Hãy tưởng tượng bạn đang huấn luyện một robot hiểu thế giới bằng “đôi mắt” của nó. Bạn cho nó xem một bức ảnh con mèo và nói: “Đây là một con mèo.” Rồi đến một bức ảnh con chó: “Đây là một con chó.” Nhưng robot không chỉ cần nhận diện chúng, mà còn phải biết “con mèo đang ngồi ở đâu?”, “phần nào là cái đuôi?”, hoặc “con chó có đang ngậm thứ gì trong miệng không?”. Để làm được điều này, bạn phải gán nhãn cho hình ảnh bằng các thông tin chi tiết.
Quá trình này được gọi là data annotation (gán nhãn dữ liệu/chú thích dữ liệu), và đây chính là nền tảng của việc dạy máy móc nhìn giống con người. Trong lĩnh vực rộng lớn của computer vision (thị giác máy tính), độ chính xác của một mô hình phụ thuộc rất nhiều vào chất lượng và độ chuẩn xác của dữ liệu mà nó được huấn luyện. Hôm nay, chúng tôi sẽ chia sẻ một số nền tảng gán nhãn dữ liệu cho thị giác máy tính tốt nhất để giúp các dự án computer vision của bạn có thiết lập thuận lợi và đi đến thành công.
>>> Xem thêm các bài viết liên quan:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
- Hướng dẫn triển khai AI trong ứng dụng di động đơn giản
Gán nhãn dữ liệu trong thị giác máy tính là gì?
Gán nhãn dữ liệu là một bước nền tảng khi xây dựng các hệ thống thị giác máy tính. Nó bao gồm việc gán nhãn cho dữ liệu thị giác, chẳng hạn như hình ảnh hoặc các khung hình video, bằng những thông tin mà mô hình học máy có thể sử dụng để học cách nhận biết và diễn giải các mẫu thị giác. Những nhãn này đóng vai trò như ground truth (nhãn chuẩn/chân lý chuẩn), định hướng mô hình trong quá trình huấn luyện để nó học cách đưa ra dự đoán chính xác khi gặp dữ liệu mới, chưa từng thấy.
Trong bối cảnh thị giác máy tính, loại và định dạng gán nhãn sẽ thay đổi tùy theo tác vụ cụ thể mà mô hình đang được huấn luyện. Dưới đây là những kỹ thuật gán nhãn dữ liệu phổ biến nhất, dùng để chuẩn bị bộ dữ liệu cho các tác vụ như phân loại ảnh, phát hiện đối tượng, phân đoạn, ước lượng tư thế, và nhiều tác vụ khác.
Nhãn phân loại
Nhãn phân loại gán một thẻ hoặc một lớp duy nhất cho toàn bộ hình ảnh. Điều này có nghĩa là hình ảnh được gán nhãn như một tổng thể, mà không chỉ rõ vị trí các đối tượng nằm ở đâu bên trong ảnh. Nhãn phân loại được dùng trong các tác vụ phân loại ảnh, nơi mục tiêu là dạy mô hình phân loại hình ảnh vào các lớp đã định nghĩa trước.
Ví dụ, trong một bộ dữ liệu bệnh cây trồng, một ảnh có thể được gán nhãn “healthy (khỏe mạnh)” trong khi ảnh khác được gán nhãn “early blight (bệnh sương mai giai đoạn sớm)”. Mô hình học cách phân loại ảnh mới vào một trong các nhóm này dựa trên các mẫu thị giác.
>>> Xem thêm:
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow

Nhãn phân loại là dạng gán nhãn đơn giản nhất và đặc biệt hiệu quả khi vị trí đối tượng không cần thiết; chỉ danh mục mới là điều quan trọng.
Bounding Box
Bounding box là một dạng chú thích hình chữ nhật được vẽ quanh các đối tượng trong ảnh. Mỗi hộp thường gắn với một nhãn lớp, cho biết đối tượng bên trong là gì. Hộp giới hạn được dùng trong các tác vụ phát hiện đối tượng, nơi mô hình vừa cần định vị vừa cần phân loại nhiều đối tượng trong cùng một hình ảnh. Ví dụ, phát hiện và gán nhãn tất cả ô tô, người và xe đạp trong một cảnh đường phố. Mỗi đối tượng được bao trong một hộp và gán nhãn “car”, “person”, v.v.
>>> Xem thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Các mô hình phát hiện đối tượng tốt nhất

Bounding box tạo ra sự cân bằng giữa mức độ chi tiết của gán nhãn và hiệu suất, khiến nó phù hợp cho các ứng dụng thời gian thực như xe tự hành và giám sát video.
Gán nhãn đa giác
Gán nhãn đa giác được tạo bằng cách nối một chuỗi các điểm để viền theo hình dạng chính xác của đối tượng. Khác với bounding box luôn là hình chữ nhật, gán nhãn đa giác có thể bám theo đường biên thực của đối tượng. Gán nhãn đa giác có thể dùng trong các tác vụ phân đoạn theo cá thể và phân đoạn ngữ nghĩa khi cần ranh giới đối tượng chính xác. Ví dụ, viền theo silhouette của một con chó, ranh giới chính xác của một biển báo giao thông, hoặc hình dạng mái nhà trong ảnh vệ tinh.
>>> Xem thêm:
- Các Mô Hình Ngôn Ngữ Thị Giác Chạy Cục Bộ Tốt Nhất
- Phát hiện đối tượng trong video với RF-DETR

V
Gán nhãn đa giác cho độ chính xác cao hơn bounding box, đặc biệt khi làm việc với hình dạng bất quy tắc hoặc khi các đối tượng nằm sát nhau, chồng lấn.
Điểm mốc
Điểm mốc/điểm then chốt là các tọa độ riêng lẻ được đánh dấu tại những phần cụ thể của một đối tượng. Chúng thường được dùng để theo dõi chuyển động hoặc cấu trúc bằng cách làm nổi bật các điểm quan trọng. Điểm mốc được sử dụng trong các tác vụ ước lượng tư thế, nhận diện khuôn mặt và nhận diện cử chỉ. Ví dụ về điểm mốc gồm việc đánh dấu các khớp như vai, khuỷu tay và đầu gối trong bộ dữ liệu tư thế người, hoặc xác định các góc của mắt, mũi và miệng trong phát hiện mốc khuôn mặt.
>>> Xem thêm:
- Suy Luận Trong Thị Giác Máy Tính: Cách Thực Hiện & Triển Khai Mô Hình AI
- Hệ thống kiểm tra thị giác (VIS) là gì?
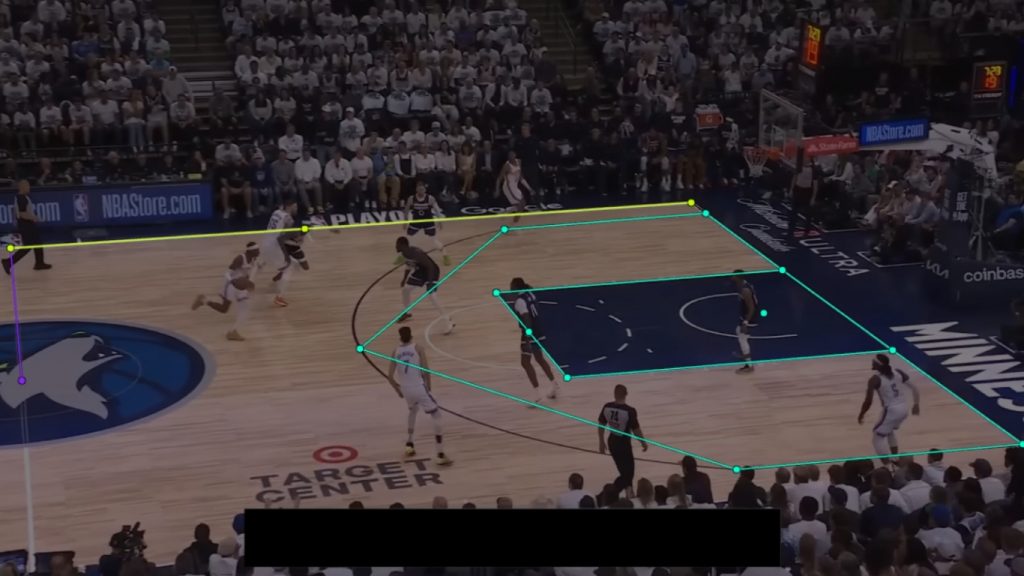
Gán nhãn điểm mốc là yếu tố then chốt để hiểu cấu trúc và chuyển động đối tượng ở mức chi tiết, cho phép các ứng dụng như theo dõi tập luyện, thử đồ ảo và diễn giải ngôn ngữ ký hiệu.
Mặt nạ phân đoạn
Phân đoạn bao gồm việc gán nhãn mọi pixel trong hình ảnh bằng một lớp. Có hai loại chính:
- Phân đoạn ngữ nghĩa gán một lớp cho mọi pixel (ví dụ: road, tree, building).
- Phân đoạn theo cá thể không chỉ phân loại pixel mà còn phân biệt giữa các cá thể khác nhau của cùng một lớp đối tượng.
Mặt nạ phân đoạn được dùng khi cần độ chính xác mức pixel, chẳng hạn trong chẩn đoán hình ảnh y tế, xe tự hành hoặc nông nghiệp. Ví dụ, trong ảnh trang trại chụp từ trên cao, gán nhãn mỗi pixel là “crop (cây trồng)”, “soil (đất)”, hoặc “weed (cỏ dại)”. Trong ảnh chụp CT, đánh dấu mọi pixel đại diện cho khối u.
>>> Xem thêm:
- Các Nhiệm Vụ Của Thị Giác Máy Tính và cách thực hiện chúng nhanh chóng
- Học Máy Là Gì Và Tại Sao Học Máy Lại Quan Trọng?

Mặt nạ phân đoạn cung cấp mức hiểu chi tiết nhất về nội dung thị giác và là yếu tố thiết yếu cho các tác vụ cần ranh giới đối tượng chính xác.
Cách đánh giá nền tảng gán nhãn dữ liệu tốt nhất
Việc lựa chọn đúng nền tảng gán nhãn dữ liệu cho thị giác máy tính là một trong những quyết định quan trọng nhất trong bất kỳ pipeline machine learning hoặc computer vision nào. Một công cụ gán nhãn chất lượng cao tác động trực tiếp đến độ chính xác của mô hình AI, hiệu suất của đội ngũ và chi phí/khả năng mở rộng của quy trình gán nhãn. Nhưng khi có quá nhiều công cụ, bạn xác định đâu là lựa chọn tốt nhất cho use case của mình bằng cách nào?
Dưới đây là các yếu tố quan trọng nhất định nghĩa một nền tảng gán nhãn dữ liệu xuất sắc:
Khả năng của công cụ gán nhãn
Về cốt lõi, một nền tảng gán nhãn phải hỗ trợ đúng các loại tác vụ mà mô hình của bạn đang được huấn luyện. Bao gồm:
- Classification Labels: Gán nhãn toàn bộ ảnh bằng một lớp duy nhất.
- Bounding Boxes: Vẽ hình chữ nhật để định vị đối tượng (dùng trong object detection).
- Polygons: Viền theo hình dạng bất quy tắc của đối tượng cho instance hoặc semantic segmentation.
- Keypoints: Xác định tọa độ cụ thể (ví dụ: mốc khuôn mặt hoặc khớp cơ thể).
- Segmentation Masks: Gán nhãn mức pixel để hiểu cảnh (scene understanding) chi tiết.
- Video Annotation: Gán nhãn đối tượng qua nhiều khung hình với nội suy (interpolation).
- 3D Annotation: Gán nhãn dữ liệu thể tích như LiDAR hoặc ảnh chụp CT/MRI (ít phổ biến hơn).
Khi tìm các tính năng như vậy, các câu hỏi then chốt cần đặt ra là:
- Công cụ có hỗ trợ tất cả các loại gán nhãn bắt buộc không?
- Công cụ có xử lý được video annotation, không chỉ hình ảnh không?
- Công cụ có hỗ trợ multi-class và multi-label trong cùng một ảnh không?
- Công cụ có thể gán nhãn cấu trúc lồng nhau (ví dụ: đối tượng bên trong đối tượng) không?
- Công cụ có hỗ trợ 3D annotation (nếu cần) không?
Hiệu năng của mô hình AI phụ thuộc rất lớn vào chất lượng và cấu trúc của annotation. Nếu use case của bạn cần mặt nạ chính xác đến từng pixel (pixel-perfect masks), một công cụ chỉ giới hạn ở bounding box sẽ không đủ.
Giao diện người dùng & khả năng sử dụng
Một giao diện mượt mà, trực quan là thiết yếu, đặc biệt khi cần gán nhãn hàng nghìn hình ảnh. Nền tảng cần tạo cảm giác tự nhiên, công thái học (ergonomic) và không gây ức chế cho cả annotator cá nhân lẫn đội nhóm. Các tính năng UI tốt bao gồm:
- Hotkeys và phím tắt để giảm thao tác click lặp lại
- Zoom/pan và object snapping để làm việc chính xác.
- Undo/redo, nhân bản đối tượng (object cloning) và tự động hoàn thành nhãn (label autocomplete).
- Bố cục sạch, không làm phân tâm khỏi hình ảnh đang gán nhãn.
- Dark/light mode và hỗ trợ khả năng tiếp cận (accessibility) cho nhiều nhóm người dùng.
Một UI được thiết kế tốt có thể tăng gấp đôi năng suất và giảm đáng kể mệt mỏi hoặc lỗi gán nhãn. Giao diện cần trực quan, nhanh và tối thiểu hóa mệt mỏi cho người dùng. Các tính năng liên quan đến UI mà bạn nên tìm gồm:
- Công cụ vẽ mượt (snapping, zoom, drag-and-drop).
- Hotkeys và phím tắt để gán nhãn nhanh hơn.
- Điều hướng ảnh (next/prev, lọc theo nhãn, thao tác hàng loạt).
- Hiệu quả thao tác bàn phím so với chuột.
- Tự động lưu (auto-save) và chức năng undo/redo.
Gán nhãn là công việc lặp lại. UI sạch, dễ dùng sẽ giảm thời gian gán nhãn, giảm lỗi và giảm mệt mỏi, đặc biệt với bộ dữ liệu lớn.
Tốc độ & tự động hóa trong gán nhãn
Gán nhãn thủ công hàng nghìn ảnh rất tốn thời gian. Các nền tảng tốt nhất tăng tốc bằng các công cụ tự động hóa, có thể bao gồm:
- Pre-labeling bằng mô hình AI (ví dụ: SAM, Grounding DINO).
- Công cụ vẽ thông minh như auto-segmentation hoặc polygon expansion.
- Vòng lặp active learning, nơi mô hình học từ chỉnh sửa của người dùng và cải thiện gán nhãn theo thời gian.
- Công cụ nội suy để gán nhãn đối tượng qua các khung hình video mà không phải làm lại từng frame.
Những tính năng này giảm thời gian gán nhãn, tăng tính nhất quán và cho phép annotator tập trung vào edge cases và hiệu chỉnh thay vì xử lý từng nhãn một cách thủ công. Một nền tảng gán nhãn phải giúp tăng tốc thông qua tự động hóa. Khi đánh giá, bạn có thể hỏi:
- Công cụ có thể dùng mô hình pre-trained để gợi ý annotation không?
- Bạn có thể kết nối mô hình của riêng mình cho active learning hoặc pre-labeling không?
- Công cụ có hỗ trợ interpolation, đặc biệt cho video và time-series annotation không?
- Công cụ có cung cấp gán nhãn bán tự động như click to outline, smart polygon hoặc image segmentation wizards không?
Gán nhãn thủ công có chi phí cao. Khả năng tự động hóa 60–90% annotation có thể tiết kiệm hàng nghìn giờ và rút ngắn timeline dự án.
Quản lý dự án & quy trình làm việc
Trong bối cảnh triển khai thực tế, annotation hiếm khi do một người thực hiện. Nó liên quan đến đội nhóm, vòng review và đảm bảo chất lượng. Công cụ gán nhãn nên có các năng lực quản lý dự án và workflow như:
- User roles: Gán quyền khác nhau (Annotator, Reviewer, Manager).
- Task assignment: Phân phối hình ảnh cho người dùng hoặc nhóm.
- Quality control tools: So sánh annotation từ nhiều người, tính điểm đồng thuận (agreement scores).
- Commenting và issue tracking: Giải quyết tranh chấp nhãn hoặc đánh dấu trường hợp không chắc chắn.
- Progress tracking: Dashboard theo dõi mức độ đã gán nhãn, đã review hoặc cần sửa.
Một nền tảng tốt đóng vai trò như “collaboration hub”, không chỉ là công cụ vẽ, vì annotation thường liên quan đến đội nhóm và nhiều giai đoạn review. Khi tìm các tính năng này, bạn có thể hỏi:
- Công cụ có cho phép giao nhiệm vụ cho người dùng không?
- Có roles và permissions (annotator, reviewer, admin) không?
- Có quality control (ví dụ: consensus scoring, inter-annotator agreement) không?
- Có thể theo dõi tiến độ, thống kê và hiệu suất của annotator không?
Các dự án lớn cần workflow đội nhóm có khả năng mở rộng. Nếu không có QA và task management tích hợp, chất lượng dữ liệu và điều phối đội nhóm sẽ bị ảnh hưởng.
Hỗ trợ định dạng & xuất bộ dữ liệu
Nền tảng cần tích hợp “sạch” vào ML workflow bằng cách hỗ trợ các định dạng dữ liệu cần thiết. Nền tảng nên cung cấp:
- Import ảnh, video (trong trường hợp huấn luyện mô hình thị giác máy tính).
- Export các định dạng như YOLO, COCO, Pascal VOC, TFRecord, CSV và JSON.
- Khả năng chuyển đổi giữa các định dạng hoặc export các trường tùy chỉnh.
Tính linh hoạt trong cách dữ liệu được lưu trữ, import và export là then chốt. Khi đánh giá các tính năng này, bạn có thể hỏi:
- Công cụ có thể import/export các định dạng phổ biến không? (YOLO, COCO, Pascal VOC, CSV, TFRecord, v.v.)?
- Bạn có thể chuyển đổi dataset giữa các định dạng một cách dễ dàng không?
Mô hình AI thường yêu cầu định dạng cụ thể. Một công cụ tốt sẽ giảm nhu cầu hậu xử lý và giảm rắc rối khi chuyển đổi định dạng.
Khả năng mở rộng & tích hợp
Workflow AI hiện đại rất phức tạp. Một nền tảng gán nhãn tốt phải có khả năng lập trình và mở rộng để có thể “cắm” vào pipeline huấn luyện và đánh giá. Một nền tảng gán nhãn tốt cần cung cấp:
- Python SDK và REST APIs để tự động hóa import, tạo task và export.
- CLI tools để scripting và tích hợp với pipeline CI/CD.
- Hỗ trợ tích hợp mô hình (ví dụ: kết nối mô hình để auto-labeling).
- Hỗ trợ cloud storage: import/export từ AWS S3, GCS, Azure.
Mục tiêu là nền tảng gán nhãn hoạt động như một thành phần trong hệ thống AI của bạn, không phải một GUI tách biệt. Các công cụ tốt tích hợp liền mạch vào ML workflow. Khi tìm các tính năng này, bạn có thể hỏi:
- Có Python SDK, REST API hoặc CLI tool không?
- Có thể tích hợp với cloud storage (S3, GCP, Azure) không?
- Có thể cắm vào training pipelines hoặc nền tảng MLOps không?
- Bạn có thể viết plugin cho logic tùy chỉnh hoặc workflow gán nhãn không?
Những nền tảng tốt nhất hoạt động như một phần của vòng đời ML, không phải một “silo”. Tích hợp tốt giúp giảm ma sát giữa gán nhãn và huấn luyện mô hình.
Chi phí, giấy phép & khả năng mở rộng
Công cụ gán nhãn có nhiều mô hình giá và hình thái triển khai:
- Công cụ open-source miễn phí nhưng có thể thiếu hỗ trợ doanh nghiệp.
- Công cụ SaaS tính phí theo seat, theo task hoặc theo dataset, đồng thời cung cấp hỗ trợ và nhiều tính năng phong phú.
- Một số công cụ chạy cục bộ, trong khi công cụ khác đa nền tảng hoặc web-based.
- Đánh giá giới hạn trong gói miễn phí (ví dụ: hạn chế export, giới hạn dung lượng dataset).
Hãy chọn nền tảng cân bằng giữa chi phí, tính năng và hỗ trợ phù hợp quy mô đội ngũ và tốc độ tăng trưởng. Các cân nhắc thực tế thường quyết định lựa chọn công cụ trong bối cảnh triển khai thật. Các câu hỏi cần đặt ra:
- Miễn phí, open-source hay subscription-based?
- Bản miễn phí có giới hạn kích thước dataset, số người dùng hoặc loại annotation không?
- Công cụ có mở rộng đến hàng triệu ảnh hoặc hỗ trợ cộng tác đội nhóm không?
- Giá được tính theo seats, tasks hay storage?
- Công cụ có gói dành cho học thuật và nghiên cứu không?
Startup và nhóm nghiên cứu có thể cần công cụ tiết kiệm hoặc open-source. Doanh nghiệp có thể cần hỗ trợ, cam kết uptime và giải pháp lưu trữ dữ liệu.
Một nền tảng gán nhãn tốt phụ thuộc vào loại dữ liệu (ảnh, video, v.v.), độ phức tạp tác vụ (classification vs segmentation vs multi-modal), quy mô đội nhóm và việc bạn có cần cộng tác hoặc tự động hóa hay không, cùng yêu cầu về quyền riêng tư, tùy biến và tối ưu chi phí.
Bằng cách đánh giá cẩn thận các nền tảng theo tiêu chí ở trên, bạn có thể chọn công cụ phù hợp nhất với workflow gán nhãn và cuối cùng tạo ra dữ liệu huấn luyện tốt hơn cho mô hình machine learning.
>>> Xem thêm:
- Hướng dẫn cách sử dụng Google AI Studio hiệu quả, nhanh chóng
- AI trong thiết kế UI/UX: Công cụ hay đối thủ của Designer?
Nền tảng gán nhãn dữ liệu tốt nhất
Trong phần này, chúng ta sẽ thảo luận một số công cụ gán nhãn dữ liệu hữu ích để đáp ứng yêu cầu của các dự án thị giác máy tính.
1. Roboflow
Roboflow là một nền tảng all-in-one để quản lý các bộ dữ liệu thị giác máy tính, thực hiện gán nhãn dữ liệu, tăng cường dữ liệu (augmentation), huấn luyện mô hình và triển khai. Nền tảng này hỗ trợ nhiều loại annotation và định dạng khác nhau, đồng thời được sử dụng rộng rãi trong nghiên cứu lẫn công nghiệp.
Dưới đây là các tính năng chính của Roboflow:
- Smart Annotation Tools: Hỗ trợ bounding boxes, polygons, segmentation, keypoints, và classification.
- AI Assisted labeling: Hỗ trợ auto-labeling với các mô hình pre-trained và các công cụ Label Assist, Smart Polygon, Box Prompting, Auto Label.
- Automated Preprocessing and Augmentation: Hỗ trợ đầy đủ tiền xử lý (pre-processing) như auto-orientation, resizing và data augmentation.
- Active Learning: Ưu tiên gán nhãn cho những ảnh giúp cải thiện hiệu năng mô hình nhiều nhất.
- Roboflow Universe: Kho dữ liệu mở với 200,000+ dataset đã gán nhãn sẵn.
- Model Training & Deployment: Huấn luyện mô hình với nhiều kiến trúc như YOLO, RF-DETR, v.v., và triển khai qua API hoặc thiết bị biên (edge devices).
- User Friendly UI: Cung cấp giao diện GUI web-based thân thiện.
- Dataset versioning: Hỗ trợ tạo nhiều phiên bản dataset khác nhau.
- Integration: Hỗ trợ tích hợp liền mạch với các ML framework phổ biến và import/export dataset trực tiếp.
- SDK Support: Cung cấp REST API và Roboflow Python SDK cho tự động hóa.
Roboflow có điểm gì khác biệt?
Roboflow nổi bật nhờ năng lực gán nhãn tăng cường bằng AI mạnh mẽ, bao gồm Label Assist, Smart Polygon, Box Prompting, Auto Label, và Roboflow Instant (mới ra mắt) giúp tự động hóa hoàn toàn gán nhãn cho các tác vụ object detection, instance segmentation và keypoint bằng các foundation models như Segment Anything và CLIP.
Ngoài annotation, Roboflow cung cấp huấn luyện và đánh giá mô hình end-to-end ngay trong dashboard, hỗ trợ các kiến trúc state-of-the-art (ví dụ: YOLOv11, YOLOv12, RF-DETR, Roboflow 3.0), với các metric tích hợp như confusion matrices, precision, recall và mAP, giúp việc lặp nhanh và liền mạch.
Điều thực sự tạo khác biệt là Roboflow Instant: công cụ này tự động huấn luyện một mô hình object detection few-shot ngay khi bạn phê duyệt annotation (hoặc khi bạn kích hoạt huấn luyện thủ công), đồng thời cung cấp mô hình ngay lập tức trong nền tảng để phục vụ inference và các workflow gán nhãn, cho phép rapid prototyping với dữ liệu tối thiểu và không cần thiết lập hạ tầng.
Sự tích hợp liền mạch giữa annotation, huấn luyện tức thời (instant model training), đánh giá và triển khai, kết hợp với Roboflow Workflow là một pipeline builder trực quan hoàn toàn (visual), low-code, có thể kết hợp mô hình custom-trained hoặc foundation models (như CLIP, SAM-2 hoặc GPT-4 with Vision) với các khối thị giác máy tính truyền thống (classical CV blocks), conditional logic, LLM APIs và visualizers.
Bạn có thể prototype logic ngay trên trình duyệt bằng các block và template triển khai có sẵn, sau đó export một đoạn code snippet hoặc triển khai trực tiếp lên cloud, dedicated servers hoặc edge devices mà không cần thêm hạ tầng. Điều này khiến Roboflow có năng lực “bắc cầu” giữa tạo dataset, inference, application logic và triển khai trong một môi trường tương tác duy nhất, điều mà các công cụ đơn lẻ không cung cấp được.
Gán nhãn hình ảnh để phát hiện đối tượng trong Roboflow
Dưới đây là các bước để gán nhãn dataset phục vụ huấn luyện mô hình object detection trong Roboflow.
Bước #1: Tạo dự án & Tải dữ liệu lên
Đăng nhập Roboflow và tạo một project mới, chọn “Object Detection” làm loại project. Tải lên hình ảnh của bạn (và annotation hiện có nếu có). Roboflow sẽ xử lý dataset và cho phép bạn xác định train/validation/test splits.
Bước #2: Mở giao diện gán nhãn
Từ mục Annotate, assign images và click vào một ảnh để mở Roboflow Annotate interface. Đây là nơi bạn sẽ vẽ bounding box.
Bước #3: Vẽ Bounding Boxes
Bounding Box Tool (“B”): Click và kéo để tạo một box mới, sau đó chọn hoặc nhập class label.
Bước #4: Sử dụng các công cụ AI hỗ trợ
- Label Assist sử dụng mô hình pre-trained hoặc mô hình custom của bạn (từ Roboflow Universe) để tự động tạo dự đoán bounding box mỗi khi bạn mở ảnh, giúp giảm đáng kể công sức thủ công.
- Box Prompting học từ các ví dụ bounding box ban đầu bạn vẽ thủ công, sau đó dự đoán các box tương tự trên ảnh hoặc dataset, và cải thiện khi bạn cung cấp thêm ví dụ và negative feedback.
- Auto Label chạy foundation model như Grounding DINO hoặc CLIP để batch auto-label ảnh của bạn bằng bounding box trong một lần, phù hợp với dataset lớn và các lớp đối tượng phổ biến.
Bước #5: Hoàn tác / Làm lại / Lặp lại
Dùng Undo/Redo để sửa lỗi, và Repeat Previous để áp dụng cùng bố cục annotation cho các ảnh tương tự nhằm tăng tốc workflow.
Bước #6: Hoàn tất & thêm vào Dataset
Sau khi gán nhãn xong, click “Add Images to Dataset” để đưa chúng vào dataset đã gán nhãn phục vụ huấn luyện.
Bước #7: Huấn luyện hoặc Export
Huấn luyện trực tiếp trong Roboflow bằng các pipeline tích hợp tương thích với YOLOv8 và các mô hình state-of-the-art khác, hoặc export annotation theo các định dạng như YOLO, COCO hoặc Pascal VOC để huấn luyện bên ngoài.
2. Autodistill
Autodistill là một framework open-source tự động hóa quá trình gán nhãn dataset ảnh bằng cách sử dụng các foundation models lớn (gọi là Base Models) như Grounding DINO hoặc GroundedSAM để tạo annotation dựa trên prompt ngôn ngữ tự nhiên hoặc ảnh ví dụ (được định nghĩa trong một Ontology). Các dataset được auto-label này sau đó được dùng để huấn luyện các Target Models nhỏ, hiệu quả như YOLOv8 hoặc DETR, tạo ra một Distilled Model có thể chạy nhanh trên edge devices hoặc trong production.
Toàn bộ quá trình này (gọi là Distillation), từ ảnh thô đến mô hình có thể triển khai, không yêu cầu gán nhãn thủ công. Autodistill có thể chạy trên phần cứng của bạn hoặc thông qua hạ tầng hosted của Roboflow. Nó đặc biệt hữu ích để xây dựng mô hình nhanh, theo tác vụ cụ thể khi bạn cần rapid iteration, active learning hoặc tạo dataset quy mô lớn mà không bị bottleneck bởi gán nhãn thủ công.
Distillation là gì?
Trong bối cảnh machine learning, distillation (hoặc knowledge distillation) là quá trình chuyển giao tri thức từ một mô hình lớn, mạnh (một “teacher”) sang một mô hình nhỏ hơn, nhanh hơn (một “student”).
Các tính năng chính của Autodistill
- Zero-Shot Labeling: Tự động gán nhãn ảnh bằng các foundation models lớn như Grounding DINO và Segment Anything, được dẫn dắt bởi các text prompt đơn giản, không cần annotation thủ công.
- Distillation Pipeline: Chuyển dữ liệu chưa gán nhãn thành mô hình nhanh, có thể triển khai (như YOLOv8) bằng cách chưng cất tri thức từ mô hình lớn sang mô hình nhỏ tối ưu cho edge use.
- Modular & Open Source: Kiến trúc plug-and-play cho phép thay base models, định nghĩa custom ontologies và tích hợp với công cụ như Roboflow và CVAT.
- Runs Anywhere: Hoạt động trên phần cứng local hoặc trên cloud, phù hợp cho phát triển offline và pipeline cloud quy mô lớn.
- Task-Specific Optimization: Tạo distilled models được fine-tune đúng với tác vụ object detection hoặc segmentation của bạn, đảm bảo hiệu năng cao với overhead tối thiểu.
Autodistill có điểm gì khác biệt?
Autodistill là một pipeline AI zero-annotation cho phép bạn chuyển các ảnh chưa gán nhãn trực tiếp thành mô hình có thể triển khai, tối ưu cho edge mà không cần công sức gán nhãn của con người. Nó sử dụng một giao diện modular có thể cắm ghép để kết nối các foundation models lớn (như Grounding DINO, Grounded SAM, OWL-ViT) với các supervised target models nhỏ (như RF-DETR, YOLOv8), tạo ra một distillation pipeline liền mạch từ dữ liệu thô đến mô hình sẵn sàng production.
Ngoài ra, nó còn bao gồm CVevals, một framework đánh giá open-source giúp bạn kiểm thử và tinh chỉnh prompt ngôn ngữ tự nhiên trước khi “commit” vào gán nhãn quy mô lớn, qua đó đảm bảo chất lượng và giảm lãng phí công sức.
Gán nhãn ảnh cho Object Detection bằng Autodistill
Bây giờ, hãy xem cách dùng Autodistill để gán nhãn ảnh bằng bounding box cho tác vụ object detection. Chúng ta cũng sẽ dùng Roboflow Supervision để trực quan hóa annotation.
Bước #1: Cài đặt thư viện cần thiết
!pip install autodistill autodistill-grounding-dino supervision -q
Bước #2: Chuẩn bị dataset
I have all my images in the /images directory.
Bước #3: Viết code
Trong ví dụ này, chúng ta sẽ dùng tổ hợp Base Model + Ontology để import mô hình lớn Grounding DINO nhằm tự động tạo nhãn bounding box mà không cần con người can thiệp. Dưới đây là code.
import cv2
from autodistill_grounding_dino import GroundingDINO
from autodistill.detection import CaptionOntology
ontology = CaptionOntology({
"a car": "car"
})
base_model = GroundingDINO(ontology=ontology)
# Run auto label on a folder of images
base_model.label(
input_folder="./images",
output_folder="./dataset"
)Đoạn code trên chạy base model Grounding DINO (qua Autodistill) để auto-annotate tất cả ảnh trong /images bằng prompt “a car”, tạo nhãn bounding box kiểu YOLO trong thư mục /dataset, trong đó “car” trở thành tên class trong các annotation đó.
Bước #4: Trực quan hóa annotation (tùy chọn)
Bây giờ, chúng ta sẽ dùng Supervision, một helper library được thiết kế để trực quan hóa detection một cách dễ dàng. Ở đây, chúng ta hiển thị bounding box trên ảnh. Bạn có thể trực quan hóa bằng đoạn code dưới đây.
import supervision as sv
from supervision import BoxAnnotator, LabelAnnotator, create_tiles
ds = sv.DetectionDataset.from_yolo(
images_directory_path="/content/dataset/train/images",
annotations_directory_path="/content/dataset/train/labels",
data_yaml_path="/content/dataset/data.yaml"
)
box = BoxAnnotator()
label = LabelAnnotator()
tiles = []
for _, image, det in ds:
if det is None or len(det.xyxy) == 0:
continue
labels = [ds.classes[cid] for cid in det.class_id]
img = box.annotate(scene=image.copy(), detections=det)
img = label.annotate(scene=img, detections=det, labels=labels)
tiles.append(img)
if tiles:
grid = create_tiles(tiles, grid_size=(2, 3), single_tile_size=(400, 400))
sv.plot_image(grid, size=(15, 15))
else:
print("No detections to visualize.")Đoạn code này dùng Supervision của Roboflow để load một detection dataset định dạng YOLO (qua sv.DetectionDataset.from_yolo), sau đó lặp qua từng ảnh và detections, vẽ bounding box quanh các đối tượng được phát hiện bằng BoxAnnotator và chồng nhãn lớp (class labels) bằng LabelAnnotator.
Nó bỏ qua những ảnh không có detections, gom các ảnh đã annotate vào một danh sách, và cuối cùng dùng create_tiles để ghép chúng thành một lưới 2×3 (mỗi tile được resize 400×400 px), sau đó hiển thị bằng sv.plot_image, cung cấp một cái nhìn tổng quan nhanh về các mẫu đã gán nhãn để kiểm tra. Bạn sẽ thấy output tương tự như sau.
>>> Xem thêm:
- Khả năng thị giác của Chat GPT-5 và Cách Prompt hiệu quả
- LLMs.txt là gì? Có nên sử dụng không?

3. CVAT (Computer Vision Annotation Tool)
CVAT (Computer Vision Annotation Tool) là một công cụ gán nhãn ảnh và video open-source, web-based, được phát triển bởi Intel và được OpenCV duy trì. Nó hỗ trợ các tác vụ annotation như object detection, classification, segmentation, tracking và polygon labeling.
Tính năng nổi bật của CVAT:
- Rich Annotation Tools: Vẽ bounding box, polygon, polyline, ellipse, cuboid, và keypoint.
- Video & Image Support: Gán nhãn theo từng frame hoặc theo chuỗi với interpolation.
- AI-Assisted Labeling: Dùng các mô hình tích hợp (ví dụ: DEXTR, Mask R-CNN) hoặc thậm chí mô hình Roboflow để gán nhãn tự động.
- Web-Based Interface: Truy cập đầy đủ công cụ từ trình duyệt mà không cần cài đặt cục bộ, hoặc self-host với Docker cho dự án lớn.
- Export Formats: Hỗ trợ COCO, YOLO, Pascal VOC và nhiều định dạng khác cho huấn luyện mô hình.
- Task Management: Tổ chức dataset qua tasks và jobs với semantic hierarchy và thiết lập lớp.
- Integration Friendly: Hoạt động cùng Roboflow, và annotation có thể export cho các pipeline huấn luyện tiếp theo.
CVAT có điểm gì khác biệt?
CVAT nổi bật nhờ sự kết hợp giữa công cụ thủ công chi tiết, gán nhãn bán tự động hỗ trợ AI phong phú và tính năng nội suy video hiệu quả, tất cả được đóng gói trong một giao diện web open-source có thể self-host. Người dùng được hưởng lợi từ các primitive gán nhãn ít gặp như cuboid, polyline, point và ellipse, cũng như các interactor tools hỗ trợ deep learning như DEXTR, Mask R-CNN, HRNet và tích hợp với mô hình Roboflow, giúp gán nhãn chính xác cao với ít công sức thủ công.
Ngoài ra, CVAT còn cung cấp tổ chức task/job, dashboard dự án, phím tắt tối ưu tốc độ gán nhãn và hỗ trợ nội suy theo frame trong video, khiến nó đặc biệt phù hợp cho các chiến dịch gán nhãn thị giác máy tính phức tạp, quy mô lớn, nhiều khung hình, đặc biệt khi cần kiểm soát, khả năng mở rộng và độ chính xác.
Gán nhãn ảnh cho Object Detection trong CVAT
Bước #1: Truy cập CVAT
Truy cập CVAT web app (ví dụ: cvat.ai) hoặc khởi chạy CVAT self-host qua Docker. Đăng nhập hoặc tạo tài khoản. Với triển khai local, chạy docker-compose up -d, sau đó truy cập http://localhost:8080/ và tạo superuser.
Bước #2: Tạo một Task mới
Vào tab “Tasks” và click “Create New Task.”
Đặt tên, định nghĩa các object classes (ví dụ: “car”, “person”), và upload ảnh (kéo-thả hoặc upload).
Bước #3: Định nghĩa nhãn và gửi
Đảm bảo bạn đã thêm đầy đủ labels cần thiết trước khi bắt đầu gán nhãn, vì cập nhật giữa chừng có thể gây nhầm lẫn. Click Submit và Open để tạo Task; task có thể sinh một hoặc nhiều Jobs nếu dataset lớn hoặc làm việc cộng tác.
Bước #4: Gán nhãn bằng Bounding Box
Mở Job để vào giao diện gán nhãn. Chọn công cụ Rectangle (bounding box) từ thanh công cụ bên trái. Chọn đúng label và nhấn “N” để bắt đầu vẽ. Bạn có thể gán nhãn bằng cách click hai góc hoặc kéo-thả để tạo hình chữ nhật. Điều hướng giữa các ảnh bằng phím mũi tên hoặc nút trên toolbar.
Bước #5: Sử dụng các hình dạng hoặc công cụ nâng cao (Tùy chọn)
Ngoài hình chữ nhật, CVAT hỗ trợ polygon, polyline, ellipse, cuboid và point cho gán nhãn phong phú hơn. Với gán nhãn bán tự động, dùng AI tools:
- Detectors (ví dụ: Mask R-CNN, Faster R-CNN, YOLO models)
- Interactors (ví dụ: DEXTR, HRNet, f-BRS)
Chọn model, ánh xạ labels của model với classes của bạn, và chạy auto-labeling để tăng tốc.
Bước #6: Lưu lại công việc
CVAT không auto-save, vì vậy hãy click “Save” thường xuyên trong quá trình gán nhãn từng ảnh hoặc theo batch.
Bước #7: Xuất các annotation
Sau khi hoàn tất, vào trang Task và click Menu -> Export task dataset. Chọn định dạng như COCO JSON, YOLO hoặc Pascal VOC XML tùy theo training pipeline của bạn.
4. LabelMe
LabelMe là một công cụ gán nhãn open-source do MIT’s Computer Science & Artificial Intelligence Lab (CSAIL) phát triển, được thiết kế để xây dựng bộ dữ liệu hình ảnh cho nghiên cứu thị giác máy tính. Nó chạy trong trình duyệt web (hoặc offline qua công cụ tải về), cho phép người dùng gán nhãn thủ công ảnh và video bằng workflow gán nhãn dựa trên polygon.
Key Features of LabelMe:
- Multiple Shape Types: Hỗ trợ sáu primitive gán nhãn—polygon, rectangle (bounding box), circle, line, point và line strip—cho gán nhãn linh hoạt và chính xác.
- Web-Based & Local Versions: Dùng công cụ nhẹ trên trình duyệt hoặc bản desktop cho Windows, macOS và Linux để triển khai linh hoạt.
- Batch Navigation: Mở một thư mục ảnh để gán nhãn tuần tự mượt mà, với tùy chọn tìm kiếm và chọn file ngẫu nhiên từ danh sách.
- Annotation Export Formats: Export dataset đã gán nhãn theo Pascal VOC XML hoặc COCO JSON, tương thích với workflow segmentation, detection và instance segmentation.
- Extensible & Open Source: Viết bằng Python với Qt; LabelMe open-source hoàn toàn và có thể chỉnh sửa; developer có thể tùy biến GUI, bật autosave, validation và classification flags.
LabelMe có điểm gì khác biệt?
Điểm nổi bật của LabelMe là thiết kế đơn giản, tập trung cho nhà nghiên cứu, ưu tiên gán nhãn nhẹ và đóng góp mở. Nó vận hành một dataset cộng đồng, nơi ảnh đã gán nhãn được chia sẻ công khai theo thời gian thực, giúp nhà nghiên cứu phát triển một kho lưu trữ liên tục cập nhật với nhiều lớp đối tượng và bối cảnh (scenes) đa dạng. Khác với nhiều công cụ cần hạ tầng nặng, giao diện LabelMe nhấn mạnh tính tối giản, chia sẻ tức thì và toàn quyền kiểm soát annotation.
LabelMe hỗ trợ data scientist và nhà nghiên cứu bằng một công cụ gán nhãn “no-frills”, lý tưởng cho gán nhãn thủ công dựa trên polygon và tạo dataset trong bối cảnh nghiên cứu/học thuật, đặc biệt khi quyền riêng tư, tính mở và chia sẻ dataset quan trọng.
Gán nhãn hình ảnh cho bài toán phát hiện đối tượng bằng LabelMe
Dưới đây là các bước chi tiết để gán nhãn hình ảnh phục vụ huấn luyện mô hình phát hiện đối tượng bằng công cụ LabelMe.
Bước #1: Cài đặt LabelMe
Cài đặt qua pip để đảm bảo tương thích đa nền tảng:
pip install labelme
Sau đó khởi chạy công cụ bằng lệnh:
Labelme
Bạn sẽ thấy một cửa sổ giao diện (GUI), trong đó các annotation được lưu dưới dạng file JSON nằm cùng thư mục với ảnh.
Bước #2: Mở thư mục ảnh
Trong giao diện LabelMe, nhấn “Open Dir” và chọn thư mục chứa toàn bộ ảnh. Danh sách file sẽ hiển thị để bạn dễ dàng điều hướng.
Bước #3: Chọn hình dạng annotation
Nhấn nút “Create Polygon”, sau đó chọn “Create Rectangle” trên thanh công cụ để bật chế độ bounding box.
Bước #4: Vẽ Bounding Box
Click để đặt một góc của bounding box và kéo đến góc đối diện. Sau khi vẽ xong, LabelMe sẽ yêu cầu bạn nhập tên class hoặc chọn từ danh sách có sẵn. Bạn có thể thêm label mới ngay trong quá trình gán nhãn.
Bước #5: Chuyển ảnh & gán nhãn tiếp
Di chuyển giữa các ảnh bằng panel danh sách file. Vẽ bounding box một cách nhất quán trên toàn bộ dataset.
Bước #6: Lưu file annotation
Nhấn Ctrl+S (Windows) hoặc Cmd+S (macOS) để lưu file JSON đã gán nhãn. LabelMe sẽ đặt tên file theo dạng <tên_ảnh>.json và lưu cùng thư mục với ảnh.
Bước #7: Chuyển đổi annotation (Tùy chọn)
Nếu bạn cần các định dạng như COCO hoặc Pascal VOC, hãy dùng Roboflow để chuyển đổi bằng cách upload các file JSON cùng với ảnh tương ứng, sau đó tạo một phiên bản dataset trong Roboflow và export sang định dạng mong muốn.
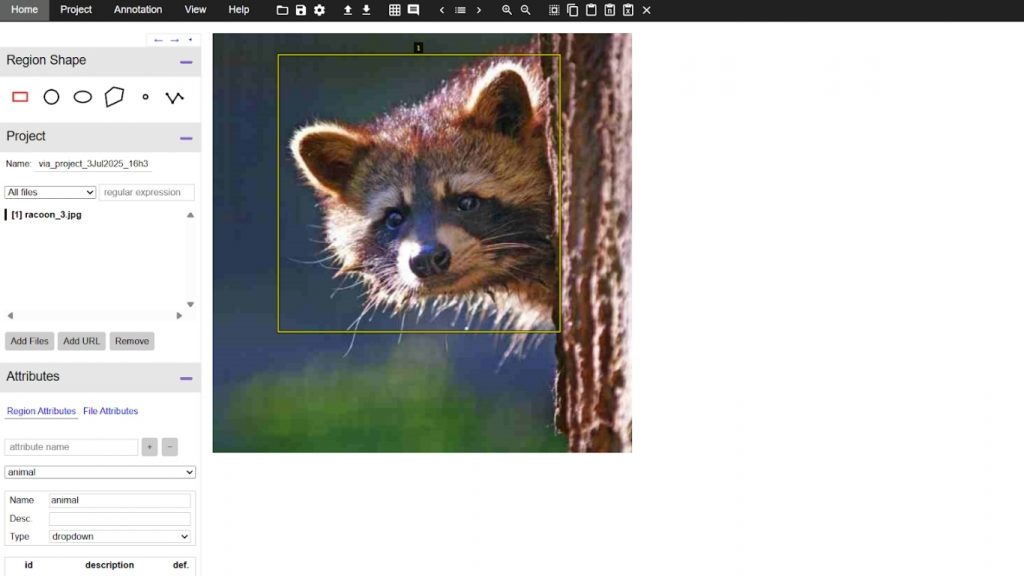
5. VGG Image Annotator (VIA)
VGG Image Annotator (VIA) là một công cụ gán nhãn open-source siêu nhẹ do Visual Geometry Group tại Đại học Oxford phát triển. Công cụ được cung cấp dưới dạng một file HTML duy nhất (~400 KB) chạy hoàn toàn trong trình duyệt: không cần cài đặt, không cần phụ thuộc (dependencies) hay thư viện ngoài. VIA hỗ trợ gán nhãn cho ảnh, video và audio, với các hình dạng như rectangle, polygon, circle, ellipse, point và polyline.
>>> Xem thêm:
- TOP 30 công cụ AI miễn phí, phổ biến, hỗ trợ học tập và làm việc hiệu quả
- TOP 20 công cụ Chat AI tiếng Việt miễn phí thông minh phổ biến
C
Các tính năng chính của VIA:
- Zero-install browser app: Chạy VIA bằng cách mở file HTML trong Chrome, Firefox hoặc Safari. Phù hợp cho thiết lập nhanh hoặc dùng offline.
- Multiple annotation primitives: Hỗ trợ sáu loại vùng (region types) gồm rectangle, polygon, circle, ellipse, point và polyline cho các tác vụ gán nhãn linh hoạt.
- Custom region attributes: Định nghĩa dropdown, radio button, hình ảnh hoặc text field cho thuộc tính (attributes) để đảm bảo tính nhất quán nhãn.
- Image Grid View: Cho phép review và lọc nhóm ảnh được gán nhãn tự động bởi các thuật toán CV (như YOLO, RF-DETR, v.v.), cho phép bulk updates hoặc cleanup, rất phù hợp cho workflow bán tự động.
- Audio & Video support: VIA cho phép gán nhãn các đoạn thời gian (temporal segments) trong video/audio cũng như các vùng không gian (spatial regions) trong frame, hữu ích cho dự án gán nhãn đa phương thức (multimodal).
- Export formats: Lưu annotation dưới dạng JSON hoặc CSV thuần, dễ tích hợp vào pipeline machine learning hoặc script chuyển đổi.
VIA có điểm gì khác biệt?
- Tính di động dạng một file: Khác với nhiều nền tảng gán nhãn AI yêu cầu cài đặt phần mềm hoặc thiết lập server, VIA hoạt động hoàn toàn offline chỉ với một file HTML tự chứa, có thể sử dụng ngay và chia sẻ dễ dàng qua email hoặc USB.
- Không phụ thuộc bên ngoài: Được xây dựng bằng HTML, JavaScript và CSS thuần, không dùng framework, không cần Node, Python hay Docker. Toàn bộ công cụ gán nhãn nằm gọn trong một file duy nhất, giúp triển khai nhanh và đơn giản.
- Thiết kế thân thiện cho làm việc nhóm: Tính năng Image Grid View hỗ trợ đội nhóm review và lọc các annotation được tạo tự động theo từng nhóm, giúp tăng tốc quy trình QA và làm sạch dataset quy mô lớn.
- Giao diện siêu nhẹ, dễ sử dụng: Giao diện tối giản theo phong cách grayscale, các thao tác điều khiển trực quan, phù hợp cả với annotator không chuyên, giảm thời gian đào tạo và nâng cao hiệu suất gán nhãn dữ liệu.
Tính độc đáo của VIA nằm ở thiết kế tối giản, không phụ thuộc, tính di động vượt trội và năng lực gán nhãn nhẹ nhưng linh hoạt, đặc biệt phù hợp cho workflow học thuật hoặc nhóm nhỏ, triển khai nhanh hoặc bối cảnh không thuận tiện cài đặt.
Gán nhãn ảnh cho Object Detection bằng VIA
Bước #1: Khởi chạy VIA
Mở file HTML của VIA trong trình duyệt (Chrome, Firefox, Safari), không cần cài đặt và chạy offline hoàn toàn. Bạn cũng có thể tải từ đây.
Bước #2: Load ảnh
Vào Project -> Add local files (hoặc Add files from URL) để tải ảnh lên. Ảnh sẽ xuất hiện ở sidebar trái.
Bước #3: Định nghĩa thuộc tính vùng cho class label
Click Attributes ở panel trái và tạo một region attribute mới (ví dụ: “class_label”). Thiết lập attribute này thành dropdown menu với tên object class (ví dụ: “cat”, “dog”, “raccoon”). Điều này giúp chọn class nhất quán.
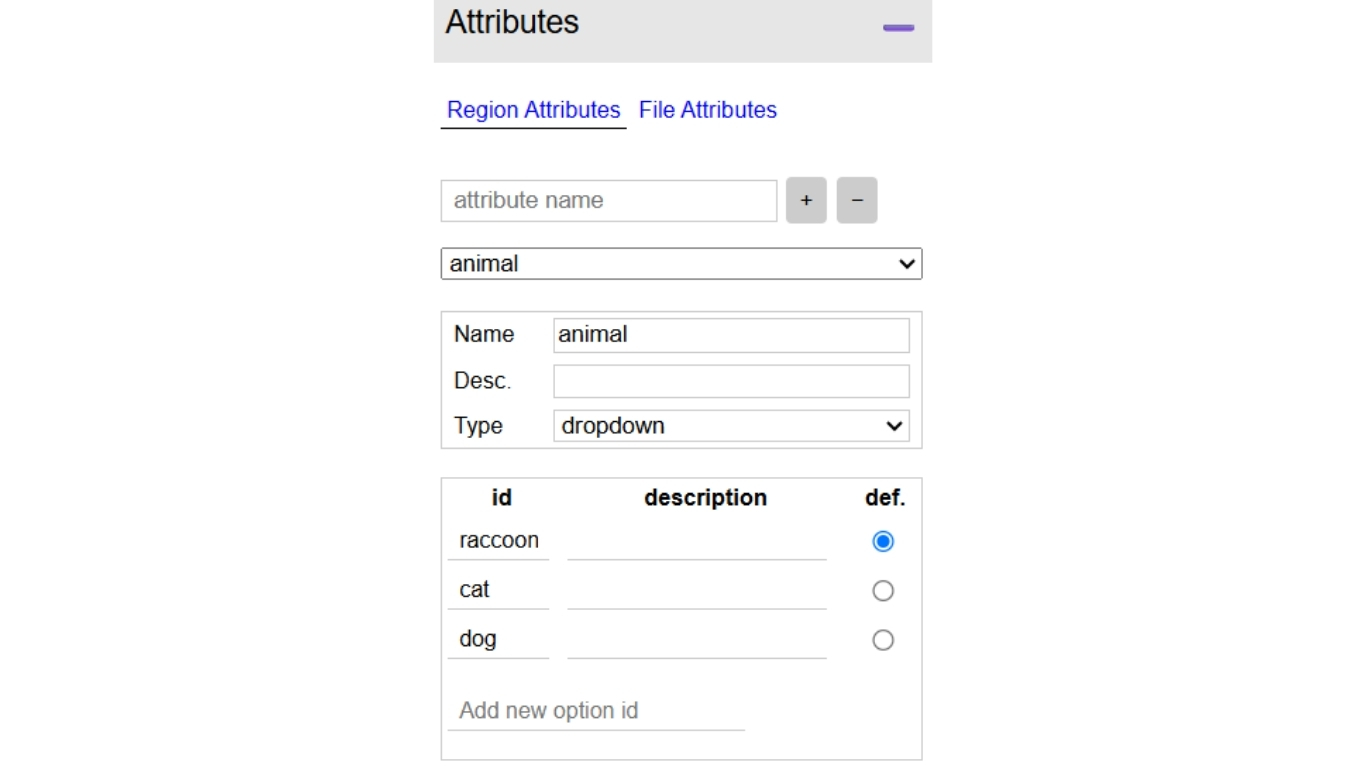
Bước #4: Gán nhãn Bounding Box
Chọn Rectangle shape tool từ sidebar trái. Click và kéo trên ảnh để vẽ hộp quanh mỗi đối tượng. Sau khi vẽ, nhấn Space bar để mở annotation pane, nơi bạn gán label bằng dropdown attribute.
>>> Xem thêm:
- Character AI là gì? Trò chuyện cùng nhân vật ảo trên mô hình mới
- 13 nền tảng chatbot mã nguồn mở tốt nhất
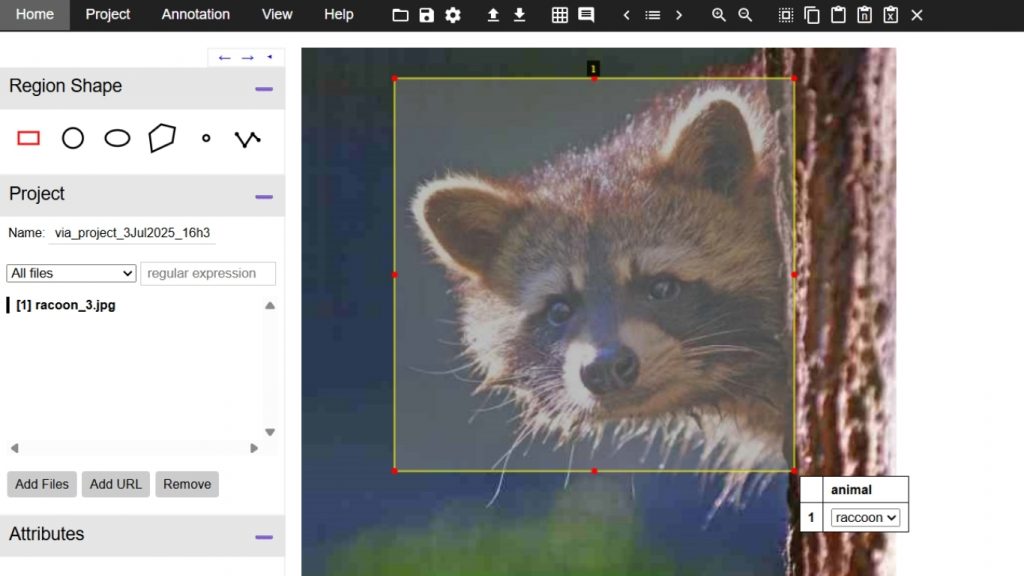
Bước #5: Di chuyển giữa các ảnh & tiếp tục gán nhãn
Dùng danh sách file ở panel trái để chuyển sang ảnh tiếp theo và tiếp tục gán nhãn đến khi tất cả ảnh được gán nhãn.
Bước #6: Lưu annotation
Vào Project -> Save project để lưu công việc trong phiên trình duyệt. Để export annotation cuối cùng, vào Annotations -> Export as CSV hoặc Annotations → Export as JSON. Các file này bao gồm tọa độ bounding box, filenames và class attributes.
Bước #7: Chuyển đổi output VIA cho huấn luyện mô hình (Tùy chọn)
Output từ VIA có thể chuyển sang COCO, Pascal VOC, YOLO, v.v. bằng Roboflow (kéo-thả images + VIA JSON). Tạo dataset version và export theo bất kỳ định dạng nào bạn cần.
6. RectLabel
RectLabel là một công cụ gán nhãn ảnh native cho macOS, chạy offline, được thiết kế cho các tác vụ object detection và segmentation. Nó hỗ trợ nhiều primitive gán nhãn như oriented bounding box (đặc biệt hữu ích cho ảnh hàng không/vệ tinh), polygon, đường cong cubic Bézier, keypoint, mặt nạ mức pixel bằng brush và superpixel, và thậm chí gán nhãn văn bản dựa trên OCR, khiến nó trở thành lựa chọn linh hoạt cho nhiều nhu cầu gán nhãn khác nhau
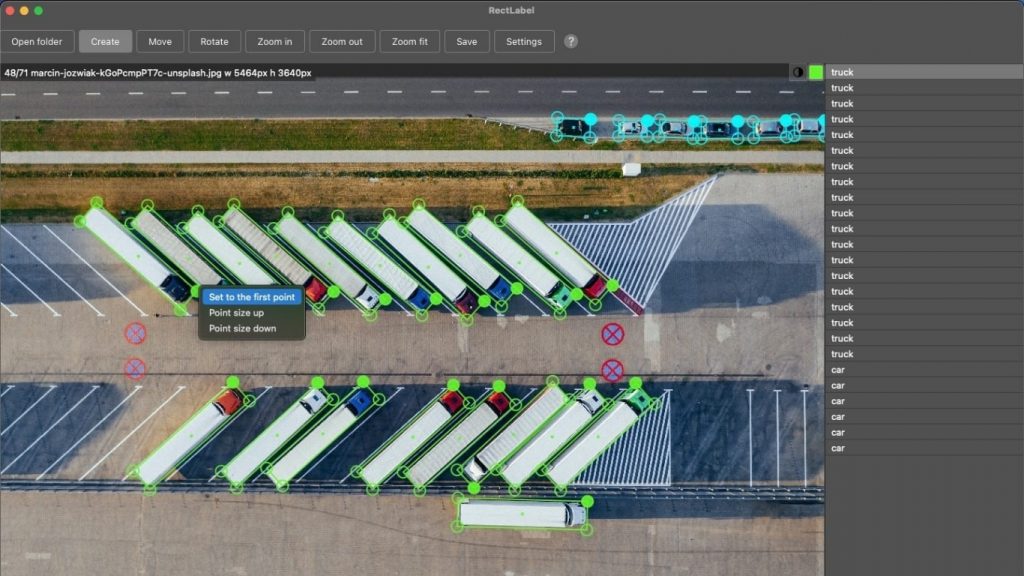
Các tính năng chính của RectLabel:
- Offline & macOS native: Chạy cục bộ không phụ thuộc server hay cloud, cho phản hồi cao và đảm bảo quyền riêng tư dữ liệu hoàn toàn.
- Segment Anything Model (SAM-2) integration: Tự động tạo polygon và pixel mask chính xác với tối thiểu thao tác thủ công.
- Core ML model support: Áp dụng mô hình pretrained cho auto-labeling, phù hợp gán nhãn nhanh hoặc khởi tạo dataset.
- Oriented bounding boxes và keypoints với skeletons: Đặc biệt quan trọng cho ảnh hàng không hoặc tác vụ ước lượng tư thế.
- Pixel-level label tools: Dùng brush hoặc superpixel cho workflow phân đoạn chi tiết.
- Advanced export formats: Export trực tiếp sang YOLO, COCO JSON, CreateML, Pascal VOC, DOTA, bao gồm hỗ trợ indexed hoặc grayscale masks.
- Customizable label dialog & hotkeys: Tăng tốc gán nhãn bằng chọn nhãn one-click và dialog theo thuộc tính có thể tùy biến; đồng thời hỗ trợ tìm kiếm theo object/attribute/image names.
- Video processing & image augmentation: Chuyển video thành frames và thực hiện augmentations ngay trong ứng dụng (crop/resize/rotate).
RectLabel có điểm gì khác biệt?
RectLabel nổi bật là một trong số ít ứng dụng gán nhãn offline đầy đủ tính năng được xây dựng riêng cho macOS, kết hợp auto-labeling polygon/mask bằng SAM-2, tích hợp Core ML và chỉnh sửa mức pixel, tất cả trong một ứng dụng GUI native không phụ thuộc Docker, server hay trình duyệt web. Hỗ trợ oriented bounding box, đường cong Bézier, keypoint theo skeleton và searchable galleries là các tính năng hiếm gặp ở nhiều công cụ gán nhãn.
Ngoài ra, công cụ còn hỗ trợ export nhanh sang nhiều định dạng machine learning và tìm kiếm gallery tương tác theo labels/attributes, khiến nó đặc biệt mạnh cho annotator chuyên nghiệp và nhà nghiên cứu làm việc trên môi trường Mac.
Gán nhãn ảnh cho Object Detection bằng RectLabel
Bước #1: Cài đặt RectLabel (ứng dụng macOS)
Tải và cài RectLabel (hoặc RectLabel Pro) từ Mac App Store. Mở ứng dụng; không cần Docker hay trình duyệt vì mọi thứ chạy native trên macOS.
Bước #2: Tạo hoặc import project
Mở RectLabel và bắt đầu một project gán nhãn mới hoặc load một image directory có sẵn.
Bước #3: Định nghĩa class & attributes
Dùng settings panel để tạo object categories, cấu hình attribute labels và tùy chỉnh hotkeys/label dialogs nhằm tăng tốc và đảm bảo nhất quán.
Bước #4: Vẽ Bounding Box
Chọn Rectangle tool và vẽ bounding box quanh từng đối tượng. Dùng smart guides để căn chỉnh và resize chính xác. Nhấn hotkey đã cấu hình hoặc chọn class từ dialog để gán nhãn ngay.
Bước #5: Dùng chỉnh sửa nâng cao & auto-labeling (Tùy chọn)
Zoom vào các box đã có hoặc dùng layers để quản lý annotation chồng lấn. Tích hợp Core ML models để auto-generate bounding box khi phù hợp.
Bước #6: Di chuyển & gán nhãn tuần tự
Di chuyển qua các ảnh trong dataset và áp dụng rectangle tool + class label cho từng ảnh cho đến khi hoàn tất.
Bước #7: Lưu & export annotation
Lưu project thường xuyên trong ứng dụng. Export annotation bounding box theo các định dạng như PASCAL VOC XML, COCO JSON, YOLO TXT hoặc DOTA mà RectLabel hỗ trợ trực tiếp.
7. HumanSignal Label Studio
HumanSignal là công ty đứng sau Label Studio, một nền tảng gán nhãn đa phương thức open-source được thiết kế cho ảnh, video, văn bản, audio và time-series. Community Edition miễn phí hoàn toàn và có thể mở rộng; Enterprise Edition bổ sung các tính năng như QA workflows, SSO, role-based access, audit logs, và tự động hóa dựa trên LLM, bao gồm auto-labeling theo prompt và công cụ so sánh mô hình cho người dùng doanh nghiệp.
Các tính năng chính của Label Studio:
- Hỗ trợ gán nhãn đa phương thức: Label Studio là nền tảng gán nhãn AI hỗ trợ nhiều loại dữ liệu trên cùng một hệ thống, bao gồm hình ảnh, video, văn bản, âm thanh và chuỗi thời gian.
- Giao diện tùy biến hoàn toàn: Cho phép định nghĩa giao diện gán nhãn theo nhu cầu bằng cấu hình dạng XML-like, dễ dàng thêm template, nhãn quan hệ, thiết lập bố cục và các UI widgets cho từng tác vụ cụ thể.
- Tích hợp ML Backend & Active Learning: Kết nối mô hình machine learning tùy chỉnh thông qua ML Backend SDK để tự động gán nhãn trước, kích hoạt vòng lặp active learning và liên tục cải thiện độ chính xác dự đoán trong quá trình gán nhãn dữ liệu.
- Tự động hóa & đánh giá prompt LLM: Sử dụng hệ thống “Prompts” dựa trên LLM của HumanSignal (ví dụ GPT-4) để tự động sinh nhãn, so sánh đầu ra giữa các mô hình LLM, bootstrap dataset và tinh chỉnh prompt thông qua công cụ đánh giá chuyên sâu
- Quy trình kiểm duyệt & QA mạnh mẽ: Phiên bản Enterprise hỗ trợ phân quyền rõ ràng (Annotator, Reviewer), phân công tác vụ tự động, đo lường mức độ đồng thuận giữa các annotator (ví dụ: Krippendorff’s alpha), dashboard theo dõi chất lượng & độ phủ dữ liệu, cùng hệ thống bình luận và xử lý xung đột khi gán nhãn.
- Hệ sinh thái plugin & framework: Dễ dàng mở rộng nền tảng gán nhãn AI bằng JavaScript plugin tùy chỉnh, cấu hình mã nguồn mở và sử dụng các template/UI layout phổ biến từ cộng đồng.
- Plugin gán nhãn video đa khung hình: Plugin chuyên biệt của HumanSignal cho phép annotator xem đồng thời nhiều frame (trước – trong – sau), giúp tăng độ chính xác khi gán nhãn video có chuyển động phức tạp.
HumanSignal có điểm gì khác biệt?
HumanSignal (Label Studio Enterprise) cung cấp những năng lực hiếm khi được kết hợp trong một nền tảng:
- Tự động hóa gán nhãn theo prompt bằng LLM, đồng thời có công cụ đánh giá LLM tích hợp để fine-tune prompt và so sánh mô hình theo chi phí và độ chính xác.
- Workflow human+AI end-to-end, nơi dự đoán tự động được review có hệ thống, chấm điểm và tinh chỉnh thông qua agreement analytics và review assignment pipelines.
- Lõi open-source kết hợp tính năng enterprise-grade giúp mở rộng từ prototyping học thuật đến production an toàn trong doanh nghiệp mà không phải đổi công cụ.
- Khả năng mở rộng qua plugins và shared config libraries, cho phép lắp ghép các tác vụ nâng cao (relations, time series, multimodal data) từ community templates.
- Trải nghiệm video annotation nâng cao (multi-view sync) và hỗ trợ quan hệ giữa annotations, vốn đặc biệt ít gặp ở open-source tools.
HumanSignal (Label Studio) đặc biệt giá trị cho các đội nhóm cần workflow vận hành dữ liệu quy mô lớn, an toàn và có AI hỗ trợ, kết nối gán nhãn của con người với tự động hóa mô hình trong cùng một nền tảng.
Gán nhãn ảnh cho Object Detection bằng Label Studio
Bước #1: Cài đặt & chạy Label Studio
Cài bằng pip:
pip install -U label-studio
Chạy:
label-studio
Mở http://localhost:8080/ trên trình duyệt để đăng ký và sử dụng.
Bước #2: Tạo project mới
Từ dashboard, click Create project, đặt tên và mô tả. Upload ảnh trong Data Import (tối đa 100 ảnh qua UI hoặc dùng API cho dataset lớn).
Bước #3: Cấu hình giao diện gán nhãn
Vào Labeling Setup, chọn template “Object Detection with Bounding Boxes”, xóa label mặc định và thêm class của bạn (ví dụ: “cat”, “dog”).
Bước #4: Bắt đầu gán nhãn
Click Label All Tasks. Chọn label (click hoặc phím số), sau đó click-kéo để vẽ box. Có thể zoom (Ctrl + / Ctrl -) để chính xác hơn.
Bước #5: Submit & điều hướng
Sau mỗi ảnh, click Submit để lưu và chuyển ảnh tiếp theo. Dùng data manager để lọc, sort hoặc gán nhãn subset cụ thể.
Bước #6: Export annotation
Tại project home, click Export và chọn định dạng mong muốn: COCO JSON, Pascal VOC XML, YOLO TXT…
0:00
/1:01
1×
Bắt đầu với các công ty gán nhãn dữ liệu tốt nhất
Việc chọn đúng nền tảng gán nhãn dữ liệu là bước then chốt trong mọi pipeline computer vision – nó có thể quyết định một mô hình hoạt động ổn định hay thất bại trong điều kiện thực tế. Dù bạn đang xây dựng prototype nhanh hay mở rộng hệ thống AI ở quy mô production, công cụ gán nhãn cần phù hợp với độ phức tạp dự án, loại dữ liệu, mức độ tự động hóa và workflow của team.
Từ hệ sinh thái tự động hóa end-to-end của Roboflow, công cụ chính xác tự host như CVAT, các giải pháp open-source nhẹ như LabelMe và VIA, cho tới nền tảng enterprise như Label Studio – luôn có một công cụ phù hợp cho từng use case. Điều quan trọng là match đúng công cụ với nhu cầu, cân bằng giữa tính dễ dùng, khả năng mở rộng và độ chính xác, để tạo ra dataset chất lượng cao – nền tảng cho huấn luyện và triển khai mô hình thành công.
Nguồn tham khảo: Best Data Annotation Platforms
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Hoàng Diệu, Phường 12, Quận 4, Thành phố Hồ Chí Minh, Việt Nam