
LLM (Large Language Model) đang là nền tảng đứng sau nhiều ứng dụng AI như chatbot, trợ lý ảo hay công cụ viết nội dung. Vậy LLM là gì, vì sao mô hình này có thể hiểu và tạo ra ngôn ngữ giống con người, và nó được ứng dụng như thế nào trong thực tế? Bài viết dưới đây sẽ giúp bạn hiểu nhanh và đúng bản chất về LLM là gì, từ cách hoạt động đến ưu điểm và hạn chế.
Mô hình ngôn ngữ lớn (LLM) là gì?
Mô hình ngôn ngữ lớn (Large Language Model – LLM) là một loại chương trình trí tuệ nhân tạo (AI) có khả năng nhận biết, hiểu và tạo ra văn bản, cùng với nhiều tác vụ khác. LLM được huấn luyện trên khối lượng dữ liệu cực lớn — đó cũng chính là lý do có tên gọi “large”. Về mặt kỹ thuật, LLM được xây dựng dựa trên machine learning, cụ thể là một dạng mạng nơ-ron gọi là mô hình Transformer.
Nói một cách đơn giản, LLM là một chương trình máy tính được “nuôi” bằng rất nhiều ví dụ, đủ để nó có thể nhận diện và diễn giải ngôn ngữ của con người hoặc các dạng dữ liệu phức tạp khác. Nhiều LLM được huấn luyện trên dữ liệu thu thập từ Internet — với khối lượng lên đến hàng nghìn hoặc hàng triệu gigabyte văn bản.
Một số LLM thậm chí còn tiếp tục thu thập dữ liệu từ web sau khi quá trình huấn luyện ban đầu hoàn tất. Tuy nhiên, chất lượng dữ liệu mẫu ảnh hưởng rất lớn đến khả năng học ngôn ngữ tự nhiên của LLM, vì vậy các lập trình viên thường sử dụng tập dữ liệu được chọn lọc kỹ càng, ít nhất là trong giai đoạn đầu.
LLM sử dụng một nhánh của học máy gọi là học sâu để hiểu cách các ký tự, từ ngữ và câu kết hợp với nhau. Học sâu liên quan đến việc phân tích xác suất trên dữ liệu phi cấu trúc, từ đó cho phép mô hình tự nhận ra sự khác biệt giữa các nội dung mà không cần con người can thiệp trực tiếp.
Sau đó, LLM tiếp tục được huấn luyện thông qua quá trình tinh chỉnh: chúng được fine-tune hoặc prompt-tune cho những nhiệm vụ cụ thể mà lập trình viên mong muốn, chẳng hạn như hiểu câu hỏi và tạo câu trả lời, hoặc dịch văn bản từ ngôn ngữ này sang ngôn ngữ khác.
>>> Xem thêm các bài viết liên quan:
- Các mô hình phát hiện đối tượng tốt nhất
- Các Mô Hình Ngôn Ngữ Thị Giác Chạy Cục Bộ Tốt Nhất
- Phát hiện đối tượng trong video với RF-DETR
- Hướng dẫn cách sử dụng Google AI Studio hiệu quả, nhanh chóng

LLM được sử dụng để làm gì?
LLM có thể được huấn luyện để thực hiện nhiều loại nhiệm vụ khác nhau. Một trong những ứng dụng phổ biến nhất là AI tạo sinh (generative AI): khi được cung cấp prompt hoặc câu hỏi, LLM có thể tạo ra văn bản phản hồi. Ví dụ, LLM công khai ChatGPT có thể tạo bài luận, thơ ca và nhiều dạng văn bản khác dựa trên đầu vào của người dùng.
Không chỉ giới hạn ở ngôn ngữ tự nhiên, LLM còn có thể được huấn luyện trên các tập dữ liệu lớn và phức tạp, bao gồm cả ngôn ngữ lập trình. Một số LLM có thể hỗ trợ lập trình viên viết mã nguồn, chẳng hạn:
- Tạo hàm theo yêu cầu
- Hoàn thiện chương trình dựa trên đoạn code có sẵn
- Gợi ý và tối ưu logic lập trình
Ngoài ra, LLM còn được ứng dụng trong nhiều lĩnh vực thực tế khác như:
- Phân tích cảm xúc (Sentiment Analysis)
- Nghiên cứu DNA
- Chăm sóc khách hàng
- Chatbot tự động
- Tìm kiếm trực tuyến
- Ví dụ các LLM trong thực tế
Một số mô hình LLM nổi bật hiện nay bao gồm:
- ChatGPT – do OpenAI phát triển
- Bard – của Google
- Llama – do Meta phát triển
- Bing Chat – của Microsoft
Bên cạnh đó, GitHub Copilot cũng là một ví dụ tiêu biểu về LLM, nhưng tập trung vào hỗ trợ lập trình thay vì xử lý ngôn ngữ tự nhiên cho người dùng phổ thông
>>> Xem thêm:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất

Mô hình ngôn ngữ lớn hoạt động như thế nào?
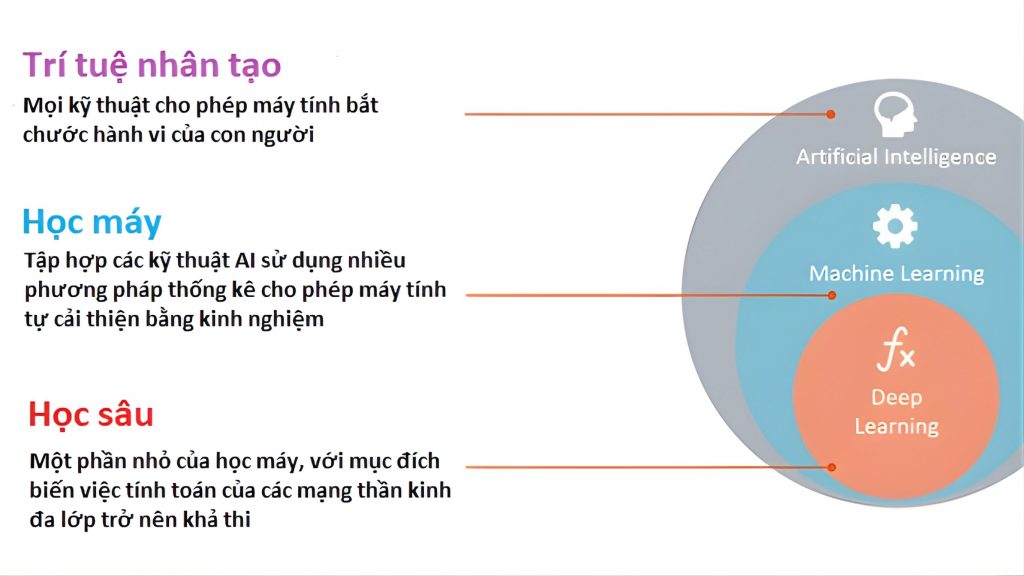
Học máy và học sâu
Ở mức cơ bản, LLM được xây dựng dựa trên học máy. Học máy là một nhánh của AI, trong đó chương trình được cung cấp lượng dữ liệu lớn để học cách nhận diện các đặc điểm của dữ liệu đó mà không cần con người chỉ dẫn trực tiếp.
LLM sử dụng một dạng học máy gọi là học sâu. Các mô hình học sâu về bản chất có thể tự học cách nhận diện sự khác biệt trong dữ liệu mà không cần sự can thiệp của con người, dù trên thực tế vẫn cần một mức độ tinh chỉnh nhất định từ con người.
Học sâu dựa trên xác suất để “học”. Ví dụ, trong câu tiếng Anh:
“The quick brown fox jumped over the lazy dog”
Các chữ cái “e” và “o” xuất hiện nhiều nhất (mỗi chữ 4 lần). Từ đó, một mô hình deep learning có thể suy ra (một cách hợp lý) rằng đây là những ký tự thường xuyên xuất hiện trong tiếng Anh.
Tất nhiên, trong thực tế, một mô hình học sâu không thể rút ra kết luận chỉ từ một câu duy nhất. Nhưng sau khi phân tích hàng nghìn tỷ câu văn, mô hình có thể học đủ để:
- Dự đoán phần còn thiếu của một câu chưa hoàn chỉnh
- Tạo ra những câu hoàn toàn mới nhưng vẫn logic và tự nhiên
>>> Xem thêm:
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
Mạng nơ-ron của LLM
Để có thể thực hiện deep learning, LLM được xây dựng trên nền tảng mạng nơ-ron. Tương tự như bộ não con người gồm các nơ-ron kết nối và truyền tín hiệu cho nhau, mạng nơ-ron nhân tạo (thường gọi ngắn gọn là neural network) được cấu thành từ các nút mạng (nodes) có liên kết với nhau.
Một mạng nơ-ron thường bao gồm nhiều lớp (layers):
- Lớp đầu vào (input layer)
- Lớp đầu ra (output layer)
- Một hoặc nhiều lớp ẩn ở giữa (hidden layers)
Thông tin chỉ được truyền từ lớp này sang lớp khác khi giá trị đầu ra vượt qua một ngưỡng nhất định. Cơ chế này giúp mô hình học cách lọc thông tin quan trọng và loại bỏ nhiễu không cần thiết.
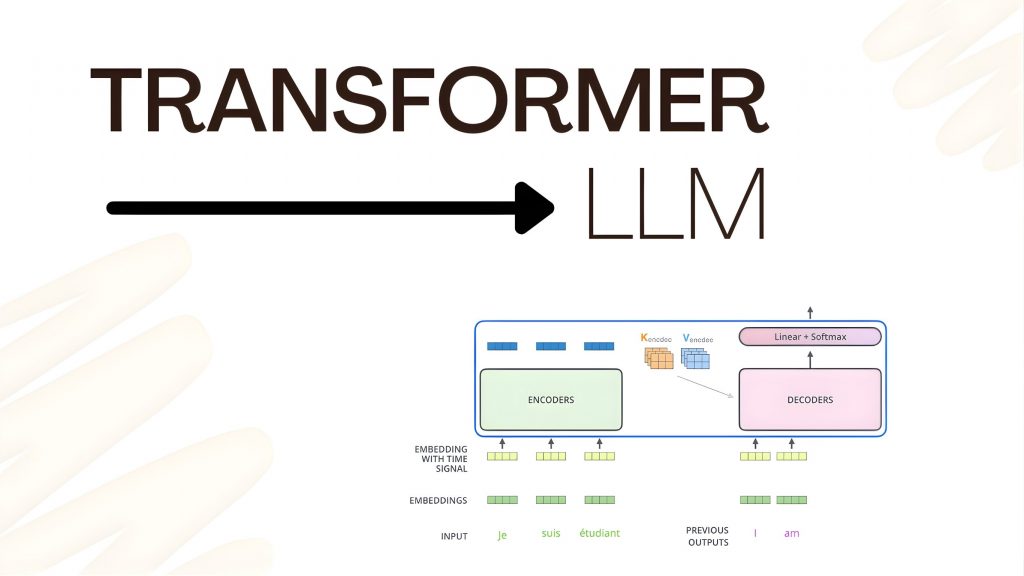
Mô hình transformer trong LLM
Loại mạng nơ-ron cụ thể được sử dụng trong LLM được gọi là mô hình Transformer. Điểm mạnh cốt lõi của Transformer là khả năng hiểu ngữ cảnh, yếu tố cực kỳ quan trọng đối với ngôn ngữ tự nhiên, vốn phụ thuộc rất nhiều vào ngữ cảnh.
Mô hình Transformer sử dụng một kỹ thuật toán học gọi là self-attention để phát hiện mối quan hệ tinh tế giữa các thành phần trong một chuỗi dữ liệu. Nhờ đó, Transformer vượt trội hơn nhiều phương pháp machine learning khác trong việc hiểu ngữ cảnh, chẳng hạn như:
- Cách phần cuối của câu liên kết với phần đầu
- Cách các câu trong cùng một đoạn văn liên quan với nhau
Chính cơ chế này cho phép LLM diễn giải ngôn ngữ con người, ngay cả khi:
- Câu chữ mơ hồ hoặc không được định nghĩa rõ ràng
- Từ ngữ được kết hợp theo cách mô hình chưa từng gặp trước đây
- Nội dung được đặt trong bối cảnh hoàn toàn mới
Ở một mức độ nhất định, LLM có thể được xem là “hiểu” ngữ nghĩa, vì nó có khả năng liên kết từ ngữ và khái niệm dựa trên ý nghĩa, sau khi đã tiếp xúc với hàng triệu hoặc hàng tỷ ví dụ tương tự trong quá trình huấn luyện.
>>> Xem thêm:
- Suy Luận Trong Thị Giác Máy Tính: Cách Thực Hiện & Triển Khai Mô Hình AI
- Hệ thống kiểm tra thị giác (VIS) là gì?
- Các Nhiệm Vụ Của Thị Giác Máy Tính và cách thực hiện chúng nhanh chóng
Ưu điểm và hạn chế của LLM là gì?
Ưu điểm của LLM
Một đặc điểm nổi bật của LLM là khả năng phản hồi các truy vấn không đoán trước. Các chương trình máy tính truyền thống chỉ hoạt động trong tập lệnh và đầu vào cố định:
- Trò chơi điện tử có số lượng nút bấm giới hạn
- Ứng dụng chỉ cho phép người dùng click hoặc nhập trong phạm vi nhất định
- Ngôn ngữ lập trình dựa trên các câu lệnh if/then chính xác
Ngược lại, LLM có thể hiểu và phản hồi ngôn ngữ tự nhiên của con người. Nhờ khả năng phân tích dữ liệu, LLM có thể trả lời các câu hỏi phi cấu trúc theo cách hợp lý. Ví dụ, một chương trình truyền thống sẽ không hiểu câu hỏi: “Bốn ban nhạc funk vĩ đại nhất lịch sử là ai?”, nhưng một LLM có thể đưa ra danh sách, kèm theo lập luận tương đối thuyết phục.
Hạn chế và rủi ro của LLM
Tuy nhiên, LLM chỉ đáng tin cậy ở mức độ dữ liệu mà nó được huấn luyện. Nếu dữ liệu đầu vào chứa thông tin sai lệch, LLM cũng sẽ trả về thông tin sai. Ngoài ra, LLM đôi khi còn gặp hiện tượng “hallucination” (ảo giác), tự tạo ra thông tin không có thật khi không thể đưa ra câu trả lời chính xác.
Ví dụ, vào năm 2022, tạp chí Fast Company từng hỏi ChatGPT về kết quả tài chính quý trước của công ty Tesla. Dù ChatGPT tạo ra một bài viết nghe rất hợp lý, phần lớn thông tin trong đó là bịa đặt.
Về mặt bảo mật, các ứng dụng sử dụng LLM cũng dễ gặp lỗi như bất kỳ phần mềm nào khác. Ngoài ra:
- LLM có thể bị thao túng bởi các đầu vào độc hại
- Có nguy cơ tạo ra nội dung nguy hiểm hoặc phi đạo đức
- Người dùng có thể vô tình nhập dữ liệu nhạy cảm hoặc bí mật để tăng năng suất làm việc
Trong khi đó, LLM không được thiết kế như một kho dữ liệu an toàn. Các dữ liệu đầu vào có thể được dùng để huấn luyện thêm mô hình và có khả năng bị lộ ra trong các truy vấn khác.
>>> Xem thêm:
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
- Cách sử dụng AI trong phát triển phần mềm như thế nào?
- Hướng dẫn tạo Landing Page bằng AI hiệu quả nhất hiện nay
Cách lập trình viên bắt đầu xây dựng LLM nhanh chóng
Để phát triển ứng dụng dựa trên LLM, lập trình viên cần:
- Truy cập nhiều bộ dữ liệu lớn
- Có hạ tầng lưu trữ dữ liệu phù hợp
Tuy nhiên, cả lưu trữ đám mây lẫn on-premises đều có thể đòi hỏi chi phí hạ tầng vượt quá ngân sách của nhiều đội ngũ phát triển. Việc gom dữ liệu từ nhiều nguồn về một nơi cũng có thể phát sinh chi phí egress rất lớn.
Giải pháp là các nền tảng hạ tầng AI như Cloudflare, nơi cung cấp nhiều dịch vụ giúp lập trình viên nhanh chóng thử nghiệm LLM và các ứng dụng AI khác.
- Vectorize: cơ sở dữ liệu vector phân tán toàn cầu
- Cloudflare Workers AI: nền tảng phát triển AI
Kết hợp các công cụ này, lập trình viên có thể bắt đầu xây dựng và thử nghiệm LLM một cách nhanh chóng, linh hoạt và tiết kiệm chi phí.
>>> Xem thêm:
- Khả năng thị giác của Chat GPT-5 và Cách Prompt hiệu quả
- LLMs.txt là gì? Có nên sử dụng không?
- Các nền tảng gán nhãn dữ liệu cho thị giác máy tính tốt nhất
- Thiết kế website bằng AI (trí tuệ nhân tạo) miễn phí

Câu hỏi thường gặp
Mô hình ngôn ngữ lớn (LLM) là gì?
Mô hình ngôn ngữ lớn là một mô hình AI được huấn luyện trên các tập dữ liệu khổng lồ để nhận diện, diễn giải và tạo ra văn bản. Khi được prompt, LLM có thể tạo văn bản hoặc khối mã nguồn chỉ trong vài giây. Người dùng có thể tương tác với LLM bằng ngôn ngữ tự nhiên thay vì thông qua giao diện cố định hoặc ngôn ngữ lập trình.
LLM hoạt động như thế nào?
LLM sử dụng học sâu để phân tích lượng lớn dữ liệu phi cấu trúc và học từ đó. Chúng được xây dựng trên mạng nơ-ron nhân tạo, cụ thể là mô hình transformer, sử dụng kỹ thuật self-attention để học và hiểu ngữ cảnh — yếu tố then chốt trong việc diễn giải ngôn ngữ con người.
LLM được dùng để làm gì?
LLM được ứng dụng rộng rãi trong:
- AI tạo sinh (generative AI)
- Phân tích cảm xúc
- Chatbot chăm sóc khách hàng
- Tìm kiếm trực tuyến
- Hỗ trợ lập trình viên viết code
Ví dụ LLM trong thực tế là gì?
Một số LLM nổi tiếng gồm:
- ChatGPT – OpenAI
- Gemini – Google
- Llama – Meta
- Bing Chat – Microsoft
- GitHub Copilot – hỗ trợ lập trình
Ưu điểm nổi bật của LLM so với ứng dụng khác là gì?
Ưu điểm lớn nhất của LLM là khả năng xử lý các câu hỏi không có cấu trúc và khó đoán trước. Không giống chương trình truyền thống cần lệnh chính xác, LLM có thể hiểu và phản hồi ngôn ngữ tự nhiên, kể cả khi câu hỏi mơ hồ hoặc chưa từng gặp.
Hạn chế và rủi ro của LLM là gì?
LLM có thể:
- Trả về thông tin sai nếu dữ liệu huấn luyện không chính xác
- “Ảo giác” và bịa nội dung
- Gặp rủi ro bảo mật nếu người dùng nhập dữ liệu nhạy cảm
>>> Xem thêm:
- Thị giác máy tính trong ngành nhà hàng đang tái định hình mô hình vận hành như thế nào?
- Hướng dẫn Gán Nhãn Dữ Liệu AI
- Đếm Đối Tượng Bằng Thị Giác Máy Tính
Hiểu rõ LLM là gì giúp bạn nắm được nền tảng cốt lõi của AI tạo sinh hiện nay. Với khả năng xử lý ngôn ngữ linh hoạt, LLM đang được ứng dụng rộng rãi trong nhiều lĩnh vực, nhưng vẫn tồn tại rủi ro về độ chính xác và bảo mật. Việc sử dụng LLM hiệu quả đòi hỏi hiểu đúng bản chất công nghệ và áp dụng phù hợp với từng nhu cầu cụ thể.
Nguồn tham khảo: What is an AI agent?
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam






