Foundation model đang tạo nên bước ngoặt lớn trong AI nhờ khả năng xử lý linh hoạt văn bản, hình ảnh, video và dữ liệu đa phương thức chỉ trong một mô hình duy nhất. Vậy điều gì khiến các mô hình này trở nên nổi bật và trở thành nền tảng cho hàng loạt ứng dụng AI hiện đại? Hãy cùng tìm hiểu foundation model là gì và cách các mô hình GPT-4o, Google Gemini hay Llama 3.2 Vision được ứng dụng thực tế qua bài viết sau.
>>> Tìm hiểu thêm:
- Phrase Grounding là gì? Mô hình và cách hoạt động
- Deep Learning là gì? Tổng quan về cách hoạt động và ứng dụng thực tế
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
- Hướng dẫn triển khai AI trong ứng dụng di động đơn giản
Foundation Model là gì?
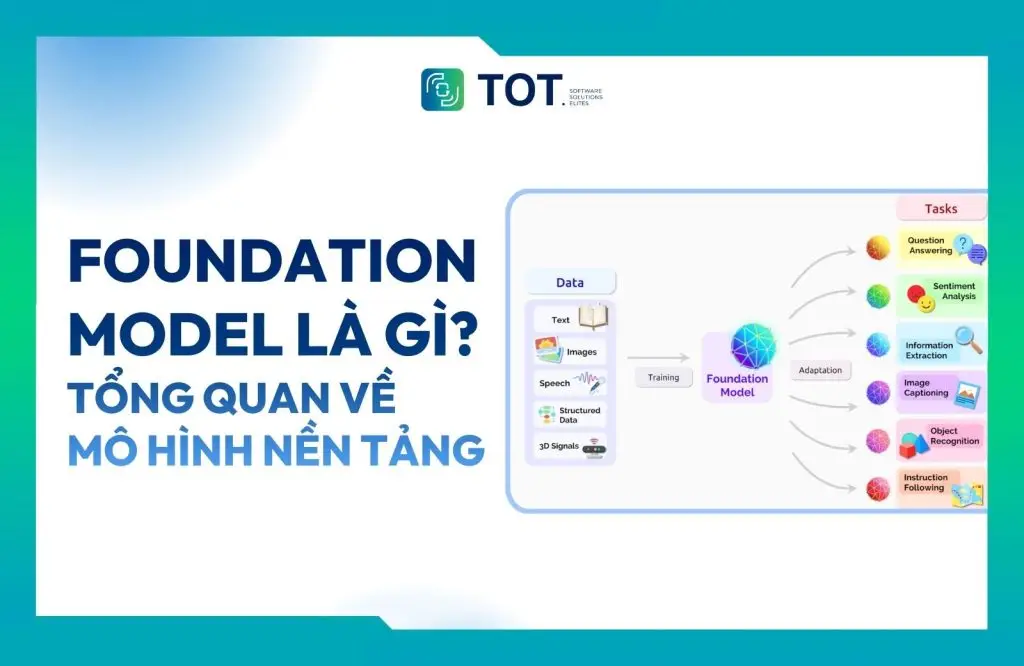
Foundation model (còn gọi là mô hình nền tảng) là một mô hình trí tuệ nhân tạo (AI) được huấn luyện trên một tập dữ liệu rộng và đa dạng với mục đích xử lý nhiều loại tác vụ khác nhau.
Các mô hình nền tảng có thể được sử dụng trực tiếp mà không cần đào tạo lại, đồng thời cũng có thể được tinh chỉnh cho nhiều tác vụ hạ nguồn khác nhau, bao gồm cả tự động gán nhãn hình ảnh (auto-labeling images) để huấn luyện các mô hình thị giác máy tính (computer vision). Những mô hình này học được các mẫu, mối quan hệ và biểu diễn từ lượng dữ liệu khổng lồ, thường thông qua các kỹ thuật học tự giám sát hoặc học không giám sát.
Thuật ngữ ”nền tảng” đề cập đến ý tưởng rằng các mô hình này đóng vai trò như một nền móng hoặc điểm khởi đầu cho nhiều ứng dụng AI khác nhau.
Mô hình nền tảng là các mô hình lớn đã được huấn luyện trước trên lượng dữ liệu rất lớn, chẳng hạn như văn bản, hình ảnh, âm thanh và video. Các mô hình này được thiết kế để học các đặc trưng và mẫu chung trong dữ liệu, từ đó có thể áp dụng cho nhiều loại tác vụ khác nhau.
>> Tham khảo thêm:
- Cách so sánh các mô hình thị giác máy tính một cách trực quan
- Computer Vision Software: Các phần mềm thị giác máy tính miễn phí
- Data Annotation Platforms: Nền tảng gán nhãn dữ liệu cho thị giác máy tính tốt nhất
Những đặc điểm chính của mô hình nền tảng
Dưới đây là những đặc điểm nổi bật của mô hình nền tảng:
- Tiền huấn luyện quy mô lớn: Mô hình nền tảng được huấn luyện trên các tập dữ liệu khổng lồ, thường sử dụng tính toán phân tán và các kỹ thuật tối ưu hóa quy mô lớn.
- Khả năng khái quát hóa: Mô hình nền tảng có thể được tinh chỉnh cho nhiều loại tác vụ khác nhau, thường chỉ cần một lượng nhỏ dữ liệu huấn luyện bổ sung.
- Khả năng chuyển giao: Mô hình nền tảng có thể được áp dụng cho các tác vụ mới chưa từng thấy, đồng thời thích nghi với các miền dữ liệu và tập dữ liệu mới.
- Tính linh hoạt: Mô hình nền tảng có thể được sử dụng như điểm khởi đầu cho nhiều ứng dụng, từ dịch ngôn ngữ đến tạo sinh hình ảnh.
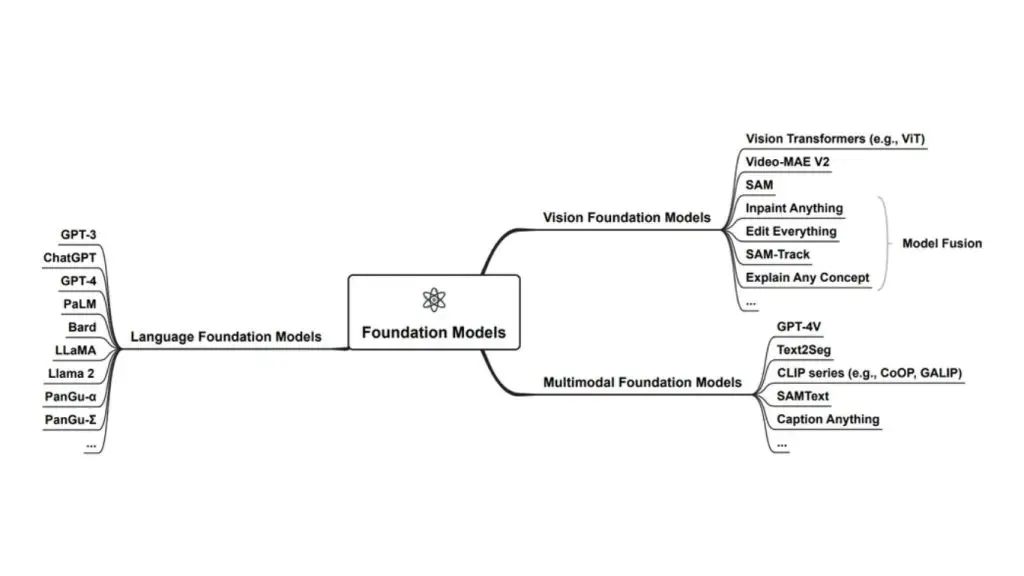
Các loại mô hình nền tảng
Mô hình nền tảng có thể được chia thành ba nhóm chính:
- Mô hình ngôn ngữ lớn (Large Language Models – LLMs)
- Mô hình ngôn ngữ thị giác (Vision Language Models – VLMs)
- Mô hình nền tảng đa phương thức (Multimodal foundation models)
Mô hình ngôn ngữ lớn (LLMs)
Mô hình ngôn ngữ lớn được huấn luyện trên các tập dữ liệu văn bản khổng lồ và chuyên sâu vào việc hiểu, tạo ra và xử lý ngôn ngữ tự nhiên của con người. Chúng có thể thực hiện các tác vụ như dịch ngôn ngữ, tóm tắt văn bản, phân tích cảm xúc, và trả lời câu hỏi.
Một ví dụ điển hình của mô hình ngôn ngữ nền tảng là GPT-3. Nền tảng này được phát triển bởi OpenAI, GPT-3 là một mô hình ngôn ngữ mạnh mẽ được huấn luyện trên lượng lớn văn bản đa dạng từ Internet. Mô hình này có khả năng tạo văn bản giống con người, trả lời câu hỏi và hỗ trợ viết mã lập trình. Các ứng dụng của GPT-3 bao gồm chatbot, sáng tạo nội dung, hỗ trợ khách hàng tự động, tạo mã nguồn,…
>> Xem thêm: Mẹo tạo prompt cho LLM trong thị giác máy tính để tăng độ chính xác
Mô hình ngôn ngữ thị giác (VLMs)
Mô hình ngôn ngữ thị giác được thiết kế để hiểu và xử lý hình ảnh, video. Chúng có thể nhận diện đối tượng, phân loại hình ảnh, phát hiện sự bất thường và thậm chí tạo ra nội dung hình ảnh.
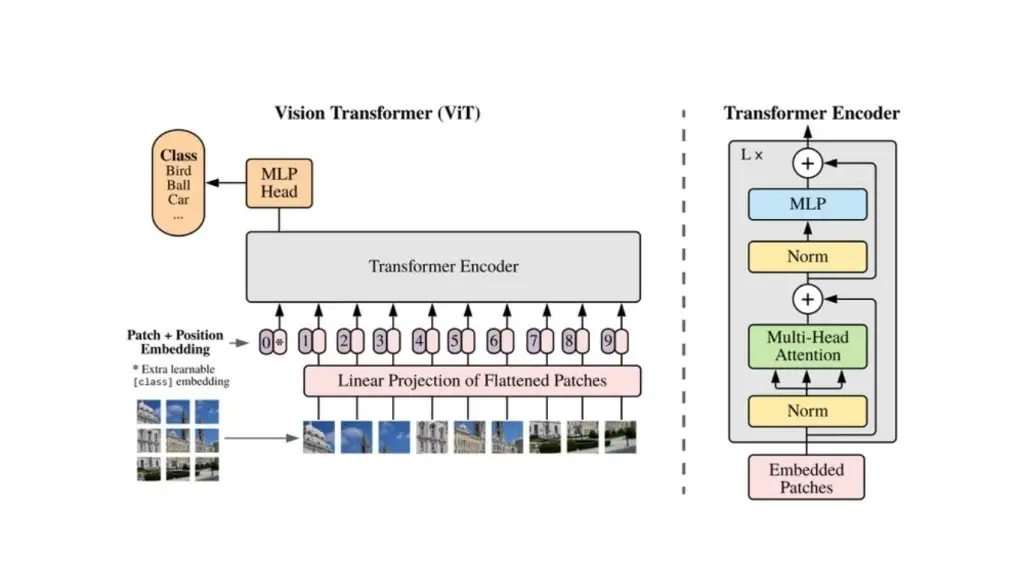
Một ví dụ về mô hình nền tảng thị giác là ViT (Vision Transformer) do Google phát triển. ViT là một mô hình dựa trên Transformer dùng cho nhận dạng hình ảnh. Không giống như các mạng nơ-ron tích chập truyền thống (CNNs), ViT coi một hình ảnh như một chuỗi các mảnh và xử lý chúng bằng cơ chế tự chú ý. Các ứng dụng của ViT bao gồm phát hiện đối tượng (Object Detection), phân tích hình ảnh y tế, nhận diện khuôn mặt, lái xe tự động,…
>> Tham khảo thêm: Phân tích hình ảnh bằng AI là gì? Cách AI hiểu và diễn giải hình ảnh
Mô hình nền tảng đa phương thức (Multimodal Foundation Models)
Các mô hình nền tảng đa phương thức có khả năng xử lý và tạo ra thông tin trên nhiều loại dữ liệu khác nhau, bao gồm văn bản, hình ảnh, âm thanh và video.
Một ví dụ về mô hình nền tảng đa phương thức là mô hình CLIP (Contrastive Language-Image Pretraining), được phát triển bởi OpenAI. CLIP học cách liên kết giữa văn bản và hình ảnh thông qua học tương phản, cho phép mô hình hiểu và trích xuất thông tin từ cả dữ liệu văn bản lẫn dữ liệu hình ảnh, qua đó trở thành một đại diện điển hình cho hệ thống AI đa phương thức.
>>> Xem thêm:
- Tạo web bán hàng bằng AI miễn phí, chuẩn SEO, hiệu quả nhất
- Cách sử dụng AI trong phát triển phần mềm như thế nào?
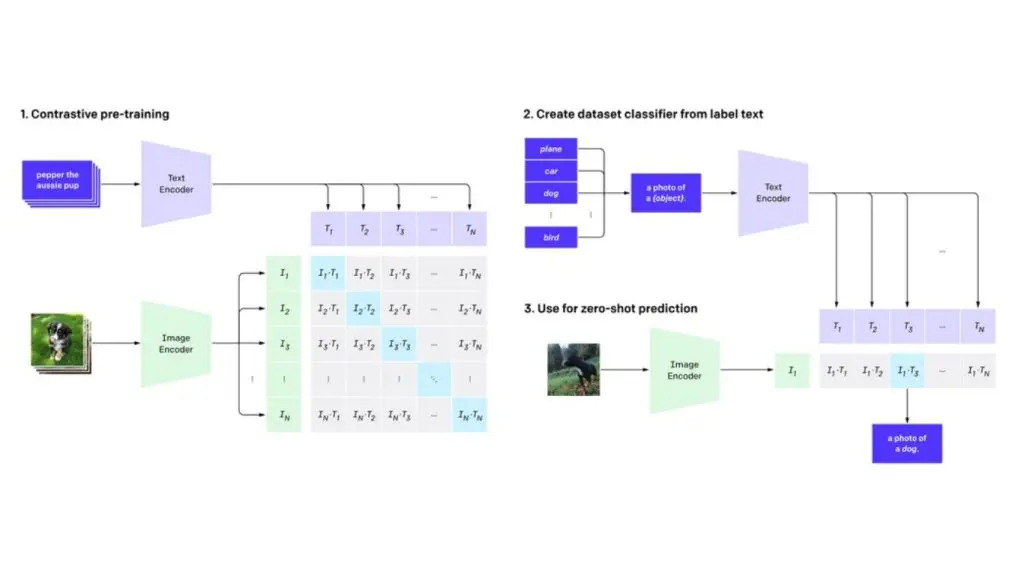
Các ví dụ về việc ứng dụng mô hình nền tảng
Tiếp theo, chúng ta sẽ xem xét một số ví dụ sử dụng các mô hình nền tảng có khả năng thị giác, nhằm khám phá những tác vụ mà chúng có thể thực hiện. Trong các ví dụ này, chúng ta sẽ sử dụng OpenAI GPT-4o, Google Gemini và Llama 3.2 Vision. Những mô hình này được xem là mô hình nền tảng vì chúng:
- Được huấn luyện trước (pretrained) trên các tập dữ liệu đa phương thức quy mô lớn, bao gồm cả hình ảnh
- Có khả năng xử lý và hiểu thông tin thị giác
- Có thể thực hiện nhiều tác vụ hạ nguồn liên quan đến thị giác
- Sử dụng kỹ thuật học tự giám sát trong quá trình tiền huấn luyện
- Có thể được tinh chỉnh cho các tác vụ hạ nguồn chuyên biệt theo từng lĩnh vực
Google Gemini
Google Gemini là một họ mô hình ngôn ngữ lớn đa phương thức (LLMs) tiên tiến do Google phát triển. Gemini có khả năng xử lý và tạo sinh thông tin trên nhiều loại dữ liệu khác nhau như văn bản, hình ảnh, âm thanh, video và mã nguồn, từ đó có thể được sử dụng để phát triển các ứng dụng linh hoạt và đa dạng.
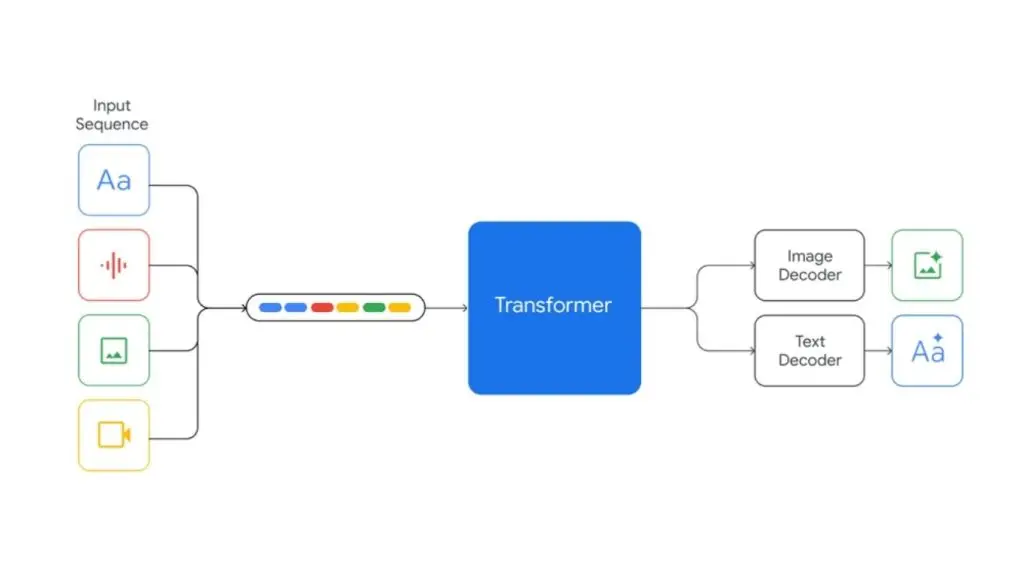
Các tính năng chính của Gemini
- Tích hợp đa phương thức: Gemini có thể xử lý và kết hợp văn bản, hình ảnh, âm thanh, video và mã nguồn trong cả đầu vào lẫn đầu ra. Mô hình này vượt trội trong các tác vụ đa phương thức, chẳng hạn như tạo chú thích hình ảnh hoặc trả lời câu hỏi về video.
- Khả năng mở rộng: Gemini có nhiều phiên bản với kích thước khác nhau, chẳng hạn như Gemini Nano cho thiết bị đầu cuối, Gemini Pro cho mục đích chung và Gemini Ultra cho các tác vụ nâng cao. Gemini được tối ưu hóa để hoạt động hiệu quả trên nhiều nền tảng, từ thiết bị di động đến hạ tầng đám mây.
- Suy luận nâng cao: Gemini có thể thực hiện giải quyết vấn đề phức tạp trong các lĩnh vực như toán học, lập trình và khoa học, đồng thời hỗ trợ suy luận logic và hiểu ngữ cảnh.
- Hỗ trợ đa ngôn ngữ: Mô hình được huấn luyện trên các bộ dữ liệu đa dạng, cho phép sử dụng thành thạo hơn 100 ngôn ngữ trong dịch thuật, tạo nội dung và phân tích dữ liệu.
- Khả năng xử lý thời gian thực: Gemini có thể xử lý dữ liệu truyền trực tiếp như video hoặc âm thanh trực tiếp, phục vụ các ứng dụng như dịch thuật theo thời gian thực hoặc trợ lý tương tác.
- Tích hợp với hệ sinh thái Google: Gemini được tích hợp vào nhiều sản phẩm của Google như Workspace, Search, Android,… và có thể truy cập thông qua các API như Vertex AI và Google AI Studio.
>> Tìm hiểu thêm: TOP 30 công cụ AI miễn phí, phổ biến, hỗ trợ học tập và làm việc hiệu quả
Ví dụ về Gemini: Phát hiện đối tượng trong hình ảnh
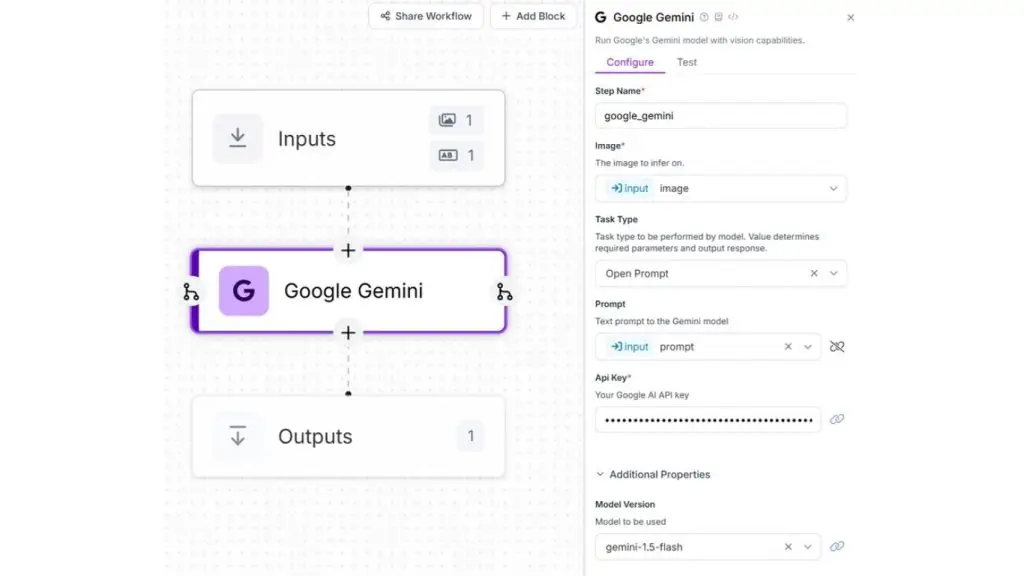
Trong ví dụ này, chúng ta sẽ phát hiện sự xuất hiện của “con chó” trong hình ảnh, xác định giống chó, và trích xuất tọa độ hộp giới hạn. Dựa trên thông tin này, chúng ta sẽ vẽ hộp giới hạn xung quanh con chó được phát hiện và hiển thị giống chó dưới dạng nhãn.
Tiếp theo, hãy tạo quy trình làm việc Roboflow với các bước cụ thể cho Gemini như hình minh họa bên dưới:
Hình ảnh đầu vào sau được sử dụng cho ví dụ này:

Bây giờ, hãy tạo một tệp Python mới và thêm đoạn mã sau:
import cv2
import numpy as np
import matplotlib.pyplot as plt
import re
import json
from PIL import Image, ImageDraw, ImageFont
from inference_sdk import InferenceHTTPClient
# Specify the image filename
image_path = "dogs.jpg"
client = InferenceHTTPClient(
api_url="https://detect.roboflow.com",
api_key="ROBOFLOW_API_KEY"
)
result = client.run_workflow(
workspace_name="tim-4ijf0",
workflow_id="custom-workflow-6",
images={
"image": image_path
},
parameters={
"prompt": "find all dogs in image and return JSON {'breed':'', 'confidence':'', 'ymin':'', 'xmin':'', 'ymax':'', 'xmax':''} "
},
use_cache=True # cache workflow definition for 15 minutes
)
# Function to extract bounding boxes from result
def extract_bboxes(result):
bbox_list = []
for item in result:
output_text = item.get('google_gemini', {}).get('output', '')
match = re.search(r'```json\n([\s\S]+?)\n```', output_text) # Extract JSON part
if match:
json_text = match.group(1).strip()
try:
bbox_list = json.loads(json_text) # Convert JSON string to Python list
except json.JSONDecodeError:
print("Error decoding JSON from result variable")
return bbox_list
# Extract bounding boxes
bounding_boxes = extract_bboxes(result)
# Load the image using PIL
image = Image.open(image_path)
width, height = image.size
draw = ImageDraw.Draw(image)
# Define a list of colors for different breeds
colors = ["red", "blue", "green", "yellow", "cyan", "magenta"]
breed_color_map = {} # Dictionary to store colors for each breed
# Font for labels
try:
font = ImageFont.truetype("NotoSansCJK-Regular.ttc", size=18)
except IOError:
font = ImageFont.load_default() # Use default font
# Draw bounding boxes
for i, obj in enumerate(bounding_boxes):
breed = obj['breed']
confidence = float(obj['confidence']) * 100 # Convert confidence to percentage
ymin, xmin, ymax, xmax = obj['ymin'], obj['xmin'], obj['ymax'], obj['xmax']
# Assign a unique color per breed
if breed not in breed_color_map:
breed_color_map[breed] = colors[len(breed_color_map) % len(colors)]
color = breed_color_map[breed]
# Convert normalized coordinates to absolute coordinates
abs_x1 = int(xmin / 1000 * width)
abs_y1 = int(ymin / 1000 * height)
abs_x2 = int(xmax / 1000 * width)
abs_y2 = int(ymax / 1000 * height)
# Draw the bounding box
draw.rectangle(((abs_x1, abs_y1), (abs_x2, abs_y2)), outline=color, width=4)
# Draw the label (breed and confidence)
label = f"{breed} ({confidence:.1f}%)"
text_size = draw.textbbox((0, 0), label, font=font)
text_width, text_height = text_size[2] - text_size[0], text_size[3] - text_size[1]
# Draw label background
draw.rectangle(
((abs_x1, abs_y1 - text_height), (abs_x1 + text_width, abs_y1)),
fill=color
)
# Draw label text
draw.text((abs_x1, abs_y1 - text_height), label, fill="white", font=font)
# Display image with bounding box
plt.figure(figsize=(10, 6))
plt.imshow(image)
plt.axis("off")
plt.show()Đoạn mã này tận dụng quy trình Roboflow để gửi một hình ảnh đầu vào cùng với một prompt tùy chỉnh tới mô hình Gemini. Mô hình sẽ trả về một phản hồi dạng JSON, trong đó mô tả giống chó được phát hiện, điểm tin cậy và tọa độ hộp giới hạn của từng con chó.
Dữ liệu này sau đó được xử lý để vẽ các hộp giới hạn, mỗi hộp có màu sắc riêng tương ứng với giống chó được phát hiện, đồng thời gắn nhãn lên hình ảnh gốc. Việc chuẩn hóa tọa độ hộp giới hạn đảm bảo rằng các hộp được vẽ chính xác trên hình ảnh. Nhìn chung, quy trình Roboflow giúp đơn giản hóa quá trình sử dụng các mô hình nền tảng. Khi chạy đoạn mã, bạn sẽ thấy kết quả đầu ra như sau:

>> Xem thêm: Xây dựng ứng dụng phát hiện đối tượng bằng Python chỉ trong vài phút với Roboflow
Ví dụ về Gemini: Phát hiện đối tượng trong Video
Trong ví dụ này, chúng ta sẽ sử dụng khả năng hiểu video của Gemini để phát hiện các đối tượng trong video. Mô hình sẽ tìm kiếm một đối tượng, xác định đối tượng đó và trả về tên của đối tượng cùng với tọa độ hộp giới hạn. Thông tin này sau đó sẽ được dùng để tạo ra một video đầu ra, trong đó đối tượng được phát hiện sẽ được hiển thị kèm nhãn và hộp giới hạn.
Sử dụng cùng một quy trình như ở trên. Chúng tôi sẽ cung cấp prompt sau đây cho Gemini:
"prompt": "Is there blue object? Return JSON for it {'ymin':'', 'xmin':'', 'ymax':'', 'xmax':'', 'objname': ''}"Chúng tôi đã sử dụng video sau đây cho ví dụ này bằng cách cắt ngắn nó.
Tạo một tệp Python mới và thêm mã sau:
import cv2
import json
import re
import numpy as np
from inference import InferencePipeline
from inference.core.interfaces.camera.entities import VideoFrame
# Initialize video writer
input_video = "robot.mp4"
output_video = "output_with_bboxes.mp4"
cap = cv2.VideoCapture(input_video)
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
fps = int(cap.get(cv2.CAP_PROP_FPS))
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_video, fourcc, fps, (frame_width, frame_height))
def extract_bboxes(result):
"""Extract bounding boxes from the inference result."""
bbox_list = []
output_text = result.get('google_gemini', {}).get('output', '')
match = re.search(r'```json\n([\s\S]+?)\n```', output_text)
if match:
json_text = match.group(1).strip()
try:
bbox_list = [json.loads(json_text)] if isinstance(json.loads(json_text), dict) else json.loads(json_text)
except json.JSONDecodeError:
print("Error decoding JSON from result variable")
return bbox_list
def draw_bboxes(frame, bounding_boxes):
"""Draw bounding boxes on the frame."""
for obj in bounding_boxes:
objname = obj['objname']
ymin, xmin, ymax, xmax = obj['ymin'], obj['xmin'], obj['ymax'], obj['xmax']
abs_x1 = int((xmin / 1000) * frame.shape[1])
abs_y1 = int((ymin / 1000) * frame.shape[0])
abs_x2 = int((xmax / 1000) * frame.shape[1])
abs_y2 = int((ymax / 1000) * frame.shape[0])
label = f"{objname}"
cv2.rectangle(frame, (abs_x1, abs_y1), (abs_x2, abs_y2), (0, 255, 0), 2)
print(f"Bounding Box - xmin: {abs_x1}, ymin: {abs_y1}, xmax: {abs_x2}, ymax: {abs_y2}")
cv2.putText(frame, label, (abs_x1, abs_y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return frame
def process_frame(result, video_frame):
"""Process each frame and draw bounding boxes."""
frame = video_frame.image
bounding_boxes = extract_bboxes(result)
frame_with_boxes = draw_bboxes(frame, bounding_boxes)
# Write frame to output video
out.write(frame_with_boxes)
cv2.imshow("Output", frame_with_boxes)
cv2.waitKey(1)
# Print progress
print("Processed frame with bounding boxes.")
# Initialize and start the pipeline
pipeline = InferencePipeline.init_with_workflow(
api_key="ROBOFLOW_API_KEY",
workspace_name="tim-4ijf0",
workflow_id="custom-workflow-6",
video_reference=input_video,
max_fps=30,
on_prediction=process_frame,
workflows_parameters={"prompt": "Is there blue object? Return JSON for it {'ymin':'', 'xmin':'', 'ymax':'', 'xmax':'', 'objname': ''}"}
)
pipeline.start()
pipeline.join()
cap.release()
out.release()
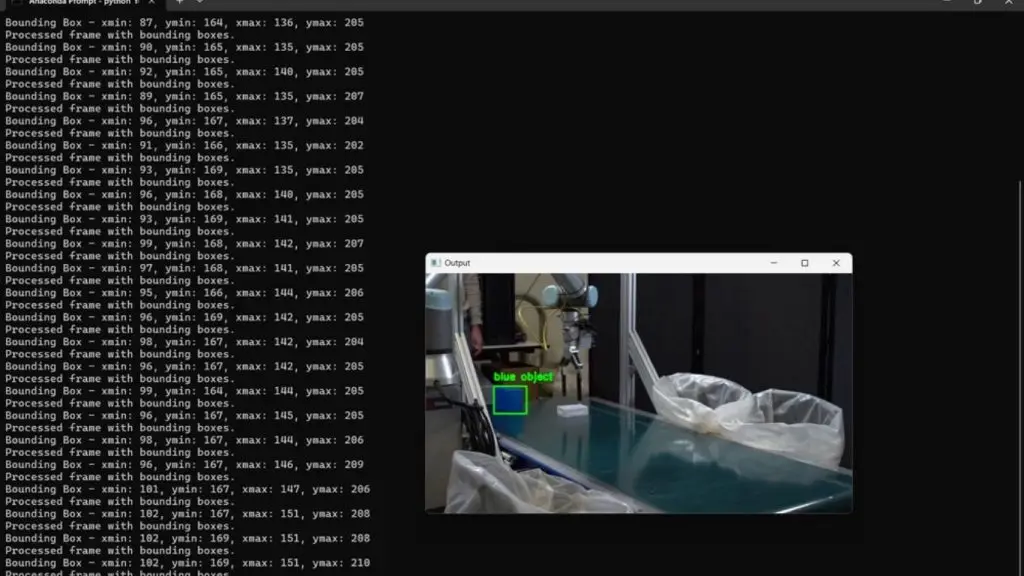
cv2.destroyAllWindows()Đoạn mã này xử lý một video để phát hiện một đối tượng được chỉ định xuyên suốt các khung hình của video, bằng cách sử dụng Roboflow được tích hợp với mô hình Gemini.
Video đầu vào cùng với một prompt xác định đối tượng cần tìm kiếm sẽ được truyền vào quy trình làm việc. Mô hình Gemini phân tích từng khung hình và trả về một phản hồi dạng JSON, trong đó chứa tên của đối tượng và tọa độ hộp giới hạn mỗi khi đối tượng được phát hiện. Các hộp giới hạn này sau đó được vẽ lên các khung hình, kèm theo tên của đối tượng và các khung hình đã xử lý được lưu thành một video đầu ra.
Tọa độ hộp giới hạn được chuẩn hóa và chuyển đổi sang giá trị tuyệt đối để đảm bảo vị trí hiển thị chính xác trong từng khung hình. Toàn bộ pipeline thực hiện suy luận theo từng khung hình vừa hiển thị các khung hình đã xử lý theo thời gian thực, vừa ghi chúng vào video đầu ra cuối cùng. Quy trình tự động này cho phép phát hiện đối tượng một cách hiệu quả trên toàn bộ video.
Khi chạy đoạn mã, bạn sẽ thấy kết quả đầu ra như sau:
>> Tìm hiểu thêm: Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
GPT-4o
GPT-4o (trong đó chữ “o” là viết tắt của “omni”) là mô hình ngôn ngữ lớn đa phương thức thế hệ tiếp theo của OpenAI, được phát hành vào tháng 5 năm 2024. GPT-4o được xây dựng dựa trên các tính năng của GPT-4, bằng cách tích hợp đầu vào và đầu ra của văn bản, hình ảnh và âm thanh vào một mô hình thống nhất duy nhất.
GPT-4o là một mô hình omni tự hồi quy, có khả năng xử lý mọi tổ hợp đầu vào gồm văn bản, âm thanh, hình ảnh và video, đồng thời tạo ra mọi tổ hợp đầu ra gồm văn bản, âm thanh và hình ảnh.
Mô hình GPT-4o được huấn luyện toàn diện từ đầu đến cuối trên nhiều phương thức dữ liệu, nghĩa là cùng một mạng nơ-ron nhân tạo (neural network) đảm nhiệm toàn bộ quá trình xử lý đầu vào và đầu ra cho văn bản, thị giác và âm thanh một cách liền mạch.
Các tính năng chính của GPT-4o
- Đầu vào / đầu ra đa phương thức: GPT-4o xử lý văn bản, hình ảnh, âm thanh và video trong một kiến trúc mô hình duy nhất. Mô hình có thể tạo đầu ra ở nhiều phương thức khác nhau như trả lời một câu hỏi văn bản bằng hình ảnh hoặc giọng nói.
- Các biến thể: GPT-4o là phiên bản đa phương thức toàn diện được tối ưu cho hiệu suất cao trên các tác vụ văn bản, hình ảnh và âm thanh, với cửa sổ ngữ cảnh rất lớn (lên đến 128.000 token) cùng năng lực xử lý mở rộng.
Bên cạnh GPT-4o, GPT-4o-mini là phiên bản nhỏ hơn và tiết kiệm chi phí hơn, được thiết kế để giảm độ trễ và giảm tài nguyên tính toán, trong khi vẫn cung cấp nhiều tính năng đa phương thức cốt lõi. - Tương tác thời gian thực: GPT-4o hỗ trợ các ứng dụng hội thoại thời gian thực với độ trễ thấp, chẳng hạn như trợ lý giọng nói phản hồi tức thì.
- Khả năng suy luận được cải thiện: So với GPT-4, GPT-4o có khả năng giải quyết vấn đề tốt hơn trong các lĩnh vực toán học, lập trình và logic. Mô hình cũng hiểu ngữ cảnh tốt hơn và tạo nội dung dài mạch lạc hơn.
- Năng lực đa ngôn ngữ: GPT-4o hỗ trợ hơn 50 ngôn ngữ cho các tác vụ dịch thuật, tạo nội dung và phân tích.
- An toàn và sự phù hợp: GPT-4o được tích hợp các cơ chế bảo vệ nhằm giảm thiểu nội dung gây hại và thiên lệch, đồng thời tuân thủ các nguyên tắc đạo đức chặt chẽ hơn so với các mô hình trước đó.
Ví dụ về GPT-4o: Hệ thống phát hiện đối tượng và cảnh báo
Trong ví dụ này, chúng ta sẽ tiến hành phát hiện một đối tượng cụ thể bằng cách nhận diện chiếc cốc màu đen trong luồng camera trực tiếp, đồng thời kích hoạt cảnh báo khi đối tượng không được phát hiện. Cách tiếp cận này có thể ứng dụng trong việc xây dựng các hệ thống giám sát hoặc cảnh báo cháy, bởi GPT-4o có khả năng vượt trội trong việc hiểu ngữ cảnh, phân tích cảnh vật trong hình ảnh hoặc video và mô tả chính xác các sự kiện đang diễn ra theo thời gian thực.
Tạo một luồng làm việc Roboflow cho ví dụ này và cấu hình kết nối với khối OpenAI như minh họa trong hình dưới đây.
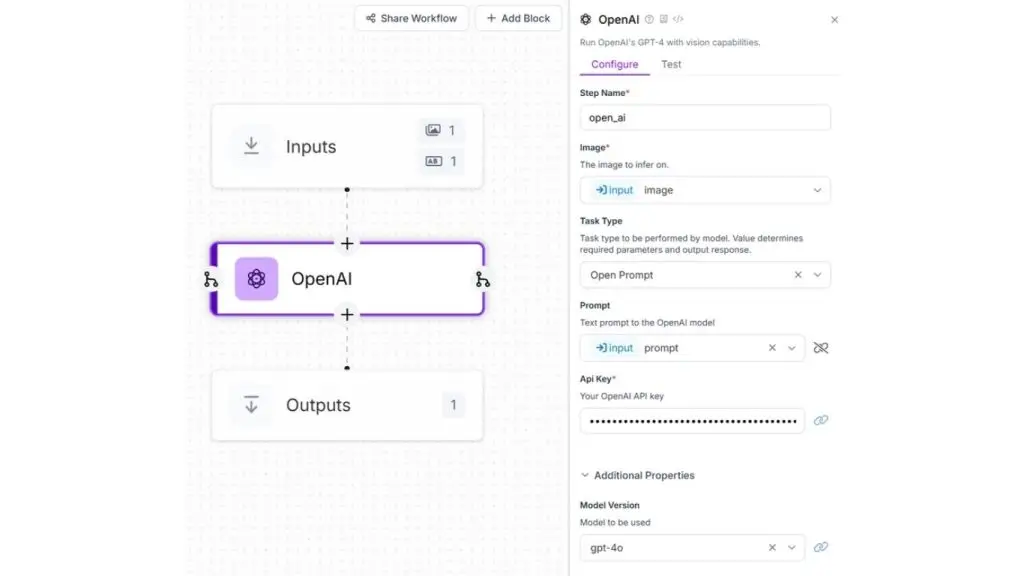
Chúng tôi sẽ cung cấp prompt sau đây cho mô hình GPT-4o:
"prompt": "Do you see black cup? Yes or No."Tạo một tệp Python mới và thêm mã sau:
import cv2
from inference import InferencePipeline
from inference.core.interfaces.camera.entities import VideoFrame
# Define a custom sink function to process and display predictions
def my_sink(predictions: dict, video_frame: VideoFrame):
# Extract the 'output' text from the 'open_ai' key in predictions
response_text = predictions.get('open_ai', {}).get('output', '')
# Determine the alert message based on the presence of "Yes" in the response
if 'Yes' in response_text:
alert_message = "Black Cup Detected"
color = (0, 255, 0) # Green for detection
else:
alert_message = "Black Cup Not Detected"
color = (0, 0, 255) # Red for no detection
# Define text properties
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1.0
thickness = 2
position = (50, 50) # Position to display the alert message
# Overlay the alert message on the video frame
cv2.putText(video_frame.image, alert_message, position, font, font_scale, color, thickness, cv2.LINE_AA)
# Display the video frame with the overlaid alert message
cv2.imshow("Live Webcam Feed with Alerts", video_frame.image)
# Exit the display window when 'q' key is pressed
if cv2.waitKey(1) & 0xFF == ord('q'):
pipeline.stop()
cv2.destroyAllWindows()
# initialize a pipeline object
pipeline = InferencePipeline.init_with_workflow(
api_key="ROBOFLOW_API_KEY",
workspace_name="tim-4ijf0",
workflow_id="custom-workflow-7",
video_reference=0, # Path to video, device id (int, usually 0 for built in webcams), or RTSP stream url
max_fps=30,
on_prediction=my_sink,
workflows_parameters={
"prompt": "Do you see black cup? Yes or No."
}
)
pipeline.start() #start the pipeline
pipeline.join() #wait for the pipeline thread to finishĐoạn mã này sử dụng mô hình GPT-4o thông qua quy trình Roboflow để diễn giải luồng video trực tiếp từ webcam và hiển thị kết quả theo thời gian thực.
Quy trình được khởi tạo với một prompt nhằm hỏi liệu một chiếc cốc màu đen có xuất hiện trong luồng video hay không. Mô hình liên tục phân tích các khung hình đầu vào và trả về phản hồi cho biết sự hiện diện hoặc không hiện diện của đối tượng. Dựa trên đầu ra của mô hình, một thông báo cảnh báo sẽ được chèn lên luồng video, có thể là “Black Cup Detected” (hiển thị bằng màu xanh lá) hoặc “Black Cup Not Detected” (hiển thị bằng màu đỏ). Các khung hình đã xử lý được hiển thị trong một cửa sổ trực tiếp, liên tục tự động cập nhật.
Cấu hình này cho phép diễn giải ngữ cảnh theo thời gian thực, hiểu nội dung và đưa ra quyết định bằng GPT-4o, khiến nó đặc biệt hữu ích cho các ứng dụng như giám sát tự động, theo dõi an ninh và kiểm tra trực quan.
Bạn sẽ thấy kết quả đầu ra tương tự như sau. Trong hình ảnh, mô hình GPT-4o phát hiện chiếc cốc (ở bên trái) khi nó xuất hiện trong khung hình video, nhưng không phát hiện khi một đối tượng khác xuất hiện.

Llama 3.2 Vision
Llama 3.2 Vision là một mô hình ngôn ngữ lớn mã nguồn mở (LLM) do Meta phát triển, thuộc phiên bản cập nhật mới nhất của dòng Llama. Đây là phiên bản mở rộng từ Llama 3.1 – vốn chỉ xử lý dữ liệu văn bản.
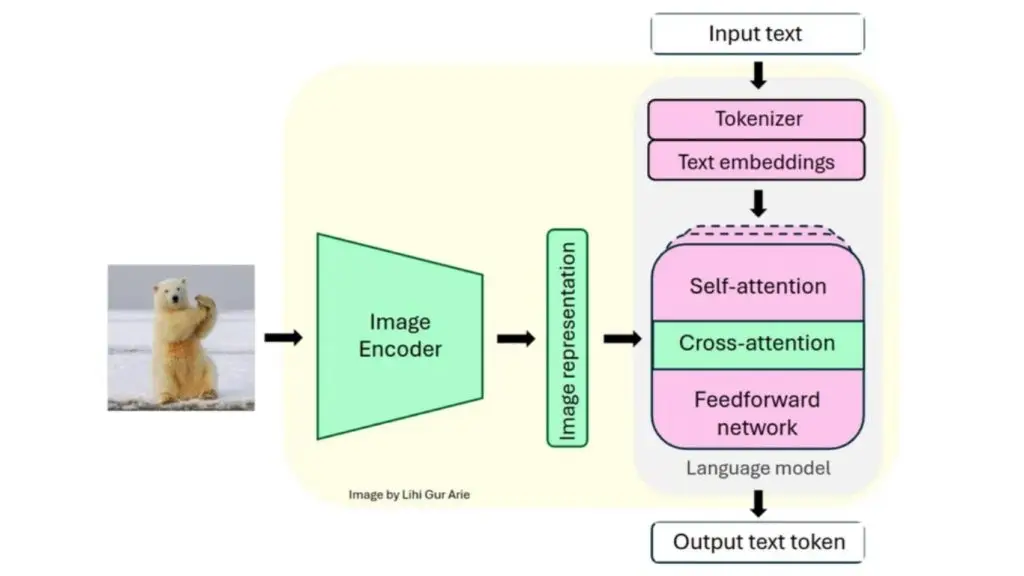
Llama 3.1 được xây dựng trên kiến trúc Transformer tối ưu, hoạt động theo cơ chế tự hồi quy và được thiết kế để xử lý văn bản với hiệu năng cao. Kế thừa nền tảng này, Llama 3.2 Vision bổ sung thêm khả năng “nhìn”, cho phép mô hình không chỉ hiểu và tạo văn bản mà còn phân tích hình ảnh và kết hợp hai loại dữ liệu này một cách liền mạch.
Nhờ đó, Llama 3.2 Vision trở thành một mô hình đa phương thức, có khả năng xử lý đồng thời văn bản và hình ảnh trong cùng một hệ thống.
Các tính năng chính của Llama 3.2 Vision
- Khả năng đa phương thức: Llama 3.2 Vision có thể nhận cả văn bản và hình ảnh làm đầu vào, đồng thời tạo ra đầu ra dựa trên văn bản. Điều này cho phép mô hình hiểu và suy luận về nội dung trực quan, chẳng hạn như mô tả hình ảnh, trả lời câu hỏi liên quan đến hình ảnh, hoặc diễn giải dữ liệu trực quan phức tạp như biểu đồ và đồ thị.
- Kích thước mô hình: Mô hình hiện có hai phiên bản
- 11B: Phiên bản nhỏ hơn, hiệu quả và tiết kiệm tài nguyên, phù hợp với các tác vụ yêu cầu mức tài nguyên tính toán vừa phải.
- 90B: Phiên bản lớn hơn, mạnh mẽ hơn, vượt trội trong suy luận phức tạp và hiểu hình ảnh chi tiết, lý tưởng cho các ứng dụng cấp doanh nghiệp.
- Hiệu năng cao: Llama 3.2 Vision đạt độ chính xác cao trong các tác vụ nhận dạng hình ảnh và hiểu nội dung trực quan. Mô hình thể hiện hiệu suất tốt trên các bộ đo chuẩn của ngành cho các bài toán nhận dạng thị giác, tạo chú thích hình ảnh và suy luận.
- Khả năng đa ngôn ngữ: Llama 3.2 Vision chính thức hỗ trợ các ngôn ngữ như tiếng Anh, tiếng Đức, tiếng Pháp, tiếng Ý, tiếng Bồ Đào Nha, tiếng Hindi, tiếng Tây Ban Nha và tiếng Thái cho các tác vụ chỉ liên quan đến văn bản.
Ví dụ về Llama 3.2 Vision: Ứng dụng dịch ngôn ngữ từ hình ảnh
Trong ví dụ này, chúng ta sẽ xây dựng một ứng dụng giao diện đồ họa (GUI) sử dụng Gradio để phát hiện văn bản trong hình ảnh bằng mô hình Llama 3.2 Vision. Ứng dụng sẽ xác định ngôn ngữ và nội dung của văn bản được trích xuất, cho phép người dùng dịch sang ngôn ngữ mong muốn.
Trong ví dụ này, các ngôn ngữ được sử dụng bao gồm:
[“English”, “Spanish”, “French”, “German”, “Chinese”, “Hindi”]
Ứng dụng này hữu ích trong nhiều tình huống khác nhau, bao gồm:
- Giúp người dùng trích xuất và dịch văn bản từ hình ảnh, đặc biệt hữu ích cho khách du lịch
- Hỗ trợ quét tài liệu in, hóa đơn hoặc ghi chú viết tay, sau đó chuyển đổi thành văn bản có thể chỉnh sửa và dịch
- Giúp trích xuất thông tin sản phẩm từ bao bì hoặc nhãn mác và dịch phục vụ thị trường quốc tế
- Hỗ trợ người khiếm thị bằng cách phát hiện và đọc to văn bản từ hình ảnh bằng ngôn ngữ mà họ lựa chọn
Để xây dựng ứng dụng, hãy tạo một quy trình với cấu hình tương ứng cho khối Llama 3.2 Vision như hình sau:
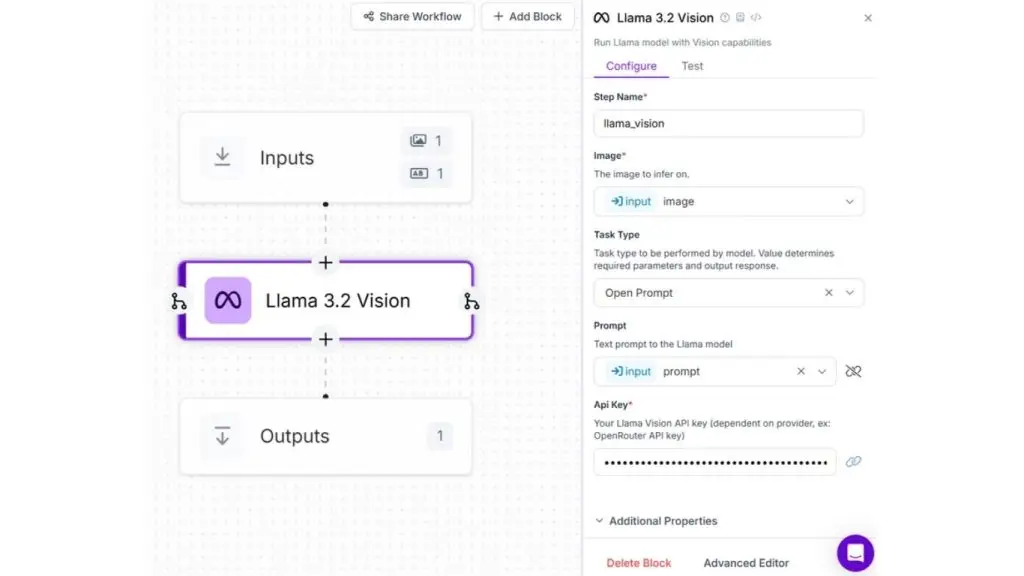
Chúng tôi sẽ cung cấp prompt sau đây cho mô hình Llama 3.2 Vision:
prompt = f"detect language and translate it to {target_language} in JSON format {{ 'detected_language' : '', 'detected_text':'', 'translated_language' : '', 'translated_text':''}}"Tạo một tệp Python mới và thêm mã sau:
import gradio as gr
from inference_sdk import InferenceHTTPClient
import json
# Initialize Roboflow client
client = InferenceHTTPClient(
api_url="https://detect.roboflow.com",
api_key="ROBOFLOW-API_KEY" # Add your Roboflow API key here
)
def translate_image(image, target_language):
prompt = f"detect language and translate it to {target_language} in JSON format {{ 'detected_language' : '', 'detected_text':'', 'translated_language' : '', 'translated_text':''}}"
result = client.run_workflow(
workspace_name="tim-4ijf0",
workflow_id="custom-workflow-8",
images={"image": image},
parameters={"prompt": prompt},
use_cache=True
)
# Extract and parse JSON output from the response
raw_output = result[0]['llama_vision']['output']
translation_data = json.loads(raw_output.replace("'", '"'))
detected_language = translation_data.get("detected_language", "")
detected_text = translation_data.get("detected_text", "")
translated_text = translation_data.get("translated_text", "")
return detected_language, detected_text, translated_text
languages = ["English", "Spanish", "French", "German", "Chinese", "Hindi"]
# Gradio Interface
iface = gr.Interface(
fn=translate_image,
inputs=[
gr.Image(sources=["webcam", "upload"], type="filepath"),
gr.Dropdown(choices=languages, label="Target Translation Language")
],
outputs=[
gr.Textbox(label="Detected Language"),
gr.Textbox(label="Detected Text"),
gr.Textbox(label="Translated Text")
],
title="Image Language Translator",
description="Capture or upload an image, select the target translation language, and get the detected language, detected text, and its translation."
)
iface.launch()Đoạn mã này tạo ra một ứng dụng dịch ngôn ngữ dựa trên hình ảnh bằng cách sử dụng Gradio và quy trình Roboflow được hỗ trợ bởi mô hình Llama 3.2 Vision.
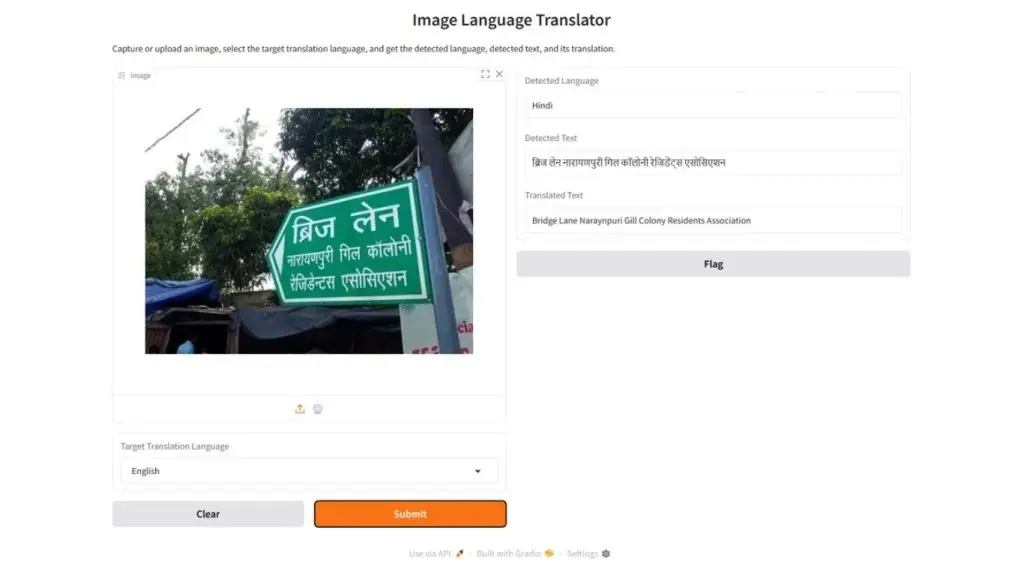
Người dùng có thể tải lên hoặc chụp một hình ảnh có chứa văn bản và chọn ngôn ngữ đích để dịch. Hình ảnh được gửi tới API Roboflow kèm theo một prompt hướng dẫn mô hình phát hiện ngôn ngữ, trích xuất văn bản, và dịch văn bản sang ngôn ngữ đích đã chọn, sau đó trả về kết quả dưới dạng JSON.
Dữ liệu JSON được trích xuất sẽ được phân tích để lấy ra ngôn ngữ được phát hiện, văn bản gốc, và văn bản đã được dịch, rồi hiển thị trong giao diện Gradio. Ứng dụng cho phép phát hiện và dịch ngôn ngữ theo thời gian thực từ hình ảnh, khiến nó trở nên hữu ích cho các tác vụ như dịch tài liệu và nhận dạng văn bản đa ngôn ngữ.
Sau đây là kết quả đầu ra:
Kết luận
Mô hình nền tảng cho phép thực hiện nhiều loại tác vụ khác nhau trên dữ liệu văn bản, hình ảnh, video và các dạng dữ liệu đa phương thức. Nhờ khả năng học từ những tập dữ liệu khổng lồ và thích nghi linh hoạt với nhiều lĩnh vực ứng dụng, các mô hình này mang lại hiệu quả cao khi triển khai trong các bài toán thực tế.
Thông qua bài viết này, bạn đã có cái nhìn tổng quan để hiểu rõ hơn foundation model là gì, cũng như cách các mô hình tiêu biểu như GPT-4o, Google Gemini và Llama 3.2 Vision được ứng dụng trong các tác vụ như phát hiện đối tượng, tìm kiếm trong video, giám sát thời gian thực hay dịch ngôn ngữ.
Nếu bạn muốn tìm hiểu sâu hơn và trực tiếp trải nghiệm các mô hình nền tảng, hãy khám phá thư mục mô hình của Roboflow. Tại đây, bạn sẽ tìm thấy hơn 100 mô hình thị giác máy tính, trong đó có hơn một tá mô hình nền tảng. Ngoài ra, bạn cũng có thể thử nghiệm Roboflow Workflows với các khối mô hình đa phương thức như GPT, Gemini hay Florence-2 để khám phá những ứng dụng mà bạn có thể xây dựng.
>>> Nguồn tham khảo: What is a Foundation Model? An Introduction
>>> Tham khảo thêm:
- Phát hiện chuyển động bằng thị giác máy tính – Cách hoạt động và logic phát hiện
- Các công cụ thị giác máy tính không cần code hàng đầu năm 2026
- Tìm hiểu về các phiên bản và quá trình phát triển của mô hình YOLO
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ:31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam







