Trong thập kỷ qua, computer vision chủ yếu tập trung vào một việc: nhận diện. Chúng ta xây dựng các mô hình để cho biết “đó là một chiếc xe”, “đây là một khuyết tật”, hoặc “đây là một người”. Nhưng bối cảnh AI đang thay đổi nhanh chóng. Chúng ta đang chuyển từ các mô hình tĩnh chỉ đơn thuần nhìn thấy sang các tác nhân động có khả năng suy nghĩ và hành động.
Đó chính là lúc Vision AI Agents (Tác nhân AI Thị giác) hay Vision Agents xuất hiện. Được vận hành bởi khả năng mạnh mẽ của các foundation models mới như Gemini 3 Pro của Google, những tác nhân này suy luận về thế giới hình ảnh, lập kế hoạch cho các tác vụ nhiều bước và thực thi hành động để giải quyết các vấn đề phức tạp.
Trong bài viết này, chúng ta sẽ khám phá Vision AI Agents là gì, cách các foundation models như Gemini 3 Pro trao quyền cho chúng, tại sao chúng đại diện cho một sự chuyển đổi thế hệ trong computer vision, và cách bạn có thể bắt đầu xây dựng tác nhân của riêng mình bằng Roboflow Workflows.
>>> Xem thêm bài viết:
- Hướng dẫn tạo Landing Page bằng AI hiệu quả nhất hiện nay
- Hướng dẫn tạo app bằng Low Code đơn giản, hiệu quả nhất
- Cách sử dụng chatbot cho giáo dục đại học và học tập
Vision AI Agents là gì?
Vision AI Agent là một hệ thống tự động kết hợp khả năng nhận thức thị giác với khả năng lý luận của Mô hình Đa phương thức Lớn (Large Multimodal Model – LMM). Không giống như mô hình phát hiện đối tượng (object detection) truyền thống chỉ thực hiện một tác vụ duy nhất, một vision agent hoạt động theo vòng lặp:
- Nhận thức: Tác nhân thu thập dữ liệu thị giác (hình ảnh, luồng video hoặc bản ghi màn hình) từ môi trường.
- Lý luận: Vision agent sử dụng mô hình nền tảng để hiểu ngữ cảnh, mối quan hệ không gian và ý định đằng sau dữ liệu thị giác; không chỉ nhận diện đối tượng mà còn thấu hiểu các cảnh phức tạp.
- Hành động: Hệ thống sử dụng các công cụ như gọi API, truy vấn cơ sở dữ liệu, kích hoạt cánh tay robot hoặc nhấp vào nút để đạt được mục tiêu.
- Phản ánh: Tác nhân xác minh xem hành động có thành công không và điều chỉnh kế hoạch nếu cần thiết. Thiết kế vòng lặp kín này cho phép cải tiến và thích ứng liên tục.
Vòng lặp “Quan sát, Suy nghĩ, Hành động, Phản ánh” này về cơ bản khác với các quy trình thị giác máy tính truyền thống. Một mô hình cổ điển phát hiện đối tượng và dừng lại. Một tác nhân phát hiện, hiểu, quyết định và hành động; sau đó học hỏi từ kết quả.
>> Xem thêm:
- Mẹo tạo prompt cho LLM trong thị giác máy tính để tăng độ chính xác
- AI tạo sinh là gì? Cách hoạt động và Ứng dụng thực tế
- Data Annotation Platforms: Nền tảng gán nhãn dữ liệu cho thị giác máy tính tốt nhất

Công cụ: Gemini 3 Pro
Yếu tố thúc đẩy sự thay đổi này là sự xuất hiện của các mô hình nền tảng đa phương thức có khả năng cao. Gemini 3 Pro, được phát hành bởi Google DeepMind vào cuối năm 2025, đại diện cho một bước nhảy vọt thế hệ trong lĩnh vực này.
Không giống như các mô hình trước đây coi hình ảnh là đầu vào thứ yếu, Gemini 3 Pro vốn dĩ là đa phương thức ngay từ đầu. Mô hình được huấn luyện từ đầu để hiểu văn bản, mã code, âm thanh, hình ảnh và video đồng thời. Điều này có nghĩa là mô hình không có các module “thị giác” và “ngôn ngữ” riêng biệt cần được ghép nối với nhau. Thay vào đó, mọi thứ được xử lý theo cách thống nhất thông qua tokenization xen kẽ.

Các khả năng chính của Vision AI Agents
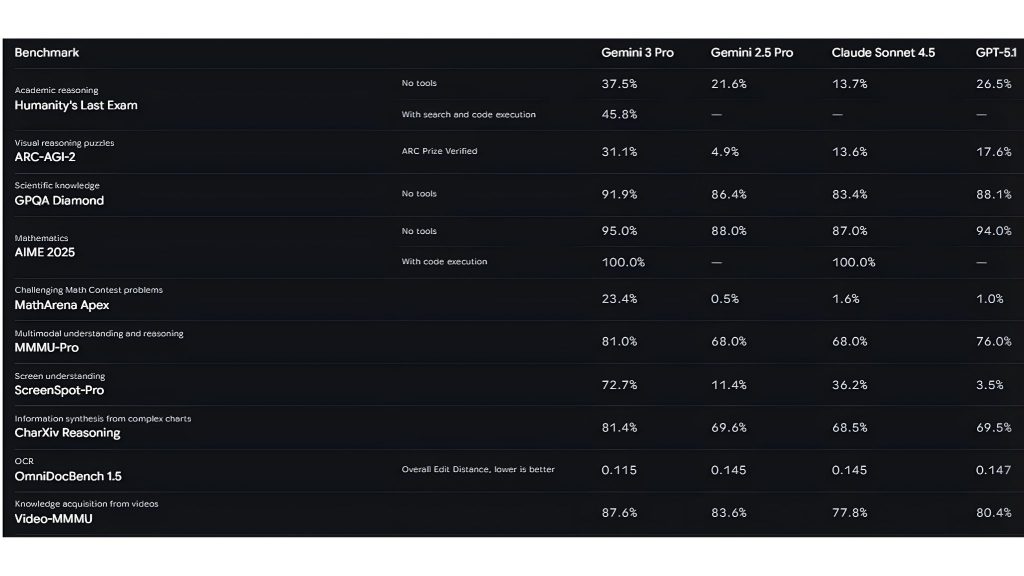
- Suy luận đa phương thức phức tạp: Gemini 3 Pro đạt 81% trên MMMU-Pro; một bài kiểm tra đo lường các nhiệm vụ suy luận hình ảnh phức tạp đòi hỏi suy luận có chủ ý trên các sơ đồ, biểu đồ và giải quyết vấn đề trực quan.
- Khả năng hiểu video nâng cao: Với điểm 87,6% trên Video-MMMU, Gemini 3 Pro xuất sắc trong suy luận thời gian, hiểu cách nội dung video phát triển theo thời gian. Mô hình được tối ưu hóa để xử lý video ở 10 FPS, nắm bắt các hành động nhanh có thể bị bỏ lỡ ở tốc độ lấy mẫu tiêu chuẩn.
- Hiểu biết không gian & định vị: Gemini 3 Pro có thể xuất tọa độ chính xác từng pixel, cho phép nó “chỉ” vào các đối tượng cụ thể trong hình ảnh hoặc các phần tử giao diện.
- Cửa sổ bối cảnh 1M+ token: Cửa sổ bối cảnh khổng lồ cho phép mô hình xử lý hàng giờ video hoặc hàng nghìn trang tài liệu trong một lần.
- Suy luận thông minh với chế độ Deep think: Với các tính năng như “Deep Think”, mô hình có thể phân tách các nhiệm vụ hình ảnh phức tạp thành các kế hoạch từng bước (ví dụ: “Đầu tiên, xác định vị trí của ốc vít. Thứ hai, kiểm tra xem nó có bị gỉ không…”).
- Đầu ra có cấu trúc: Nó có thể xuất JSON một cách đáng tin cậy, giúp dễ dàng chuyển suy luận của nó trực tiếp vào mã hoặc các hệ thống phần mềm khác.
- Hiểu văn bản: Gemini 3 Pro xuất sắc trong việc xử lý các tài liệu thực tế với chữ viết tay lộn xộn, bảng lồng nhau và bố cục phi tuyến tính, đạt 80,5% trên bài kiểm tra CharXiv Reasoning.
>> Xem thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
- Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow
Sự chuyển đổi kiến trúc từ nhận thức sang lý luận
Để xây dựng một Vision AI Agent hiệu quả đòi hỏi ba thành phần hoạt động hài hòa:
Thành phần 1: Lớp nhận thức (Phát hiện nhanh)
Lớp nhận thức xử lý đầu vào hình ảnh theo thời gian thực. Để tốc độ và hiệu quả chi phí, đây là nơi các mô hình chuyên biệt như RF-DETR hoặc YOLO11 tỏa sáng. Những mô hình này nhanh; YOLO11 có thể chạy ở tốc độ 200+ FPS trên GPU và có thể được tinh chỉnh để phát hiện các đối tượng đặc thù theo lĩnh vực.
Thành Phần 2: Lớp suy luận (Các mô hình nền tảng)
Lớp suy luận trả lời các câu hỏi phức tạp đòi hỏi bối cảnh. Đây là nơi Gemini 3 Pro hoạt động. Nó thu thập kết quả từ lớp nhận thức (cùng với ảnh/video thô) và thực hiện suy luận cấp cao.
Thành Phần 3: Lớp Hành Động (API và công cụ)
Lớp hành động thực thi các quyết định. Nếu lớp suy luận quyết định rằng một công nhân không đeo thiết bị an toàn, lớp hành động có thể kích hoạt cảnh báo Slack hoặc báo hiệu cho hệ thống robot tạm dừng.

Xây dựng Vision AI Agents với quy trình làm việc Roboflow
Trong khi các mô hình nền tảng cung cấp “bộ não”, chúng thường thiếu tốc độ hoặc kiểm soát chi tiết cần thiết cho các nhiệm vụ doanh nghiệp cụ thể. Đây là nơi Roboflow Workflows phát huy tối đa hiệu quả.
Bằng cách kết hợp suy luận của Gemini 3 Pro với độ chính xác của các mô hình chuyên biệt (như YOLO11 hoặc RF-DETR) bên trong Roboflow Workflows, bạn có thể xây dựng các tác nhân mạnh mẽ vừa thông minh vừa nhanh chóng.
Hãy cùng nhau xây dựng một thứ gì đó đơn giản. Vision AI Agents của chúng ta thực hiện các bước sau:
- Phát hiện sự hiện diện của khuôn mặt bằng cách sử dụng mô hình RF-DETR nhanh, đã được huấn luyện trước.
- Thiết lập luồng công việc để lý luận ở phía sau chỉ chạy nếu phát hiện khuôn mặt.
- Sử dụng Gemini 3 Pro để phân tích hoạt động và trạng thái chú ý của người được phát hiện.
- Chuyển đổi đầu ra của Gemini thành JSON có cấu trúc để đảm bảo độ tin cậy cho các logic xử lý tiếp theo.
- Gửi thông báo email tự động chứa kết quả được phân tích.
Thiết kế này đảm bảo tác nhân hoạt động nhanh, tiết kiệm chi phí và có tính xác định, đồng thời vẫn tận dụng được khả năng suy luận cấp cao.
>> Xem thêm:
- Các Mô Hình Ngôn Ngữ Thị Giác Chạy Cục Bộ Tốt Nhất
- AI agent là gì? Cách Agentic AI hoạt động trong hệ thống trí tuệ nhân tạo
- Cách tạo ứng dụng AI với vibe coding trên Google AI Studio đơn giản
Bước 1: Đăng nhập vào Roboflow
- Truy cập Roboflow và đăng nhập. Nếu chưa có tài khoản, hãy đăng ký miễn phí; chỉ mất một phút.
- Đảm bảo bạn đã thiết lập không gian làm việc cho các dự án của mình.
Bước 2: Tạo workflow mới
Bắt đầu bằng cách tạo một workflow mới trong Roboflow Workflows. Điều hướng đến tab workflow ở bên trái và nhấp “create workflow”:
Sau đó chọn “build your own” và nhấp “Create Workflow”:
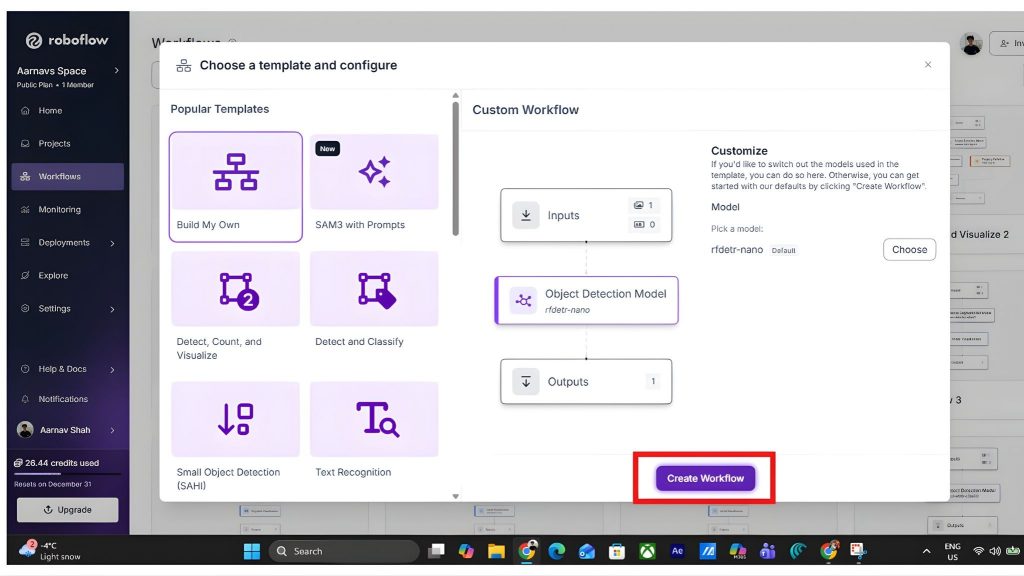
Quy trình này sẽ xử lý hình ảnh từng khung hình một. Dữ liệu đầu vào có thể đến từ hình ảnh được tải lên, chụp ảnh định kỳ hoặc nguồn cấp dữ liệu từ camera.
Bước 3: Thêm mô hình nhận diện khuôn mặt nhanh
Bước đầu tiên trong workflow là object detection nhanh.
Thêm một khối Object Detection và chọn mô hình RF-DETR phát hiện khuôn mặt có sẵn. Hướng dẫn này giả định rằng bạn đã có mô hình object detection được xây dựng sẵn. Nếu chưa, bạn có thể sử dụng hướng dẫn để tạo một mô hình. Hiện tại, tôi sẽ sử dụng mô hình phát hiện khuôn mặt mà tôi đã tạo trước đó.
Chọn khối object detection model và sau đó nhấp vào mục “Model” trong panel bên phải.
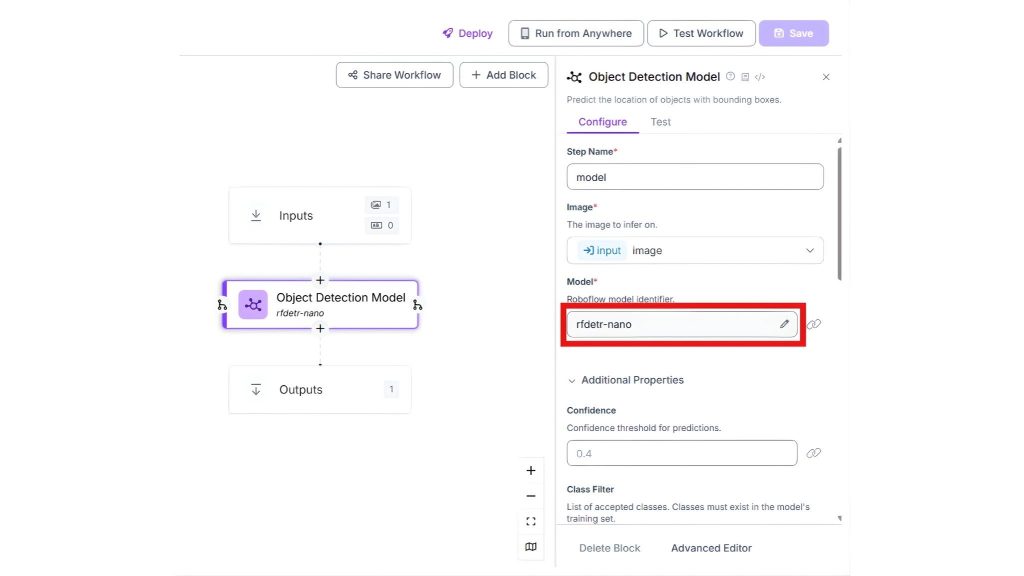
Chọn mô hình ưa thích của bạn để hoạt động như lớp nhận thức cho phát hiện đối tượng nhanh:
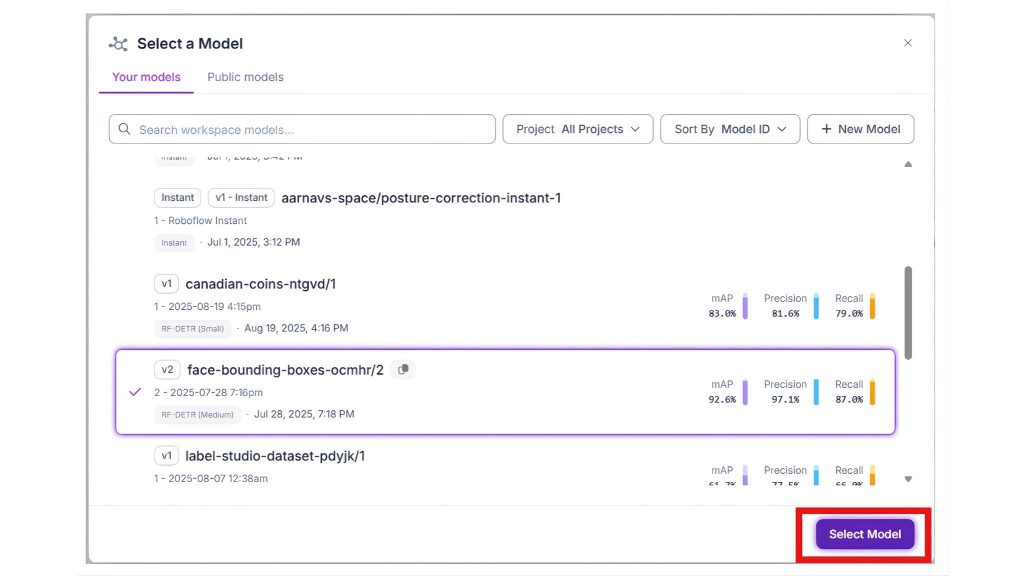
Lý do bước này được thực hiện đầu tiên: Nó tránh các cuộc gọi LLM không cần thiết; nó lọc bỏ các khung trống; RF-DETR nhanh và có tính xác định.
Đến giai đoạn này, workflow có thể xác định một cách đáng tin cậy liệu có khuôn mặt nào tồn tại trong hình ảnh hay không.
>> Xem thêm:
- Các mô hình phát hiện đối tượng tốt nhất năm 2025
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- Phát hiện đối tượng trong video với RF-DETR
Bước 4: Kiểm soát workflow bằng logic có điều kiện
Tiếp theo, thêm khối Continue If.
Khối này đảm bảo rằng workflow chỉ tiếp tục khi phát hiện khuôn mặt.
Trong bước Configure Condition, bạn đang cho workflow biết chính xác tín hiệu nào sẽ quyết định xem việc thực thi có tiếp tục hay không. Khi bạn chọn $steps.model.predictions, bạn đang chỉ điều kiện vào đầu ra thô của mô hình phát hiện của bạn.
Chọn “Condition based on the Number of Bounding Boxes” có nghĩa là workflow sẽ đánh giá có bao nhiêu phát hiện còn lại sau khi xử lý, thay vì kiểm tra giá trị pixel hoặc metadata mô hình.
Chuyển đổi chính ở đây là “Filter detections before counting?” khi được bật, Roboflow áp dụng các bộ lọc phát hiện của bạn trước khi số lượng được tính toán, loại bỏ các dự đoán độ tin cậy thấp, thực thi các ràng buộc lớp (ví dụ: chỉ khuôn mặt).
Cuối cùng, đặt Detection Threshold (≥) xác định số lượng tối thiểu các phát hiện hợp lệ cần thiết để tiếp tục; ví dụ: ≥ 1 đảm bảo workflow chỉ tiếp tục khi ít nhất một đối tượng thực tế, đã được lọc được phát hiện.
Cùng nhau, các cài đặt này đảm bảo rằng các bước downstream (như suy luận Gemini hoặc cảnh báo email) chỉ chạy khi một phát hiện có ý nghĩa thực sự tồn tại. Cuối cùng, không cần điền vào “next steps”, vì Roboflow sẽ tự động thực hiện điều này.
Bước kiểm soát này rất quan trọng để xây dựng các tác nhân có khả năng mở rộng.
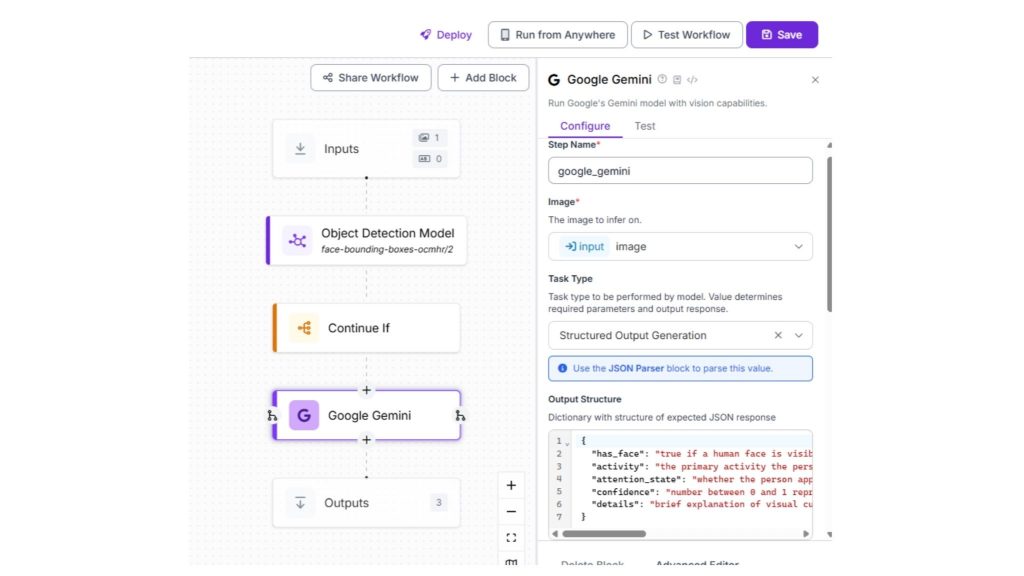
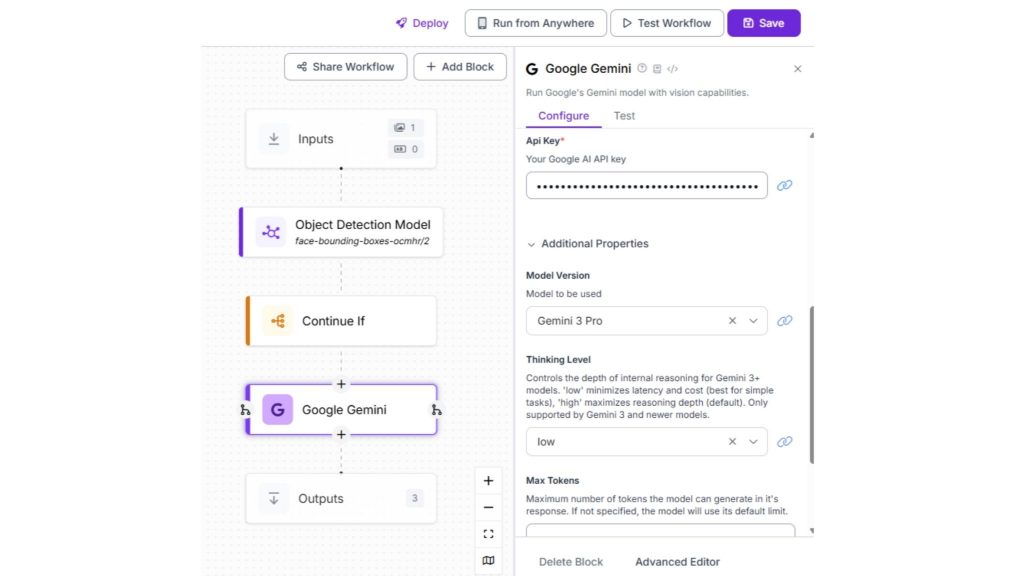
Bước 5: Thêm Gemini 3 Pro để phân tích hoạt động
Khi phát hiện khuôn mặt, hình ảnh được chuyển đến Gemini 3 Pro, hoạt động như lớp suy luận.
Thêm khối Google Gemini và chọn một prompt có cấu trúc, ví dụ như:
“{
"has_face": "true nếu có khuôn mặt người trong ảnh, ngược lại là false".
"hoạt động": "hoạt động chính mà người đó dường như đang làm (ví dụ: nói chuyện, nhìn điện thoại, đi bộ). Nếu không rõ, ghi là 'không xác định'".
"attention_state": "cho dù người đó có vẻ đang chú ý, mất tập trung hay thờ ơ",
"Độ tin cậy": "một con số nằm giữa 0 và 1, thể hiện độ tin cậy trong việc phân loại hoạt động".
"Chi tiết": "Giải thích ngắn gọn về các dấu hiệu trực quan được sử dụng để suy luận hoạt động"
}”
Gemini thực hiện suy luận ngữ nghĩa cấp cao mà các mô hình thị giác truyền thống không thể: Cung cấp giải thích theo bối cảnh, ước tính trạng thái chú ý và suy ra hoạt động.
Vì vậy, chọn mô hình Gemini 3 Pro và cung cấp khóa API Gemini của bạn. Tiếp theo, cấu hình mức độ suy nghĩ, kiểm soát mức độ sâu mà mô hình suy luận về mỗi đầu vào. Đối với các ứng dụng đơn giản hơn hoặc quy mô nhỏ hơn, mức độ suy nghĩ thấp hơn thường đủ và giữ độ trễ thấp.
Đối với các tình huống phức tạp hơn hoặc triển khai quy mô lớn đòi hỏi suy luận tinh tế và nhất quán, nên sử dụng mức độ suy nghĩ cao hơn.
Bước 6: Chuyển đổi đầu ra của Gemini thành JSON có cấu trúc
Gemini trả về văn bản, điều này không đáng tin cậy cho việc tự động hóa trừ khi văn bản đó được cấu trúc.
Thêm khối JSON Parser ngay sau khối Gemini.
Trong phần Expected Fields, chúng ta có thể định nghĩa các trường khớp với JSON có cấu trúc mà chúng ta yêu cầu Gemini trả về. Dựa trên prompt được sử dụng trong workflow này, các trường phù hợp nhất là has_face, activity, attention_state, confidence và details.
Các trường này cho phép workflow phân tích đáng tin cậy đầu ra của Gemini và sử dụng nó trong các bước downstream như thông báo hoặc ghi log. Đối với ứng dụng của riêng bạn, các trường chính xác có thể khác nhau tùy thuộc vào thông tin bạn muốn mô hình trích xuất.
Bước này chuyển đổi suy luận dạng tự do thành dữ liệu có thể đọc được bằng máy mà các hành động downstream có thể tin tưởng.
Bước 7: Gửi thông báo email tự động
Cuối cùng, thêm khối Email Notification để đóng vai trò là bước hành động của workflow. Trong khi cảnh báo email là một ví dụ đơn giản, cùng một mẫu áp dụng cho các trường hợp sử dụng nâng cao hơn; Roboflow Workflows sử dụng cơ chế chính xác này để kích hoạt bất kỳ hành động nào tiếp theo, cho dù đó là ghi log vào cơ sở dữ liệu, gọi webhook hoặc tích hợp với các hệ thống bên ngoài.
Khối lệnh này sẽ gửi cảnh báo khi workflow đạt đến điểm này, có nghĩa là:
- Kết quả đầu ra đã được phân tích thành dữ liệu có cấu trúc.
- Gemini đã phân tích thành công hình ảnh
- Một khuôn mặt đã được phát hiện
Email có thể bao gồm:
- Chi tiết bổ sung
- Điểm độ tin cậy
- Trạng thái chú ý
- Hoạt động được phát hiện
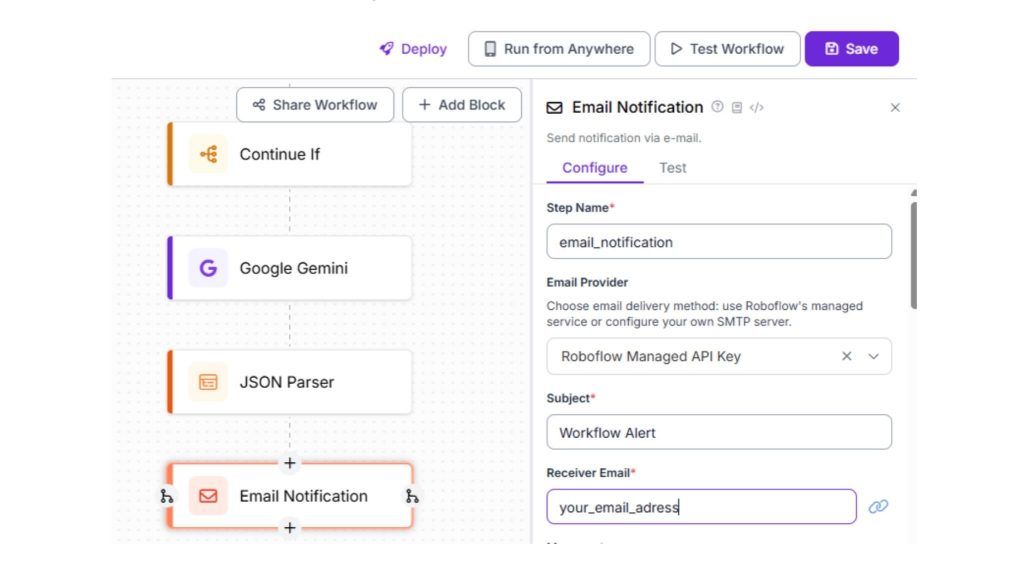
Để bắt đầu, sau khi bạn đã chọn khối đúng, hãy bắt đầu bằng cách đặt tên bước rõ ràng cho khối, chẳng hạn như email_notification, để dễ dàng xác định và gỡ lỗi sau này trong workflow. Tiếp theo, quyết định về nhà cung cấp email.
Đối với hầu hết người dùng, khuyến nghị chọn Roboflow Managed API Key, vì Roboflow sẽ xử lý việc gửi email cho bạn mà không cần thiết lập SMTP nào. Sau đó, điền vào trường subject với tiêu đề ngắn, mô tả như Workflow Alert, để email ngay lập tức có thể nhận ra.
Cuối cùng, nhập địa chỉ email người nhận, xác định nơi thông báo sẽ được gửi đến; điều này có thể giữ nguyên tĩnh hoặc được tạo động sau, tùy thuộc vào trường hợp sử dụng của bạn.
Tiếp theo, điền vào những gì bạn muốn bên trong email. Đây là nội dung cảnh báo có thể đọc được của con người. Nó hỗ trợ tạo mẫu bằng cú pháp {{ }}.
Ví dụ:
Đã phát hiện khuôn mặt
Có khuôn mặt: {{ $parameters.has_face }}
Hoạt động: {{ $parameters.activity }}
Chú ý: {{ $parameters.attention_state }}
Độ tin cậy: {{ $parameters.confidence }}
Chi tiết: {{ $parameters.details }}- Thông báo này không truy cập trực tiếp vào các bước.
- Chỉ tham chiếu đến các tham số thông báo.
- {{ $parameters.* }} là các phần giữ chỗ sẽ được thay thế bằng các giá trị thực tại thời điểm chạy.
Cuối cùng, chúng ta có thể thêm tất cả các tham số. Phần này liên kết dữ liệu thực từ workflow của bạn với các phần giữ chỗ được sử dụng trong thông báo.
Mỗi thuộc tính thực hiện hai việc:
- Kéo một giá trị từ một bước trước đó
- Làm cho nó có sẵn dưới dạng {{ $parameters.<name> }} trong thông điệp
Ví dụ:
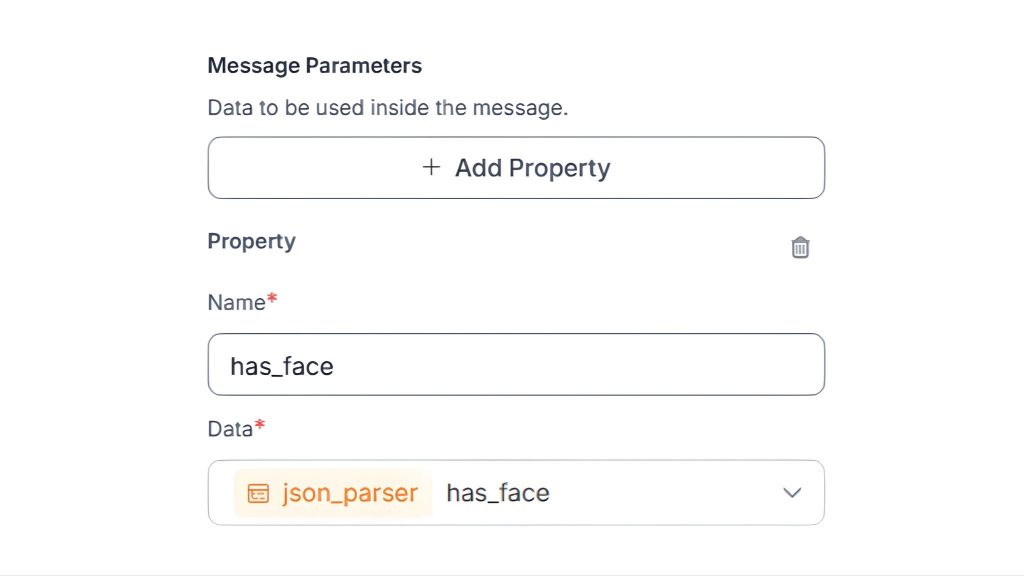
Lặp lại mẫu chính xác này cho tất cả các biến từ các bước trước đó mà bạn muốn đưa vào thông điệp của mình. Bước này là bắt buộc. Nếu một giá trị không được định nghĩa ở đây, nó không thể được sử dụng trong thông điệp, ngay cả khi nó tồn tại trong các bước trước đó.
>> Xem thêm:
- Character AI là gì? Trò chuyện cùng nhân vật ảo trên mô hình mới
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Inference In Computer Vision: Suy luận trong thị giác máy tính là gì?
Bước 8: Kiểm thử, kích hoạt và lặp lại
Sau khi hoàn tất quy trình, hãy xác thực và triển khai nó.
Tải lên một hình ảnh thử nghiệm vào workflow
Nếu phát hiện khuôn mặt:
- Mô hình phát hiện trả về các dự đoán hợp lệ
- Điều kiện “Continue If” vượt qua
- Hình ảnh được gửi đến Gemini 3 Pro để suy luận
- JSON Parser trích xuất các trường có cấu trúc
- Email được gửi với hoạt động, trạng thái chú ý, độ tin cậy và chi tiết
Nếu không phát hiện khuôn mặt:
- Điều kiện “Continue If” không thành công
- Workflow dừng ngay lập tức
- Gemini không được gọi
- Không có email nào được gửi
Xác minh:
- Chỉ nhận được email khi có hình ảnh khuôn mặt.
- Các giá trị email được điền tự động (không phải là các chỗ giữ chỗ trong mẫu).
- Không có suy luận hoặc cảnh báo không cần thiết cho các khung hình trống
Kiến trúc Vision AI Agent (Phù hợp với Workflow này)
Workflow này triển khai một kiến trúc Vision AI Agent hoàn chỉnh:
- Hành động (phần “Bàn tay”): Một cảnh báo email tự động được kích hoạt dựa trên kết quả.
- Đầu ra có cấu trúc: Phản hồi của Gemini được chuyển đổi thành JSON có tính xác định.
- Khả năng suy luận (Bộ não): Gemini 3 Pro phân tích hoạt động và sự chú ý của con người.
- Luồng điều khiển: Logic điều kiện đảm bảo quá trình suy luận tiếp theo chỉ được thực thi khi cần thiết.
- Nhận thức (Phần “Đôi mắt”): Mô hình phát hiện khuôn mặt RF-DETR nhanh chóng xác định xem có khuôn mặt nào hiện diện hay không.
- Kích hoạt: Một khung hình ảnh được đưa vào quy trình làm việc.
>>> Xem thêm:
- Tạo web bán hàng bằng AI miễn phí, chuẩn SEO, hiệu quả nhất
- Hướng dẫn cách sử dụng Google AI Studio hiệu quả, nhanh chóng
Các trường hợp sử dụng thực tế: Vision AI Agents trong hành động
1. Kiểm thử QA tự động
Vision AI Agents có thể “quan sát” giao diện phần mềm, sử dụng khả năng hiểu màn hình của Gemini 3 Pro để xác minh rằng các nút xuất hiện đúng vị trí và giao diện người dùng phản hồi chính xác. Tác nhân có thể nhấp vào các nút, điền vào biểu mẫu và xác minh kết quả dựa trên việc giao diện người dùng “trông đúng” hay không, thay vì chỉ kiểm tra tọa độ pixel.
2. Robot thông minh và sản xuất
Thay vì mã hóa cứng tọa độ robot, một hệ thống thị giác có thể được giao một mục tiêu cấp cao: “Dọn dẹp bàn”. Nó sử dụng Gemini 3 Pro để phân biệt rác thải và vật dụng có giá trị, đồng thời hướng dẫn đầu cuối của robot. Đối với sản xuất, các hệ thống này có thể thực hiện kiểm soát chất lượng bằng cách phát hiện lỗi (sử dụng YOLO11) và phân tích nguyên nhân gốc rễ (sử dụng Gemini).
3. Xử lý tài liệu phức tạp: Các công cụ OCR
Các công cụ OCR tiêu chuẩn thường thất bại trên các tài liệu lộn xộn. Gemini 3 Pro có thể đọc tài liệu như một con người, tổng hợp thông tin từ biểu đồ và văn bản đồng thời. Các tổ chức xử lý hàng nghìn hóa đơn hoặc hồ sơ y tế đạt được cải thiện năng suất khổng lồ.
4. Phân tích và huấn luyện thể thao
Khả năng xử lý video 10 FPS của Gemini 3 Pro biến đổi hoàn toàn công tác huấn luyện. Tải lên bản ghi hình một giải đấu golf, và phần mềm sẽ nhận diện đối tượng, phân tích kỹ thuật vung gậy từng khung hình một, và đưa ra các khuyến nghị cá nhân hóa; một phân tích mà trước đây cần đến các chuyên gia đắt tiền.
5. Giám sát an toàn và tuân thủ
Vision AI Agents giám sát các môi trường có rủi ro cao theo thời gian thực. Sử dụng các mô hình phát hiện nhẹ kết hợp với Gemini 3 Pro, tác nhân có thể đánh giá tuân thủ (ví dụ: sử dụng PPE đúng cách) và kích hoạt cảnh báo trước khi sự cố xảy ra, áp dụng kiến thức miền để đưa ra quyết định phán đoán.
>> Xem thêm:
- Trí tuệ nhân tạo (AI) là gì? Hiểu đúng về khái niệm & ứng dụng
- Khả năng thị giác của Chat GPT-5 và Cách Prompt hiệu quả

Kết luận về Vision AI Agents
Kỷ nguyên của Vision AI Agent đã đến. Vision AI Agents là gì? Đó chính là các hệ thống thông minh có khả năng không chỉ “nhìn” mà còn “hiểu” và “hành động” dựa trên dữ liệu thị giác. Bằng cách tận dụng sức mạnh lý luận của các mô hình như Gemini 3 Pro cùng với cơ sở hạ tầng mạnh mẽ của Roboflow, các nhà phát triển có thể xây dựng các hệ thống tích cực tham gia vào việc quan sát thế giới.
Bạn không còn phải lựa chọn giữa tốc độ và lý luận. Các mô hình chuyên biệt nhanh xử lý nhận thức; các mô hình nền tảng xử lý lý luận; Roboflow Workflows điều phối toàn bộ pipeline.
Cho dù bạn đang tự động hóa kiểm tra công nghiệp, xây dựng trợ lý thông minh hay xử lý tài liệu phức tạp, con đường phía trước rất rõ ràng: bắt đầu với Roboflow Workflows, kết hợp các mô hình chuyên biệt với lý luận Gemini 3 Pro, và để các vision agents của bạn học hỏi và thích ứng.
Nguồn tham khảo: Vision Agents
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam