Bạn đã bao giờ tự hỏi liệu máy tính có thể không chỉ nhìn thấy mà còn hiểu nội dung trong một bức ảnh và trả lời các câu hỏi liên quan đến nó hay chưa? Đó chính xác là nội dung mà lĩnh vực nghiên cứu học thuật Visual Question Answering (VQA) hướng tới. VQA liên quan đến việc huấn luyện máy tính kết nối mối quan hệ giữa hình ảnh và ngôn ngữ.
Trong bài viết dưới đây sẽ cung cấp khái niệm Visual Question Answering là gì, tổng quan về cách thức VQA hoạt động và khám phá các phương pháp khác nhau để áp dụng VQA trong thực tế.
>> Tìm hiểu thêm:
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- Xây dựng ứng dụng phát hiện đối tượng bằng Python chỉ trong vài phút với Roboflow
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
- Hướng dẫn triển khai AI trong ứng dụng di động đơn giản
Visual Question Answering là gì?
Hãy hình dung tình huống sau: Bạn đưa cho máy tính một bức ảnh chụp công viên và đặt câu hỏi: “Có bao nhiêu cái cây trong ảnh?”. Lúc này, máy tính không chỉ đơn thuần dừng lại ở việc đếm số cây trong hình, mà còn cần hiểu được ý nghĩa đằng sau câu hỏi “có bao nhiêu”.
Nhiệm vụ này thuộc lĩnh vực Visual Question Answering (trả lời câu hỏi trực quan), trong đó máy tính phải xử lý đồng thời hai miền quan trọng. Trước hết là quá trình máy tính phân tích hình ảnh, nhận diện và đếm số cây – còn được gọi là Computer Vision (thị giác máy tính). Tiếp theo là khả năng máy tính hiểu câu hỏi và phản hồi theo cách giống con người, được gọi là Natural Language Processing (NLP – xử lý ngôn ngữ tự nhiên).
Vậy Visual Question Answering là gì? Có thể hiểu VQA giống như việc huấn luyện máy tính không chỉ “nhìn thấy” các yếu tố thị giác, mà còn “hiểu” và “diễn đạt” về chúng khi được đặt câu hỏi.
Ví dụ, bạn có thể đặt các câu hỏi như:
- Có bao nhiêu xe nâng trong hình?
- Có xe nâng nào ở gần pallet gỗ không?
- Có công nhân nào không đội mũ bảo hộ không?
- Hộp trong hình có nhãn không?
- Đọc nội dung văn bản trên nhãn trong hình.
Các nhà nghiên cứu hướng tới việc xây dựng các mô hình VQA có khả năng trả lời những câu hỏi như trên, cũng như nhiều câu hỏi khác. Nếu bạn có một câu hỏi liên quan đến hình ảnh, một mô hình VQA lý tưởng sẽ có thể hiểu và xử lý được câu hỏi đó.
>> Xem thêm:
- Phân tích hình ảnh bằng AI là gì? Cách AI hiểu và diễn giải hình ảnh
- AI nhận diện ảnh là gì? Thuật toán và ứng dụng phổ biến
Các phương pháp tiếp cận Visual Question Answering
Trong phần này, chúng ta sẽ đi sâu vào các khía cạnh chi tiết của Visual Question Answering. Trước tiên, bài viết sẽ trình bày một cách tiếp cận tổng quát đối với VQA, sau đó phân tích kỹ hơn ba phương pháp tiêu biểu: phương pháp Bayesian, cơ chế Attention-based (dựa trên chú ý) và mô hình CLIP.
VQA hoạt động như thế nào?
Nhìn chung, các phương pháp trong VQA có thể được mô tả như sau:
- Trích xuất đặc trưng từ câu hỏi
- Trích xuất đặc trưng từ hình ảnh
- Kết hợp các đặc trưng để tạo ra câu trả lời
Đối với đặc trưng văn bản, các phương pháp như sử dụng Bag-Of-Words (BOW) hoặc áp dụng bộ mã hóa Long Short-Term Memory (LSTM) là những lựa chọn khả thi. Với đặc trưng hình ảnh, phương pháp phổ biến nhất là sử dụng CNN (mạng nơ-ron tích chập) đã được huấn luyện trước. Đối với bước sinh câu trả lời, cách tiếp cận thường thấy là mô hình hóa bài toán như một tác vụ phân loại.
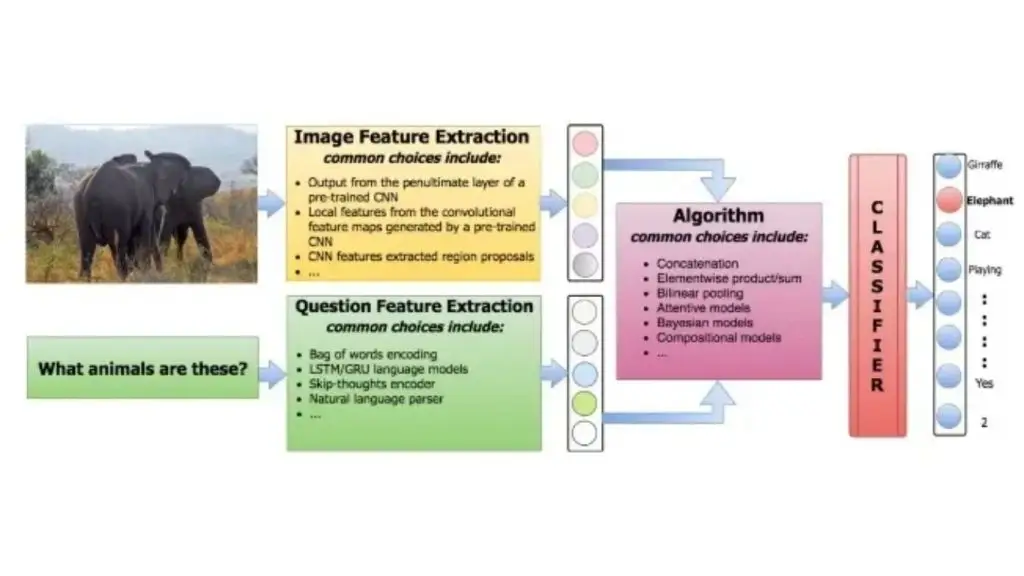
Do đó, sự khác biệt chính giữa các phương pháp VQA nằm ở cách thức chúng tích hợp các đặc trưng văn bản và đặc trưng hình ảnh. Ví dụ, một số phương pháp lựa chọn cách kết hợp đơn giản thông qua việc ghép nối các đặc trưng rồi đưa vào một mô hình phân loại tuyến tính. Ngược lại, các phương pháp khác sử dụng mô hình Bayesian để suy luận mối quan hệ tiềm ẩn giữa phân phối đặc trưng của câu hỏi, hình ảnh và câu trả lời.
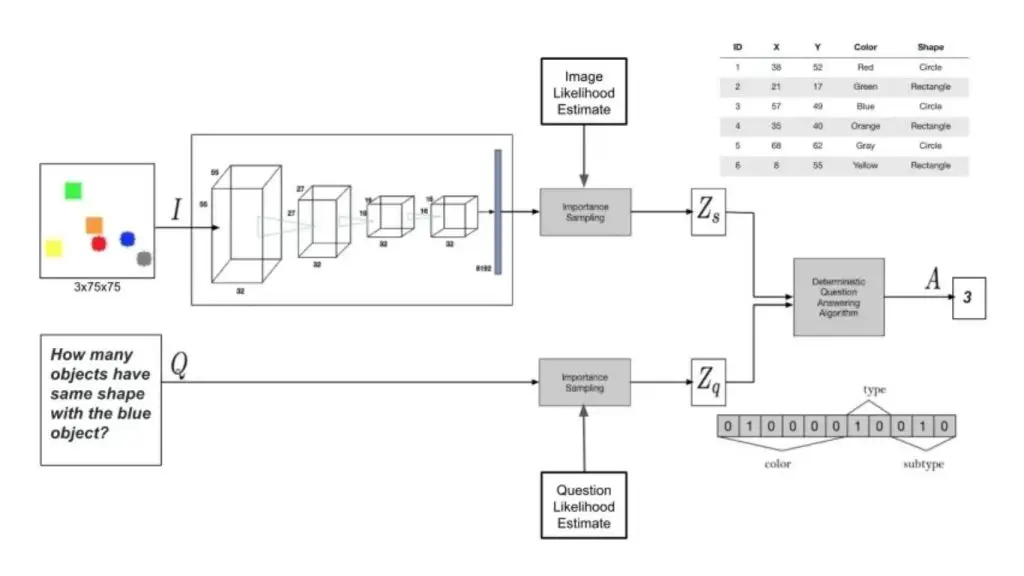
Phương pháp Bayesian
Phương pháp Bayesian giới thiệu một khung tiếp cận đặc biệt, tập trung vào mô hình hóa VQA dựa trên xác suất. Không giống các phương pháp mang tính xác định, mô hình Bayesian gán xác suất cho các kết quả khác nhau, nhằm xử lý sự không chắc chắn vốn có trong cả miền thị giác lẫn ngôn ngữ.
Phương pháp này tiếp cận này tích hợp kiến thức trước đó, tận dụng thông tin có sẵn về các đối tượng, cảnh vật hoặc mối quan hệ trong hình ảnh. Bằng cách này, phương pháp cung cấp một sự hiểu biết tinh tế hơn, cho phép hệ thống có thể đưa ra các quyết định dựa trên bối cảnh quen thuộc với ngữ cảnh.
Một điểm mạnh quan trọng của phương pháp Bayesian là khả năng định lượng độ không chắc chắn. Thay vì chỉ đưa ra một câu trả lời duy nhất, mô hình còn thể hiện mức độ tự tin hoặc không chắc chắn của câu phản hồi đó. Điều này đặc biệt hữu ích trong các tình huống hệ thống gặp phải các câu hỏi mơ hồ hoặc phức tạp.
Do VQA đòi hỏi sự tích hợp giữa hai phương thức thị giác và ngôn ngữ, các mô hình Bayesian thể hiện khả năng xuất sắc trong việc suy luận mối quan hệ giữa hai yếu tố này. Sự liên kết giữa nội dung thị giác từ hình ảnh và nội dung ngôn ngữ trong câu hỏi được xử lý một cách liền mạch, giúp nâng cao khả năng hiểu rõ hơn về nhiệm vụ.
Một khía cạnh quan trọng của phương pháp Bayesian nằm ở việc kết hợp hiệu quả các nguồn thông tin. Bằng cách xem xét phân phối xác suất chung của các đặc trưng từ cả hình ảnh và câu hỏi, mô hình tạo ra các câu trả lời không chỉ phù hợp với ngữ cảnh mà còn phản ánh sự tương tác phức tạp giữa các mô hình khác nhau.
Phương pháp Attention-based
Các phương pháp Attention-based (phương pháp dựa trên sự chú ý) nhằm hướng sự tập trung của thuật toán vào những chi tiết quan trọng nhất trong dữ liệu đầu vào. Ví dụ, với câu hỏi “Áo sơ mi của trọng tài có màu gì?”. Trong trường hợp này, vùng hình ảnh chứa nhân vật chính trở nên quan trọng hơn các vùng khác, tương tự như các từ “màu”, “áo sơ mi” và “trọng tài” mang ý nghĩa thông tin quan trọng hơn so với phần còn lại.
Trong Hệ thống Visual Question Answering, chiến lược phổ biến là sử dụng chú ý không gian để tạo ra các đặc trưng cụ thể cho từng vùng nhằm đào tạo Mạng Nơ-ron tích chập. Việc xác định các vùng không gian trong hình ảnh có thể được thực hiện theo nhiều cách khác nhau. Một phương pháp phổ biến là chiếu một lưới lên hình ảnh. Sau khi áp dụng, mức độ quan trọng của từng vùng được đánh giá dựa trên nội dung cụ thể của câu hỏi.
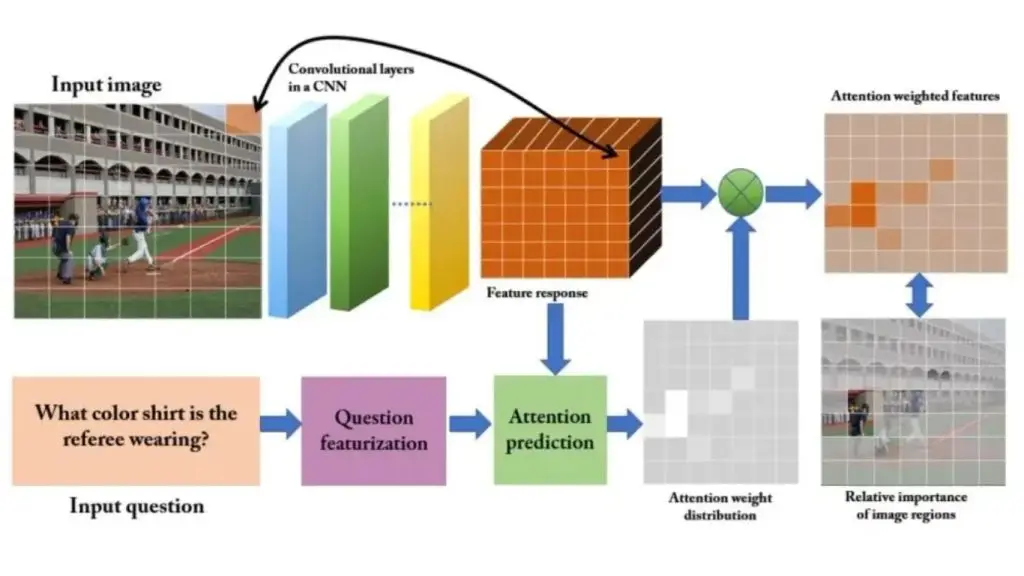
Một cách tiếp cận khác là tự động sinh ra các hộp giới hạn (bounding box) để sử dụng trong quá trình đào tạo mô hình. Hộp giới hạn làm nổi bật một vùng quan tâm cụ thể trong hình ảnh. Sau khi các vùng được đề xuất, câu hỏi sẽ được sử dụng để đánh giá mức độ liên quan của đặc trưng trong từng vùng, từ đó trích xuất có chọn lọc những thông tin cần thiết để trả lời câu hỏi.
>> Tìm hiểu thêm:
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
- Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow
Các mô hình Visual Question Answering phổ biến
Trong phần này, chúng ta sẽ mô tả một số thuật toán phổ biến được sử dụng để thực hiện Visual Question Answering.
Mô hình Pix2Struct
Pix2Struct là một mô hình deep learning (học sâu) giải quyết bài toán VQA bằng cách tận dụng khả năng chuyển đổi hình ảnh sang văn bản. Pix2Struct là một mô hình transformer encoder-decoder. Phần encoder (bộ mã hóa) phân tích hình ảnh, chia nhỏ nó thành các thành phần hình ảnh. Trong khi đó, phần decoder (bộ giải mã) giỏi trong việc hiểu và tạo ra nội dung văn bản.
Dưới đây là phân tích chi tiết về cách Pix2Struct giải quyết vấn đề VQA:
- Tiền xử lý: Đầu vào của Pix2Struct trong bài toán VQA gồm hai phần: hình ảnh và câu hỏi dạng văn bản. Pix2Struct sử dụng kỹ thuật biểu diễn đầu vào với độ phân giải thay đổi cho hình ảnh. Điều này có nghĩa là hình ảnh không bị điều chỉnh về kích thước cố định mà được chia thành các mảnh nhỏ với kích thước thay đổi tùy theo nội dung. Câu hỏi được giữ nguyên ở dạng văn bản ban đầu.
- Học biểu diễn chung: Khác với nhiều mô hình VQA xử lý hình ảnh và câu hỏi một cách tách biệt, Pix2Struct đưa cả mảnh hình ảnh và văn bản câu hỏi đồng thời vào bộ mã hóa. Bộ mã hóa – một kiến trúc dựa trên Transformer, có khả năng xử lý nhiều loại đầu vào khác nhau cùng lúc: vừa phân tích thông tin thị giác từ các mảnh hình ảnh, vừa hiểu ý nghĩa ngữ nghĩa của câu hỏi để tạo ra một biểu diễn kết hợp.
- Lập luận và sinh câu trả lời: Bộ giải mã của Pix2Struct nhận biểu diễn kết hợp từ bộ mã hóa. Bằng cách xem xét đồng thời thông tin hình ảnh và văn bản, bộ giải mã suy luận câu trả lời trong ngữ cảnh của hình ảnh và sinh ra câu trả lời dưới dạng chuỗi từ.
>> Tìm hiểu thêm: Học Máy Là Gì Và Tại Sao Học Máy Lại Quan Trọng?
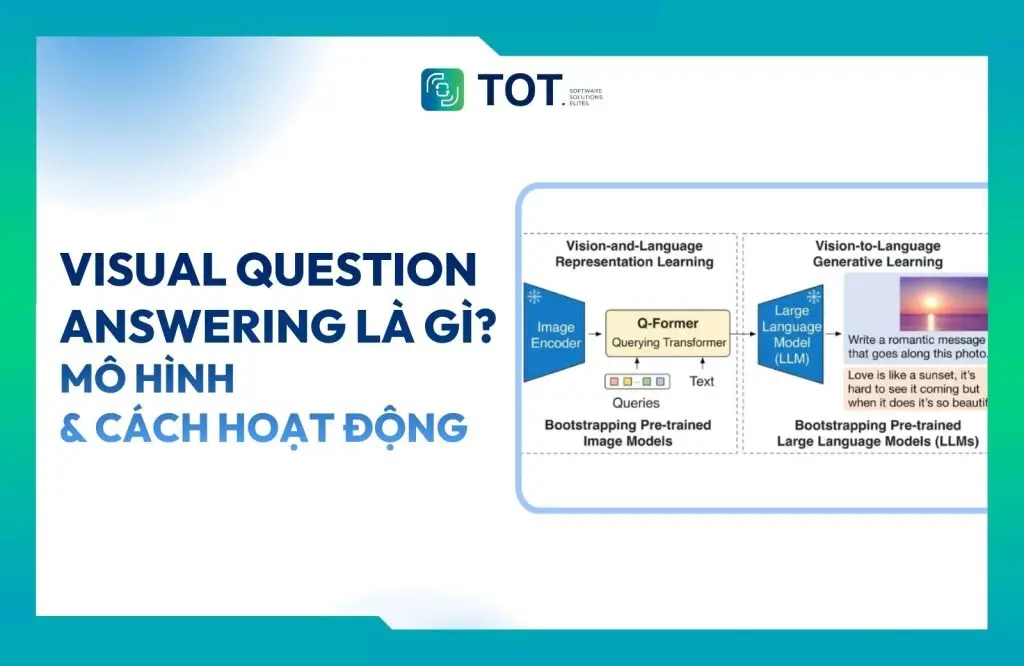
Mô hình BLIP-2
BLIP-2 (Bootstrapping Language-Image Pre-training) là một mô hình VQA tập trung mạnh vào hiệu quả. Khác với một số mô hình VQA đòi hỏi tài nguyên tính toán khổng lồ, BLIP-2 đạt được hiệu suất ngang tầm với các mô hình tiên tiến thông qua một phương pháp tối ưu hóa hơn.
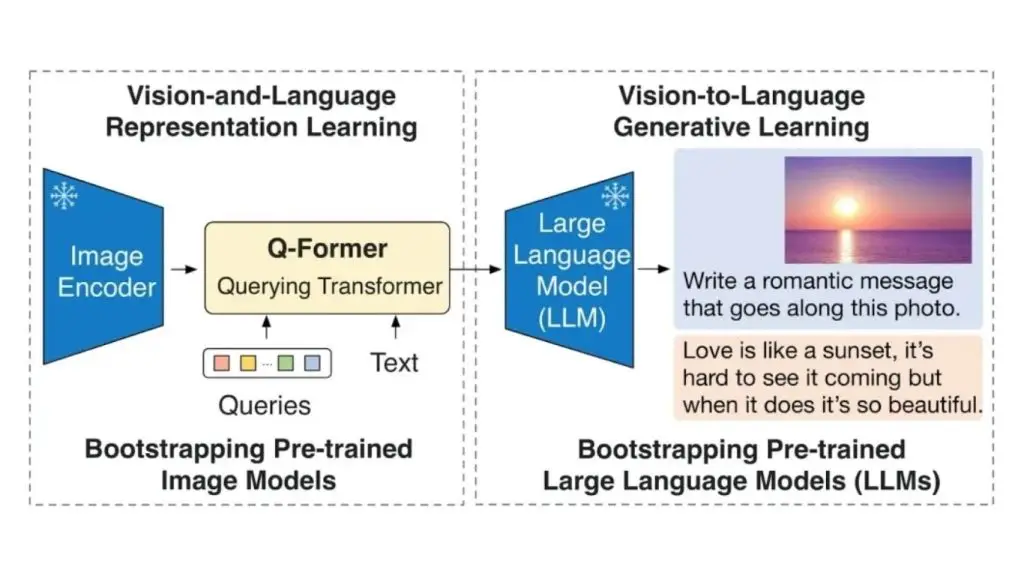
BLIP-2 đóng vai trò như một cầu nối giữa hai thành phần đã được huấn luyện trước: một bộ mã hóa hình ảnh cố định và một mô hình ngôn ngữ lớn (LLM). Bộ mã hóa hình ảnh mặc dù không được huấn luyện lần nữa trong BLIP-2 nhưng đã rất mạnh trong việc trích xuất đặc trưng hình ảnh. LLM, cũng được huấn luyện trước, mang lại khả năng hiểu và tạo ra văn bản.
Thành phần then chốt của BLIP-2 là một kiến trúc mạng nơ-ron nhẹ gọi là Querying Transformer (Q-Former). Mô hình này trải qua hai giai đoạn huấn luyện:
- Học đại diện: Trong giai đoạn đầu tiên, mô hình Q-Former được huấn luyện để học cách xây dựng một “ngôn ngữ chung” cho biểu diễn hình ảnh và văn bản. Nó đóng vai trò như một bộ phiên dịch, học cách chuyển đổi các đặc trưng thị giác từ bộ mã hóa hình ảnh sang định dạng mà mô hình ngôn ngữ lớn (LLM) có thể hiểu.
- Học tạo sinh: Sau khi Q-Former có thể chuyển đổi giữa hai phương thức, nó tiếp tục được huấn luyện ở giai đoạn thứ hai. Giai đoạn này, mô hình tập trung vào việc tạo ra các mô tả văn bản phản ánh chính xác nội dung hình ảnh. Bước này củng cố mối liên kết giữa thông tin thị giác và hiểu biết ngôn ngữ.
>> Xem thêm:
- Cách tạo prompt cho LLM trong thị giác máy tính tăng độ chính xác
- Ứng dụng AI trong bán hàng online: TOP 10 công cụ AI & cách triển khai hiệu quả
Mô hình GPT-4 with Vision
GPT-4 with Vision, thường được gọi là GPT-4V, là một bước tiến đột phá trong lĩnh vực VQA. Không giống các mô hình VQA truyền thống xử lý văn bản và hình ảnh riêng biệt, GPT-4 with Vision hoạt động như một hệ thống thống nhất.
GPT-4 with Vision tích hợp một thành phần xử lý văn bản mạnh mẽ dựa trên mô hình ngôn ngữ GPT-4, nổi tiếng với khả năng hiểu ngôn ngữ tự nhiên vượt trội. Điểm đặc biệt là GPT-V còn tích hợp một mô-đun xử lý thị giác, cho phép trực tiếp phân tích các đặc trưng hình ảnh.
Quy trình GPT-4 with Vision trả lời câu hỏi về hình ảnh gồm:
- Tích hợp đầu vào: Một hình ảnh và câu hỏi được đưa vào cùng lúc.
- Học biểu diễn chung: GPT-V không xử lý riêng lẻ, mà tạo ra một biểu diễn kết hợp, trong đó thông tin văn bản và đặc trưng hình ảnh được đan xen với nhau.
- Suy luận và tạo câu trả lời: Dựa trên biểu diễn đa phương thức phong phú này, GPT-V suy luận câu trả lời trong ngữ cảnh của hình ảnh và sử dụng khả năng ngôn ngữ để sinh ra câu trả lời hoàn chỉnh.
Khả năng xử lý thông tin một cách thống nhất mang lại cho GPT-V nhiều lợi thế: bằng cách xem xét đồng thời tín hiệu thị giác và văn bản cùng lúc, GPT-V hiểu ngữ cảnh câu hỏi sâu sắc hơn về bối cảnh đằng sau câu hỏi, từ đó tạo ra câu trả lời chính xác và tự nhiên hơn so với các mô hình xử lý tách biệt.
Ngoài ra, các mô hình ngôn ngữ đa phương thức khác như Claude 3 Opus (Anthropic), CogVLM (mã nguồn mở) và Gemini (Google) cũng có khả năng trả lời câu hỏi thị giác.
>> Tham khảo thêm:
- Các mô hình ngôn ngữ thị giác chạy cục bộ tốt nhất
- Tạo web bán hàng bằng AI miễn phí, chuẩn SEO, hiệu quả nhất
Các chỉ số đánh giá khả năng của VQA
Trong các tác vụ thị giác máy tính và xử lý ngôn ngữ, chỉ số được sử dụng phổ biến nhất là độ chính xác truyền thống. Mặc dù tiêu chuẩn này đủ cho nhiều loại tác vụ, tuy nhiên, chỉ số này không thật sự phù hợp với các câu trả lời được trả về bởi các mô hình VQA.
Hãy xem xét ví dụ sau: Nếu câu trả lời đúng là “cây sồi”, liệu câu trả lời “cây” có nên được coi là hoàn toàn sai? Tương tự, khi đối mặt với câu hỏi “Những con vật nào xuất hiện trong hình ảnh?” và hình ảnh đó thể hiện chó, mèo và thỏ, chúng ta nên đánh giá câu trả lời “mèo và chó” là sai đến mức nào?
Những thách thức này đòi hỏi các phương pháp đánh giá tinh tế hơn để so sánh chính xác các mô hình VQA.
Hãy cùng tìm hiểu một số chỉ số thường được sử dụng để đánh giá VQA:
Chỉ số WUPS
Chỉ số WUPS ước tính khoảng cách ngữ nghĩa giữa câu trả lời và dữ liệu tham chiếu, cho ra giá trị nằm trong khoảng từ 0 đến 1. Dựa trên WordNet, WUPS tính toán độ tương đồng bằng cách xem xét khoảng cách cây ngữ nghĩa của các thuật ngữ chung giữa câu trả lời và dữ liệu tham chiếu. Để khắc phục xu hướng gán giá trị tương đối cao cho các thuật ngữ không liên quan, các tác giả đề xuất giảm điểm số dưới 0.9 xuống 0.1 lần.
Chỉ số METEOR và BLEU
Chỉ số METEOR, lấy cảm hứng từ bài toán dịch máy, đánh giá chất lượng câu trả lời bằng cách xem xét độ chính xác, độ bao phủ và các thuật ngữ phạt. Chỉ số BLEU ban đầu dùng cho đánh giá dịch thuật, cũng được áp dụng trong VQA bằng cách đo mức độ tương đồng n-gram giữa câu trả lời sinh ra và câu trả lời tham chiếu.
>> Tìm hiểu thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Cách so sánh các mô hình thị giác máy tính một cách trực quan
Bộ dữ liệu VQA
Giống như nhiều loại tác vụ trong xử lý ngôn ngữ tự nhiên (NLP) và thị giác máy tính, có nhiều bộ dữ liệu VQA mở mà bạn có thể sử dụng để đào tạo và đánh giá các mô hình VQA.
Sự phức tạp của lĩnh vực Trả lời câu hỏi hình ảnh (VQA) đòi hỏi các bộ dữ liệu đủ rộng để bao quát đa dạng các khả năng tiềm ẩn trong câu hỏi và nội dung hình ảnh trong các tình huống thực tế. Nhiều bộ dữ liệu này sử dụng hình ảnh từ Microsoft Common Objects in Context (COCO), bao gồm 328.000 hình ảnh với 91 loại đối tượng dễ nhận biết đối với một đứa trẻ 4 tuổi, tổng cộng 2,5 triệu trường hợp được gắn nhãn.
Hãy xem một số bộ dữ liệu có sẵn:
Bộ dữ liệu COCO-QA
Bộ dữ liệu COCO-QA bao gồm 123.287 hình ảnh được lấy từ bộ dữ liệu COCO, với 78.736 cặp câu hỏi-trả lời (QA) dùng để đào tạo và 38.948 cặp QA dùng để kiểm tra. Để tạo ra bộ dữ liệu QA khổng lồ này, các tác giả đã sử dụng một thuật toán xử lý ngôn ngữ tự nhiên (NLP), tự động trích xuất câu hỏi từ các chú thích hình ảnh COCO. Ví dụ, với chú thích “Hai ghế trong phòng”, câu hỏi như “Có bao nhiêu ghế?” sẽ được tạo ra. Điều quan trọng cần lưu ý là tất cả các câu trả lời đều bị giới hạn trong một từ duy nhất.
Tuy nhiên, phương pháp này có một số nhược điểm: các câu hỏi chịu ảnh hưởng của những hạn chế nội tại của NLP, dẫn đến một số trường hợp câu hỏi được diễn đạt một cách kỳ lạ, chứa lỗi ngữ pháp hoặc thậm chí hoàn toàn không thể hiểu được.
Bộ dữ liệu DAQUAR
Bộ dữ liệu DAQUAR bao gồm 6.794 cặp câu hỏi-trả lời trong quá trình đào tạo và 5.674 cặp câu hỏi-trả lời trong quá trình kiểm tra, được trích xuất từ các hình ảnh trong bộ dữ liệu NYU-Depth V2. Điều này tương đương với trung bình khoảng 9 cặp câu hỏi-trả lời cho mỗi hình ảnh.
Mặc dù bộ dữ liệu DAQUAR là một nỗ lực đáng khen ngợi, tuy nhiên bộ dữ liệu NYU chỉ giới hạn trong các cảnh trong nhà và thỉnh thoảng gặp phải điều kiện ánh sáng phức tạp, gây khó khăn trong việc trả lời câu hỏi.
Bộ dữ liệu Visual QA
So với các bộ dữ liệu khác, bộ dữ liệu Visual QA có quy mô lớn hơn đáng kể. Nó bao gồm 204.721 hình ảnh được lấy từ bộ dữ liệu COCO và bổ sung thêm 50.000 hình ảnh hoạt hình trừu tượng. Mỗi hình ảnh được liên kết với ba câu hỏi, và mỗi câu hỏi có mười câu trả lời tương ứng, dẫn đến hơn 760.000 câu hỏi với khoảng 10 triệu câu trả lời.
Quá trình tạo dữ liệu bao gồm một nhóm nghiên cứu của Amazon tạo ra các câu hỏi và một nhóm khác tạo ra các câu trả lời. Mặc dù đã có những cân nhắc kỹ lưỡng trong thiết kế bộ dữ liệu, chẳng hạn như bao gồm các câu trả lời phổ biến để tăng độ khó trong việc suy luận loại câu hỏi từ tập hợp câu trả lời, một số vấn đề vẫn nảy sinh.
Đáng chú ý, một số câu hỏi quá chủ quan để có thể có một câu trả lời chính xác duy nhất. Trong trường hợp này, có thể cung cấp câu trả lời có khả năng cao nhất.
>> Xem thêm:
- Phát hiện chuyển động bằng thị giác máy tính – Cách hoạt động và logic phát hiện
- Phrase Grounding là gì? Mô hình và cách hoạt động
- Object Detection là gì? Cách hoạt động & Ứng dụng trong thực tế
Kết luận
Khả năng đặt câu hỏi về một hình ảnh cho máy tính và nhận được câu trả lời hợp lý không còn là điều viễn tưởng. Các mô hình tiên phong như Pix2Struct, BLIP-2 và GPT-V đã giúp chúng ta tiến xa hơn.
Cách tiếp cận của Pix2Struct mở ra cơ hội cho tài liệu và giao diện. BLIP-2 thể hiện hiệu quả ấn tượng, đạt kết quả hàng đầu với ít tài nguyên hơn. GPT-V, một bước đột phá, xử lý cả hình ảnh và văn bản cùng lúc, dẫn đến sự hiểu biết sâu sắc hơn về hình ảnh. Visual Question Answering hứa hẹn sẽ thay đổi cách máy tính tương tác với hình ảnh trong tương lai. Hy vọng qua bài viết trên bạn đã hiểu rõ Visual Question Answering là gì.
>>> Nguồn tham khảo: What is Visual Question Answering (VQA)?
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam







