
Convolutional neural network là gì mà lại trở thành nền tảng cốt lõi của học sâu trong thị giác máy tính? Nhờ khả năng khai thác hiệu quả dữ liệu hình ảnh thông qua nhiều lớp ẩn, CNN đã giúp các mô hình AI vượt xa phương pháp truyền thống trong các bài toán như nhận dạng mẫu, phân loại và phát hiện đối tượng. Hãy cùng TOT tìm hiểu qua bài viết sau!
>> Tìm hiểu thêm:
- Những trình soạn thảo mã cho thị giác máy tính tốt nhất 2026
- Phát hiện chuyển động bằng thị giác máy tính – Cách hoạt động và logic phát hiện
- Đếm Đối Tượng Bằng Thị Giác Máy Tính
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
Mở đầu
Việc sử dụng nhiều lớp ẩn trong học máy (Machine Learning), thường được gọi là học sâu (Deep Learning), đã vượt qua hiệu năng của các kỹ thuật truyền thống trong việc giải quyết nhiều bài toán khác nhau, đặc biệt là trong lĩnh vực nhận dạng mẫu và phát hiện đối tượng. Một trong những kiến trúc phổ biến nhất được sử dụng trong học sâu là Mạng nơ-ron tích chập (Convolutional Neural Network – CNN), thường được áp dụng cho các bài toán phân loại.
CNN đã đóng vai trò then chốt trong lĩnh vực thị giác máy tính (computer vision), với mục tiêu giúp máy móc hiểu được dữ liệu hình ảnh. Vào năm 2012, một nhóm các nhà nghiên cứu tại Đại học Toronto đã phát triển một mô hình AI có tên là AlexNet, được đặt theo tên của người tạo ra chính là Alex Krizhevsky. Mô hình này đã đạt được độ chính xác chưa từng có là 85% trong bài toán nhận dạng hình ảnh, vượt xa mức 74% của mô hình đứng thứ hai trong cuộc thi thị giác máy tính ImageNet.
Thành công của AlexNet phần lớn đến từ việc sử dụng CNN – một loại mạng nơ-ron nhân tạo (neural network) được thiết kế mô phỏng theo cách con người nhìn và xử lý hình ảnh. Theo thời gian, CNN đã trở thành một thành phần không thể thiếu trong nhiều ứng dụng thị giác máy tính và hiện nay là một chủ đề phổ biến trong các khóa học trực tuyến về lĩnh vực này. Vì vậy, việc hiểu cách hoạt động của CNN cũng như thuật toán CNN trong học sâu (deep learning) rất quan trọng đối với bất kỳ ai quan tâm đến lĩnh vực này.
>> Xem thêm:
- Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow
- Vision AI Agents là gì? Cách xây dựng Vision AI Agents với Roboflow
Convolutional Neural Network là gì?
Convolutional Neural Network – CNN (còn gọi là mạng nơ-ron tích chập), đây là một kiến trúc học sâu (Deep Learning) nhận đầu vào là hình ảnh, thực hiện các phép tích chập và lấy mẫu, sau đó đi qua các lớp kết nối toàn phần và hàm kích hoạt để trả về kết quả đầu ra. Đầu ra này thường chứa thông tin phân loại nội dung của hình ảnh hoặc thông tin về vị trí của các đối tượng khác nhau trong hình ảnh.
Khác với các mạng nơ-ron truyền thống, chủ yếu dựa trên phép nhân ma trận, CNN sử dụng một kỹ thuật gọi là tích chập. Về mặt toán học, tích chập là một phép toán kết hợp hai hàm để tạo ra một hàm thứ ba, thể hiện cách một hàm làm thay đổi hình dạng của hàm còn lại. Sau đó, dữ liệu tiếp tục được xử lý thông qua các bước như pooling, đi qua các lớp kết nối đầy đủ và hàm kích hoạt để tạo ra dự đoán cuối cùng.
Dưới đây là kiến trúc điển hình của một CNN:
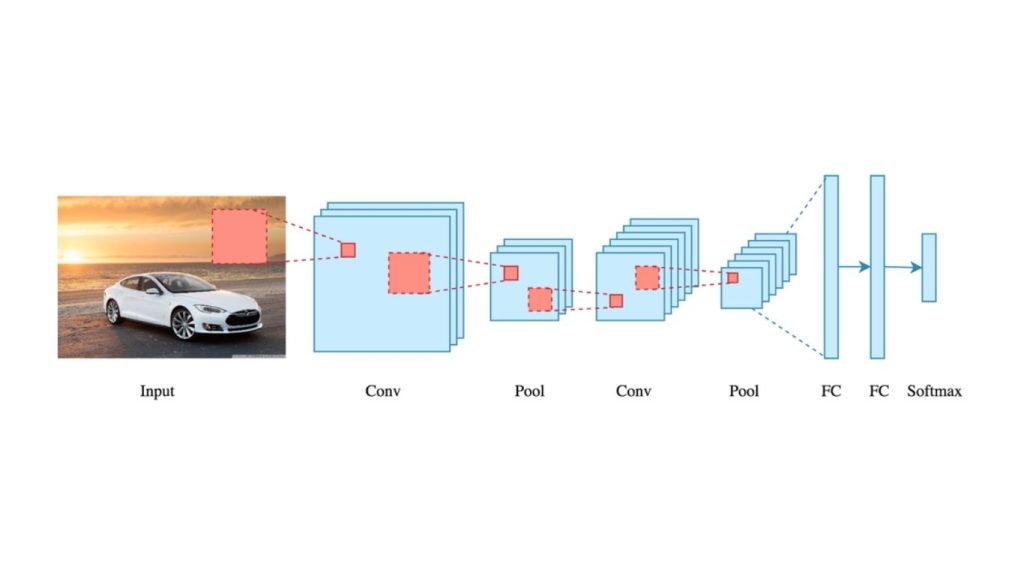
Các lớp tích chập (convolutional layers) trong CNN quét toàn bộ hình ảnh để trích xuất các đặc trưng quan trọng như cạnh, kết cấu và hình dạng. Những đặc trưng này được truyền qua nhiều lớp và xử lý bằng các kỹ thuật như gộp (pooling) và hàm kích hoạt, từ đó tạo ra một biểu diễn nhỏ gọn nhưng vẫn giàu thông tin của hình ảnh ban đầu. Biểu diễn này sau đó được đưa vào các lớp kết nối đầy đủ để đưa ra dự đoán cuối cùng.
Mặc dù việc hiểu chi tiết toán học đằng sau phép tích chập có thể hữu ích, nhưng không phải là yếu tố thiết yếu để nắm được khái niệm tổng quát của CNN.
Ở mức độ cao hơn, CNN được thiết kế để nhận vào một hình ảnh và chuyển đổi hình ảnh thành một dạng biểu diễn mà mạng nơ-ron có thể hiểu được, đồng thời vẫn giữ lại những đặc trưng quan trọng giúp đưa ra dự đoán chính xác.
>> Tham khảo: AI nhận diện ảnh là gì? Thuật toán và ứng dụng phổ biến
So sánh mạng nơ-ron tích chập và mạng nơ-ron truyền thẳng
Để hiểu rõ về CNN trong bối cảnh, cần xem xét mô hình tiền thân của nó là mạng nơ-ron truyền thẳng (feed-forward neural network).
Mạng nơ-ron truyền thẳng là loại mạng xử lý dữ liệu theo một chiều duy nhất, trong đó dữ liệu đầu vào được truyền qua nhiều lớp trước khi tạo ra đầu ra. Tuy nhiên, khi áp dụng cho xử lý hình ảnh, loại mạng này gặp một hạn chế lớn là có thể gặp nguy cơ quá khớp.
Cụ thể, một hình ảnh có thể được biểu diễn dưới dạng một ma trận số với kích thước (số hàng × số cột × số kênh). Một hình ảnh thực tế thông thường có kích thước ít nhất 200 × 200 × 3 pixel. Một cách tiếp cận để đưa hình ảnh vào mạng nơ-ron truyền thẳng là chuyển đổi hình ảnh thành ma trận 1D. Điều này đòi hỏi số lượng lớn nơ-ron và trọng số ở lớp ẩn đầu tiên, dẫn đến số lượng tham số rất lớn và làm tăng nguy cơ quá khớp.
Ngược lại, CNN tiếp cận bài toán xử lý hình ảnh theo cách khác. Thay vì phẳng hóa hình ảnh và xử lý toàn bộ hình ảnh trong một lần, CNN xử lý từng vùng nhỏ của hình ảnh và quét trên toàn bộ ảnh. Điều này cho phép mạng học các đặc trưng quan trọng của hình ảnh, đồng thời sử dụng ít nơ-ron và ít tham số hơn. Phương pháp này giúp CNNs hiệu quả hơn và ít bị quá khớp hơn so với các mạng nơ-ron truyền thẳng.
>> Tham khảo thêm:
- Visual Question Answering là gì? Mô hình và Phương pháp hoạt động
- Mã nguồn mở là gì? TOP 15 nền tảng mã nguồn mở thiết kế web phổ biến nhất hiện nay
CNN hoạt động như thế nào?
Trước khi đi sâu vào cơ chế hoạt động của CNN, cần hiểu những kiến trúc cơ bản về hình ảnh và cách chúng được biểu diễn.
Một hình ảnh có thể được biểu diễn dưới dạng ma trận các giá trị pixel, với mỗi pixel có một giá trị màu cụ thể. Trong đó, hình ảnh RGB là loại hình ảnh phổ biến nhất, có ba kênh màu: đỏ, xanh lá và xanh dương. Trong khi đó, hình ảnh xám chỉ có một kênh, đại diện cho độ sáng của pixel.
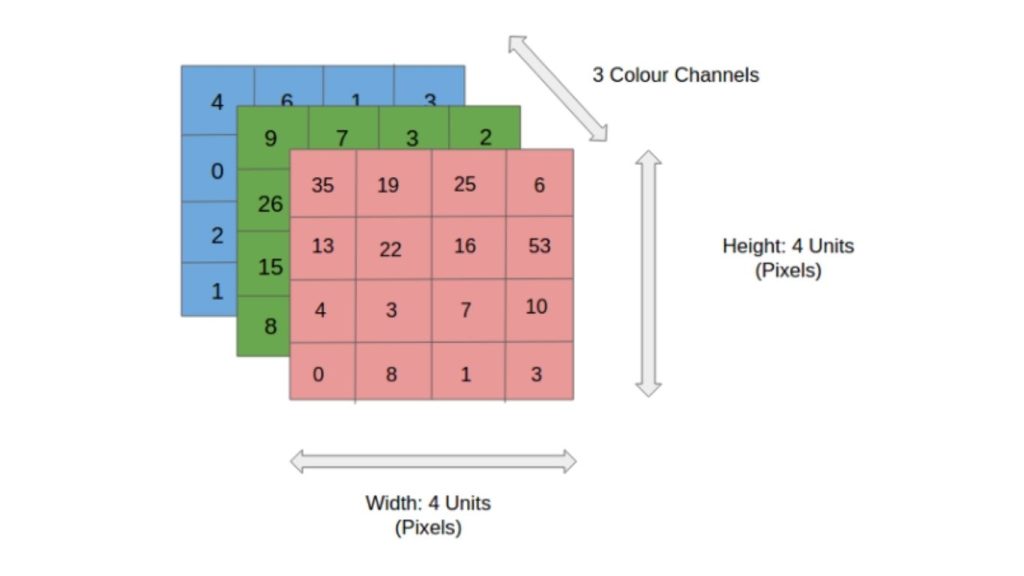
Số lượng pixel trong hình ảnh quyết định độ phân giải, với hình ảnh có độ phân giải cao chứa nhiều pixel hơn và do đó mang nhiều thông tin chi tiết hơn.
Sau khi đã thảo luận các kiến thức nền tảng cần thiết, bây giờ chúng ta sẽ đi sâu vào cách CNN hoạt động. Hãy cùng xem xét một ví dụ sử dụng hình ảnh thang xám, vì cấu trúc của chúng không phức tạp như hình ảnh RGB.
Tích chập là gì?
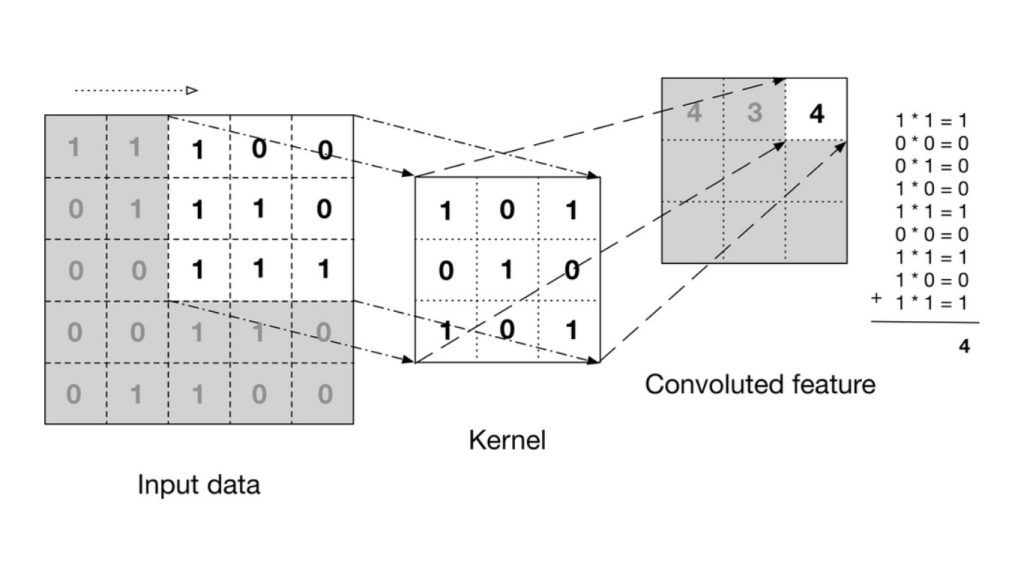
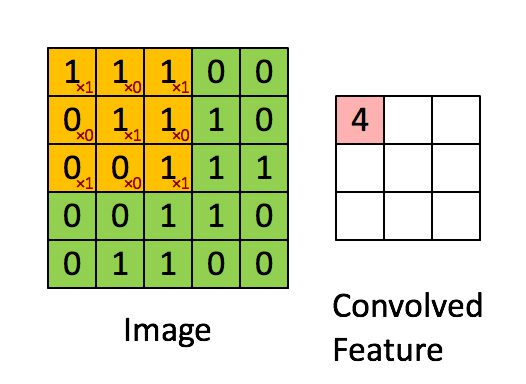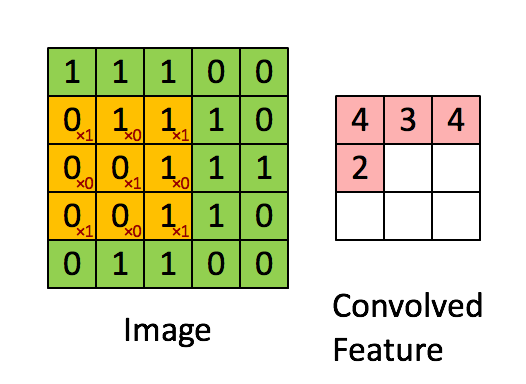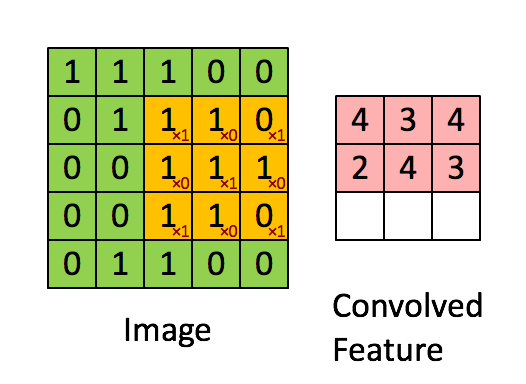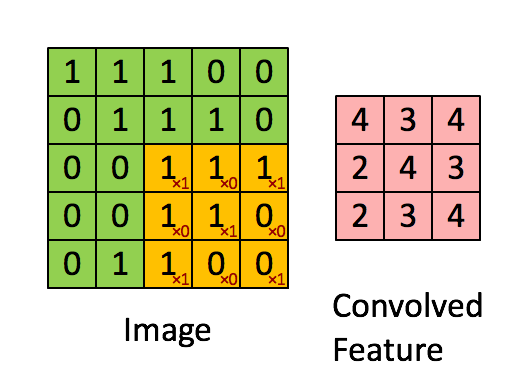
Trong CNN, phép tích chập hoạt động bằng cách sử dụng một ma trận nhỏ gọi là bộ lọc hoặc kernel để quét qua hình ảnh đầu vào, từ đó phát hiện các đặc trưng quan trọng. Khi bộ lọc di chuyển đến từng vị trí trên ảnh, nó sẽ nhân từng phần tử của mình với các giá trị pixel tương ứng, rồi cộng tất cả các kết quả lại với nhau.
Kết quả của quá trình này là một đặc trưng sau tích chập, và đặc trưng đó sẽ được chuyển sang lớp tiếp theo để tiếp tục xử lý.
Bên dưới là hình động minh họa cách phép tích chập được áp dụng trên một lưới dữ liệu pixel kích thước 5×5.
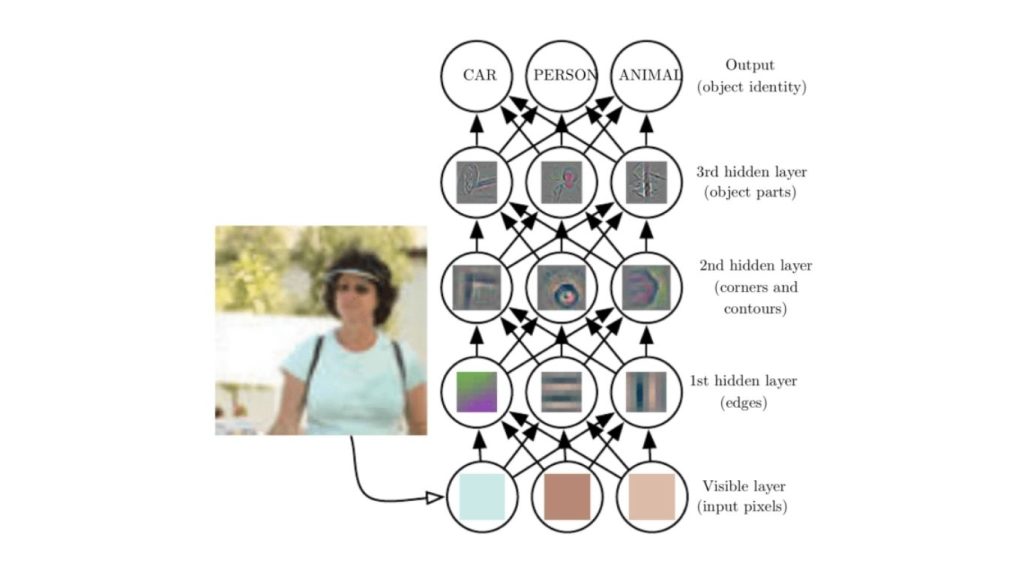
Mạng nơ-ron tích chập được cấu thành từ một chuỗi các lớp nơ-ron nhân tạo liên kết với nhau. Các nơ-ron nhân tạo này là các hàm toán học nhận vào nhiều đầu vào, đánh giá chúng và trả về một giá trị kích hoạt.
Lớp đầu tiên của CNN có nhiệm vụ nhận diện các đặc trưng cơ bản như cạnh, góc và những hình dạng đơn giản khác. Khi hình ảnh được truyền qua các lớp tiếp theo, mạng có thể phát hiện các đặc trưng phức tạp hơn, chẳng hạn như vật thể và khuôn mặt bằng cách xây dựng và tổng hợp thông tin từ các lớp trước đó. Khi hình ảnh được xử lý càng sâu hơn, CNN càng có khả năng nhận diện những đặc trưng phức tạp hơn nữa như các vật thể, khuôn mặt,…
Lớp tích chập cuối cùng của CNN tạo ra một “bản đồ kích hoạt”. Trong các bài toán phân loại, chẳng hạn, lớp phân loại sẽ sử dụng bản đồ này để xác định mức độ khả năng mà hình ảnh đầu vào thuộc về một “lớp” cụ thể.
Mức độ khả năng này được biểu diễn dưới dạng một tập các điểm tin cậy, với giá trị nằm trong khoảng từ 0 đến 1. Ví dụ, nếu mạng nơ-ron tích chập được thiết kế để nhận diện mèo, chó và ngựa, thì đầu ra của lớp cuối cùng sẽ là các xác suất cho biết hình ảnh đầu vào chứa một trong những loài động vật đó. Giá trị càng cao thì khả năng hình ảnh thuộc về lớp tương ứng càng lớn.
>> Tìm hiểu thêm:
- Các công cụ thị giác máy tính không cần code hàng đầu năm 2026
- Inference In Computer Vision: Suy luận trong thị giác máy tính là gì?
CNN trong phát hiện đối tượng
CNN có thể được sử dụng cho phát hiện đối tượng (object detection), một nhiệm vụ bao gồm việc xác định vị trí và nhận dạng các đối tượng trong hình ảnh hoặc video. Kết quả đầu ra của một CNN trong phát hiện đối tượng là tập hợp các khung giới hạn xung quanh các đối tượng trong hình ảnh, kèm theo nhãn lớp và điểm tin cậy cho biết mỗi đối tượng là gì và mức độ tin cậy của mạng đối với dự đoán của mình.
Có nhiều phương pháp khác nhau để sử dụng CNN cho phát hiện đối tượng. Trong đó, một cách phổ biến là mô hình hai giai đoạn như họ mô hình R-CNN (Regions with Convolutional Neural Networks). Ở giai đoạn đầu tiên, mạng được sử dụng để đề xuất các vùng đối tượng tiềm năng trong hình ảnh (còn được gọi là đề xuất vùng).
Các đề xuất vùng này sau đó được đưa vào giai đoạn thứ hai, nơi mạng kết nối đầy đủ được sử dụng để phân loại các đối tượng trong các vùng và tinh chỉnh các khung giới hạn. Các phương pháp mới hơn như mô hình YOLO (You Only Look Once) và RetinaNet sử dụng phương pháp tiếp cận một giai đoạn, trong đó mạng dự đoán hộp giới hạn, nhãn lớp và điểm tin cậy trực tiếp trong một lần xử lý duy nhất. Các mô hình này thường nhanh hơn phương pháp hai giai đoạn, nhưng thường có độ chính xác thấp hơn.
Dù sử dụng kiến trúc nào, ý tưởng cốt lõi của CNN trong phát hiện đối tượng là tận dụng các lớp tích chập để trích xuất các đặc trưng giàu thông tin và có khả năng phân biệt cao từ hình ảnh. Sau đó sử dụng các đặc trưng này để đưa ra dự đoán về các đối tượng trong hình ảnh.
>> Xem thêm:
- Xây dựng ứng dụng phát hiện đối tượng bằng Python chỉ trong vài phút với Roboflow
- Phát hiện đối tượng trong video
Các lớp trong Mạng nơ-ron tích chập
Trong phần này, chúng ta sẽ cung cấp một cái nhìn tổng quan chi tiết về các lớp thường được sử dụng trong việc xây dựng kiến trúc mạng nơ-ron tích chập (CNN). Chúng ta sẽ tìm hiểu các loại lớp khác nhau cấu thành nên CNN: lớp pooling, lớp kích hoạt, lớp chuẩn hóa lô, lớp dropout và lớp phân loại.
Lớp Pooling
Lớp Pooling (lớp gộp), tương tự như lớp tích chập đã đề cập trước đó, có nhiệm vụ giảm kích thước không gian của các đặc trưng sau khi được tích chập trong CNN.
Việc giảm kích thước không gian này được thực hiện thông qua quá trình down-sampling (lấy mẫu xuống) các đặc trưng đã tích chập. Cách làm này phục vụ hai mục đích chính: vừa giảm lượng tài nguyên tính toán cần thiết để xử lý dữ liệu, vừa giúp tăng mức độ trừu tượng của các đặc trưng được học.
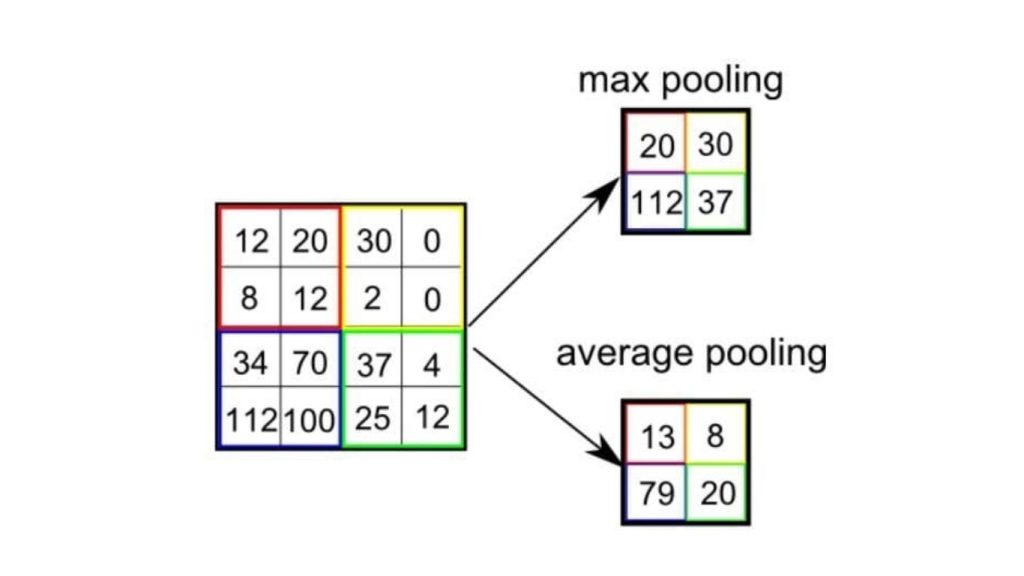
Trong CNN, có hai kỹ thuật pooling phổ biến nhất là average pooling (gộp trung bình) và max pooling (gộp cực đại).
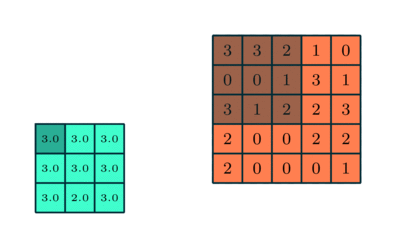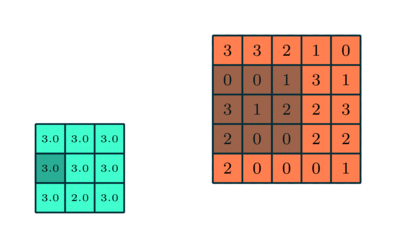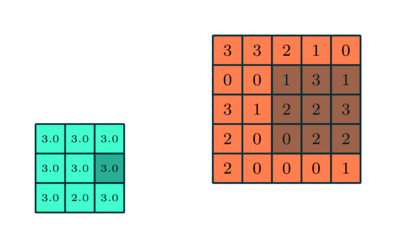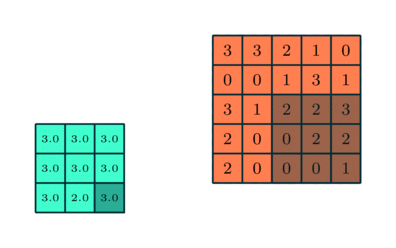
Phương pháp gộp cực đại giúp giảm kích thước không gian của các đặc trưng đã được tích chập thông qua quá trình down-sampling (lấy mẫu xuống). Cơ chế hoạt động của nó là chọn giá trị lớn nhất của pixel trong một vùng của hình ảnh được bộ lọc bao phủ.
Kỹ thuật này không chỉ giúp giảm lượng tài nguyên tính toán cần thiết để xử lý dữ liệu mà còn đóng vai trò như một bộ lọc nhiễu giúp loại bỏ các kích hoạt nhiễu và thực hiện quá trình giảm nhiễu cùng với giảm chiều.
Ngược lại, phương pháp gộp trung bình trả về giá trị trung bình của tất cả các pixel trong vùng hình ảnh được bộ lọc bao phủ. Mặc dù kỹ thuật này cũng giúp giảm chiều dữ liệu, nhưng nó không có khả năng loại bỏ nhiễu hiệu quả như phương pháp gộp cực đại.
Vì vậy trong thực tế, phương pháp gộp cực đại thường được xem là hiệu quả và ổn định hơn, mang lại hiệu năng tốt hơn so với phương pháp gộp trung bình. Việc lựa chọn giữa hai kỹ thuật này phụ thuộc chủ yếu vào yêu cầu cụ thể của bài toán cũng như mức độ nhiễu của tập dữ liệu.
Lớp hàm kích hoạt
Lớp hàm kích hoạt giúp mạng học được các mối quan hệ phi tuyến giữa đầu vào và đầu ra. Lớp này có nhiệm vụ đưa tính phi tuyến vào mạng, từ đó cho phép mô hình biểu diễn và học các mẫu cũng như mối quan hệ phức tạp trong dữ liệu.
Hàm kích hoạt thường được áp dụng lên đầu ra của mỗi nơ-ron trong mạng. Nó nhận vào tổng có trọng số của các đầu vào và tạo ra một giá trị đầu ra, sau đó được truyền sang lớp tiếp theo.
Các hàm kích hoạt được sử dụng phổ biến nhất trong mạng nơ-ron tích chập bao gồm:
- Đơn vị tuyến tính chỉnh lưu (Rectified linear unit – ReLU)
- Sigmoid
- Hàm tang hyperbol (Hyperbolic tangent – tanh)
ReLU là lựa chọn phổ biến trong CNN vì có hiệu quả tính toán cao và thường tạo ra các biểu diễn thưa cho dữ liệu đầu vào. Hàm này trả về chính giá trị đầu vào nếu giá trị đó là dương, và trả về 0 nếu giá trị đó là âm.
Sigmoid và tanh cũng là các hàm phi tuyến, tuy nhiên chúng ít được sử dụng hơn trong CNN vì có thể tạo ra gradient (độ dốc) gần bằng 0 khi giá trị đầu vào lớn, gây khó khăn cho quá trình huấn luyện.
Lớp hàm kích hoạt có thể được xem như “bộ não” của CNN, nơi dữ liệu đầu vào được biến đổi thành các biểu diễn có ý nghĩa. Đây là một thành phần nền tảng và không thể thiếu của mạng.
Lớp chuẩn hóa theo batch
Lớp Batch Normalization – BN (chuẩn hóa theo lô) thường được sử dụng trong CNN nhằm chuẩn hóa đầu vào của mỗi nơ-ron sao cho có giá trị trung bình bằng 0 và phương sai bằng 1. Điều này giúp quá trình học trở nên ổn định hơn và ngăn chặn vấn đề dịch chuyển hiệp biến nội bộ – hiện tượng xảy ra khi phân phối của dữ liệu đầu vào của một lớp thay đổi trong suốt quá trình huấn luyện.
BN chuẩn hóa đầu ra của mỗi nơ-ron dựa trên giá trị trung bình và độ lệch chuẩn của một batch dữ liệu đầu vào, và thường được áp dụng sau lớp tích chập và lớp kết nối đầy đủ.
Lớp chuẩn hóa theo lô mang lại nhiều tác động tích cực cho CNNs, bao gồm:
- BN có thể tăng tốc quá trình huấn luyện bằng cách giảm hiện tượng sự dịch chuyển hiệp biến nội bộ và cho phép sử dụng tốc độ học cao hơn.
- BN giúp điều chuẩn mô hình, làm cho mô hình ít bị quá khớp hơn.
- BN đã được chứng minh là có thể cải thiện khả năng khái quát hóa của CNNs, giúp mô hình đạt hiệu quả tốt hơn trên dữ liệu chưa từng thấy.
- BN giúp giảm số lượng siêu tham số cần tinh chỉnh, chẳng hạn như tốc độ học, từ đó đơn giản hóa quá trình huấn luyện và cải thiện khả năng tổng quát hóa.
- BN cho phép mô hình ít nhạy cảm hơn với giá trị khởi tạo ban đầu của trọng số.
Tóm lại, chuẩn hóa theo lô là một kỹ thuật mạnh mẽ và được sử dụng rộng rãi trong CNNs nhằm ổn định quá trình học và nâng cao hiệu suất của mô hình. Bằng cách chuẩn hóa đầu vào của mỗi nơ-ron, BN giúp giảm sự dịch chuyển hiệp biến nội bộ và điều chuẩn mô hình, từ đó mang lại khả năng khái quát hóa tốt hơn.
>>> Xem thêm: Hướng dẫn triển khai AI trong ứng dụng di động đơn giản

Lớp Dropout (Dropout Layer)
Lớp dropout sử dụng một kỹ thuật điều chuẩn nhằm ngăn chặn hiện tượng quá khớp. Cơ chế hoạt động của lớp này là ngẫu nhiên đặt một tỷ lệ các đơn vị đầu vào về 0 trong mỗi vòng lặp huấn luyện, qua đó “loại bỏ tạm thời” các nơ-ron và ngăn chúng tham gia vào quá trình lan truyền xuôi.
Quá trình này buộc mạng phải học nhiều biểu diễn độc lập của dữ liệu đầu vào, giúp mô hình trở nên bền vững hơn trước những thay đổi của dữ liệu và làm giảm nguy cơ xảy ra quá khớp. Dropout thường được áp dụng cho các lớp kết nối đầy đủ trong CNN, nhưng về mặt nguyên tắc, kỹ thuật này có thể được sử dụng cho bất kỳ lớp nào.
Ý tưởng về dropout được lấy cảm hứng từ câu chuyện của Hinton và ngân hàng của ông:
“Tôi đến ngân hàng của mình và nhận thấy các giao dịch viên liên tục thay đổi. Khi hỏi lý do, một người trong số họ cho biết anh ta cũng không rõ, chỉ biết rằng họ thường xuyên bị luân chuyển vị trí. Tôi cho rằng điều này là vì nếu muốn gian lận ngân hàng thành công thì cần có sự phối hợp của nhiều nhân viên. Từ đó, tôi nhận ra rằng việc ngẫu nhiên loại bỏ các tập con nơ-ron khác nhau ở mỗi ví dụ huấn luyện sẽ ngăn chặn sự ‘thông đồng’ giữa chúng và qua đó làm giảm hiện tượng quá khớp.”
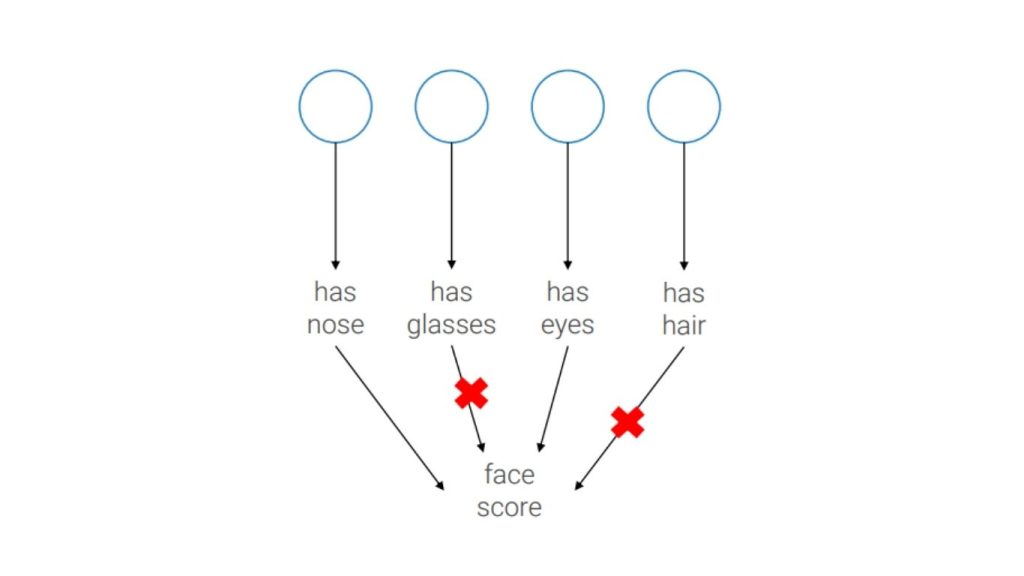
Giả sử chúng ta muốn phát hiện khuôn mặt. Trên thực tế, khuôn mặt không phải lúc nào cũng có đầy đủ các đặc điểm như mũi, mắt, miệng,… mà có thể bị che khuất một phần. Ví dụ, ta muốn huấn luyện mạng nơ-ron để nhận diện cả những khuôn mặt bị che một mắt.
Vì vậy, việc không để tất cả các đặc trưng đồng thích nghi với nhau mà thay vào đó học ngẫu nhiên một tập con các đặc trưng sẽ giúp mô hình khái quát hóa tốt hơn trên dữ liệu chưa từng thấy và buộc bộ phát hiện khuôn mặt vẫn hoạt động ngay cả khi chỉ có một số đặc điểm xuất hiện.
>> Tham khảo: Mẹo tạo prompt cho LLM trong thị giác máy tính để tăng độ chính xác
Lớp phân loại (Classification Layer)
Lớp phân loại là lớp cuối cùng trong một mạng nơ-ron tích chập, có nhiệm vụ tạo ra các điểm số lớp cho hình ảnh đầu vào. Trong CNN, hai loại lớp phân loại được sử dụng phổ biến nhất là lớp kết nối đầy đủ và lớp gộp trung bình toàn cục (global average pooling – GAP).
Lớp kết nối đầy đủ (Fully Connected – FC) là một lớp mạng nơ-ron tiêu chuẩn, trong đó tất cả các nơ-ron của lớp trước đều được kết nối với toàn bộ các nơ-ron ở lớp hiện tại. Đầu ra của lớp FC được tính bằng cách áp dụng ma trận trọng số và vector độ lệch lên dữ liệu đầu vào, sau đó đưa qua một hàm kích hoạt. Trong các bài toán phân loại, lớp FC thường được kết hợp với hàm kích hoạt softmax để tạo ra các điểm số phân loại.
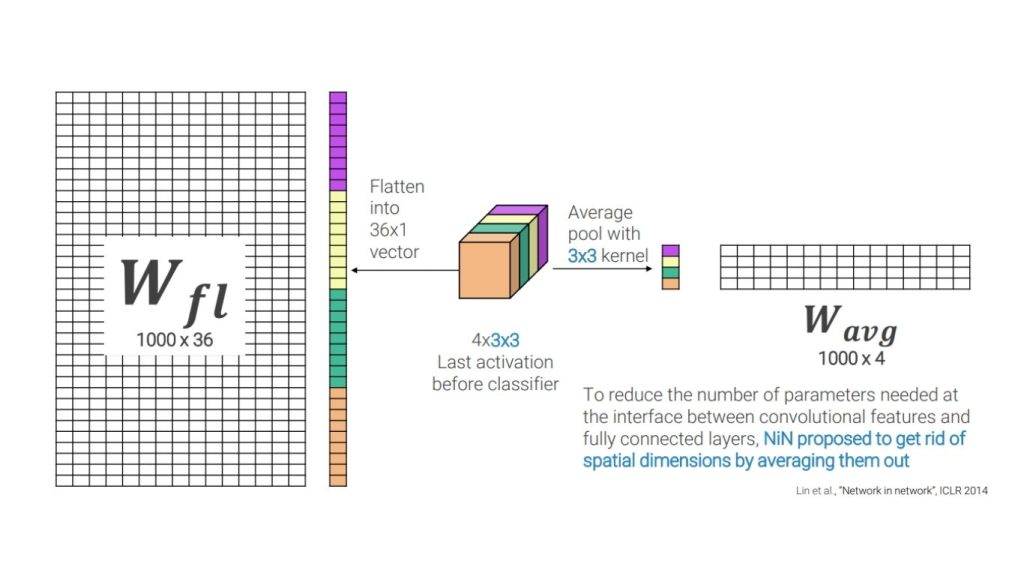
Ưu điểm của lớp kết nối đầy đủ là cho phép mạng học được các ranh giới quyết định phức tạp giữa các lớp. Tuy nhiên, loại lớp này yêu cầu số lượng tham số lớn và do đó dễ dẫn đến hiện tượng quá khớp. Để khắc phục những hạn chế này, lớp gộp trung bình toàn cục (GAP) đã được đề xuất.
Lớp gộp trung bình toàn cục là một dạng lớp pooling giúp giảm kích thước không gian của các bản đồ đặc trưng bằng cách lấy giá trị trung bình của từng bản đồ đặc trưng. Đầu ra của lớp GAP là một vector một chiều (1D) có kích thước tương ứng với số lượng bản đồ đặc trưng. Vector này sau đó được đưa vào một lớp kết nối đầy đủ (FC) kèm theo hàm kích hoạt softmax để tạo ra các điểm số phân loại.
Ưu điểm của lớp GAP là cần ít tham số hơn và ít bị ảnh hưởng bởi hiện tượng quá khớp. Tuy nhiên, nhược điểm của nó là không cho phép mạng học được các ranh giới quyết định quá phức tạp giữa các lớp.
Tóm lại, lớp kết nối đầy đủ phù hợp với việc học các ranh giới quyết định phức tạp nhưng đòi hỏi nhiều tham số và dễ dẫn đến quá khớp, trong khi lớp gộp trung bình toàn cục (GAP) giúp giảm nguy cơ quá khớp và số lượng tham số, nhưng bị hạn chế hơn trong khả năng học các ranh giới quyết định phức tạp.
>> Xem thêm: Ứng dụng nhận dạng cử chỉ với Vision AI
Các mô hình mạng nơ-ron tích chập phổ biến
Hãy cùng thảo luận về một số cách triển khai mạng nơ-ron tích chập phổ biến, bao gồm cả các mô hình CNN đời đầu và các mô hình hiện đại hơn.
LeNet
LeNet lần đầu tiên được đề xuất bởi Yann LeCun vào năm 1998 để phục vụ bài toán nhận dạng chữ số viết tay. Đây được xem là một trong những CNN thành công sớm nhất và là nền tảng cho nhiều kiến trúc CNN ra đời sau này.
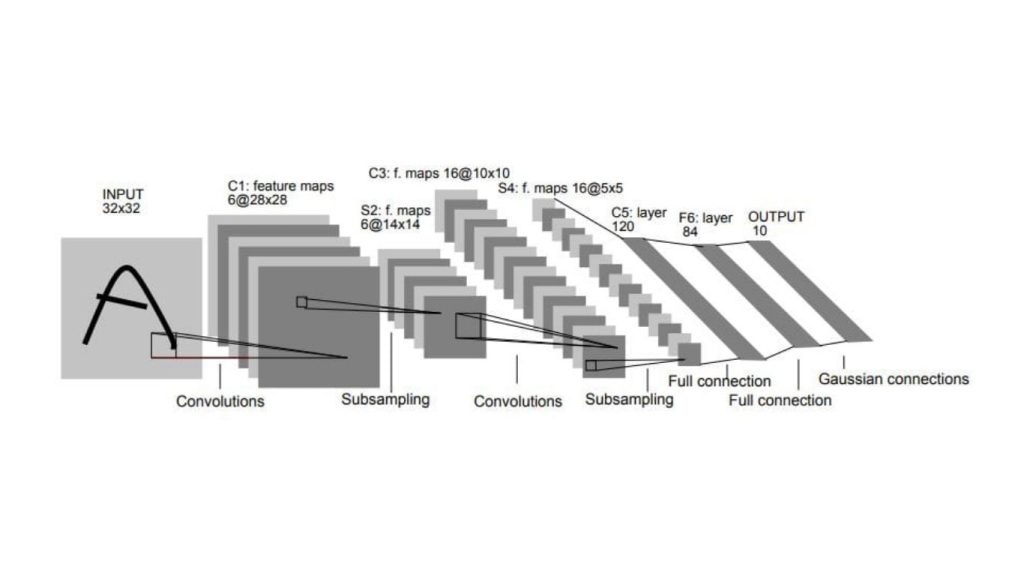
Kiến trúc của LeNet bao gồm nhiều lớp, cụ thể:
- Hai lớp tích chập, mỗi lớp được theo sau bởi một lớp gộp cực đại (max-pooling layer), dùng để trích xuất đặc trưng từ hình ảnh đầu vào.
- Hai lớp kết nối đầy đủ, còn được gọi là lớp dày đặc, dùng để phân loại các đặc trưng.
Lớp tích chập thứ nhất có 6 bộ lọc với kích thước 5×5, và lớp tích chập thứ hai có 16 bộ lọc với kích thước 5×5. Lớp max-pooling giúp giảm kích thước không gian của các bản đồ đặc trưng bằng cách lấy giá trị lớn nhất trong mỗi cửa sổ kích thước 2×2.
Lớp kết nối đầy đủ đầu tiên có 120 và lớp kết nối đầy đủ thứ hai có 84 nơ-ron. Lớp cuối cùng là một lớp kết nối đầy đủ gồm 10 nơ-ron, tương ứng với mỗi lớp chữ số.
LeNet là một kiến trúc tương đối đơn giản nhưng vẫn được sử dụng cho đến ngày nay như một điểm khởi đầu cho nhiều bài toán phân loại hình ảnh (image classification). Tuy nhiên, LeNet không mạnh mẽ bằng nhiều kiến trúc hiện đại ngày nay.
AlexNet
AlexNet được đề xuất bởi Alex Krizhevsky, Ilya Sutskever và Geoffrey Hinton vào năm 2012. Đây là mô hình chiến thắng trong cuộc thi ImageNet Large Scale Visual Recognition Challenge (ILSVRC) năm 2012. AlexNet là CNN đầu tiên vượt qua hiệu năng của các mô hình truyền thống được thiết kế thủ công trên bộ chuẩn này.
Kiến trúc của AlexNet bao gồm nhiều lớp, cụ thể:
- Năm lớp tích chập, mỗi lớp được theo sau bởi một lớp max-pooling, dùng để trích xuất đặc trưng từ hình ảnh đầu vào.
- Ba lớp kết nối đầy đủ, dùng để phân loại đặc trưng.
Hai lớp tích chập đầu tiên có 96 bộ lọc kích thước 11×11, hai lớp tích chập tiếp theo có 256 bộ lọc kích thước 5×5, và lớp tích chập cuối cùng có 384 bộ lọc kích thước 3×3. Lớp max-pooling giảm kích thước không gian của các bản đồ đặc trưng bằng cách lấy giá trị lớn nhất trong mỗi cửa sổ 2×2.
Lớp kết nối đầy đủ thứ nhất có 4096 nơ-ron, lớp thứ hai cũng có 4096 nơ-ron, và lớp cuối cùng là một lớp kết nối đầy đủ gồm 1000 nơ-ron, tương ứng với mỗi lớp trong tập dữ liệu ImageNet.
AlexNet đã giới thiệu nhiều cải tiến quan trọng giúp đạt được hiệu năng tiên tiến nhất tại thời điểm đó, chẳng hạn như việc sử dụng hàm kích hoạt ReLU, tăng cường dữ liệu và điều chuẩn dropout. So với LeNet, AlexNet có dung lượng mô hình lớn hơn nhiều và có khả năng học các đặc trưng phức tạp hơn từ hình ảnh.
Tại thời điểm ra mắt, AlexNet được xem là một bước đột phá trong lĩnh vực thị giác máy tính và đã truyền cảm hứng cho nhiều kiến trúc ra đời sau này.
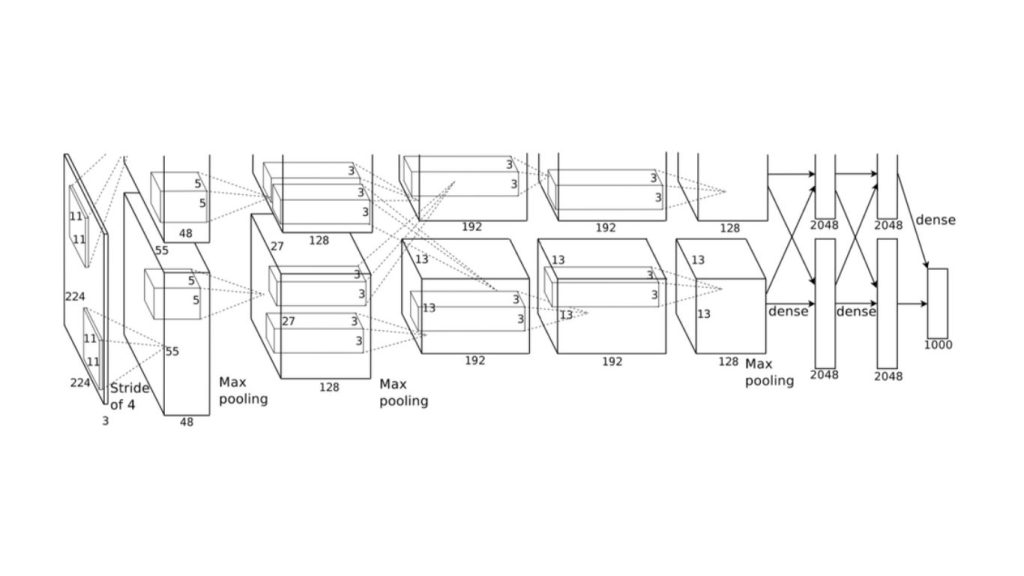
VGGNet
VGGNet là một kiến trúc mạng nơ-ron tích chập được phát triển bởi Visual Geometry Group (VGG) tại Đại học Oxford. Mô hình được giới thiệu trong một bài báo năm 2014 của Karen Simonyan và Andrew Zisserman, và đã giành chiến thắng tại cuộc thi ILSVRC-2014.
VGGNet nổi tiếng nhờ sự đơn giản trong thiết kế nhưng vẫn đạt hiệu năng cao trong các bài toán phân loại hình ảnh. Kiến trúc của VGGNet bao gồm một chuỗi các lớp tích chập và max-pooling, theo sau là các lớp kết nối đầy đủ. Đặc điểm then chốt của VGGNet là việc sử dụng các bộ lọc tích chập rất nhỏ (3×3) kết hợp với kiến trúc rất sâu (lên tới 19 lớp).
Kiến trúc này sau đó đã được điều chỉnh và sử dụng làm backbone cho nhiều tác vụ thị giác máy tính khác nhau như phát hiện đối tượng và phân đoạn hình ảnh.
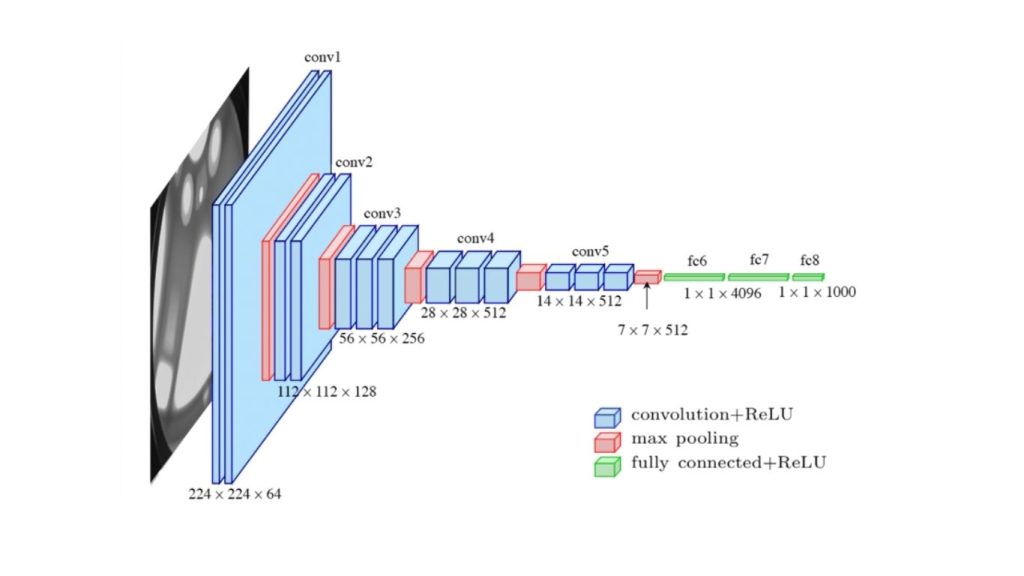
ResNet
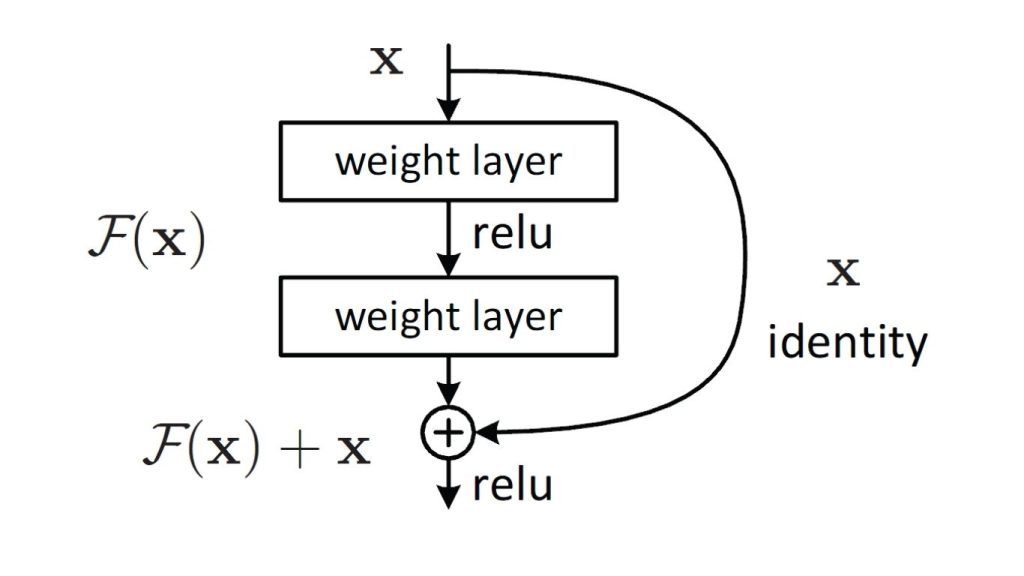
Một trong những thách thức lớn khi huấn luyện sâu các mạng nơ-ron (deep neural networks) là vấn đề tiêu biến gradient, trong đó gradient (được dùng để cập nhật tham số trong quá trình huấn luyện) trở nên rất nhỏ, khiến việc huấn luyện chậm và kém hiệu quả. ResNet (Residual Neural Network), được phát triển bởi Microsoft Research vào năm 2015, giúp giải quyết vấn đề này bằng cách giới thiệu khái niệm kết nối dư (residual connections).
Một kết nối dư là một kết nối tắt (shortcut connection) cho phép bỏ qua một hoặc nhiều lớp, giúp gradient truyền trực tiếp về các lớp trước đó. Nhờ vậy, ResNet có thể huấn luyện các mạng sâu hơn nhiều so với các kiến trúc trước mà không gặp phải vấn đề tiêu biến gradient.
Các kiến trúc ResNet được phân biệt chủ yếu dựa trên độ sâu. ResNet nguyên bản có 152 lớp. Các phiên bản phổ biến hơn như ResNet-50, ResNet-101 và ResNet-152 lần lượt có 50, 101 và 152 lớp. ResNet đã trở thành lựa chọn phổ biến làm kiến trúc nền cho nhiều tác vụ thị giác máy tính như phát hiện đối tượng, phân đoạn ngữ nghĩa và phân loại hình ảnh.
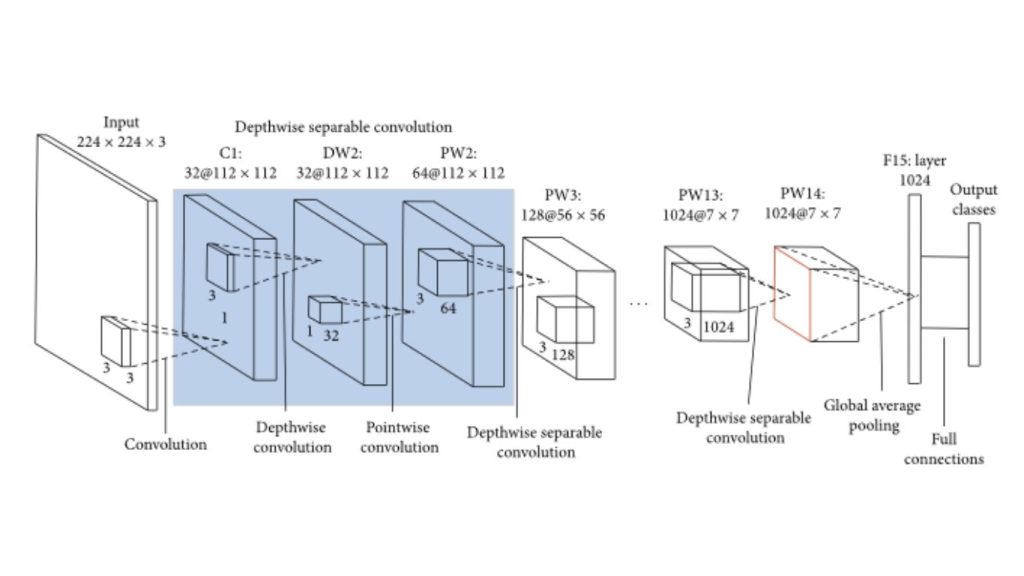
MobileNet
Mô hình MobileNet, do Google phát triển vào năm 2017, được thiết kế chuyên biệt cho các thiết bị di động và thiết bị nhúng có tài nguyên tính toán hạn chế. MobileNet sử dụng tích chập phân tách theo chiều sâu nhằm giảm số lượng tham số và chi phí tính toán, đồng thời vẫn duy trì độ chính xác tốt.
Một tích chập phân tách theo chiều sâu áp dụng một bộ lọc tích chập riêng cho mỗi kênh đầu vào, sau đó sử dụng tích chập điểm (tích chập 1×1) để kết hợp các kết quả. Cách tiếp cận này giúp giảm đáng kể số lượng tham số và phép tính so với các lớp tích chập tiêu chuẩn.
Kiến trúc MobileNet được thiết kế theo hướng nhẹ và hiệu quả, do đó rất phù hợp để triển khai trên các thiết bị di động và thiết bị nhúng có bộ nhớ và năng lực xử lý hạn chế.
Mô hình có nhiều phiên bản với mức độ phức tạp và độ chính xác khác nhau. MobileNet V1, V2 và V3 là các phiên bản phổ biến nhất. Phiên bản mới nhất, MobileNet V3, được xem là hiệu quả nhất, đạt sự cân bằng tốt giữa độ chính xác và hiệu năng.
MobileNet đã được sử dụng trong nhiều ứng dụng khác nhau như phát hiện đối tượng, phân đoạn ngữ nghĩa và phân loại hình ảnh, đồng thời cũng được dùng làm kiến trúc nền cho nhiều tác vụ thị giác máy tính như nhận diện khuôn mặt, theo dõi đối tượng và nhiều ứng dụng khác.
>>> Tham khảo thêm:
- Phrase Grounding là gì? Mô hình và cách hoạt động
- Visual Question Answering là gì? Mô hình và Phương pháp hoạt động
- LLM là gì? Mô hình ngôn ngữ lớn và cách chúng hoạt động
Kết luận
Mạng nơ-ron tích chập (Convolutional Neural Networks – CNNs) là một dạng kiến trúc học sâu được sử dụng rộng rãi trong các bài toán thị giác máy tính như phân loại hình ảnh, phát hiện đối tượng và phân đoạn ngữ nghĩa. So với các phương pháp thị giác máy tính truyền thống, CNNs sở hữu nhiều ưu điểm nổi bật, bao gồm:
- Khả năng bền vững trước tịnh tiến và xoay: CNNs có thể học các đặc trưng ít nhạy cảm với những thay đổi nhỏ về vị trí và hướng của đối tượng trong ảnh, nhờ đó rất phù hợp cho các bài toán phát hiện đối tượng và phân đoạn ngữ nghĩa.
- Khả năng xử lý dữ liệu quy mô lớn: CNNs có thể học hiệu quả từ các tập dữ liệu lớn, do đó đặc biệt phù hợp để huấn luyện trên những bộ dữ liệu có quy mô lớn như ImageNet.
- Học chuyển giao: Các mô hình CNN được huấn luyện trước trên các tập dữ liệu lớn như ImageNet có thể được tinh chỉnh (fine-tune) trên những tập dữ liệu nhỏ hơn, giúp giảm đáng kể lượng dữ liệu và tài nguyên tính toán cần thiết cho từng tác vụ cụ thể.
Bên cạnh những ưu điểm, CNNs cũng tồn tại một số hạn chế và thách thức, bao gồm:
- Chi phí tính toán: Việc huấn luyện và triển khai CNNs đòi hỏi tài nguyên tính toán lớn, điều này có thể trở thành rào cản đối với các thiết bị di động và thiết bị nhúng.
- Hiện tượng quá khớp: Khi dữ liệu huấn luyện hạn chế, CNNs dễ bị quá khớp, dẫn đến hiệu suất kém trên dữ liệu chưa từng xuất hiện trong quá trình huấn luyện.
- Khả năng giải thích: CNNs thường được xem như các “hộp đen”, khiến việc hiểu rõ cách mô hình đưa ra quyết định cũng như xác định các lỗi tiềm ẩn trở nên khó khăn hơn.
>>> Nguồn tham khảo: What is a Convolutional Neural Network?
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ:31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam







