
Trong bối cảnh các mối đe dọa kỹ thuật số ngày càng tinh vi, việc ứng dụng trí tuệ nhân tạo không còn là lựa chọn mà đã trở thành yêu cầu cấp thiết. Anthropic đã đánh dấu một bước ngoặt mới khi tối ưu hóa Claude Sonnet 4.5 trở thành công cụ AI phòng thủ an ninh mạng đắc lực, vượt trội hơn các thế hệ tiền nhiệm trong việc phát hiện và khắc phục lỗ hổng. Bài viết này sẽ đi sâu vào những tiến bộ vượt bậc của Claude trong việc hỗ trợ các chuyên gia bảo mật bảo vệ hệ thống trước những cuộc tấn công phức tạp nhất hiện nay, cùng TOT tìm hiểu ngay!
>>> Tìm hiểu thêm:
- AI tạo sinh là gì? Cách hoạt động và Ứng dụng thực tế
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- Predictive AI là gì? Cách AI dự đoán hành vi và xu hướng tương lai
- Ứng dụng AI trong bán hàng online: TOP 10 công cụ AI & cách triển khai hiệu quả
Mở đầu
Các mô hình AI hiện đã có thể hỗ trợ những nhiệm vụ an ninh mạng trong thực tế, không chỉ dừng ở lý thuyết. Khi các nghiên cứu và kinh nghiệm đã chứng minh tính hữu dụng của các mô hình AI tiên tiến như một công cụ cho các kẻ tấn công mạng, Anthropic cho biết họ đã đầu tư vào việc nâng cao khả năng của Claude để hỗ trợ các chuyên gia phòng thủ phát hiện, phân tích và khắc phục lỗ hổng trong mã nguồn cũng như các hệ thống đang vận hành.
Nhờ nỗ lực này, Claude Sonnet 4.5 có thể đạt hoặc vượt hiệu năng của Opus 4.1 – một mô hình tiên tiến được Anthropic ra mắt chỉ hai tháng trước, nổi bật trong việc phát hiện lỗ hổng mã nguồn và thực hiện các nhiệm vụ liên quan đến an ninh mạng. Công ty cho rằng việc áp dụng và thử nghiệm AI sẽ trở thành yếu tố quan trọng để các chuyên gia phòng thủ theo kịp tốc độ phát triển của các mối đe dọa.
Anthropic nhận định rằng AI đang ở một bước ngoặt quan trọng về tác động đối với an ninh mạng.
Trong vài năm qua, đội ngũ nghiên cứu của Anthropic đã theo dõi sát sao các năng lực liên quan đến an ninh mạng của các mô hình AI. Ban đầu, các mô hình này chưa thể hiện sức mạnh đáng kể trong những năng lực phức tạp. Tuy nhiên, khoảng một năm trở lại đây, công ty bắt đầu quan sát thấy sự thay đổi rõ rệt. Ví dụ:
- Các nhà nghiên cứu đã chứng minh rằng mô hình AI có thể tái hiện trong mô phỏng một trong những vụ tấn công mạng tốn kém nhất lịch sử – vụ rò rỉ dữ liệu Equifax năm 2017.
- Claude đã được đưa vào các cuộc thi an ninh mạng và trong một số trường hợp đã vượt trội hơn các đội ngũ con người.
- Claude cũng đã giúp Anthropic phát hiện các lỗ hổng trong chính mã nguồn của họ và khắc phục chúng trước khi phát hành.
Trong cuộc thi DARPA AI Cyber Challenge mùa hè này, các đội thi đã sử dụng các mô hình ngôn ngữ lớn (LLM), bao gồm Claude, để xây dựng các “hệ thống suy luận an ninh mạng” có khả năng phân tích hàng triệu dòng mã nhằm tìm ra lỗ hổng bảo mật và vá lỗi.
Ngoài các lỗ hổng được cố ý cài vào, các đội còn phát hiện (và đôi khi vá) những lỗ hổng bảo mật chưa từng được phát hiện trước đó, không phải do tổng hợp nhân tạo. Ngoài bối cảnh thi đấu, nhiều phòng thí nghiệm AI tiên tiến cũng đang áp dụng mô hình AI để phát hiện và báo cáo các lỗ hổng mới.
Song song đó, trong quá trình triển khai hệ thống Bảo vệ An ninh (Safeguards), Anthropic cũng đã phát hiện và ngăn chặn các tác nhân đe dọa lợi dụng AI để mở rộng quy mô hoạt động của họ.
Gần đây, đội ngũ Bảo vệ An ninh của Anthropic đã phát hiện và ngăn chặn một trường hợp được gọi là “vibe hacking”, trong đó một tội phạm mạng sử dụng Claude để xây dựng một mô hình tống tiền dữ liệu quy mô lớn – một hoạt động trước đây thường cần cả một đội người thực hiện. Nhóm này cũng phát hiện việc Claude bị lợi dụng trong các chiến dịch gián điệp ngày càng phức tạp, bao gồm việc nhắm mục tiêu vào hạ tầng viễn thông quan trọng, với các dấu hiệu tương đồng với hoạt động của các nhóm APT có liên hệ với Trung Quốc.
Theo Anthropic, những bằng chứng này cho thấy hệ sinh thái an ninh mạng đang bước vào một giai đoạn chuyển đổi quan trọng, nơi tốc độ tiến bộ và mức độ ứng dụng AI có thể tăng rất nhanh.
Vì vậy, công ty cho rằng đây là thời điểm cần tăng tốc việc ứng dụng AI cho mục đích phòng thủ, nhằm bảo vệ mã nguồn và cơ sở hạ tầng số. Anthropic nhấn mạnh rằng lợi thế từ AI trong lĩnh vực an ninh mạng không nên rơi vào tay các tác nhân tấn công hay tội phạm.
Bên cạnh việc tiếp tục phát hiện và ngăn chặn các hành vi lạm dụng, công ty tin rằng giải pháp có khả năng mở rộng tốt nhất là xây dựng các hệ thống AI hỗ trợ những người bảo vệ môi trường số, như đội ngũ bảo mật doanh nghiệp và chính phủ, các nhà nghiên cứu an ninh mạng và những người duy trì các dự án mã nguồn mở quan trọng.
Trong quá trình chuẩn bị ra mắt Claude Sonnet 4.5, Anthropic cho biết họ đã bắt đầu thực hiện mục tiêu này.
>> Xem thêm:
- Mẹo tạo prompt cho LLM trong thị giác máy tính để tăng độ chính xác
- LLMs.txt là gì? Có nên sử dụng không?
- Low Code là gì? Giải pháp phát triển phần mềm và xu hướng tương lai
Claude Sonnet 4.5: Nâng cao kỹ năng an ninh mạng
Khi các mô hình ngôn ngữ lớn (LLMs) ngày càng phát triển về quy mô, những “khả năng phát sinh” – những kỹ năng không thấy ở các mô hình nhỏ hơn và không nhất thiết được huấn luyện trực tiếp, bắt đầu xuất hiện. Theo Anthropic, khả năng của Claude trong các nhiệm vụ an ninh mạng như phát hiện và khai thác lỗ hổng phần mềm trong các thử thách Capture-the-Flag (CTF), ban đầu chỉ là tác dụng phụ của quá trình phát triển trợ lý AI đa năng.
Tuy nhiên, công ty cho biết họ không muốn chỉ dựa vào sự tiến bộ chung của mô hình để hỗ trợ các chuyên gia phòng thủ. Trước tính cấp bách của bối cảnh hiện tại, Anthropic đã dành riêng các nhà nghiên cứu để cải thiện những kỹ năng cốt lõi, như phát hiện và vá lỗ hổng trong mã nguồn.
Kết quả của nỗ lực này được thể hiện trong Claude Sonnet 4.5, một mô hình được đánh giá tương đương hoặc vượt trội Opus 4.1 trong nhiều nhiệm vụ an ninh mạng, đồng thời có chi phí thấp hơn và tốc độ nhanh hơn.
>> Tham khảo thêm:
- AI trong thiết kế UI/UX: Sức mạnh của Generative AI
- Ứng dụng AI trong bán hàng online: TOP 10 công cụ AI miễn phí & cách triển khai hiệu quả

Bằng chứng từ các đánh giá
Trong quá trình phát triển Sonnet 4.5, một nhóm nghiên cứu nhỏ của Anthropic tập trung nâng cao khả năng của Claude trong việc phát hiện lỗ hổng trong các kho mã nguồn, vá các lỗ hổng đó và kiểm tra điểm yếu trong hạ tầng an ninh mạng mô phỏng.
Những nhiệm vụ này được lựa chọn vì phản ánh các công việc quan trọng mà các bên phòng thủ thường phải thực hiện. Đồng thời, nhóm nghiên cứu cũng chủ động tránh những cải tiến có thể rõ ràng phục vụ cho mục đích tấn công, chẳng hạn như khai thác lỗ hổng ở mức nâng cao hoặc viết mã độc.
Mục tiêu là giúp các mô hình có thể phát hiện mã nguồn không an toàn trước khi triển khai, cũng như tìm và khắc phục các lỗ hổng trong những hệ thống đã đi vào vận hành. Tất nhiên, vẫn còn nhiều nhiệm vụ an ninh quan trọng khác chưa được tập trung trong giai đoạn này. Các hướng phát triển tiếp theo sẽ được đề cập ở phần cuối bài viết.
Anthropic cũng thực hiện các bài đánh giá chuẩn trong ngành để đo lường tiến bộ của mô hình. Những đánh giá này cho phép so sánh rõ ràng giữa các mô hình khác nhau, đo lường tốc độ tiến bộ của AI và đặc biệt trong trường hợp các bài đánh giá mới do bên ngoài phát triển, chúng cung cấp một thước đo đáng tin cậy để đảm bảo rằng mô hình không chỉ được huấn luyện nhằm tối ưu cho các bài kiểm tra nội bộ.
Một điểm đáng chú ý trong quá trình đánh giá là tầm quan trọng của việc chạy thử nghiệm nhiều lần. Mặc dù điều này có thể tốn kém về mặt tính toán khi áp dụng cho một tập lớn các nhiệm vụ đánh giá, nhưng nó phản ánh chính xác hơn cách một tác nhân tấn công hoặc phòng thủ có động lực sẽ tiếp cận một vấn đề thực tế – tức là thử nhiều phương án khác nhau cho cùng một bài toán. Cách tiếp cận này cho thấy hiệu năng ấn tượng không chỉ của Claude Sonnet 4.5, mà còn của một số mô hình thuộc các thế hệ trước đó.
>> Tham khảo:
- So sánh Low-Code và No-Code: Hiểu đúng bản chất & Ứng dụng trong doanh nghiệp
- Khả năng thị giác của Chat GPT-5 và Cách Prompt hiệu quả
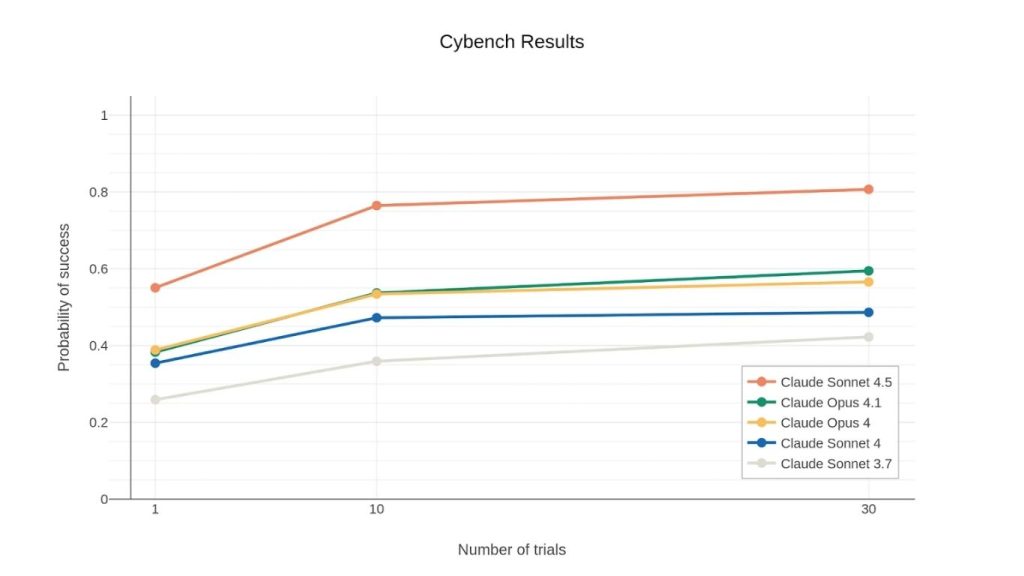
Cybench
Một trong những bộ đánh giá mà Anthropic theo dõi hơn một năm là Cybench, một benchmark dựa trên các thử thách từ các cuộc thi CTF.
Trong đánh giá này, Claude Sonnet 4.5 cho thấy sự cải thiện rõ rệt, không chỉ so với Sonnet 4 mà còn vượt cả Opus 4 và Opus 4.1. Đáng chú ý, Sonnet 4.5 có xác suất thành công cao hơn Opus 4.1 chỉ với một lần thử, trong khi Opus cần tới 10 lần thử.
Các thử thách trong Cybench thường yêu cầu các quy trình phức tạp và kéo dài. Ví dụ, một thử thách yêu cầu:
- Phân tích lưu lượng mạng
- Trích xuất mã độc từ dữ liệu đó
- Giải biên dịch và giải mã mã độc
Anthropic ước tính một chuyên gia con người có thể mất ít nhất một giờ để hoàn thành nhiệm vụ này, trong khi Claude giải quyết trong 38 phút.
Khi được phép thử 10 lần cho mỗi nhiệm vụ, Sonnet 4.5 giải thành công 76,5% thử thách. Đáng chú ý, tỷ lệ thành công này đã tăng gấp đôi chỉ trong sáu tháng, so với Claude 3.7 Sonnet (ra mắt tháng 2/2025) chỉ đạt 35,9%.
>> Xem thêm: Tìm hiểu về các phiên bản và quá trình phát triển của mô hình YOLO
CyberGym
Trong một đánh giá khác do bên ngoài phát triển là CyberGym, Claude Sonnet 4.5 được thử nghiệm trên hai nhiệm vụ:
- Phát hiện các lỗ hổng bảo mật đã biết được phát hiện trước đó trong các dự án phần mềm nguồn mở thực tế dựa trên mô tả tổng quan về lỗ hổng
- Phát hiện các lỗ hổng mới chưa từng được phát hiện
Đội ngũ CyberGym trước đây đã phát hiện ra rằng Claude Sonnet 4 là mô hình mạnh nhất trên bảng xếp hạng công khai của họ.
Kết quả cho thấy Claude Sonnet 4.5 vượt đáng kể Claude Sonnet 4 và Claude Opus 4.
Với cùng giới hạn chi phí như bảng xếp hạng công khai của CyberGym (2 USD truy vấn API cho mỗi lỗ hổng), Sonnet 4.5 đạt 28,9%, thiết lập mức hiệu năng cao nhất mới.
Tuy nhiên, trong thực tế, kẻ tấn công hiếm khi bị giới hạn chi phí. Khi cho phép Claude thử 30 lần cho mỗi nhiệm vụ, Sonnet 4.5 có thể tái tạo lỗ hổng trong 66,7% chương trình. Tổng chi phí cho 30 lần thử khoảng 45 USD – một mức vẫn tương đối thấp.
Một điểm đáng chú ý khác là khả năng phát hiện lỗ hổng mới. Trong khi Sonnet 4 chỉ phát hiện lỗ hổng mới trong khoảng 2% mục tiêu, Sonnet 4.5 đạt 5% với một lần thử, và hơn 33% khi thử 30 lần.
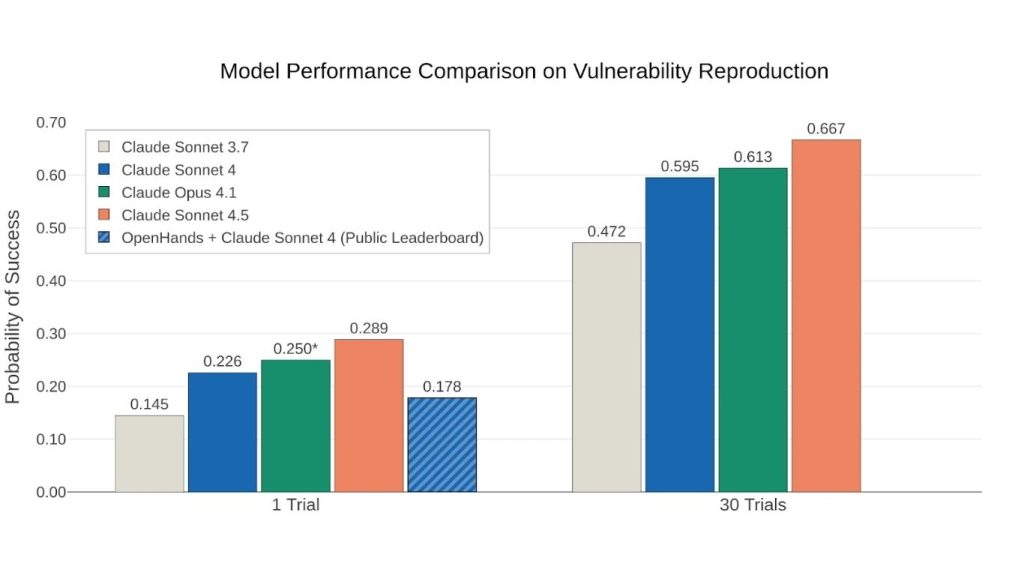
Điều thú vị không kém là tốc độ mà Claude Sonnet 4.5 phát hiện ra các lỗ hổng bảo mật mới. Trong khi bảng xếp hạng CyberGym cho thấy Claude Sonnet 4 chỉ phát hiện ra lỗ hổng bảo mật trong khoảng 2% mục tiêu, Sonnet 4.5 phát hiện ra lỗ hổng bảo mật mới trong 5% trường hợp. Bằng cách lặp lại thử nghiệm 30 lần, nó phát hiện ra lỗ hổng bảo mật mới trong hơn 33% dự án.

>> Tham khảo:
- Hướng dẫn nhanh tạo Landing Page bằng AI miễn phí, hiệu quả
- AI nhận diện ảnh là gì? Thuật toán và ứng dụng phổ biến
Nghiên cứu sâu hơn về việc vá lỗ hổng
Anthropic cũng đang tiến hành nghiên cứu sơ bộ về khả năng của Claude trong tạo và đánh giá các bản vá để khắc phục lỗ hổng bảo mật. Việc vá lỗi thường khó hơn việc tìm lỗi, vì mô hình phải chỉnh sửa chính xác mã nguồn để loại bỏ lỗ hổng mà không làm thay đổi chức năng ban đầu của chương trình. Nếu không có hướng dẫn hoặc thông số kỹ thuật, mô hình phải suy luận chức năng mong muốn từ cơ sở mã nguồn.
Trong thử nghiệm, Claude Sonnet 4.5 được giao nhiệm vụ vá lỗ hổng bảo mật trong bộ dữ liệu CyberGym dựa trên mô tả lỗ hổng và thông tin về những gì chương trình đang thực hiện khi nó bị treo. Anthropic cho biết, họ sử dụng Claude để tự đánh giá các bản vá của mình bằng cách tham chiếu với bản vá do con người viết.
Kết quả cho thấy 15% các bản vá do Claude tạo ra được đánh giá là tương đương về mặt ngữ nghĩa với các bản vá do con người xây dựng. Tuy nhiên, cách đánh giá dựa trên so sánh này vẫn có một hạn chế quan trọng: vì một lỗ hổng thường có thể được khắc phục bằng nhiều phương án hợp lệ khác nhau, nên những bản vá khác với bản tham chiếu vẫn có thể đúng. Điều này có thể dẫn đến các trường hợp bị đánh giá sai là không đạt trong quá trình đánh giá.
Nhóm nghiên cứu cũng tiến hành phân tích thủ công một số bản vá có điểm số cao nhất và nhận thấy chúng có chức năng hoàn toàn tương đương với các bản vá tham chiếu đã được tích hợp vào các phần mềm mã nguồn mở làm cơ sở cho bộ đánh giá CyberGym.
Kết quả này cho thấy một xu hướng phù hợp với những quan sát rộng hơn trước đó: các năng lực liên quan đến an ninh mạng của Claude được cải thiện song song với sự tiến bộ tổng thể của mô hình. Những kết quả ban đầu cho thấy việc tạo bản vá – tương tự như khả năng phát hiện lỗ hổng trước đó, là một năng lực “nổi lên” và có thể được cải thiện hơn nữa thông qua các nghiên cứu chuyên sâu.
Bước tiếp theo của nhóm là giải quyết một cách có hệ thống những thách thức đã được xác định, nhằm giúp Claude trở thành một công cụ đáng tin cậy trong việc tạo và đánh giá các bản vá bảo mật.
>> Xem thêm:
- Vision Inspection Systems: Hệ thống kiểm tra thị giác là gì?
- AI Data Labeling: Hướng dẫn gán nhãn dữ Liệu AI
Hợp tác với các đối tác
Trong thực tế, công tác phòng thủ an ninh mạng phức tạp hơn nhiều so với những gì các bài đánh giá có thể phản ánh. Nhóm nghiên cứu cho biết họ thường xuyên nhận thấy rằng các vấn đề trong môi trường thực tế phức tạp hơn, thách thức khó hơn và các chi tiết trong quá trình triển khai đóng vai trò rất quan trọng.
Vì vậy, việc hợp tác với các tổ chức đang trực tiếp sử dụng AI cho mục đích phòng thủ được xem là cần thiết, nhằm thu thập phản hồi về cách các nghiên cứu có thể giúp họ tăng tốc và nâng cao hiệu quả. Trong giai đoạn chuẩn bị ra mắt Sonnet 4.5, Anthropic cho biết họ đã làm việc với một số tổ chức áp dụng mô hình này vào các thách thức thực tế như khắc phục lỗ hổng bảo mật, kiểm tra an ninh mạng và phân tích mối đe dọa.
Các trường hợp áp dụng Claude Sonent 4.5 thực tế:
- Nidhi Aggarwal, Giám đốc Sản phẩm của HackerOne, cho biết: “Claude Sonnet 4.5 đã giúp giảm 44% thời gian tiếp nhận lỗ hổng trung bình đối với các tác nhân bảo mật Hai của chúng tôi, đồng thời cải thiện độ chính xác thêm 25%, qua đó giúp chúng tôi tự tin hơn trong việc giảm thiểu rủi ro cho doanh nghiệp.”
- Theo Sven Krasser, Phó Chủ tịch cấp cao phụ trách Khoa học Dữ liệu và Nhà khoa học trưởng tại CrowdStrike: “Claude cho thấy nhiều tiềm năng trong hoạt động red teaming – có thể tạo ra các kịch bản tấn công sáng tạo, giúp tăng tốc quá trình nghiên cứu chiến thuật của kẻ tấn công. Những hiểu biết này góp phần củng cố khả năng phòng thủ của chúng tôi trên nhiều lớp hệ thống, bao gồm thiết bị đầu cuối, danh tính, hạ tầng đám mây, dữ liệu, các dịch vụ SaaS và khối lượng công việc AI.”
Những phản hồi từ các đối tác này giúp nhóm nghiên cứu thêm tự tin về tiềm năng ứng dụng của Claude trong các hoạt động phòng thủ an ninh mạng.
Bước tiếp theo là gì?
Anthropic cho rằng Claude Sonnet 4.5 là một bước tiến đáng kể, nhưng nhiều khả năng của mô hình vẫn còn ở giai đoạn đầu và chưa thể sánh với các chuyên gia bảo mật giàu kinh nghiệm hoặc các quy trình bảo mật đã được thiết lập lâu năm. Trong thời gian tới, nhóm nghiên cứu sẽ tiếp tục cải thiện các năng lực liên quan đến phòng thủ của mô hình, đồng thời tăng cường các hệ thống tình báo mối đe dọa và các biện pháp giảm thiểu rủi ro nhằm bảo vệ nền tảng.
Tuy vậy, nhóm nghiên cứu cho rằng đây cũng là thời điểm phù hợp để nhiều tổ chức bắt đầu thử nghiệm cách AI có thể cải thiện năng lực an ninh của mình, đồng thời xây dựng các phương pháp đánh giá nhằm đo lường hiệu quả của những cải tiến đó. Các tính năng đánh giá bảo mật tự động trong Claude Code cho thấy AI có thể được tích hợp vào quy trình CI/CD để hỗ trợ kiểm tra an ninh trong quá trình phát triển phần mềm.
Trong tương lai, nhóm nghiên cứu đặc biệt quan tâm đến việc hỗ trợ các nhà nghiên cứu và đội ngũ kỹ thuật thử nghiệm việc ứng dụng mô hình AI trong các lĩnh vực như:
- Tự động hóa Security Operations Center (SOC)
- Phân tích Security Information and Event Management (SIEM)
- Kỹ thuật mạng an toàn
- Các chiến lược phòng thủ chủ động
Ngoài ra, nhóm cũng mong muốn có thêm nhiều bộ đánh giá về năng lực phòng thủ được phát triển trong hệ sinh thái đánh giá mô hình bởi các bên thứ ba.
Tuy nhiên, việc phát triển và ứng dụng AI nhằm hỗ trợ các bên phòng thủ chỉ là một phần của giải pháp. Song song với đó, cần có những cuộc thảo luận rộng hơn về cách xây dựng hạ tầng số có khả năng chống chịu tốt hơn và thiết kế phần mềm mới theo hướng an toàn ngay từ đầu – trong đó các mô hình AI tiên tiến cũng có thể đóng vai trò hỗ trợ.
Nhóm nghiên cứu mong muốn tiếp tục các cuộc trao đổi với doanh nghiệp, chính phủ và các tổ chức xã hội khi thế giới bước vào giai đoạn mà tác động của AI đối với an ninh mạng không còn là vấn đề của tương lai, mà đã trở thành một yêu cầu cấp thiết trong hiện tại.
Kết luận
Tóm lại, sự ra đời của Claude Sonnet 4.5 không chỉ chứng minh sức mạnh của công nghệ mà còn mở ra một kỷ nguyên mới cho chiến lược AI phòng thủ an ninh mạng chủ động. Bằng cách không ngừng cải thiện khả năng vá lỗi và phân tích mã nguồn, Anthropic đang cung cấp một “lá chắn” thông minh giúp các tổ chức đi trước kẻ tấn công một bước. Đây chính là thời điểm vàng để các doanh nghiệp tích hợp AI vào hệ thống quản trị rủi ro nhằm xây dựng một tương lai số an toàn và bền vững hơn.
>>> Tìm hiểu thêm:
- AI Agents cho Startup: Lợi ích và trường hợp sử dụng phổ biến
- Cách sử dụng AI tối ưu trải nghiệm khách hàng: Xu hướng
- Foundation Model là gì? Các loại mô hình nền tảng và ứng dụng trong AI
>>> Nguồn tham khảo: Building AI for cyber defenders
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com🏢 Địa chỉ:31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam







