
Trong bối cảnh dữ liệu ngày càng phức tạp và đa chiều, giảm chiều dữ liệu trở thành kỹ thuật không thể thiếu trong học máy và phân tích dữ liệu hiện đại. Phương pháp này giúp đơn giản hóa tập dữ liệu, giảm chi phí tính toán nhưng vẫn giữ lại các thông tin quan trọng cốt lõi. Nhờ đó, mô hình hoạt động hiệu quả hơn, dễ trực quan hóa và hạn chế rủi ro quá khớp. Bài viết sau từ TOT sẽ giúp bạn hiểu rõ bản chất, vai trò và các kỹ thuật giảm chiều dữ liệu phổ biến hiện nay.
>>> Tìm hiểu thêm:
- So sánh giữa mô hình ngôn ngữ thị giác và phát hiện đối tượng
- Neural Network là gì? Tổng quan về mạng nơ-ron nhân tạo
- Object Detection là gì? Cách hoạt động & Ứng dụng trong thực tế
Giới thiệu về giảm chiều dữ liệu
Trong những năm gần đây, giảm chiều dữ liệu đã có nhiều bước tiến đáng kể, nhằm giải quyết các thách thức do dữ liệu đa chiều gây ra trong nhiều lĩnh vực khác nhau. Giảm chiều dữ liệu bao gồm việc giảm số lượng biến đầu vào hoặc đặc trưng, kỹ thuật này đóng vai trò then chốt trong việc đơn giản hóa mô hình, cải thiện hiệu năng và giảm chi phí tính toán, đồng thời vẫn giữ lại các thông tin cốt lõi.
Các kỹ thuật giảm chiều dữ liệu có thể biến đổi những tập dữ liệu phức tạp bằng cách ánh xạ chúng sang không gian có số chiều thấp hơn, trong khi vẫn bảo toàn các mối quan hệ trong dữ liệu, chẳng hạn như các mẫu (patterns) hoặc cụm (clusters) vốn thường bị che khuất trong môi trường nhiều chiều.
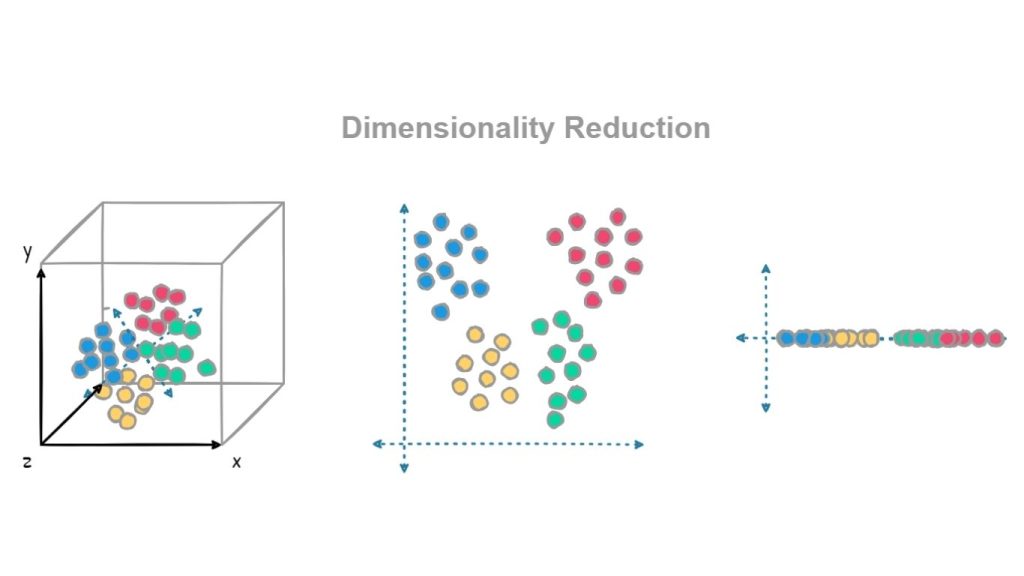
Cách tiếp cận đơn giản hóa cấu trúc dữ liệu này giúp các thuật toán hoạt động hiệu quả hơn, cho phép trực quan hóa tốt hơn và giảm nguy cơ quá khớp trong các mô hình học máy. Giảm chiều dữ liệu đặc biệt hiệu quả trong các lĩnh vực như xử lý ảnh (image processing), xử lý ngôn ngữ tự nhiên (natural language processing) và hệ gen học (genomics), nơi số lượng đặc trưng có thể rất lớn và khó kiểm soát.
Trong bài viết này, chúng ta sẽ khám phá các kỹ thuật cốt lõi của giảm chiều dữ liệu, xem xét các ứng dụng của chúng và thảo luận về tác động của chúng đối với các quy trình khoa học dữ liệu và học máy hiện đại.
>> Tham khảo thêm:
- Phân tích hình ảnh bằng AI là gì? Cách AI hiểu và diễn giải hình ảnh
- LLM là gì? Mô hình ngôn ngữ lớn và cách chúng hoạt động
Giảm chiều dữ liệu là gì?
Giảm chiều dữ liệu là một kỹ thuật quan trọng trong phân tích dữ liệu và học máy, được thiết kế nhằm để giảm số lượng biến đầu vào hoặc đặc trưng trong một tập dữ liệu, đồng thời vẫn bảo toàn những thông tin quan trọng nhất. Trong các tập dữ liệu thực tế, sự tồn tại của quá nhiều biến có thể làm tăng độ phức tạp, khiến mô hình dễ bị quá khớp và làm giảm khả năng diễn giải.
Các kỹ thuật giảm chiều dữ liệu giải quyết những thách thức này bằng cách tạo ra các biến mới hoặc các phép chiếu nhằm nắm bắt những đặc điểm cốt lõi của dữ liệu. Mục tiêu là giữ lại cấu trúc nền tảng, các mẫu và mối quan hệ trong dữ liệu, trong khi làm việc với số chiều ít hơn.
Bằng cách giảm số chiều, dữ liệu trở nên dễ trực quan hóa, dễ khám phá và dễ phân tích hơn, từ đó giúp tăng tốc độ tính toán, cải thiện hiệu suất mô hình và mang lại những hiểu biết rõ ràng hơn về các yếu tố nền tảng chi phối dữ liệu.
Vì sao cần giảm chiều dữ liệu?
Giảm chiều dữ liệu là cần thiết vì nhiều lý do, đặc biệt là:
- Lời nguyền chiều dữ liệu: Dữ liệu có số chiều cao thường gặp vấn đề về tính thưa, khiến việc khai thác thông tin hữu ích hoặc xây dựng mô hình chính xác trở nên khó khăn. Khi số lượng đặc trưng tăng lên, các điểm dữ liệu bị phân tán, làm giảm mật độ dữ liệu của chúng. Giảm chiều dữ liệu giúp thu hẹp không gian đặc trưng, cải thiện mật độ và khả năng diễn giải của dữ liệu.
- Hiệu quả tính toán: Càng nhiều đặc trưng trong tập dữ liệu thì chi phí tính toán khi chạy các thuật toán học máy càng cao. Giảm chiều dữ liệu giúp giảm số lượng đặc trưng, từ đó giảm gánh nặng tính toán và cho phép xử lý dữ liệu cũng như huấn luyện mô hình nhanh hơn.
- Ngăn ngừa quá khớp: Các tập dữ liệu có quá nhiều đặc trưng dễ dẫn đến hiện tượng quá khớp, khi mô hình học cả nhiễu hoặc các biến động ngẫu nhiên thay vì các mẫu thực sự. Bằng cách giảm số chiều, nguy cơ quá khớp được giảm thiểu, giúp mô hình trở nên ổn định và có khả năng khái quát tốt hơn.
- Trực quan hóa và diễn giải: Việc trực quan hóa dữ liệu ở không gian nhiều chiều (trên ba chiều) vốn dĩ rất khó. Các kỹ thuật giảm chiều dữ liệu chiếu dữ liệu xuống không gian có số chiều thấp hơn, giúp việc trực quan hóa, diễn giải và nhận diện các mẫu hoặc mối quan hệ giữa các biến trở nên dễ dàng hơn, từ đó hỗ trợ tốt hơn cho việc ra quyết định.
>> Xem thêm: Mẹo tạo prompt cho LLM trong thị giác máy tính để tăng độ chính xác
Các đặc điểm chính của giảm chiều dữ liệu
Các kỹ thuật giảm chiều dữ liệu mang lại nhiều lợi ích quan trọng trong phân tích dữ liệu và học máy, bao gồm:
- Lựa chọn đặc trưng: Những phương pháp này giúp xác định và giữ lại các đặc trưng mang nhiều thông tin và có mức độ liên quan cao nhất từ tập dữ liệu ban đầu. Bằng cách loại bỏ các biến dư thừa hoặc không liên quan, giảm chiều dữ liệu làm nổi bật tập con các đặc trưng đại diện tốt nhất cho các mẫu và mối quan hệ nền tảng trong dữ liệu.
- Nén dữ liệu: Giảm chiều dữ liệu nén dữ liệu bằng cách chuyển đổi nó sang dạng có số chiều thấp hơn. Biểu diễn rút gọn này vẫn giữ lại tối đa các thông tin quan trọng, đồng thời giảm kích thước tổng thể của tập dữ liệu. Điều này giúp giảm nhu cầu lưu trữ và độ phức tạp tính toán.
- Giảm nhiễu: Các tập dữ liệu đa chiều thường chứa các đặc trưng nhiễu hoặc không liên quan, có thể làm sai lệch quá trình phân tích và hiệu năng mô hình. Giảm chiều dữ liệu làm giảm tác động của nhiễu bằng cách loại bỏ các biến kém quan trọng, từ đó cải thiện tỷ lệ tín hiệu trên nhiễu và nâng cao chất lượng phân tích.
- Cải thiện khả năng trực quan hóa: Do con người chỉ có thể trực quan hóa dữ liệu tối đa trong ba chiều, các tập dữ liệu nhiều chiều thường khó diễn giải. Trong khi đó, giảm chiều dữ liệu chuyển đổi dữ liệu sang các chiều thấp hơn, thường là hai hoặc ba chiều, giúp việc trực quan hóa và hiểu các mẫu, cụm và mối quan hệ trong dữ liệu trở nên dễ dàng hơn.
>> Xem thêm:
- AI nhận diện ảnh là gì? Thuật toán và ứng dụng phổ biến
- Top 5 thư viện Python cho thị giác máy tính – So sánh sự khác nhau
- Vision Inspection Systems: Hệ thống kiểm tra thị giác là gì?
Các kỹ thuật giảm chiều dữ liệu phổ biến
Trong phần này, chúng ta sẽ khám phá một số kỹ thuật giảm chiều dữ liệu được sử dụng phổ biến nhất. Mỗi phương pháp mang đến những cách tiếp cận khác nhau để đơn giản hóa dữ liệu có số chiều cao, đồng thời vẫn giữ lại các đặc trưng cốt lõi, khiến chúng trở thành những công cụ giá trị trong nhiều bài toán học máy và phân tích dữ liệu.
Phân tích thành phần chính (PCA)
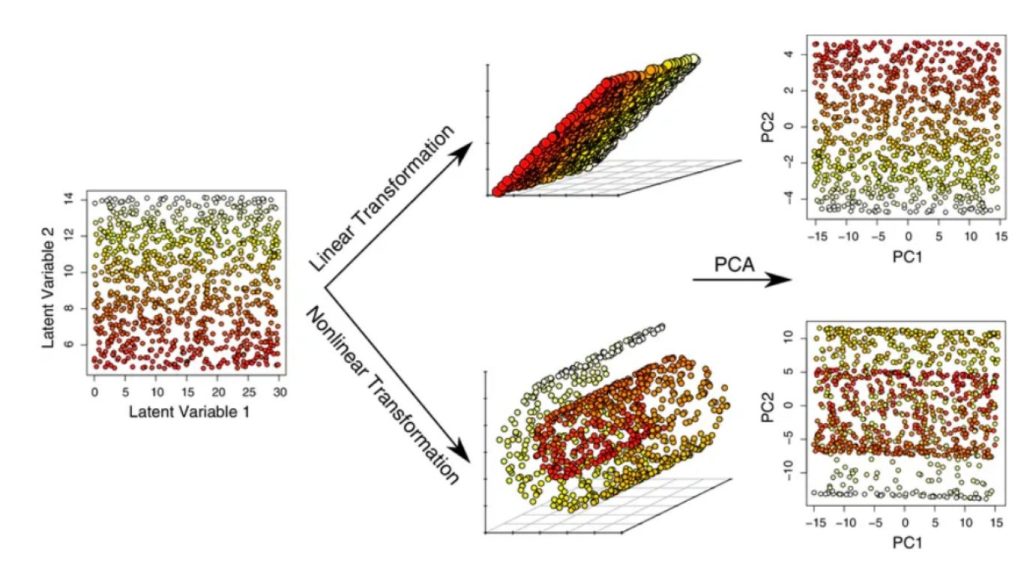
Phân tích thành phần chính (Principal Component Analysis – PCA) là một kỹ thuật giảm chiều tuyến tính được thiết kế nhằm trích xuất một tập hợp biến mới từ một tập dữ liệu ban đầu có số chiều cao. Mục tiêu chính của PCA là giảm số chiều của dữ liệu trong khi vẫn bảo toàn được nhiều phương sai nhất có thể.
PCA là một thuật toán không giám sát, tạo ra các tổ hợp tuyến tính của các đặc trưng gốc, được gọi là các thành phần chính. Các thành phần này được tính toán sao cho thành phần đầu tiên nắm bắt độ biến thiên lớn nhất trong tập dữ liệu, còn mỗi thành phần tiếp theo sẽ giải thích phần biến thiên còn lại mà không tương quan với các thành phần trước đó.
Thay vì lựa chọn một tập con các đặc trưng ban đầu và loại bỏ phần còn lại, PCA tạo ra các đặc trưng mới thông qua các tổ hợp tuyến tính của các đặc trưng hiện có, từ đó cung cấp một cách biểu diễn dữ liệu thay thế. Thông thường, chỉ một vài thành phần chính được giữ lại – những thành phần đủ để nắm bắt khoảng 90% tổng biến động. Điều này là do mỗi thành phần bổ sung sẽ giải thích ngày càng ít phương sai hơn và đồng thời đưa thêm nhiều nhiễu hơn. Bằng cách giữ lại ít thành phần hơn, PCA giúp bảo toàn tín hiệu quan trọng và lọc bỏ nhiễu hiệu quả.
PCA cải thiện khả năng diễn giải dữ liệu trong khi giảm thiểu mất mát thông tin, khiến nó trở nên hữu ích trong việc xác định các đặc trưng quan trọng nhất cũng như trực quan hóa dữ liệu trong không gian 2D hoặc 3D. Tuy nhiên, PCA phù hợp nhất với dữ liệu có mối quan hệ tuyến tính và có thể gặp khó khăn trong việc nắm bắt các mẫu phức tạp. Ngoài ra, PCA khá nhạy cảm với các ngoại lệ lớn, thậm chí có thể làm sai lệch kết quả.
>> Xem thêm:
- Các mô hình ngôn ngữ thị giác chạy cục bộ tốt nhất
- Mã nguồn mở là gì? TOP 15 nền tảng mã nguồn mở thiết kế web phổ biến nhất hiện nay
Nhúng lân cận ngẫu nhiên phân phối t (t-SNE)
t-SNE (t-Distributed Stochastic Neighbor Embedding) là một thuật toán giảm chiều phi tuyến tính, được thiết kế chủ yếu cho mục đích trực quan hóa dữ liệu đa chiều. Mục tiêu chính của t-SNE là tối đa hóa xác suất đặt các điểm dữ liệu tương tự gần nhau trong không gian có số chiều thấp, trong khi việc bảo toàn mối quan hệ giữa các điểm ở xa được xem là ưu tiên thứ cấp. Thuật toán này hoạt động hiệu quả trong việc gom cụm các điểm lân cận và đẩy các điểm còn lại ra xa nhau.
Không giống PCA, t-SNE là một kỹ thuật xác suất. Nó tối thiểu hóa sự khác biệt giữa hai phân phối: một phân phối đo lường mức độ tương đồng theo cặp trong dữ liệu gốc và một phân phối đo lường mức độ tương đồng giữa các điểm tương ứng trong không gian có số chiều thấp.
Bằng cách căn chỉnh hai phân phối này, t-SNE có thể biểu diễn hiệu quả tập dữ liệu ban đầu trong ít chiều hơn. Cụ thể, t-SNE sử dụng phân phối chuẩn (normal distribution) cho không gian nhiều chiều và phân phối t (t-distribution) cho không gian ít chiều. Phân phối t tương tự phân phối chuẩn nhưng có phần đuôi dày hơn, cho phép các điểm được phân tách thưa hơn, từ đó cải thiện khả năng trực quan hóa.
t-SNE có một số siêu tham số có thể điều chỉnh, bao gồm:
- Perplexity: Điều khiển kích thước vùng lân cận để thu hút các điểm dữ liệu.
- Exaggeration: Điều chỉnh mức độ lực hút giữa các điểm.
- Learning Rate: Xác định bước nhảy trong quá trình hạ gradient nhằm tối thiểu hóa sai số.
Việc tinh chỉnh các siêu tham số này có thể ảnh hưởng đáng kể đến chất lượng và độ chính xác của kết quả t-SNE. Mặc dù t-SNE rất mạnh trong việc khám phá các cấu trúc mà những phương pháp khác có thể bỏ sót, nó lại khá khó diễn giải, do các đặc trưng ban đầu trở nên không thể nhận diện sau khi xử lý.
Ngoài ra, vì là một thuật toán ngẫu nhiên, các lần chạy khác nhau với khởi tạo khác nhau có thể cho ra kết quả khác nhau. Độ phức tạp về tính toán và bộ nhớ của t-SNE là O(n²), do đó có thể đòi hỏi tài nguyên hệ thống đáng kể.

>> Xem thêm:
- Xây dựng ứng dụng phát hiện đối tượng bằng Python chỉ trong vài phút với Roboflow
- Phát hiện chuyển động bằng thị giác máy tính – Cách hoạt động và logic phát hiện
Phương pháp xấp xỉ và chiếu đa tạp đồng nhất (UMAP)
UMAP (Uniform Manifold Approximation and Projection) là một thuật toán giảm chiều phi tuyến được phát triển nhằm khắc phục một số hạn chế của t-SNE. Tương tự t-SNE, UMAP hướng tới việc tạo ra một biểu diễn có số chiều thấp, bảo toàn các mối quan hệ giữa các điểm lân cận trong không gian nhiều chiều, nhưng thực hiện điều này với tốc độ nhanh hơn và khả năng giữ lại cấu trúc toàn cục của dữ liệu tốt hơn.
UMAP hoạt động như một thuật toán phi tham số với hai bước chính: (1) tính toán một biểu diễn topologik mờ của tập dữ liệu, và (2) tối ưu hóa biểu diễn có số chiều thấp sao cho khớp chặt chẽ với biểu diễn topologik mờ này, sử dụng entropy chéo làm thước đo.
Có hai siêu tham số quan trọng trong UMAP quyết định sự cân bằng giữa cấu trúc cục bộ và toàn cục trong kết quả cuối cùng:
- Số lượng hàng xóm gần nhất: Tham số này xác định mức độ cân bằng giữa cấu trúc cục bộ và toàn cục. Giá trị thấp tập trung vào chi tiết cục bộ bằng cách giới hạn số điểm lân cận được xét, trong khi giá trị cao nhấn mạnh cấu trúc tổng thể nhưng có thể làm mất các chi tiết nhỏ.
- Khoảng cách tối thiểu: Tham số này quyết định mức độ gần nhau của các điểm dữ liệu trong không gian ít chiều. Giá trị nhỏ tạo ra các embedding chặt chẽ hơn, còn giá trị lớn dẫn đến sự phân bố lỏng hơn, ưu tiên bảo toàn các đặc trưng topologik rộng hơn.
Việc tinh chỉnh các siêu tham số này có thể khá phức tạp, nhưng tốc độ xử lý nhanh của UMAP cho phép chạy nhiều lần với các thiết lập khác nhau, từ đó giúp hiểu rõ hơn sự thay đổi của các phép chiếu.
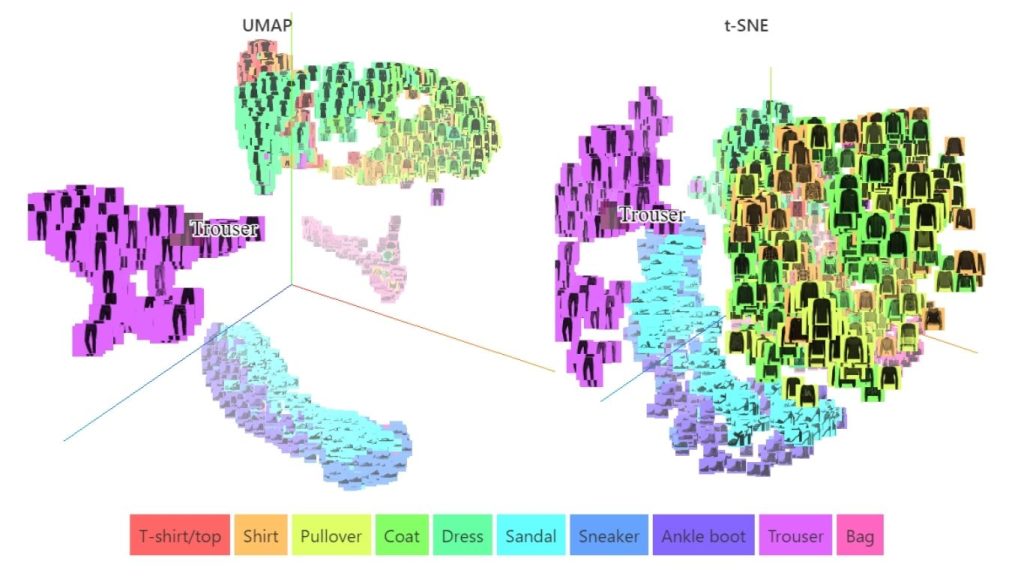
Khi so sánh UMAP với t-SNE, UMAP cho thấy nhiều ưu điểm đáng chú ý. Trước hết, UMAP mang lại hiệu quả trực quan hóa tương đương, cho phép biểu diễn dữ liệu đa chiều một cách hiệu quả. Bên cạnh đó, UMAP vượt trội trong việc bảo toàn cấu trúc toàn cục của dữ liệu, đảm bảo rằng khoảng cách giữa các cụm mang ý nghĩa thực tế, từ đó nâng cao khả năng diễn giải và phân tích mối quan hệ trong dữ liệu.
Ngoài ra, UMAP có tốc độ và hiệu quả cao hơn, phù hợp để xử lý các tập dữ liệu lớn mà không tạo ra gánh nặng tính toán đáng kể. Cuối cùng, không giống t-SNE vốn chủ yếu được thiết kế cho mục đích trực quan hóa, UMAP là một công cụ giảm chiều linh hoạt, có thể áp dụng trong nhiều bối cảnh và ứng dụng khác nhau.
>>> Tìm hiểu thêm:
- Visual Question Answering là gì? Mô hình và Phương pháp hoạt động
- Deep Learning là gì? Tổng quan về cách hoạt động và ứng dụng thực tế
- Vision AI Agents là gì? Cách xây dựng Vision AI Agents với Roboflow
- Vertex AI là gì? Nền tảng học máy của Google Cloud
Kết luận
Tóm lại, các kỹ thuật giảm chiều dữ liệu như PCA, t-SNE và UMAP đóng vai trò then chốt trong phân tích dữ liệu và học máy, bằng cách đơn giản hóa các tập dữ liệu phức tạp có số chiều cao. Những phương pháp này không chỉ giúp giảm chi phí tính toán và hạn chế các vấn đề như quá khớp, mà còn cải thiện khả năng trực quan hóa và diễn giải dữ liệu.
PCA hiệu quả với dữ liệu tuyến tính, cung cấp một cách tiếp cận rõ ràng để xác định các đặc trưng quan trọng nhất trong khi vẫn bảo toàn phương sai. Ngược lại, t-SNE nổi bật trong việc khám phá các cấu trúc cục bộ trong dữ liệu nhiều chiều, dù nó có thể gặp hạn chế với cấu trúc toàn cục và đòi hỏi tinh chỉnh tham số cẩn thận. UMAP khắc phục một số hạn chế này, mang lại hiệu năng nhanh hơn và khả năng bảo toàn cấu trúc toàn cục tốt hơn, khiến nó phù hợp với phạm vi ứng dụng rộng hơn.
Cuối cùng, việc lựa chọn kỹ thuật giảm chiều dữ liệu phụ thuộc vào nhu cầu cụ thể của phân tích của bạn, bao gồm bản chất dữ liệu, mục tiêu mong muốn và tài nguyên tính toán sẵn có. Bằng cách hiểu rõ điểm mạnh và hạn chế của từng phương pháp, bạn có thể khai thác hiệu quả các công cụ này để thu được những hiểu biết sâu hơn và đưa ra các quyết định dựa trên dữ liệu một cách chính xác hơn trong các dự án của mình.
>>> Nguồn tham khảo: What is Dimensionality Reduction? A Guide
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com🏢 Địa chỉ:31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam







