Đếm vật thể là một năng lực của con người mà chúng ta thường mặc định là hiển nhiên. Nhìn qua thì có vẻ đơn giản, nhưng thực tế có rất nhiều quá trình nhận thức và xử lý diễn ra phía sau để chúng ta có thể “nhìn và đếm”. Điểm quan trọng là: khi đếm đúng và nhanh, ta thu được thông tin có giá trị vận hành và ra quyết định.
Hãy hình dung một người nông dân đi qua ruộng của mình, dừng lại dưới một gốc cây và tự hỏi: “Trên cây này có bao nhiêu quả táo?”. Câu hỏi tưởng như rất đời thường, nhưng lại hàm chứa giá trị kinh tế rõ rệt. Biết được số lượng giúp người nông dân ước tính sản lượng, tổ chức thu hoạch và lập kế hoạch phân phối. Tuy nhiên, nếu phải làm ở quy mô lớn, việc đếm thủ công gần như không khả thi. Đó chính là sức mạnh của đếm đối tượng bằng thị giác máy tính: huấn luyện máy móc “nhìn” và “đếm” nhanh, nhất quán và chính xác.
>>> Xem thêm các bài viết khác:
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
- Cách ứng dụng AI tối ưu trải nghiệm khách hàng

Tổng quan về đếm đối tượng bằng thị giác máy tính
Trong bài viết này, chúng ta sẽ đi từ khái niệm nền tảng đến các ứng dụng thực tế của đếm đối tượng bằng thị giác máy tính. Cụ thể, bạn sẽ tìm hiểu:
- Đếm đối tượng là gì và vì sao quan trọng.
- Sự khác biệt giữa đếm trong ảnh và đếm trong video.
- Những thách thức mà hệ thống máy gặp phải (ví dụ: che khuất, chồng lấn, đếm trùng).
- Ứng dụng theo ngành: sản xuất, y tế, nông nghiệp, kho vận.
- Cách dùng các công cụ như Roboflow để đơn giản hóa quy trình từ tạo dữ liệu đến triển khai mô hình.
- Vì sao RF-DETR (một mô hình dựa trên transformer) đặc biệt mạnh cho bài toán đếm trong điều kiện khó.
- Cách xây dựng ứng dụng đếm đối tượng cho:
- Đếm đối tượng trên ảnh
- Đếm đối tượng trên video
- Đếm theo vùng trong video
- Đếm đối tượng theo luồng camera trực tiếp
Đếm đối tượng là gì?
Đếm đối tượng trong thị giác máy tính là bài toán trong đó hệ thống tự động nhận diện và đếm số lượng các đối tượng cụ thể xuất hiện trong hình ảnh hoặc các khung hình video. Mục tiêu cốt lõi là phát hiện và thống kê bao nhiêu đối tượng quan tâm (ví dụ: con người, phương tiện, sản phẩm) xuất hiện trong một khung cảnh của hình ảnh hoặc video.
Cách tiếp cận này được áp dụng trong nhiều bối cảnh khác nhau:
- Với hình ảnh, hệ thống đếm tất cả các đối tượng nhìn thấy trong cùng một thời điểm.
- Với video, hệ thống theo dõi và đếm các đối tượng khi chúng di chuyển xuyên suốt khung cảnh, chẳng hạn như người đi qua cửa ra vào hoặc xe cộ đi qua trạm kiểm soát.
Trong phần tiếp theo của bài viết, chúng ta sẽ lần lượt tìm hiểu cả hai phương pháp đếm đối tượng trên hình ảnh và trên video.
Các khái niệm cốt lõi trong đếm đối tượng
Về bản chất, đếm đối tượng xoay quanh một câu hỏi nền tảng: “Có bao nhiêu đối tượng thuộc một loại cụ thể đang hiện diện trong ảnh hoặc video?”. Với con người, đây là kỹ năng tự nhiên. Với thị giác máy tính, mục tiêu là huấn luyện hệ thống tái hiện năng lực này theo cách tự động và đáng tin cậy.
Một pipeline đếm đối tượng thường có ba bước chính:
- Xác định “đếm cái gì”: hệ thống phải được định nghĩa rõ “đối tượng quan tâm” là gì. Đó có thể là người, xe, động vật, công cụ, hoặc linh kiện sản xuất.
- Định vị từng cá thể: khi loại đối tượng đã rõ, hệ thống cần nhận diện mọi lần xuất hiện của đối tượng trong cảnh. Mỗi lần phát hiện được xem là một cá thể riêng.
- Duy trì bộ đếm chính xác: mỗi cá thể hợp lệ làm tăng bộ đếm. Kết quả cuối cùng là một con số đại diện cho tổng số đối tượng.
Cách đếm đối tượng trong ảnh
Đếm đối tượng trong thị giác máy tính xoay quanh một câu hỏi cốt lõi:
“Có bao nhiêu đối tượng thuộc một loại cụ thể xuất hiện trong hình ảnh hoặc video?”
Đối với con người, đây là một khả năng rất tự nhiên. Trong thị giác máy tính, mục tiêu là huấn luyện máy móc tái tạo khả năng này của con người theo cách tự động và đáng tin cậy.
Bản chất của bài toán đếm đối tượng gồm ba bước chính:
- Xác định đối tượng cần đếm: Trước tiên, hệ thống phải định nghĩa rõ đâu là đối tượng quan tâm. Đó có thể là bất kỳ thứ gì, từ con người, xe cộ, động vật cho đến công cụ hoặc các linh kiện sản xuất.
- Xác định vị trí từng cá thể: Khi loại đối tượng đã được xác định, hệ thống cần phát hiện từng cá thể riêng lẻ của đối tượng đó trong khung cảnh. Mỗi đối tượng được phát hiện được xem là một thực thể độc lập.
- Duy trì số lượng chính xác: Với mỗi cá thể được tìm thấy, hệ thống sẽ tăng bộ đếm tương ứng. Kết quả cuối cùng là một con số đại diện cho tổng số đối tượng thuộc loại đó xuất hiện trong hình ảnh hoặc.
>>> Xem thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Các mô hình phát hiện đối tượng tốt nhất
- Ứng dụng AI trong bán hàng online: TOP 10 công cụ AI & cách triển khai hiệu quả
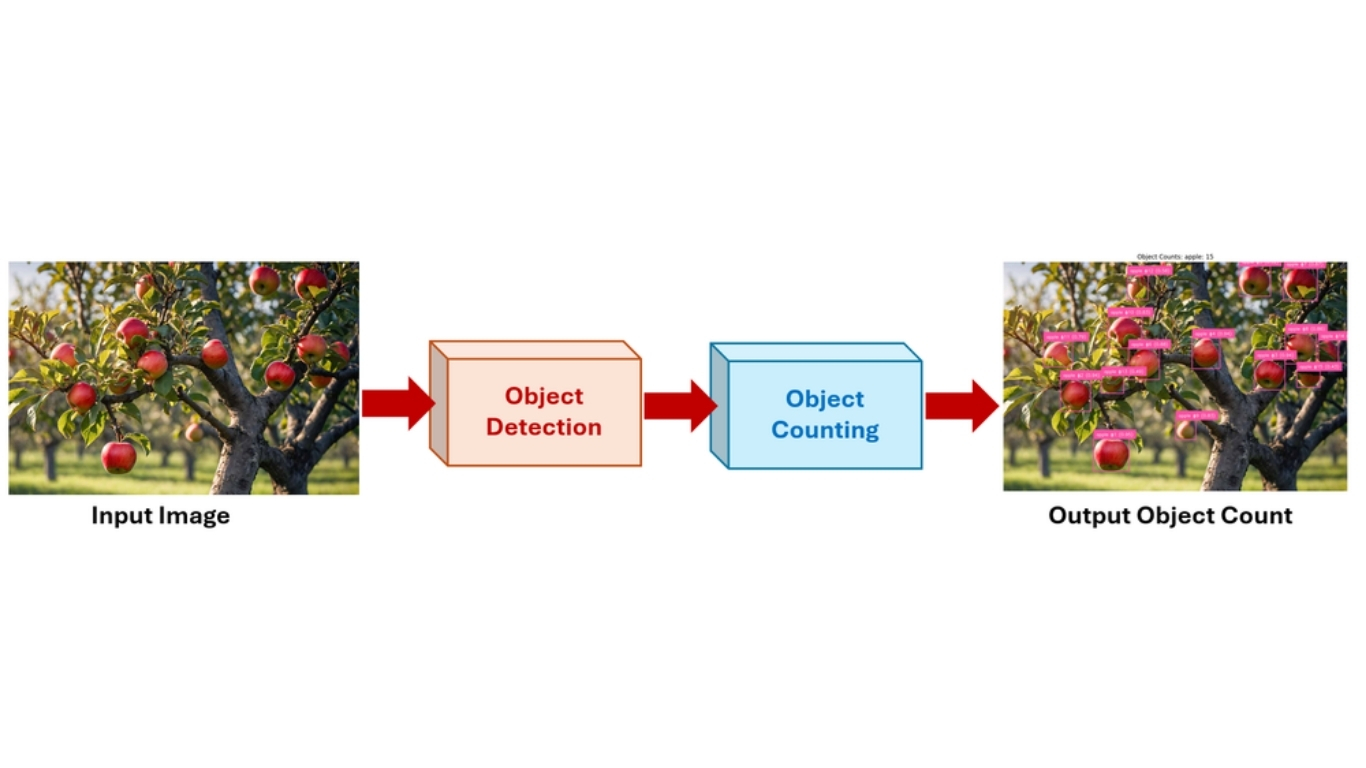
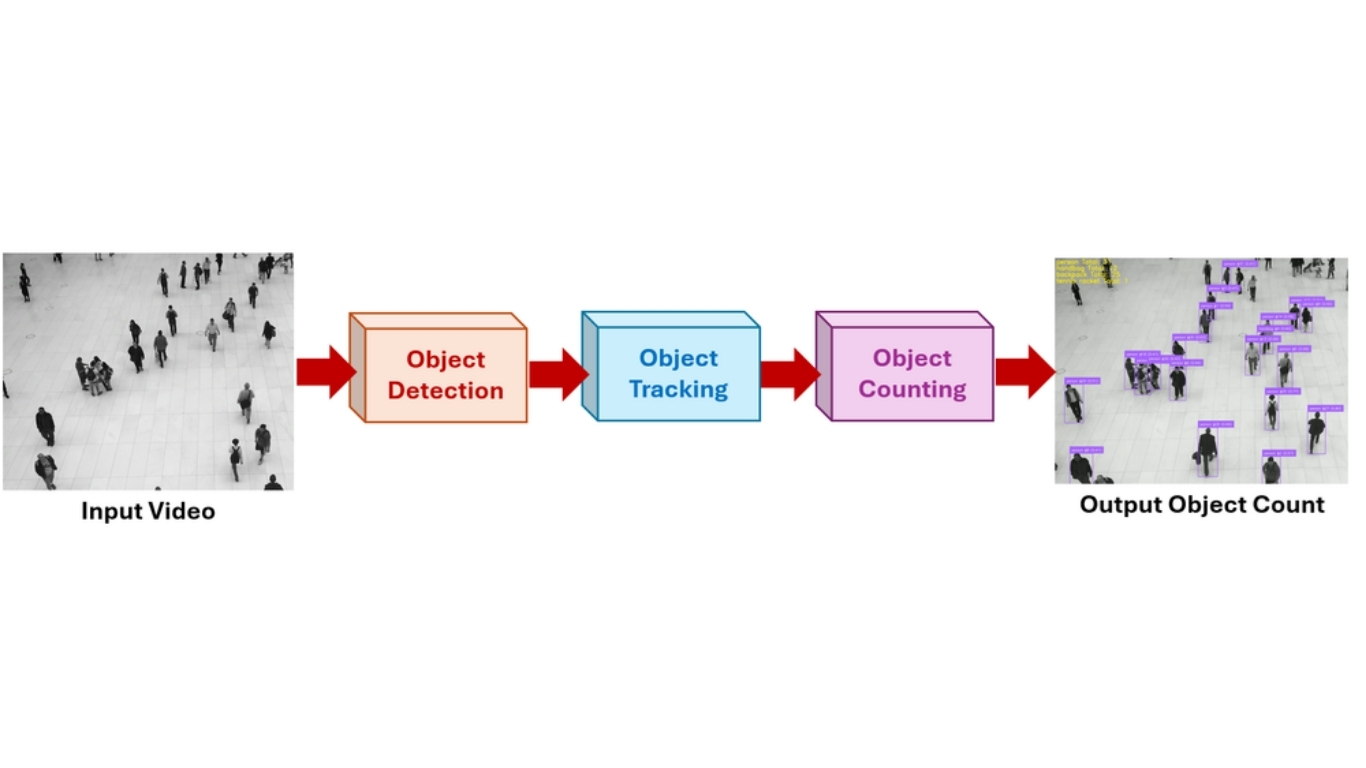
Cách đếm đối tượng trong video
Đếm trong video không chỉ là phát hiện đối tượng theo từng frame, mà còn phải theo dõi đối tượng theo thời gian để tránh đếm trùng. Quy trình điển hình gồm:
- Phát hiện: mô hình phát hiện đối tượng được chạy trên từng khung hình, tạo bounding box, vị trí và nhãn lớp cho mỗi đối tượng trong frame hiện tại.
- Theo dõi: sau khi phát hiện, thuật toán tracking (SORT, DeepSORT, ByteTrack, …) gán một ID duy nhất cho mỗi đối tượng và theo dõi qua các frame tiếp theo. Nhờ đó, cùng một đối tượng được nhận diện nhất quán khi nó di chuyển.
- Đếm: hệ thống duy trì một registry các object IDs và chỉ đếm mỗi đối tượng một lần. Việc “kích hoạt đếm” có thể dựa trên:
- Đối tượng cắt qua một đường hoặc đi vào vùng được định nghĩa (line-crossing/zone logic)
- Một object ID mới xuất hiện trong cảnh
- Đối tượng hoàn tất một quỹ đạo hoặc rời khỏi khung hình
Cách tiếp cận này giúp đếm chính xác theo thời gian thực bằng cách loại bỏ đếm lặp của cùng một đối tượng và đảm bảo tính nhất quán theo thời gian.
>>> Xem thêm:
- TOP 20 công cụ Chat AI tiếng Việt miễn phí thông minh phổ biến
- TOP 25 công cụ AI miễn phí, phổ biến, tốt nhất hiện nay
Những thách thức của đếm đối tượng
Mặc dù khái niệm đếm đối tượng nghe có vẻ đơn giản, nhưng trên thực tế tồn tại nhiều thách thức khiến đây không phải là một bài toán dễ đối với máy móc. Cụ thể bao gồm:
- Phân biệt các đối tượng tương tự nhau: Các đối tượng cùng loại có thể đứng rất gần nhau, chồng chéo lên nhau hoặc có hình dạng gần như giống hệt. Hệ thống cần nhận diện và tách biệt chính xác từng đối tượng riêng lẻ.
- Tránh đếm trùng lặp: Đặc biệt trong các luồng video, hệ thống phải đảm bảo rằng các đối tượng di chuyển không bị đếm lặp lại nhiều lần.
- Xử lý che khuất và nhiễu cảnh: Một phần của đối tượng có thể bị che khuất bởi đối tượng khác hoặc nằm ngoài khung hình, đòi hỏi hệ thống phải suy luận thông minh để ước lượng chính xác.
- Thích ứng với sự biến đổi: Sự thay đổi về ánh sáng, góc quay camera, kích thước đối tượng và độ phức tạp của phông nền đều có thể ảnh hưởng trực tiếp đến độ chính xác của việc đếm.
Đếm đối tượng là quá trình tự động xác định và tính tổng số lượng từng đối tượng riêng lẻ xuất hiện trong một hình ảnh hoặc video. Mục tiêu cốt lõi của bài toán này là phát hiện từng cá thể đối tượng khác biệt và đưa ra con số đếm chính xác, tương tự như cách con người quan sát và đếm, nhưng được thực hiện bởi máy móc với độ nhất quán cao và khả năng mở rộng lớn.
Nói một cách đơn giản, có thể hiểu đây là việc huấn luyện máy tính “nhìn” vào một khung cảnh và đưa ra kết luận như:
- “Có 7 người.”
- “Có 12 phương tiện đã đi qua.”
Bài toán nền tảng này đóng vai trò xương sống cho nhiều ứng dụng thực tế, nơi việc hiểu và kiểm soát số lượng là yếu tố then chốt.
>>> Xem thêm:
- Thiết kế website bằng AI (trí tuệ nhân tạo) miễn phí
- Hướng dẫn cách sử dụng Google AI Studio hiệu quả, nhanh chóng
Cách xây dựng ứng dụng đếm đối tượng bằng thị giác máy tính với Roboflow (4 ví dụ)
Dưới đây là cách bạn có thể xây dựng các ứng dụng đếm đối tượng bằng Roboflow. Trong các ví dụ, chúng ta sử dụng RF-DETR và triển khai cho bốn bài toán:
- Đếm đối tượng trong ảnh
- Đếm đối tượng trong video
- Đếm đối tượng theo vùng trong video
- Đếm đối tượng trong luồng camera trực tiếp
Ví dụ 1: Đếm đối tượng trong ảnh
Trong ví dụ này, chúng ta sẽ tạo một Workflow của Roboflow có khả năng tiếp nhận hình ảnh đầu vào và phát hiện các đối tượng bằng cách sử dụng mô hình RF-DETR cơ bản.
Cụ thể, quy trình thực hiện gồm các bước sau: tạo một Workflow, sau đó thêm khối Phát hiện đối tượng (Object Detection) và cấu hình khối này với mô hình RF-DETR cơ bản, như minh họa trong hình bên dưới.
import cv2
import numpy as np
import supervision as sv
from collections import Counter
import matplotlib.pyplot as plt
from PIL import Image
from inference_sdk import InferenceHTTPClient
# Load original image
image_path = "dogs.png"
image_bgr = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
client = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key="YOUR_API_KEY"
)
result = client.run_workflow(
workspace_name="tim-4ijf0",
workflow_id="object-counting-image",
images={
"image": image_path
},
use_cache=False
)
# Parse predictions
predictions = result[0]["output"]["predictions"]
xyxy = []
confidences = []
class_names = []
for pred in predictions:
conf = pred["confidence"]
cls = pred["class"]
x_c, y_c = pred["x"], pred["y"]
w, h = pred["width"], pred["height"]
x1 = x_c - w / 2
y1 = y_c - h / 2
x2 = x_c + w / 2
y2 = y_c + h / 2
xyxy.append([x1, y1, x2, y2])
confidences.append(conf)
class_names.append(cls)
xyxy = np.array(xyxy, dtype=float)
confidences = np.array(confidences, dtype=float)
class_names = np.array(class_names)
# Assign per-class object numbers
per_class_counter = Counter()
labels = []
for cls, conf in zip(class_names, confidences):
per_class_counter[cls] += 1
count = per_class_counter[cls]
labels.append(f"{cls} #{count} ({conf:.2f})")
# Supervision Detections object
detections = sv.Detections(
xyxy=xyxy,
confidence=confidences,
class_id=np.zeros(len(xyxy), dtype=int)
)
# Visualize
annotated = image_rgb.copy()
box_annotator = sv.BoxAnnotator(thickness=2)
label_annotator = sv.LabelAnnotator(text_scale=0.5, text_thickness=1)
annotated = box_annotator.annotate(scene=annotated, detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections, labels=labels)
# Display
plt.figure(figsize=(12, 10))
plt.imshow(annotated)
plt.axis("off")
plt.title("Object Counts: " + ", ".join(f"{k}: {v}" for k, v in per_class_counter.items()))
plt.show()>>> Xem thêm:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Vertex AI là gì? Nền tảng học máy của Google Cl
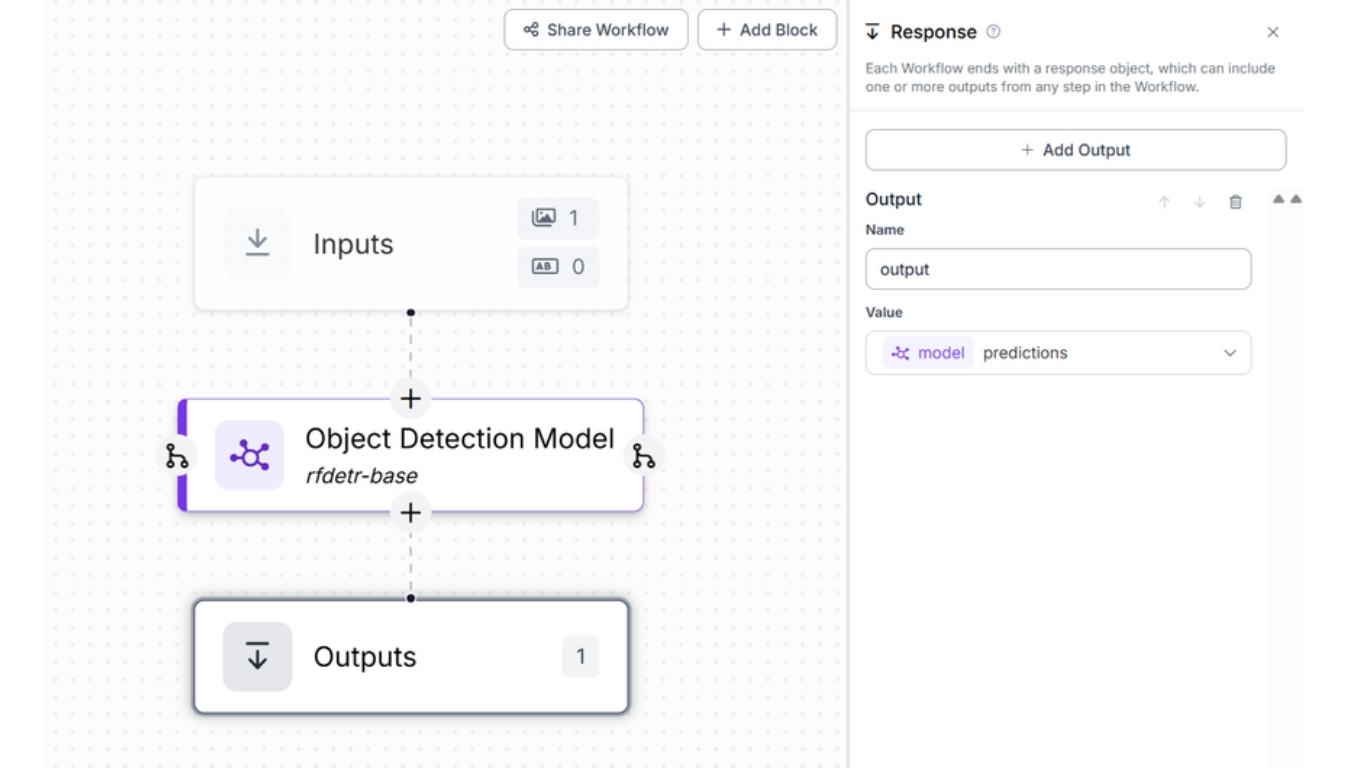
Cách hoạt động: Đoạn mã này thực hiện đếm đối tượng và trực quan hóa kết quả trên hình ảnh dựa trên đầu ra từ Roboflow Workflow. Trước tiên, chương trình tải một hình ảnh và gửi hình ảnh đó đến một Workflow Roboflow tùy chỉnh thông qua InferenceHTTPClient.
Workflow này sử dụng một mô hình phát hiện đối tượng (rf-detr-base) và trả về danh sách các dự đoán, trong đó mỗi dự đoán bao gồm: tên lớp đối tượng, vị trí, kích thước và độ tin cậy. Script sẽ chuyển các kết quả phát hiện này thành các khung bao (bounding box), sau đó gán một số thứ tự duy nhất cho từng đối tượng được phát hiện theo từng lớp (ví dụ: chó #1, mèo #2), kèm theo điểm độ tin cậy.
Tiếp theo, bằng cách sử dụng thư viện Supervision, chương trình trực quan hóa các kết quả phát hiện bằng cách vẽ khung bao và nhãn trực tiếp lên hình ảnh. Cuối cùng, hình ảnh đã được chú thích sẽ được hiển thị kèm theo một tiêu đề tóm tắt số lượng của từng lớp đối tượng (ví dụ: Số lượng đối tượng – chó: 3, mèo: 2), qua đó biến đoạn mã này thành một ứng dụng đếm đối tượng đơn giản nhưng hiệu quả.


Ví dụ 2: Đếm đối tượng trong video
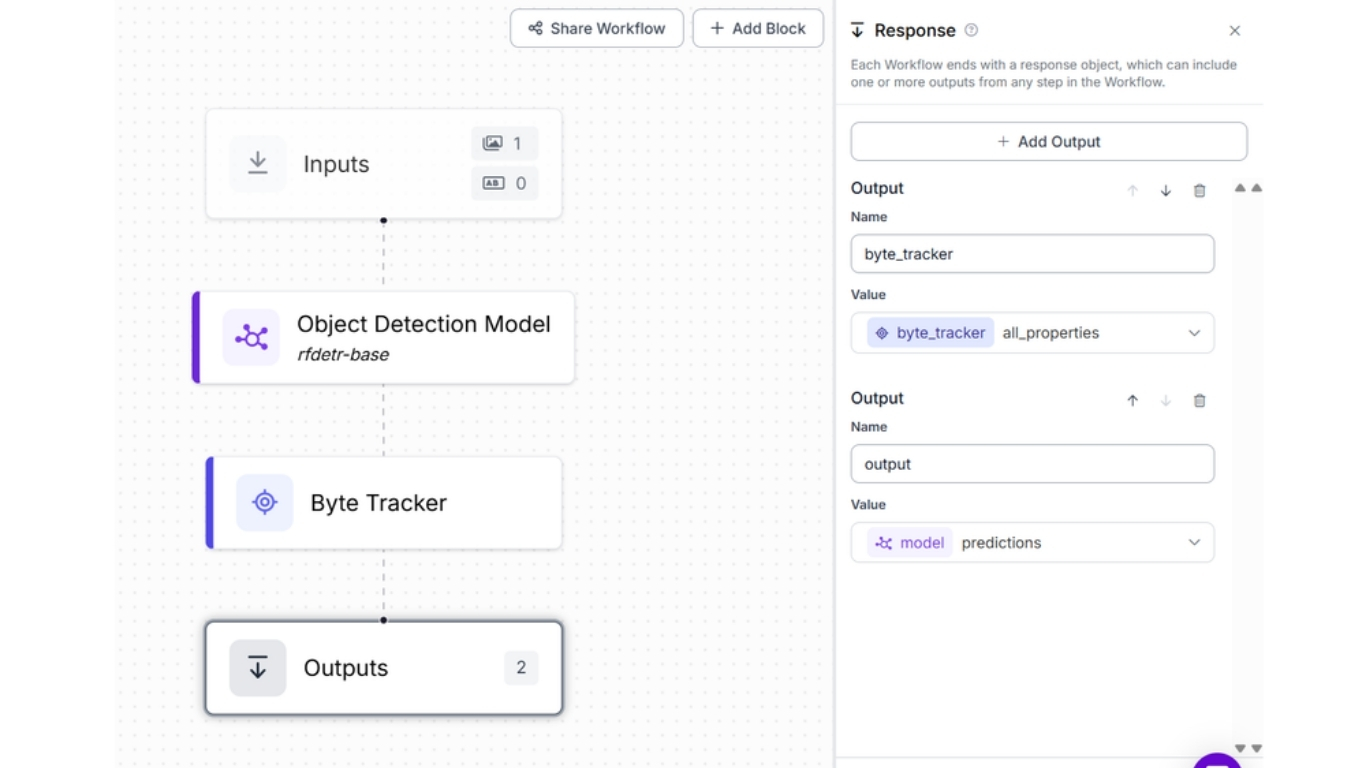
Trong ví dụ này, bạn học cách đếm đối tượng trong video. Trước hết, tạo một Roboflow Workflow kết hợp:
- Object Detection Model (rf-detr-base): phát hiện đối tượng theo từng frame.
- ByteTrack: gán ID duy nhất cho mỗi đối tượng và theo dõi qua các frame.
Thiết lập này là then chốt trong đếm đối tượng bằng thị giác máy tính cho video, vì nó đảm bảo một đối tượng chỉ bị đếm một lần, bất kể nó xuất hiện bao lâu trong video. Workflow xuất ra cả dự đoán thô và thông tin tracking, từ đó phù hợp cho các ứng dụng đếm cộng dồn.
Triển khai Workflow bằng script sau:
from inference import InferencePipeline
import supervision as sv
import cv2
import numpy as np
from collections import defaultdict
# === Output video config ===
output_path = "output_object_counting.mp4"
video_writer = None
output_fps = 30
output_size = None
# Object ID and count state
id_registry = {} # (class_name, tracker_id) -> object_number
next_object_number = defaultdict(int) # class_name -> next id (starting from 1)
total_class_counts = defaultdict(int) # class_name -> total seen ever
# Annotators
box_annotator = sv.BoxAnnotator(thickness=2)
label_annotator = sv.LabelAnnotator(text_scale=0.5, text_thickness=1)
def my_sink(result, video_frame):
global video_writer, output_size
frame = video_frame.image
tracked = result["byte_tracker"]["tracked_detections"]
# Data extraction
xyxy = tracked.xyxy
class_names = tracked.data["class_name"]
tracker_ids = tracked.tracker_id
confidences = tracked.confidence
labels = []
per_frame_counter = defaultdict(int)
# Assign IDs and prepare labels
for i, (cls_name, trk_id, conf) in enumerate(zip(class_names, tracker_ids, confidences)):
key = (cls_name, int(trk_id))
if key not in id_registry:
next_object_number[cls_name] += 1
id_registry[key] = next_object_number[cls_name]
total_class_counts[cls_name] += 1
obj_number = id_registry[key]
per_frame_counter[cls_name] += 1
labels.append(f"{cls_name} #{obj_number} ({conf:.2f})")
# Build supervision Detections object
detections = sv.Detections(
xyxy=xyxy,
confidence=confidences,
class_id=np.zeros(len(xyxy), dtype=int),
tracker_id=tracker_ids
)
# Annotate with supervision
annotated = box_annotator.annotate(scene=frame.copy(), detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections, labels=labels)
# Draw global count summary (cumulative)
y0 = 30
for i, (cls, cnt) in enumerate(total_class_counts.items()):
text = f"{cls} Total: {cnt}"
cv2.putText(
annotated, text,
(10, y0 + i * 30),
cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 255), 2, cv2.LINE_AA
)
# Init video writer
if video_writer is None:
h, w = annotated.shape[:2]
output_size = (w, h)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(output_path, fourcc, output_fps, output_size)
# Show + save frame
cv2.imshow("annotated", annotated)
cv2.waitKey(1)
# if running on google colab, use cv2_imshow
# from google.colab.patches import cv2_imshow
# cv2_imshow(annotated)
video_writer.write(annotated)
# Roboflow inference pipeline
pipeline = InferencePipeline.init_with_workflow(
api_key="YOUR_API_KEY",
workspace_name="tim-4ijf0",
workflow_id="object-counting-video",
video_reference="/content/people-walking.mp4",
max_fps=30,
on_prediction=my_sink
)
pipeline.start()
pipeline.join()
# Final cleanup
if video_writer:
video_writer.release()
cv2.destroyAllWindows()Cách hoạt động: Đoạn mã Python này gửi từng khung hình của video đến Workflow, sau đó nhận lại kết quả phát hiện đối tượng kèm theo ID theo dõi duy nhất cho mỗi đối tượng. Tiếp theo, chương trình sử dụng thư viện Supervision để vẽ khung bao và nhãn (ví dụ: “người #2”) chồng trực tiếp lên video.
Hệ thống duy trì bộ đếm cộng dồn cho từng đối tượng duy nhất bằng cách kiểm tra xem ID đó đã xuất hiện trước đây hay chưa. Kết quả cuối cùng là một video thể hiện trực quan mỗi đối tượng được phát hiện, số thứ tự được gán, cùng với tổng số đối tượng duy nhất đã được đếm theo thời gian, qua đó rất phù hợp cho các bài toán đếm đối tượng chính xác trong video.
Chạy workflow này trên video sau:
Bạn sẽ thấy kết quả đầu ra tương tự như hình minh họa bên dưới, trong đó thông tin đếm đối tượng được hiển thị ở góc trên bên trái của video, đồng thời mỗi đối tượng được phát hiện sẽ có khung bao và chú thích số thứ tự đối tượng tương ứng hiển thị trực tiếp trên video.
Ví dụ 3: Đếm đối tượng theo vùng trong video
Trong ví dụ này, chúng ta sẽ tìm hiểu cách đếm số người đi vào một khu vực cụ thể trong luồng video. Chúng ta sẽ tái sử dụng Roboflow Workflow đã được xây dựng ở Ví dụ #2.
Sau khi tạo xong Roboflow Workflow, bạn hãy triển khai (deploy) workflow này bằng đoạn mã code dưới đây.
from inference import InferencePipeline
import supervision as sv
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
from collections import defaultdict
# Output config
output_path = "output_zone_count_filtered.mp4"
video_writer = None
output_fps = 30
output_size = None
# Tracking state
id_registry = {}
next_object_number = defaultdict(int)
total_class_counts = defaultdict(int)
# Target class
TARGET_CLASS = "person"
# Zone polygon
polygon = np.array([[604, 876], [1313, 864], [1235, 535], [670, 544]])
zone = sv.PolygonZone(polygon=polygon)
# Manual polygon drawer (removes supervision’s default center ID)
def draw_polygon(scene, polygon, color=(255, 255, 255), thickness=2):
points = polygon.reshape((-1, 1, 2)).astype(int)
return cv2.polylines(scene, [points], isClosed=True, color=color, thickness=thickness)
# Annotators
box_annotator = sv.BoxAnnotator(thickness=2)
label_annotator = sv.LabelAnnotator(text_scale=0.5, text_thickness=1)
def my_sink(result, video_frame):
global video_writer, output_size
frame = video_frame.image
tracked = result["byte_tracker"]["tracked_detections"]
xyxy = tracked.xyxy
class_names = tracked.data["class_name"]
tracker_ids = tracked.tracker_id
confidences = tracked.confidence
# Supervision detections
detections = sv.Detections(
xyxy=xyxy,
confidence=confidences,
class_id=np.zeros(len(xyxy), dtype=int),
tracker_id=tracker_ids
)
# Filter: by zone
in_zone_mask = zone.trigger(detections)
detections = detections[in_zone_mask]
filtered_class_names = class_names[in_zone_mask]
filtered_tracker_ids = tracker_ids[in_zone_mask]
filtered_confidences = confidences[in_zone_mask]
# Filter: by target class
final_mask = np.array([cls == TARGET_CLASS for cls in filtered_class_names])
detections = detections[final_mask]
filtered_class_names = filtered_class_names[final_mask]
filtered_tracker_ids = filtered_tracker_ids[final_mask]
filtered_confidences = filtered_confidences[final_mask]
# Tracking logic
current_ids_in_zone = set()
labels = []
for cls_name, trk_id, conf in zip(filtered_class_names, filtered_tracker_ids, filtered_confidences):
key = (cls_name, int(trk_id))
current_ids_in_zone.add(key)
if key not in id_registry:
next_object_number[cls_name] += 1
id_registry[key] = next_object_number[cls_name]
total_class_counts[cls_name] += 1 # Cumulative count
obj_number = id_registry[key]
labels.append(f"{cls_name} #{obj_number} ({conf:.2f})")
# Annotate frame
annotated = box_annotator.annotate(scene=frame.copy(), detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections, labels=labels)
annotated = draw_polygon(annotated, polygon)
# Draw text on frame
cv2.putText(
annotated,
f"Total {TARGET_CLASS}(s) in Zone: {total_class_counts.get(TARGET_CLASS, 0)}",
(20, 120),
cv2.FONT_HERSHEY_SIMPLEX,
0.8,
(255, 255, 255),
2,
cv2.LINE_AA
)
cv2.putText(
annotated,
f"{TARGET_CLASS}(s) currently in Zone: {len(current_ids_in_zone)}",
(20,150),
cv2.FONT_HERSHEY_SIMPLEX,
0.8,
(255, 255, 255),
2,
cv2.LINE_AA
)
# Video output
if video_writer is None:
h, w = annotated.shape[:2]
output_size = (w, h)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(output_path, fourcc, output_fps, (w, h))
cv2_imshow(annotated)
video_writer.write(annotated)
# Start pipeline
pipeline = InferencePipeline.init_with_workflow(
api_key="YOUR_API_KEY",
workspace_name="tim-4ijf0",
workflow_id="object-counting-video",
video_reference="/content/people-walking.mp4",
max_fps=30,
on_prediction=my_sink
)
pipeline.start()
pipeline.join()
if video_writer:
video_writer.release()
cv2.destroyAllWindows()Đoạn mã này là một triển khai nâng cao cho bài toán đếm các đối tượng cụ thể (ví dụ: “người”) trong một khu vực xác định của video. Khu vực này được định nghĩa dưới dạng đa giác (polygon), được tạo bằng công cụ PolygonZone và sau đó nhập vào script dưới dạng các tọa độ.
Đoạn mã sử dụng một Roboflow Workflow bao gồm mô hình phát hiện đối tượng (rf-detr-base), sau đó kết hợp với ByteTrack để gán ID duy nhất cho từng đối tượng được phát hiện. Các ID này cho phép hệ thống theo dõi từng đối tượng xuyên suốt các khung hình, từ đó tránh việc đếm trùng lặp. Script sẽ lọc các kết quả phát hiện dựa trên hai điều kiện: đối tượng nằm bên trong vùng đa giác và thuộc lớp mục tiêu (trong trường hợp này là “người”).
Thư viện Supervision chịu trách nhiệm vẽ khung bao và nhãn lên các khung hình video, trong khi OpenCV được sử dụng cho các chú thích bổ sung như vẽ vùng đa giác và hiển thị văn bản trực tiếp trên khung hình.
Sau khi xử lý mỗi khung hình, chương trình kiểm tra các đối tượng hiện đang nằm trong khu vực và duy trì bộ đếm cộng dồn dựa trên ID theo dõi của chúng. Khi một đối tượng với ID mới đi vào khu vực lần đầu tiên, đối tượng đó sẽ được ghi nhận và tính vào tổng số.
Script sẽ cập nhật và hiển thị hai chỉ số quan trọng trên mỗi khung hình:
- Tổng số người duy nhất đã từng đi vào khu vực
- Số người hiện đang có mặt trong khu vực
Các thông tin này được vẽ trực tiếp lên khung hình video. Cuối cùng, các khung hình đã được chú thích sẽ được lưu thành một file video mới, cung cấp một báo cáo trực quan đầy đủ về việc đếm đối tượng theo khu vực.
Kiểu theo dõi và phân tích theo vùng này đặc biệt hữu ích trong các kịch bản thực tế như giám sát lưu lượng người, phân tích bán lẻ, hoặc hệ thống giám sát thông minh.
Chạy đoạn script trên cùng video “people walking” sẽ tạo ra kết quả đầu ra tương tự như minh họa bên dưới.
Ví dụ 4: Đếm đối tượng trong luồng camera trực tiếp
Trong ví dụ này, ta đếm một loại đối tượng cụ thể (ví dụ: “book”), lọc theo lớp, trực tiếp từ camera. Vì ta chỉ quan tâm số đối tượng trong frame hiện tại nên không cần tracking; bộ đếm được reset mỗi frame. Điều này tương tự đếm trong ảnh tĩnh, nhưng lặp lại theo thời gian thực. Hãy liên hệ với ví dụ người nông dân ở phần mở đầu: người nông dân hướng camera vào cây táo, hệ thống ngay lập tức đếm số quả táo đang nhìn thấy.
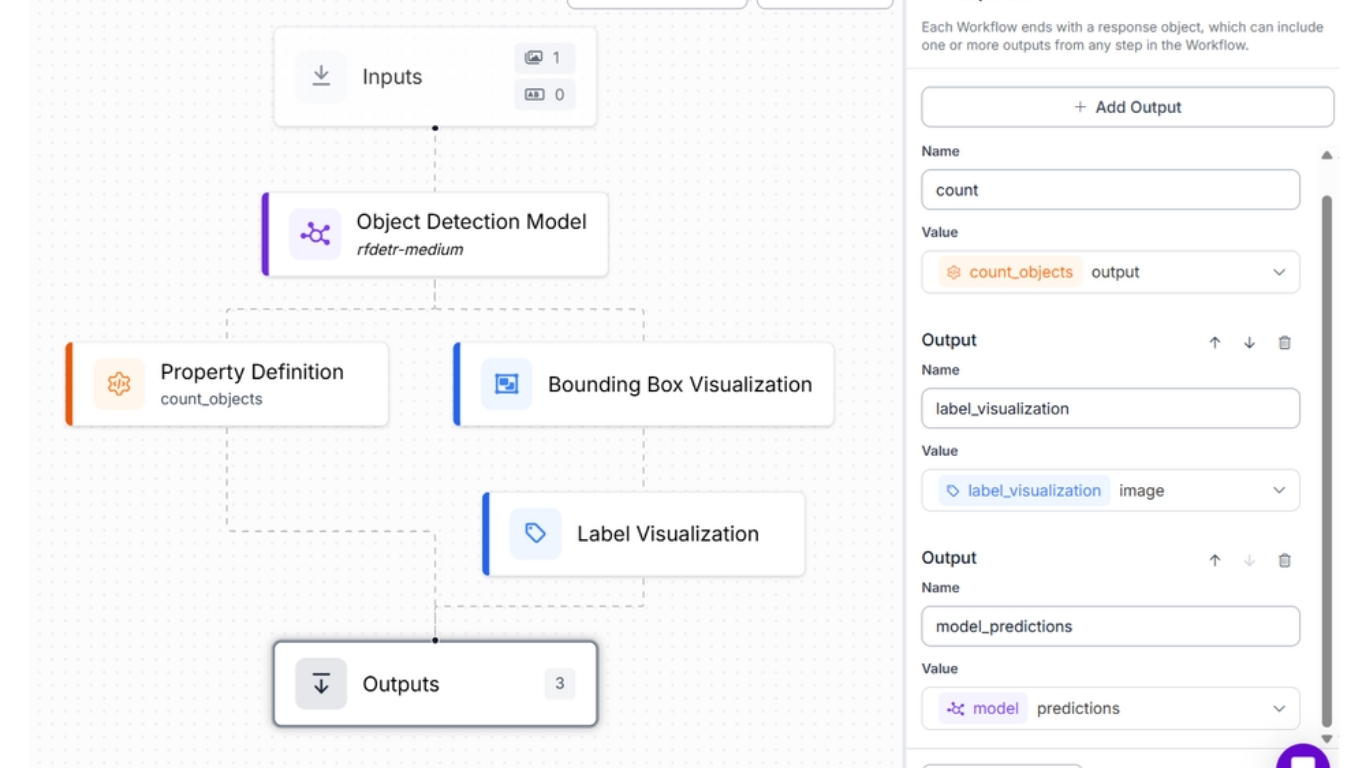
Để làm được điều này, ta xây dựng Roboflow Workflow gồm các block:
- Object Detection Block: phát hiện đối tượng bằng RF-DETR; cấu hình Class Filter là “book”.
- Bounding Box Visualization Block: vẽ bounding box quanh mỗi detection.
- Label Visualization Block: hiển thị nhãn lớp.
- Property Definition Block: tự động đếm số instance được phát hiện.
Triển khai bằng code sau:
from inference import InferencePipeline
import cv2
def my_sink(result, video_frame):
# Start from the visualization image
frame = result["label_visualization"].numpy_image.copy()
# Read count safely
count = int(result.get("count", 0))
text = f"Count: {count}"
# Text styling
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 0.8
thickness = 2
margin = 12
# Compute background box for readability
(text_w, text_h), baseline = cv2.getTextSize(text, font, font_scale, thickness)
x, y = margin, margin + text_h
# Draw filled background rectangle (black) then white text
cv2.rectangle(
frame,
(x - 6, y - text_h - 6),
(x + text_w + 6, y + baseline + 6),
(0, 0, 0),
-1
)
cv2.putText(frame, text, (x, y), font, font_scale, (255, 255, 255), thickness, cv2.LINE_AA)
# Show the frame
cv2.imshow("Object Counting", frame)
cv2.waitKey(1)
# initialize a pipeline object
pipeline = InferencePipeline.init_with_workflow(
api_key="YOUR_API_KEY",
workspace_name="tim-4ijf0",
workflow_id="object-counting-camera",
video_reference=0,
max_fps=30,
on_prediction=my_sink
)
pipeline.start()
pipeline.join()Đoạn mã này kết nối với luồng camera trực tiếp và sử dụng Roboflow Workflow có sẵn để phát hiện và đếm đối tượng theo thời gian thực. Với mỗi khung hình, quy trình hoạt động như sau:
- Đầu ra trực quan hóa nhãn của workflow được sử dụng làm hình ảnh nền.
- Thuộc tính count từ workflow được đọc để xác định số lượng đối tượng được phát hiện trong khung hình hiện tại.
- Giá trị đếm được hiển thị ở góc trên bên trái, đặt trên một hình chữ nhật màu đen để đảm bảo dễ quan sát.
- Khung hình đã xử lý được hiển thị trực tiếp trong một cửa sổ.
InferencePipeline liên tục thực thi quy trình này cho đến khi bị dừng, đảm bảo bạn luôn nhìn thấy số lượng đối tượng hiện đang xuất hiện trong khung hình theo thời gian thực.
Khi chạy Workflow, bạn sẽ thấy kết quả đầu ra tương tự như minh họa bên dưới.

Sử dụng RF-DETR cho đếm đối tượng bằng thị giác máy tính
RF-DETR là kiến trúc phát hiện đối tượng dựa trên transformer, được thiết kế để cân bằng độ chính xác cao và suy luận thời gian thực; vì vậy đặc biệt phù hợp cho các bài toán đếm đối tượng.
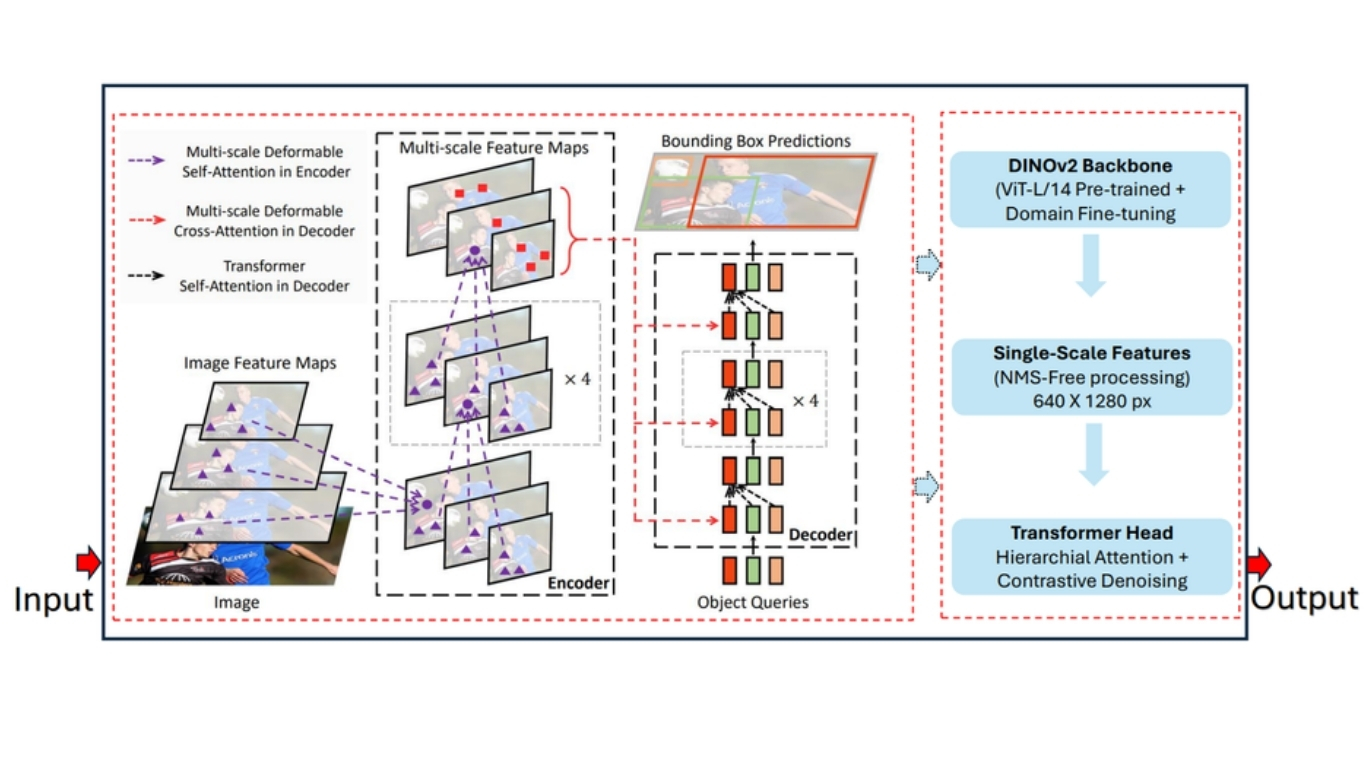
RF-DETR được mô tả là bộ phát hiện đối tượng thời gian thực đầu tiên vượt mốc 60 mAP trên benchmark MS-COCO trong khi chạy khoảng 25 FPS trên NVIDIA T4, qua đó đặt ra một chuẩn mới cho bài toán đánh đổi giữa độ chính xác và tốc độ trong detection.
Dựa trên deformable transformer architecture và cơ chế global self-attention, RF-DETR mạnh trong xử lý các đối tượng bị chồng lấn hoặc bị che khuất một phần, theo hướng “set prediction” mà không phụ thuộc vào anchor boxes hoặc NMS.
Ví dụ, trong bối cảnh đếm trái cây nông nghiệp với mức che khuất lớn, RF-DETR đạt mAP@50 = 0.9464, cho thấy khả năng phân biệt tốt giữa trái bị che và trái nhìn thấy rõ. Ngoài ra, trong bài toán phát hiện đa lớp, RF-DETR được nêu đạt mAP@50 = 0.8298, thể hiện năng lực phân tách trái bị che và không bị che.

Các trường hợp ứng dụng của đếm đối tượng bằng thị giác máy tính
Đếm đối tượng bằng thị giác máy tính giúp tinh gọn vận hành, giảm lao động thủ công và tăng độ chính xác trong nhiều ngành. Một số ví dụ tiêu biểu:
- Sản xuất: đếm linh kiện trên băng chuyền, phát hiện lỗi theo thời gian thực, kiểm tra đóng gói để dây chuyền nhanh và ít lỗi.
- Y tế: tự động đếm tế bào trong chẩn đoán, theo dõi dụng cụ phẫu thuật, kiểm tra liều dùng thuốc để tăng an toàn và hiệu quả.
- Kho vận: theo dõi pallet và thùng hàng, kiểm tra độ đúng của đơn khi đóng gói, duy trì tồn kho thời gian thực mà không cần kiểm đếm thủ công.
- Nông nghiệp: ước tính sản lượng bằng đếm trái/cây, theo dõi số lượng vật nuôi, phát hiện sớm dấu hiệu dịch hại.
>>> Xem thêm: Low Code là gì? Giải pháp phát triển phần mềm và xu hướng tương lai
Cách đếm đối tượng tự động với thị giác máy tính
Đếm đối tượng có thể trông như một tác vụ đơn giản, nhưng khi được “tăng lực” bởi thị giác máy tính, nó trở thành một công cụ mang tính chuyển đổi ở nhiều ngành: từ theo dõi dây chuyền sản xuất đến giám sát bệnh nhân hoặc ước tính năng suất cây trồng. Với các mô hình mạnh như RF-DETR, việc xây dựng hệ thống đếm chính xác và có khả năng mở rộng đã trở nên dễ tiếp cận hơn rất nhiều.
Nguồn tham khảo: Object Counting with Computer Vision
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Hoàng Diệu, Phường 12, Quận 4, Thành phố Hồ Chí Minh, Việt Nam