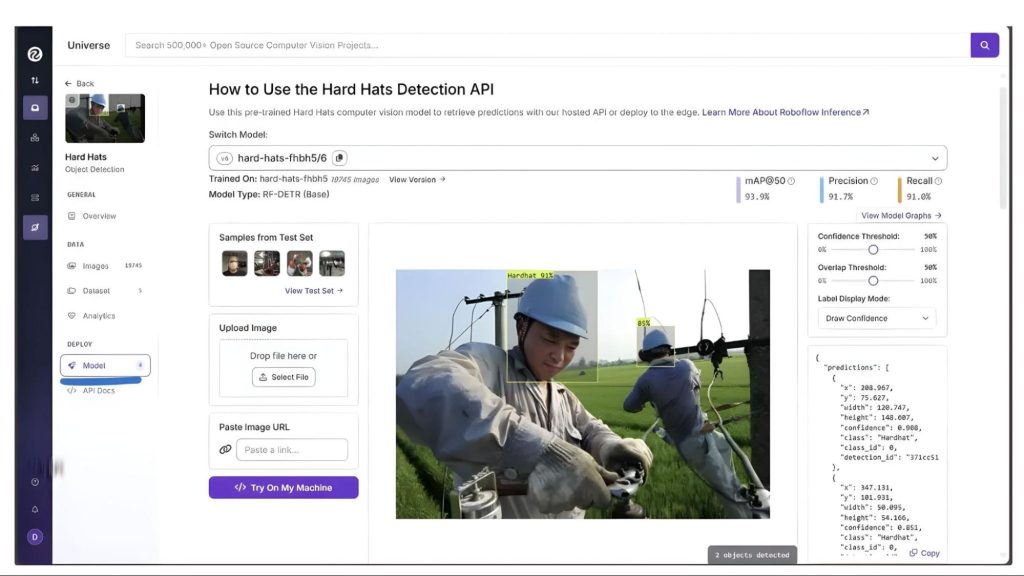
>> Xem thêm:
- Top 17 ứng dụng thiết kế đồ họa miễn phí, dễ dùng & chuyên nghiệp nhất
- Inference In Computer Vision: Suy luận trong thị giác máy tính là gì?
Phát hiện đối tượng trên ảnh với mô hình Roboflow Universe được tinh chỉnh qua Roboflow Inference
Trong trường hợp hình ảnh, cập nhật class_filter và ID mô hình trong script đã hoàn thành trước đó được sử dụng để phát hiện đối tượng, như hiển thị dưới đây, sử dụng ID mô hình mới và các lớp phát hiện được mô hình hỗ trợ:
# Trained classes
class_filter = ["NO-Hardhat"]
# Get finetuned roboflow universe model
model = get_model("hard-hats-fhbh5/6")Bạn có thể để phần còn lại của code không thay đổi. class_filter bây giờ nhắm mục tiêu các đối tượng “No-Hardhat” trong hình ảnh. Nếu danh sách để trống, mô hình sẽ phát hiện tất cả các lớp có sẵn; trong trường hợp này, cả “Hardhat” và “No-Hardhat” sẽ được phát hiện.
Hình ảnh dưới đây minh họa khả năng phát hiện đối tượng của mô hình được tinh chỉnh trên hình ảnh thử nghiệm của chúng ta:

Trong hình ảnh trên, mô hình được tinh chỉnh đã phát hiện thành công một trường hợp mà ai đó không đội mũ cứng, mặc dù danh mục này không được bao gồm trong các lớp bộ dữ liệu COCO.
Phát hiện đối tượng trên video với mô hình Roboflow Universe được tinh chỉnh qua Roboflow Inference
Tương tự, đối với video, cập nhật class_filter và ID mô hình trong script đã hoàn thành trước đó được sử dụng để phát hiện đối tượng, như hiển thị dưới đây, sử dụng model ID mới và các lớp phát hiện được mô hình hỗ trợ:
# Trained classes
class_filter = ["Hardhat"]
# Initialize with finetuned roboflow universe model
pipeline = InferencePipeline.init(
model_id = "hard-hats-fhbh5/6",
video_reference=video_path,
on_prediction=callback,
api_key="YOUR_ROBOFLOW_KEY",
confidence=0.5,
)Bạn có thể để phần còn lại của code không thay đổi. class_filter bây giờ nhắm mục tiêu các đối tượng “Hardhat” trong video.
Video dưới đây minh họa khả năng phát hiện đối tượng của mô hình được tinh chỉnh trên video thử nghiệm của chúng ta:
Trong video trên, mô hình được tinh chỉnh đã phát hiện thành công mũ cứng, mặc dù chúng không được bao gồm trong các lớp bộ dữ liệu COCO.
>> Xem thêm:
- LLM là gì? Mô hình ngôn ngữ lớn và cách chúng hoạt động
- Mẹo tạo prompt cho LLM trong thị giác máy tính để tăng độ chính xác
- Hướng dẫn triển khai AI trong ứng dụng di động đơn giản
Tinh chỉnh các mô hình trên bộ dữ liệu tùy chỉnh của bạn với Roboflow
Roboflow cung cấp một bộ công cụ toàn diện giúp đơn giản hóa việc tinh chỉnh các mô hình thị giác máy tính, chẳng hạn như RF-DETR, SmolVLM2 và SAM-2.1, cho các trường hợp sử dụng cụ thể như:
- Roboflow Annotate: Một nền tảng gắn nhãn được hỗ trợ bởi AI với các tính năng Smart Polygon, Label Assist và Auto Label để tăng tốc độ tạo bộ dữ liệu.
- Roboflow Universe: Một trung tâm hướng đến cộng đồng để khám phá và chia sẻ các bộ dữ liệu và mô hình được huấn luyện trước.
- Roboflow Inference: Cho phép chạy các mô hình được tinh chỉnh cục bộ hoặc thông qua API của Roboflow để xử lý hình ảnh và video nhanh chóng.
- Roboflow Maestro: Đơn giản hóa việc tinh chỉnh các mô hình đa phương thức với các công thức sẵn sàng sử dụng cho các mô hình như Florence-2, PaliGemma 2 và Qwen2.5-VL.
Roboflow cũng cung cấp các tài nguyên học tập mở rộng để tinh chỉnh các mô hình khác nhau, bao gồm RF-DETR, SmolVLM2, SAM2.1 và nhiều hơn nữa.
>> Xem thêm:
- Các nhiệm vụ chính của thị giác máy tính
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Ứng dụng AI trong bán hàng online: TOP 10 công cụ AI & cách triển khai hiệu quả
Kết luận: Thực hiện phát hiện đối tượng bằng Python
Roboflow, kết hợp với Python, làm cho phát hiện đối tượng bằng Python trở nên dễ tiếp cận và có khả năng mở rộng, cho phép các nhà phát triển phát hiện và theo dõi đối tượng một cách hiệu quả trong hình ảnh, video hoặc luồng trực tiếp.
Bằng cách tận dụng các mô hình được huấn luyện trước như RF-DETR hoặc các mô hình được tinh chỉnh từ Roboflow Universe, bạn có thể nhận diện các đối tượng cụ thể theo lĩnh vực như mũ cứng xây dựng vượt ra ngoài các lớp COCO tiêu chuẩn.
Hệ sinh thái của Roboflow, bao gồm Inference, Annotate, Universe và Maestro, cung cấp tất cả các công cụ bạn cần để huấn luyện, tinh chỉnh và triển khai các mô hình tùy chỉnh được điều chỉnh theo trường hợp sử dụng cụ thể của bạn. Tìm hiểu thêm về phát hiện đối tượng.
>>> Nguồn tham khảo: Build Python Object Detection Apps in Minutes with Roboflow
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam







