
Hãy tưởng tượng một cô bé tên Emma có niềm đam mê đặc biệt với các loài chim. Mỗi cuối tuần, em cùng ông đến một công viên gần nhà để quan sát chim. Theo thời gian, Emma học được cách nhận ra các loài chim khác nhau dựa trên màu sắc, kích thước, hình dáng, thậm chí là tiếng hót của chúng.
Một buổi chiều nọ, khi đang lật xem một cuốn sách, em dễ dàng chỉ vào một bức ảnh và nói: “Ông ơi, nhìn này! Đó là chim cổ đỏ (robin)!” Emma không cần đo sải cánh hay phân tích cấu trúc lông chim; bộ não của em ngay lập tức liên kết hình ảnh đó với những trải nghiệm và ký ức về chim cổ đỏ ở công viên.
Khả năng tự nhiên này của con người (nhìn – hiểu – nhận diện) cho phép chúng ta quan sát sự vật và nhận ra chúng một cách gần như tức thì. Nhưng điều gì sẽ xảy ra nếu chúng ta muốn máy tính làm được điều tương tự? Đây chính là mục tiêu mà AI nhận diện ảnh hướng tới.
Nhận diện ảnh là một tác vụ trong lĩnh vực thị giác máy tính, cho phép máy móc diễn giải và nhận dạng đối tượng, con người, địa điểm và hành động trong hình ảnh. Công nghệ này mô phỏng khả năng hiểu dữ liệu thị giác của con người bằng cách phân tích các mẫu, hình dạng và đặc trưng trong ảnh số.
Về bản chất, AI nhận diện ảnh hoạt động bằng cách phân tích các pixel của hình ảnh và xác định các mẫu. Điều này được thực hiện thông qua các thuật toán phức tạp, nổi bật nhất là một loại mô hình tính toán gọi là mạng nơ-ron. Những mạng nơ-ron này được lấy cảm hứng từ vỏ não thị giác của não người và được huấnluyện trên các tập dữ liệu hình ảnh đã được gán nhãn với quy mô rất lớn. Thông qua quá trình xử lý này, mạng nơ-ron học cách nhận diện đặc điểm và tính chất của các đối tượng khác nhau.
>>> Xem thêm các bài viết liên quan:
- Các Nhiệm Vụ Của Thị Giác Máy Tính và cách thực hiện chúng nhanh chóng
- Học Máy Là Gì Và Tại Sao Học Máy Lại Quan Trọng?
- Khả năng thị giác của Chat GPT-5 và Cách Prompt hiệu quả
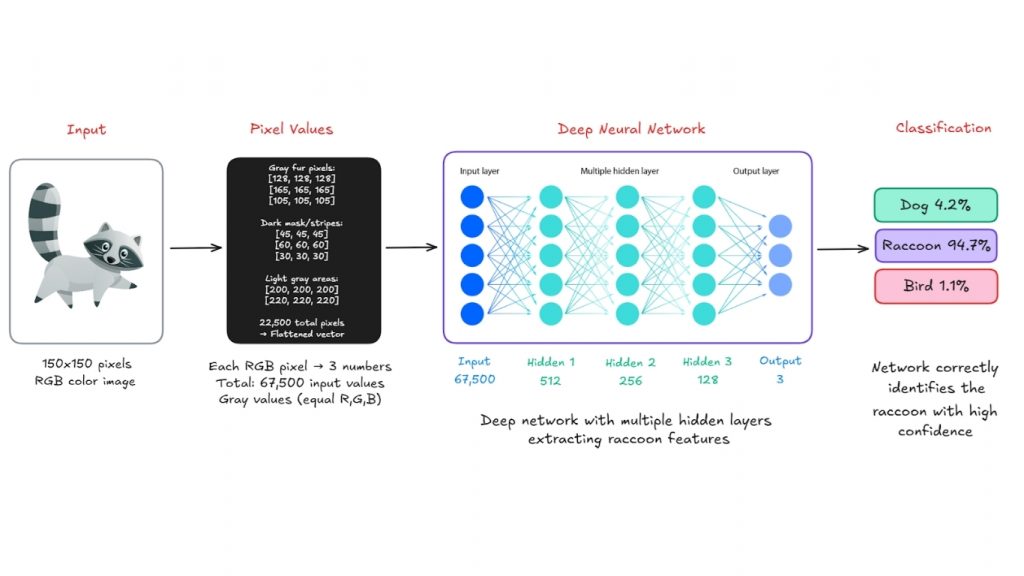
AI nhận diện ảnh hoạt động như thế nào?
Đối với con người, việc nhìn một hình ảnh đồng nghĩa với nhận ra ngay lập tức các hình dạng, màu sắc hoặc khuôn mặt quen thuộc. Nhưng với máy tính, “nhìn” hoàn toàn khác: hình ảnh chỉ là các con số. Dưới đây là quy trình từng bước giải thích cách máy tính nhìn và hiểu một hình ảnh.
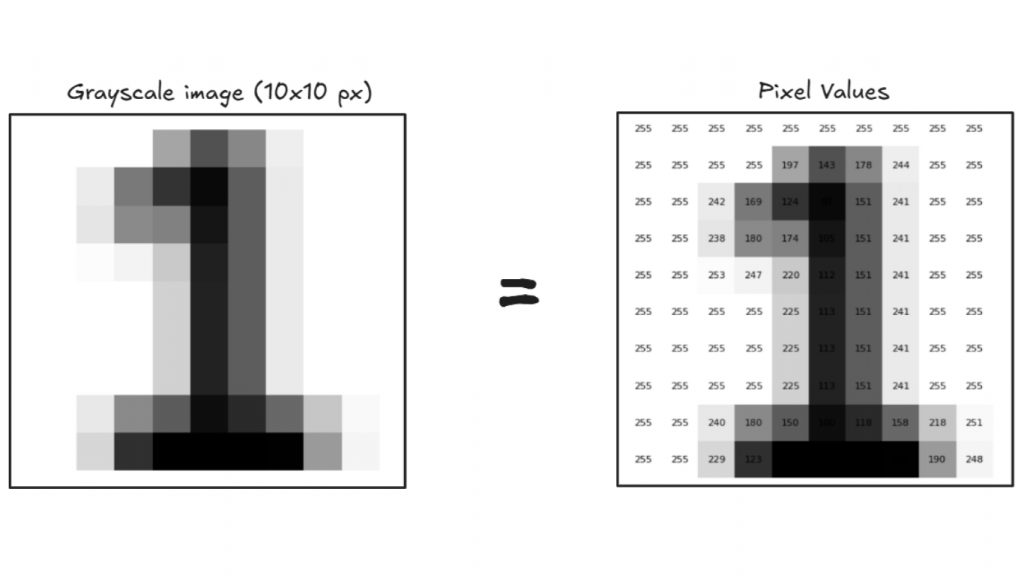
Bước 1: Pixels (Ngôn ngữ thị giác của máy tính)
Mọi hình ảnh đều được tạo thành từ các chấm nhỏ gọi là pixel. Mỗi pixel chứa một giá trị số đại diện cho một màu sắc hoặc sắc độ.
Ví dụ:
- Ảnh đen trắng là một lưới 2D các con số, trong đó mỗi giá trị nằm trong khoảng từ 0 (đen) đến 255 (trắng).
- Ảnh màu có ba kênh Red – Green – Blue (RGB), do đó được biểu diễn dưới dạng mảng 3D.
>>> Xem thêm:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất
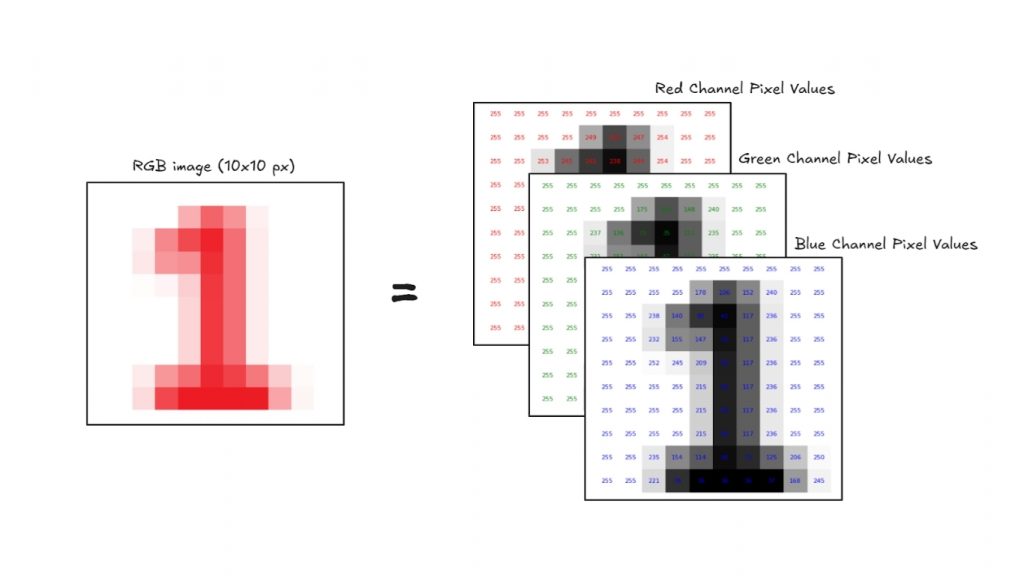
Bước 2: Phát hiện đặc trưng (Tìm kiếm mẫu)
Sau khi hình ảnh được chuyển đổi thành các con số, máy tính bắt đầu tìm kiếm các mẫu như:
- Cạnh
- Góc và điểm giao nhau
- Đường thẳng và đường cong
- Hình dạng
- Kết cấu bề mặt
Máy tính sử dụng các bộ lọc hoặc các phép toán toán học để tự động phát hiện những đặc trưng này
Bước 3: Học từ dữ liệu (Huấn luyện)
Máy tính được cung cấp hàng nghìn hoặc hàng triệu hình ảnh đã gán nhãn (ví dụ: mèo, xe hơi, chim). Trong quá trình huấn luyện, nó học được những đặc trưng nào thường xuất hiện với từng loại đối tượng.
Toàn bộ kiến thức này được lưu trữ trong mạng nơ-ron, một mô hình hoạt động tương tự như bộ não đơn giản hóa.
Bước 4: Phân loại (Thời điểm dự đoán)
Khi một hình ảnh mới được đưa vào, máy tính sẽ:
- Phân tích các pixel
- Phát hiện đặc trưng
- So sánh với những gì đã học
- Xuất ra nhãn dự đoán (ví dụ: “raccoon”) kèm theo độ tin cậy (ví dụ: 94,7%)
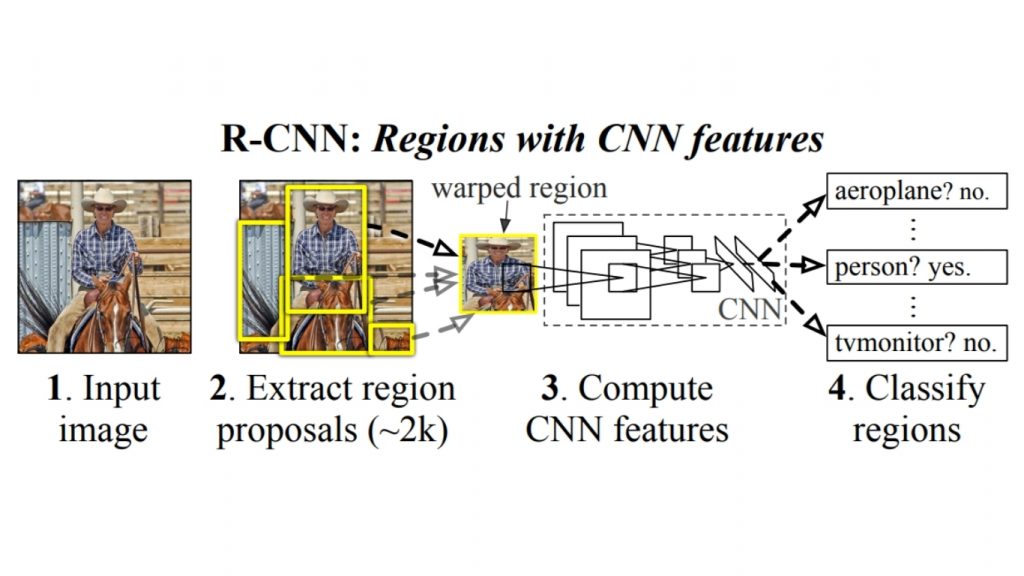
Sơ đồ kiến trúc R-CNN dưới đây minh họa cách AI nhận diện ảnh nhìn và nhận dạng các đối tượng trong hình ảnh bằng phương pháp R-CNN (Region-based Convolutional Neural Network).
- Bước 1: Máy tính nhận hình ảnh đầu vào, được biểu diễn nội bộ dưới dạng lưới các giá trị pixel.
- Bước 2: Thay vì phân tích toàn bộ ảnh cùng lúc, R-CNN tạo ra khoảng 2.000 vùng đề xuất – những phần nhỏ của ảnh có khả năng chứa đối tượng.
- Bước 3: Các vùng này được chuẩn hóa về kích thước cố định và đưa qua một CNN, nơi áp dụng các phép toán như convolution, pooling và hàm kích hoạt phi tuyến để trích xuất đặc trưng (cạnh, kết cấu, mẫu hình…).
- Bước 4: Cuối cùng, các đặc trưng của từng vùng được phân loại bằng bộ phân loại (ví dụ: SVM), trả lời những câu hỏi như “Đây có phải là người không?” hoặc “Đây có phải là màn hình TV không?”
Quy trình này cho thấy máy tính không hiểu toàn bộ hình ảnh ngay lập tức. Thay vào đó, nó chia ảnh thành nhiều phần, tìm kiếm các mẫu có ý nghĩa và sử dụng dữ liệu đã học để nhận diện nội dung bên trong, tương tự cách con người quét cảnh vật để tìm các đối tượng quen thuộc.
>>> Xem thêm:
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
Máy tính không nhìn hình ảnh như con người, mà nhìn chúng như những lưới số học. Nhờ machine learning, đặc biệt là deep learning, máy tính học cách nhận ra các mẫu trong những con số đó và liên kết chúng với các đối tượng quen thuộc. Giống như một đứa trẻ học cách nhận ra con chó sau khi nhìn thấy rất nhiều con chó khác nhau, AI nhận diện ảnh học từ dữ liệu để “nhìn” và hiểu thế giới xung quanh.
Các loại mô hình AI nhận diện ảnh
AI nhận diện ảnh có phạm vi ứng dụng rất rộng với nhiều loại mô hình khác nhau, mỗi mô hình được thiết kế cho những tác vụ cụ thể như phân loại ảnh, phát hiện đối tượng, phân đoạn ảnh, nhận diện khuôn mặt hoặc ước lượng keypoint.
Mô hình phân loại ảnh
Phân loại ảnh gán một nhãn duy nhất cho toàn bộ hình ảnh. Mô hình sẽ quan sát ảnh và dự đoán đối tượng (hoặc lớp) mà ảnh đó chứa, ví dụ như “cat”, “car” hoặc “banana”.
Các mô hình này được dùng để nhận diện đối tượng hoặc bối cảnh chiếm ưu thế trong ảnh, chẳng hạn như “cat”, “airplane” hay “fractured bone”.
Ví dụ:
- ResNet-32 / ResNet-50: Sử dụng kết nối dư để giải quyết vấn đề suy giảm hiệu năng ở mạng sâu.
- Vision Transformers (ViT): Vision Transformer áp dụng các embedding mạnh mẽ từ xử lý ngôn ngữ tự nhiên (như BERT) vào bài toán hình ảnh.
Mô hình phát hiện đối tượng
Mô hình phát hiện đối tượng (Object Detection) vừa xác định vị trí vừa phân loại nhiều đối tượng trong một ảnh bằng cách vẽ bounding box và gán nhãn (ví dụ: “person”, “dog”). Các mô hình này được sử dụng để nhận diện và theo dõi nhiều đối tượng như con người, phương tiện, động vật hoặc sản phẩm trong ảnh hoặc video.
Ví dụ:
- YOLOv12: Mô hình phát hiện đối tượng thời gian thực với tốc độ rất nhanh.
- DETR: Mô hình phát hiện đối tượng end-to-end dựa trên Transformer.
- RF-DETR: Mô hình phát hiện đối tượng thời gian thực dựa trên Transformer.
- Grounding DINO: Mô hình phát hiện đối tượng zero-shot tiên tiến hàng đầu hiện nay.
Mô hình phân đoạn instance & semantic
Các mô hình này thực hiện phân loại ở mức pixel, bao gồm:
- Semantic Segmentation: Gán nhãn cho từng pixel (ví dụ: trời, đường, người).
- Instance Segmentation: Không chỉ phân biệt lớp mà còn tách từng cá thể riêng biệt (ví dụ: người 1, người 2).
Những mô hình này được dùng để hiểu chính xác hình dạng và ranh giới của đối tượng, chẳng hạn như tách làn đường, khối u, hoặc lá cây khỏi nền.
Ví dụ:
- Mask R-CNN: Kết hợp Faster R-CNN với mặt nạ pixel.
- YOLOv8 Instance Segmentation: Phiên bản YOLOv8 hiện đại hỗ trợ tác vụ phân đoạn instance.
- Segment Anything 2: Mô hình phân đoạn mở, dựa trên prompt, do Meta phát triển.
- SegFormer: Mô hình dựa trên Transformer cho bài toán semantic segmentation.
>>> Xem thêm:
- Các Mô Hình Ngôn Ngữ Thị Giác Chạy Cục Bộ Tốt Nhất
- Phát hiện đối tượng trong video với RF-DETR
Mô hình phát hiện keypoint & ước lượng tư thế
Mô hình phát hiện keypoint xác định các điểm mốc cụ thể trên đối tượng, phổ biến nhất là các khớp trên cơ thể người (khuỷu tay, cổ tay, đầu gối…).
Pose estimation sử dụng các keypoint này để xác định tư thế hoặc hướng chuyển động của cơ thể hay đối tượng.
Các mô hình này thường được dùng cho:
- Ước lượng tư thế con người
- Nhận diện cử chỉ
- Phân tích vận động & fitness
- Motion capture
Thông thường, mô hình sẽ trả về tọa độ của 17–33 khớp cơ thể cho mỗi người, ví dụ:
[
{ "x": 100, "y": 200, "label": "left_elbow" },
...
]Ví dụ: YOLO-NAS Pose: Mô hình phát hiện keypoint do Deci AI phát triển.
Phát hiện & nhận diện khuôn mặt
Các mô hình phát hiện khuôn mặt có nhiệm vụ tìm và xác định vị trí khuôn mặt trong ảnh, trong khi nhận diện khuôn mặt dùng để xác định hoặc xác minh danh tính của một người dựa trên đặc điểm khuôn mặt. Các mô hình AI nhận diện ảnh này được sử dụng rộng rãi trong xác thực sinh trắc học, giám sát an ninh, gắn thẻ khuôn mặt trong ảnh, và hệ thống kiểm soát truy cập.
Ví dụ:
- RetinaFace: Mô hình phát hiện khuôn mặt có độ chính xác cao, hỗ trợ trích xuất các điểm mốc.
- FaceNet / ArcFace / InsightFace: Chuyển đổi khuôn mặt thành vector embedding để so khớp và nhận diện.
- DeepFace: Thư viện cấp cao hỗ trợ nhiều backend như VGGFace, Dlib, v.v.
Mô hình ngôn ngữ thị giác
Mô hình ngôn ngữ thị giác kết hợp khả năng hiểu hình ảnh với xử lý ngôn ngữ tự nhiên. Bạn có thể đặt câu hỏi cho mô hình như: “Điều gì đang xảy ra trong bức ảnh này?”, “Con chó ở đâu?”
Các mô hình AI nhận diện ảnh này hiểu được cả mẫu hình thị giác lẫn ngôn ngữ, từ đó đưa ra câu trả lời thông minh dưới dạng văn bản. Chúng có thể diễn giải hình ảnh bằng ngôn ngữ tự nhiên, trả lời câu hỏi, tạo mô tả ảnh hoặc tìm đối tượng theo tên.
Ví dụ:
- MetaCLIP: Ghép hình ảnh với văn bản theo phương pháp zero-shot.
- Florence-2 / Kosmos-2: Dùng cho grounding, captioning và segmentation dựa trên ngôn ngữ.
- GPT-4o: Trò chuyện về hình ảnh, tạo mô tả, phân tích tài liệu
>>> Xem thêm:
- Thiết kế website bằng AI (trí tuệ nhân tạo) miễn phí
- Tối ưu website bằng AI là gì? Cách tối ưu SEO và các công cụ AI
- Hướng dẫn tạo Landing Page bằng AI hiệu quả nhất hiện nay
Cách sử dụng AI nhận diện ảnh với Roboflow
Roboflow cho phép bạn huấn luyện, kiểm thử và triển khai các mô hình thị giác máy tính có khả năng nhận diện ảnh. Bạn có thể xây dựng hệ thống AI nhận diện ảnh mạnh mẽ chỉ với vài bước. Dưới đây là các bước xây dựng AI nhận diện ảnh với Roboflow:
Bước 1: Tạo dự án
Chọn loại tác vụ mà bạn muốn xây dựng mô hình AI nhận diện ảnh. Roboflow hỗ trợ các loại project sau:
- Phân loại ảnh (Gán nhãn cho toàn bộ ảnh)
- Phát hiện đối tượng (Xác định đối tượng và vị trí bằng bounding box)
- Instance Segmentation (Phát hiện nhiều đối tượng và hình dạng của chúng)
- Semantic Segmentation (Gán nhãn cho từng pixel)
- Xác định điểm mốc (Xác định keypoint / bộ xương của đối tượng)
- Multimodal (Mô tả ảnh bằng cặp văn bản)
Bước 2: Tải Dataset
Sau khi tạo dự án, tải ảnh lên Roboflow bằng cách upload hoặc kéo thả. Bạn cũng có thể nhập dữ liệu từ:
- Roboflow Universe
- URL YouTube
- Cloud Providers
- Upload API
Bước 3: Gán nhãn hình ảnh
Gán nhãn cho ảnh bằng công cụ annotation tích hợp sẵn của Roboflow. Bạn có thể sử dụng các kỹ thuật sau:
- Manual Annotation: Dùng công cụ gán nhãn trên web của Roboflow để vẽ bounding box, polygon, v.v.
- Auto-Labeling: Sử dụng AI hỗ trợ gán nhãn như Label Assist, Smart Polygon, Box Prompting, Auto Label để tăng tốc quá trình.
>>> Xem thêm:
- Suy Luận Trong Thị Giác Máy Tính: Cách Thực Hiện & Triển Khai Mô Hình AI
- Hệ thống kiểm tra thị giác (VIS) là gì?
Bước 4: Tiền xử lý & tăng cường dữ liệu
Roboflow cung cấp nhiều tùy chọn giúp cải thiện độ ổn định và khả năng tổng quát của mô hình AI nhận diện ảnh.
Tiền xử lý: Chuẩn hóa ảnh đầu vào cho quá trình huấn luyện. Các kỹ thuật phổ biến gồm:
- Auto-Orient
- Isolate Objects
- Static Crop
- Dynamic Crop
- Resize
- Grayscale
- Auto-Adjust Contrast
- Tile, v.v.
Tăng cường dữ liệu: Mở rộng dataset bằng cách áp dụng các biến đổi ngẫu nhiên, giúp giảm overfitting.
- Tăng cường ở mức toàn ảnh: ật ảnh (Flip), xoay 90° (Rotate 90°), cắt ảnh (Crop), xoay (Rotation), biến dạng xiên (Shear), chuyển ảnh xám (Grayscale), điều chỉnh sắc độ (Hue), độ bão hòa (Saturation), độ sáng (Brightness), độ phơi sáng (Exposure), làm mờ (Blur), thêm nhiễu (Noise), che vùng ngẫu nhiên (Cutout), ghép ảnh (Mosaic)..
- ăng cường ở mức bounding box: Lật ảnh (Flip), xoay 90° (Rotate 90°), cắt ảnh (Crop), xoay (Rotation), biến dạng xiên (Shear), điều chỉnh độ sáng (Brightness), độ phơi sáng (Exposure), làm mờ (Blur), thêm nhiễu (Noise).
Bước 5: Tạo Dataset
Nhấn “Create” để tạo một phiên bản dataset mới với các thiết lập bạn đã chọn.
Bước 6: Huấn luyện mô hình
Bạn có thể:
- Huấn luyện trực tiếp trên Roboflow bằng Custom Train (hosted model), hoặc
- Export dataset để huấn luyện local bằng YOLO, TensorFlow hoặc PyTorch.
Ví dụ export a dataset định dạng YOLOv8:
rf = Roboflow(api_key=”YOUR_API_KEY”)
project = rf.workspace().project(“your-project”)
dataset = project.version(1).download(“yolov8”)
Bước 7: Triển khai mô hình
Roboflow cung cấp nhiều tùy chọn triển khai linh hoạt:
- Workflows deployment: Cấu hình, tích hợp và deploy mô hình nhanh chóng.
- Hosted image & video inference: Endpoint inference trên cloud, phù hợp xử lý batch hoặc non-real-time.
- Edge deployment: Triển khai trên thiết bị nhúng như TPU, Android hoặc NVIDIA Jetson (qua Docker) để inference thời gian thực.
Ngoài ra còn có các tùy chọn khác như server chuyên dụng do Roboflow quản lý, mobile deployment trên iOS, Snap AR Lens Studio integration,… giúp AI nhận diện ảnh tương thích với nhiều nền tảng và use case khác nhau.
>>> Xem thêm:
- Cách ứng dụng AI tối ưu trải nghiệm khách hàng
- Hướng dẫn tạo app bằng Low Code đơn giản, hiệu quả nhất
- Cách sử dụng chatbot cho giáo dục đại học và học tập
Roboflow Workflows được dùng cho AI nhận diện ảnh như thế nào?
Roboflow Workflows cho phép kết hợp nhiều mô hình thị giác máy tính vào một pipeline duy nhất. Thay vì chạy từng mô hình riêng lẻ, workflow cho phép chuỗi hóa các tác vụ như object detection, classification, OCR chỉ với một API call. Trong Roboflow Workflows, bạn có thể xây dựng pipeline AI nhận diện ảnh bằng cách kết hợp nhiều block chức năng khác nhau theo trình tự.
Roboflow Workflows hỗ trợ:
- Mô hình pretrained
- Mô hình custom hoặc fine-tuned
Sử dụng mô hình pretrained trong Roboflow
Roboflow cung cấp nhiều mô hình sẵn dùng như:
- YOLOv8, YOLOv11, YOLO-NAS
- RF-DETR-Base
- VLMs / Multimodal Models
Bạn có thể dùng trực tiếp các mô hình này trong Workflows mà không cần huấn luyện. Ví dụ:
- RF-DETR-Base hoặc YOLOv8 → Object Detection Model block
- YOLOv8n-Seg → Instance Segmentation Model block
- YOLOv8n-Pose → Keypoint Detection Model block
- GPT-4o → OpenAI block
- gemini-2.0-flash → Google Gemini block
>>> Xem thêm:
- Character AI là gì? Trò chuyện cùng nhân vật ảo trên mô hình mới
- 13 nền tảng chatbot mã nguồn mở tốt nhất năm 2026
- TOP 10 AI thiết kế website miễn phí, trả phí, hiệu quả năm 2026
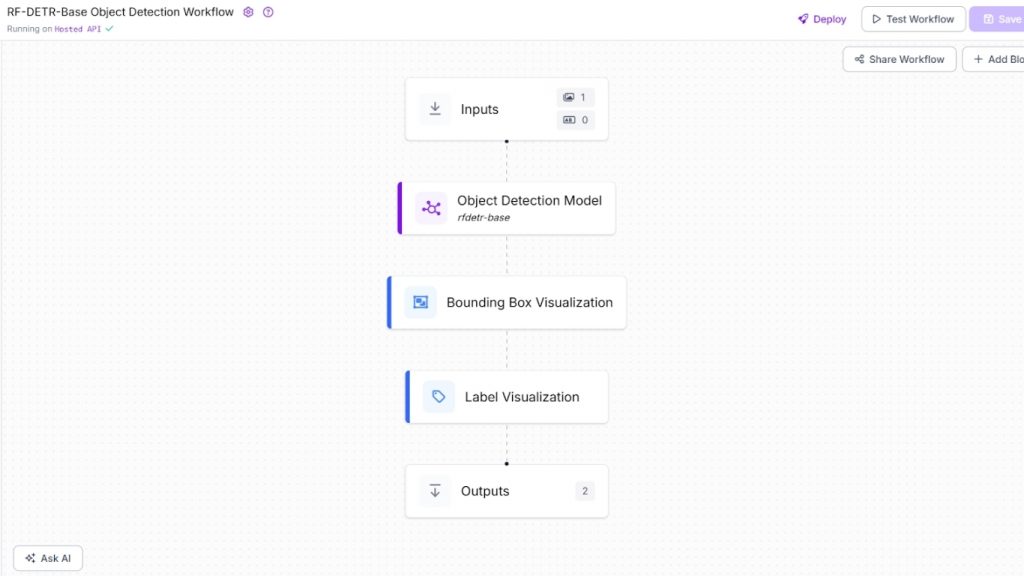
Roboflow Workflows là trình xây dựng ứng dụng thị giác máy tính no-code, cho phép tạo pipeline phức tạp trực tiếp trên trình duyệt. Workflow có thể triển khai trên cloud hoặc self-host trên edge devices.
Sử dụng mô hình custom đã huấn luyện
Roboflow là một nền tảng end-to-end dành cho phát triển thị giác máy tính. Nền tảng này hỗ trợ toàn bộ vòng đời xây dựng mô hình thị giác máy tính, từ thu thập và gán nhãn dữ liệu, tạo dataset, huấn luyện, fine-tune, suy luận, triển khai cho đến tích hợp thông qua API. Khi bạn huấn luyện một mô hình thị giác máy tính tùy chỉnh bằng Roboflow, mô hình sẽ được lưu trữ sẵn và có thể dễ dàng tích hợp vào ứng dụng của bạn thông qua API.
Ngoài ra, bạn cũng có thể tích hợp các mô hình này vào Roboflow Workflow thông qua workspace của mình hoặc sử dụng các mô hình được công khai trong workspace của những người dùng khác trên nền tảng Roboflow.
>>> Xem thêm:
- TOP 30 công cụ AI miễn phí, phổ biến, hỗ trợ học tập và làm việc hiệu quả
- TOP 20 công cụ Chat AI tiếng Việt miễn phí thông minh phổ biến
Xây dựng AI nhận diện ảnh với Roboflow
Bây giờ, hãy cùng xem một số ví dụ về cách xây dựng ứng dụng AI nhận diện ảnh bằng Roboflow. Trong phần này, chúng ta sẽ sử dụng cả mô hình được huấn luyện tùy chỉnh (Phát hiện gỗ/khúc gỗ, Nhận diện cử chỉ tay) cũng như mô hình pretrained (Florence-2) kết hợp với Roboflow Workflows để xây dựng ứng dụng.
Ví dụ 1: Phát hiện và đếm gỗ/khúc gỗ
Trong ví dụ này, chúng ta sẽ xây dựng một ứng dụng Roboflow Workflow có khả năng nhận diện, phát hiện và đếm các khúc gỗ trong hình ảnh.
Để thực hiện, chúng ta tạo một project object detection, tải lên và gán nhãn dataset, sau đó huấn luyện mô hình bằng tùy chọn Roboflow Autotraining. Mô hình sau khi huấn luyện sẽ được lưu trữ trên Roboflow hosted inference server và sẵn sàng để sử dụng.
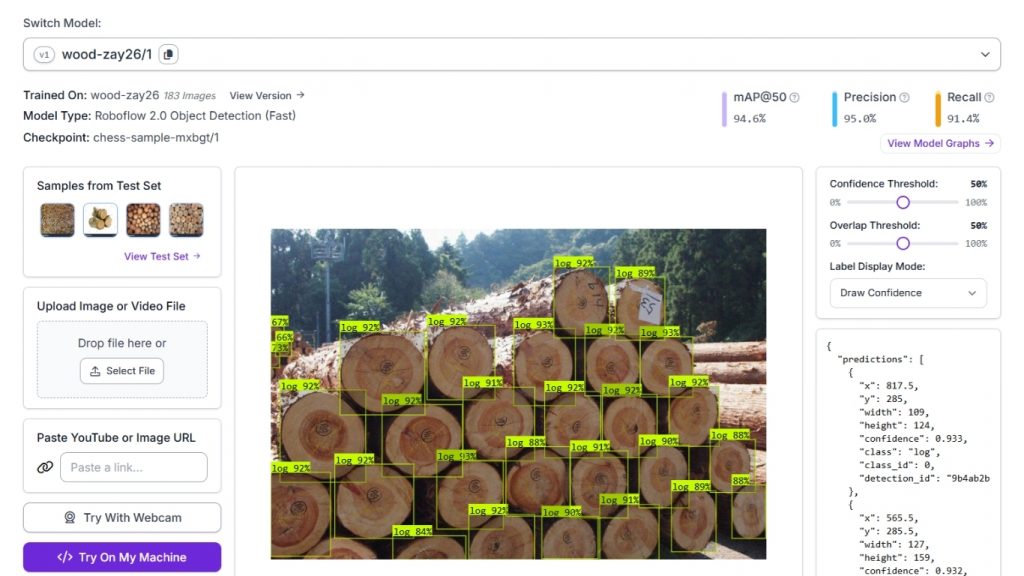
Cụ thể, ứng dụng Roboflow Workflow này được thiết kế để phát hiện và đếm các khúc gỗ trong ảnh. Dự án sử dụng phương pháp object detection với mô hình Roboflow 2.0 Object Detection (Fast).
Để xây dựng ứng dụng, một dataset tùy chỉnh gồm 183 hình ảnh đã được gán nhãn, chứa các khúc gỗ, đã được tải lên Roboflow. Mỗi khúc gỗ trong ảnh được gán nhãn với class “log”.
Mô hình được huấn luyện bằng pipeline AutoML của Roboflow và đạt các chỉ số:
- mAP@50: 94.6%
- Precision: 95.0%
- Recall: 91.4%
Mô hình đã huấn luyện, có định danh wood-zay26/1, được host trên Roboflow inference server và có thể dễ dàng tích hợp vào workflow hoặc gọi trực tiếp thông qua API.
>>> Xem thêm:
- LLMs.txt là gì? Có nên sử dụng không?
- 18 cách ứng dụng AI cho ecommerce đạt hiệu quả cao
- Cách sử dụng AI trong phát triển phần mềm như thế nào?
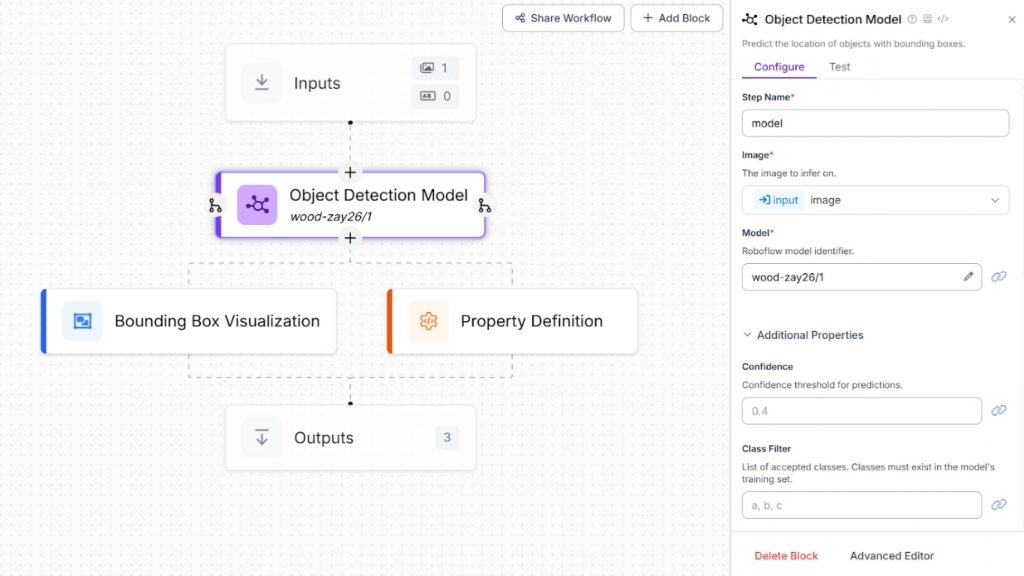
Chúng ta sẽ tích hợp mô hình này vào Roboflow Workflow bằng cách tạo một workflow mới và thêm Object Detection Model block. Block này chịu trách nhiệm thực hiện suy luận (inference) bằng mô hình đã được huấn luyện.
Trong phần cấu hình của block, hãy thiết lập thuộc tính Model thành wood-zay26/1, trỏ tới mô hình phát hiện đối tượng tùy chỉnh đã được triển khai và lưu trữ trên Roboflow. Cấu hình này cho phép workflow tự động phát hiện và gán nhãn các khúc gỗ trong hình ảnh đầu vào bằng mô hình đã huấn luyện.
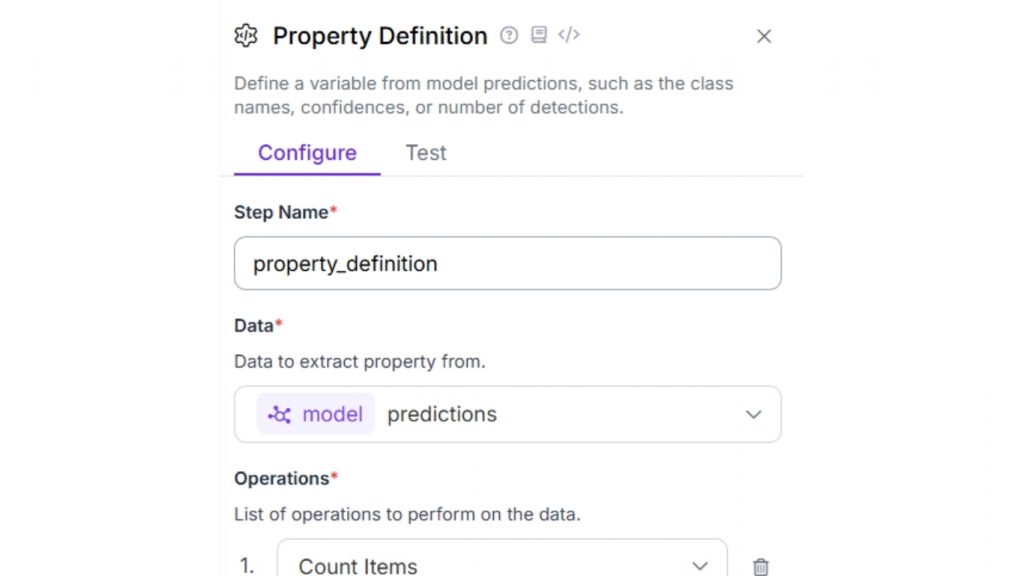
Tiếp theo, hãy thêm Property Definition block. Block này được sử dụng để đếm số lượng kết quả phát hiện, từ đó giúp tính tổng số khúc gỗ (wood/log) xuất hiện trong hình ảnh. Trong phần cấu hình của block, đặt thuộc tính Operations thành “Count Items” như minh họa bên dưới.
Cuối cùng, thêm Bounding Box Visualization block để hiển thị kết quả phát hiện bằng các khung bounding box bao quanh những đối tượng đã được nhận diện. Khi workflow được chạy, hệ thống sẽ tạo ra một ảnh đầu ra làm nổi bật từng khúc gỗ được phát hiện, giúp bạn xác nhận trực quan khả năng nhận diện gỗ của mô hình trong hình ảnh.
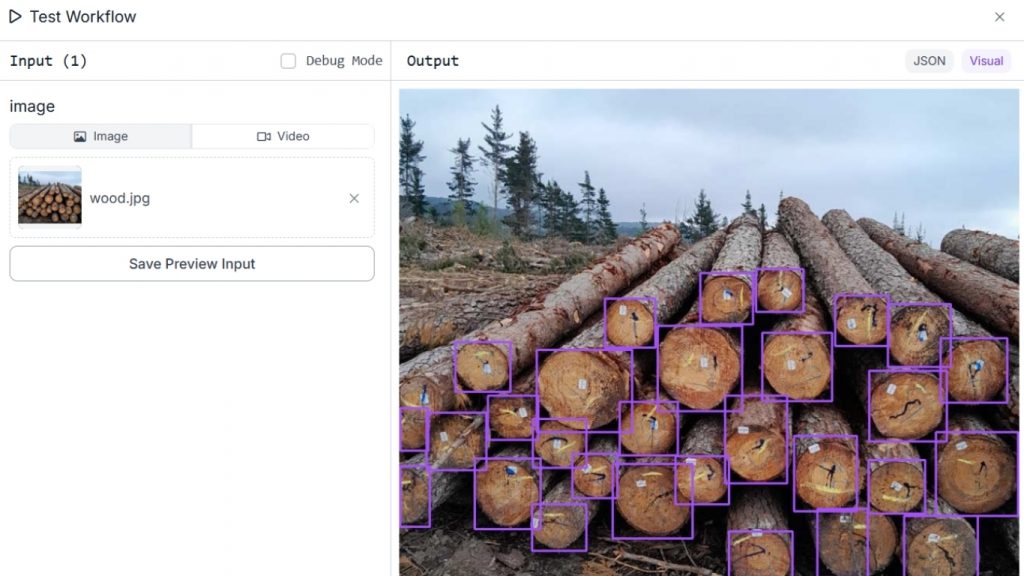
Kết quả đầu ra dạng JSON hiển thị dữ liệu từ Property Block, trong đó cung cấp tổng số khúc gỗ được phát hiện trong hình ảnh.
“property_definition”: 29
Loại workflow này đặc biệt hữu ích trong các lĩnh vực như quản lý lâm nghiệp, theo dõi tồn kho và xử lý vật liệu tự động, nơi việc đếm và nhận diện các khúc gỗ trong hình ảnh xếp chồng là yêu cầu quan trọng.
Bạn cũng có thể chạy workflow này cục bộ hoặc theo thời gian thực bằng cách sử dụng webcam hoặc các thiết bị edge, đồng thời tùy chỉnh sâu hơn bằng cách điều chỉnh ngưỡng độ tin cậy và thiết lập mức độ chồng lấn.
Ví dụ 2: Nhận diện cử chỉ tay
Trong ví dụ này, chúng ta xây dựng một ứng dụng nhận diện cử chỉ tay bằng cách sử dụng mô hình object detection được huấn luyện tùy chỉnh từ Roboflow. Mô hình được thiết kế để phát hiện và nhận diện các cử chỉ tay khác nhau, như minh họa trong hình ảnh bên dưới, dựa trên hình dạng của bàn tay trong ảnh. Các cử chỉ tay này được sử dụng để điều khiển bóng đèn AC.
Mô hình được huấn luyện bằng pipeline AutoML của Roboflow, dựa trên kiến trúc Roboflow 3.0 Object Detection (Accurate) với checkpoint COCOs làm nền tảng. Dataset huấn luyện bao gồm các hình ảnh đã được gán nhãn, đại diện cho nhiều cử chỉ tay khác nhau, trong đó mỗi cử chỉ được gán nhãn bằng tên cử chỉ tương ứng làm class.

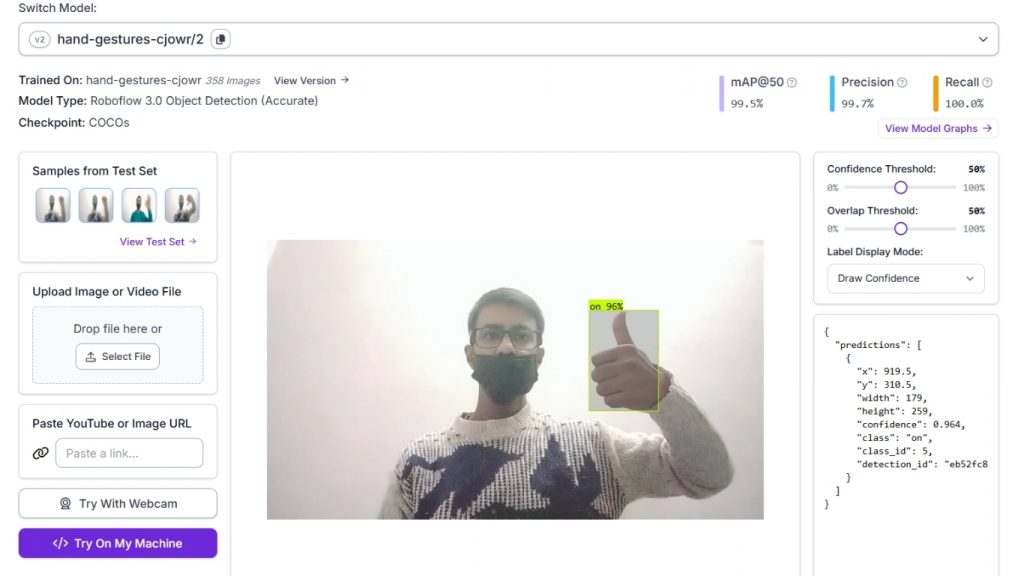
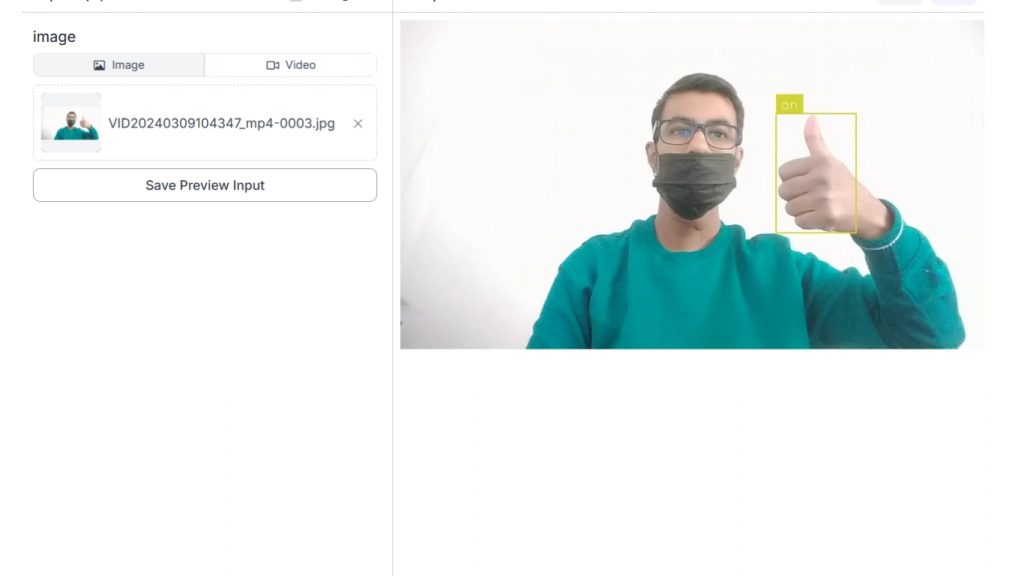
Trong kết quả suy luận (inference) minh họa bên dưới, mô hình đã phát hiện thành công một cử chỉ tay và gán nhãn là “on” với độ tin cậy 96%. Mô hình sau khi huấn luyện đạt các chỉ số ấn tượng:
- mAP@50: 99.5%
- Precision: 99.7%
- Recall: 100.0%
Chúng ta sẽ sử dụng mô hình này trong Roboflow Workflow để xây dựng một ứng dụng nhận diện cử chỉ tay. Để thiết lập, hãy tạo một workflow mới và thêm Object Detection Model block, sau đó cấu hình thuộc tính Model thành hand-gestures-cjowr/2.
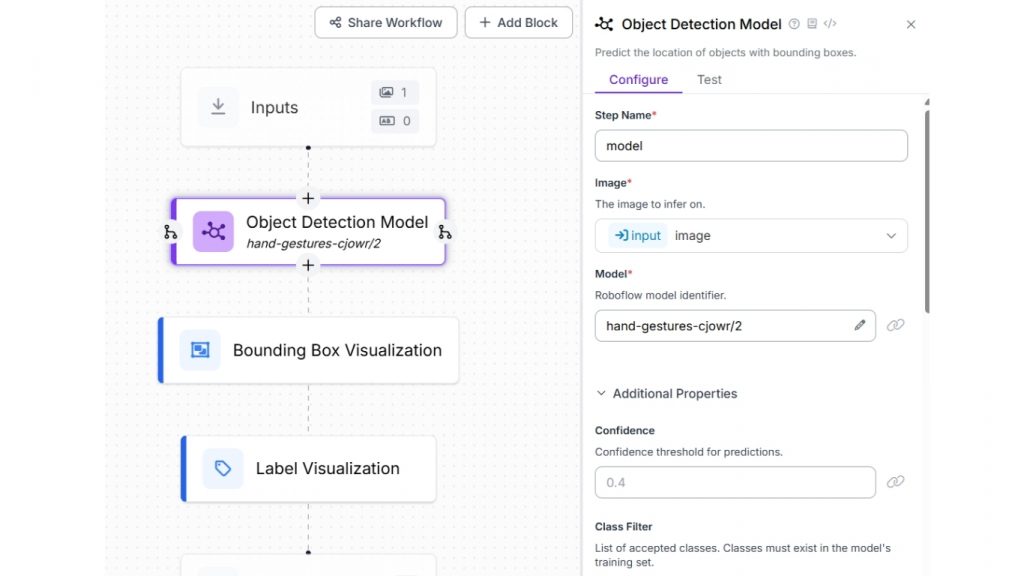
Tiếp theo, thêm cả Bounding Box Visualization block và Label Visualization block để hiển thị các cử chỉ tay được phát hiện cùng với tên class tương ứng.
Ngoài việc xử lý ảnh tĩnh, workflow còn có thể xử lý file video và luồng video trực tiếp (live stream). Bằng cách sử dụng Inference Pipeline SDK, bạn có thể triển khai và chạy workflow cục bộ trên thiết bị edge để xử lý video theo thời gian thực. Điều này khiến giải pháp đặc biệt phù hợp cho các ứng dụng tương tác như hệ thống điều khiển bằng cử chỉ, giao diện nhà thông minh, công nghệ hỗ trợ người khuyết tật và hệ thống nhận diện ngôn ngữ ký hiệu.
Ví dụ 3: VLM cho nhận diện ảnh
Trong ví dụ này, chúng ta sử dụng Vision-Language Model (VLM) Florence-2 của Microsoft để xây dựng một ứng dụng AI nhận diện ảnh thông minh. Ứng dụng được vận hành bởi một Roboflow Workflow tích hợp mô hình Florence-2 pretrained, có khả năng xác định và định vị các đối tượng cụ thể trong hình ảnh.
Bằng cách cung cấp một prompt văn bản (ví dụ: tên hoặc mô tả của đối tượng), mô hình sẽ được hướng dẫn để phát hiện và làm nổi bật đối tượng mục tiêu trong hình ảnh. Cách tiếp cận này tận dụng sức mạnh của AI đa phương thức (multimodal AI), kết hợp thị giác máy tính và ngôn ngữ tự nhiên để thực hiện nhận diện đối tượng linh hoạt dựa trên prompt.
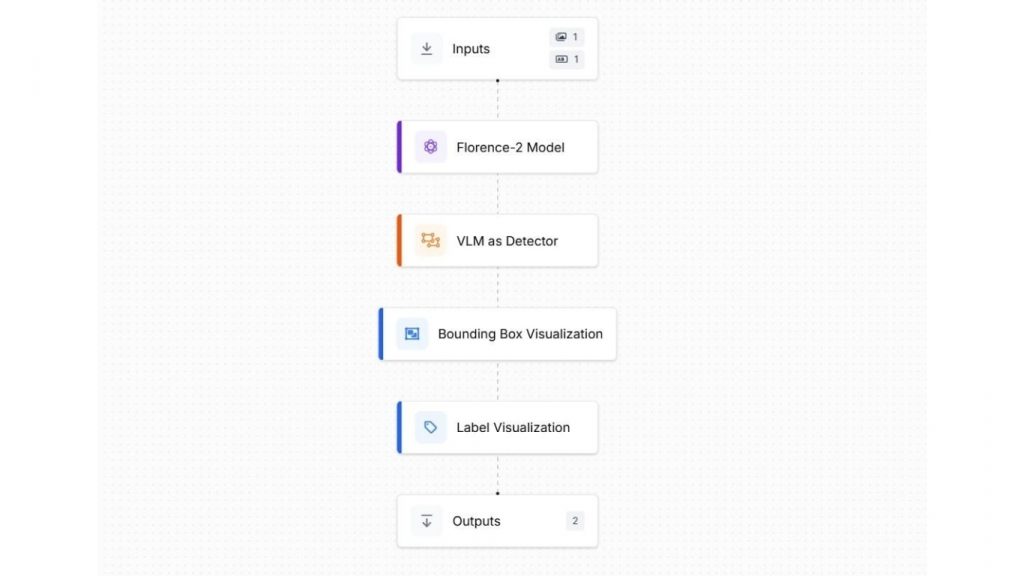
Thêm một tham số văn bản (text parameter) vào Input block để chỉ định prompt dạng văn bản đi kèm với ảnh đầu vào.
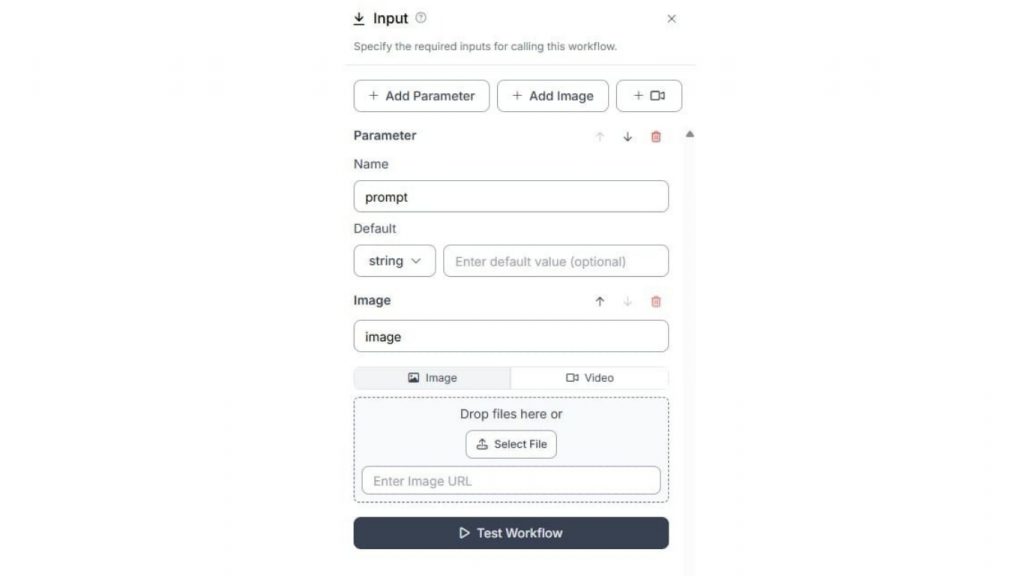
Cấu hình Florence-2 block như sau. Chọn Task Type là “Prompted Object Detection”. Liên kết thuộc tính Prompt với tham số “prompt” đã được thêm trong Input Block.
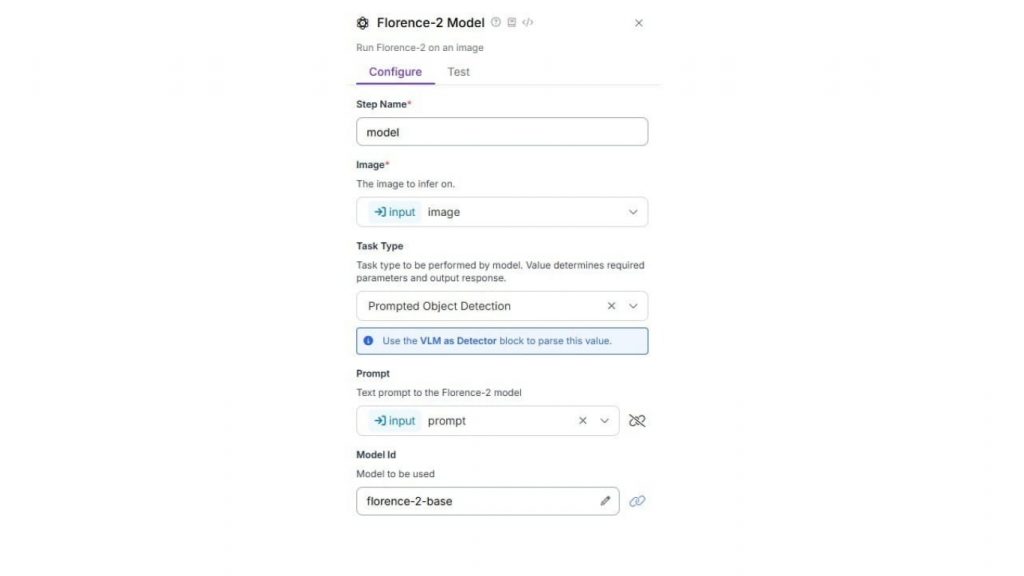
Tiếp theo, cấu hình VLM as Detector block như sau. Các thuộc tính VLM Output và Classes được thiết lập bằng đầu ra từ Florence-2 block, thuộc tính Model Type được đặt là Florence-2 và Task Type được đặt là Prompted Object Detection.
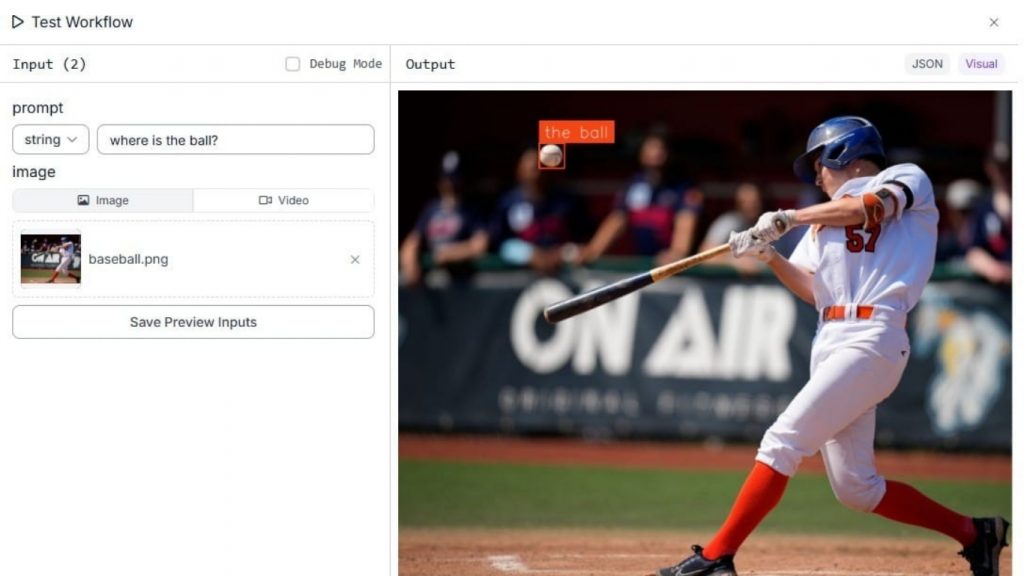
Chạy Workflow bằng cách nhập prompt và tải lên ảnh đầu vào. Trong trường hợp prompt là “Where is the ball?” và ảnh đầu vào là hình ảnh một vận động viên bóng chày (batter) đang đánh bóng, chúng ta muốn xác định quả bóng và vị trí của nó trong ảnh.
Vision-Language Models (VLMs) mang đến một cách tiếp cận mạnh mẽ và linh hoạt cho nhận diện hình ảnh bằng cách kết hợp hiểu biết thị giác với prompt ngôn ngữ tự nhiên. Thay vì chỉ dựa vào các class được định nghĩa sẵn, VLM cho phép người dùng mô tả đối tượng cần phát hiện bằng văn bản đơn giản.
Điều này cho phép phát hiện đối tượng dựa trên prompt, trong đó mô hình có thể nhận diện và định vị các đối tượng trong ảnh dựa trên mô tả được cung cấp. Dù được sử dụng để tìm kiếm vật thể cụ thể, tạo chú thích ảnh hay trả lời câu hỏi về nội dung hình ảnh, VLM giúp quá trình nhận diện hình ảnh trở nên trực quan và linh hoạt hơn, phù hợp với nhiều kịch bản thực tế khác nhau.
>>> Xem thêm:
- Hướng dẫn cách sử dụng Google AI Studio hiệu quả, nhanh chóng
- Hướng dẫn triển khai AI trong ứng dụng di động đơn giản
- Tạo web bán hàng bằng AI miễn phí, chuẩn SEO, hiệu quả nhất
- AI trong thiết kế UI/UX: Công cụ hay đối thủ của Designer?
Phần mềm AI nhận diện hình ảnh
Nhận diện hình ảnh là một ứng dụng mạnh mẽ của thị giác máy tính, cho phép máy móc hiểu và diễn giải dữ liệu hình ảnh giống như con người. Với các nền tảng như Roboflow, việc xây dựng và triển khai các hệ thống nhận diện hình ảnh thông minh trở nên dễ dàng và dễ tiếp cận hơn, ngay cả với những người không có nhiều kinh nghiệm lập trình.
Dù là phát hiện và đếm khúc gỗ, nhận diện cử chỉ tay, hay sử dụng mô hình thị giác–ngôn ngữ cho phát hiện đối tượng dựa trên prompt, Roboflow Workflows cho phép các nhà phát triển tạo ra các pipeline AI tùy chỉnh hoặc đa phương thức một cách đơn giản. Những khả năng này mở ra nhiều ứng dụng thực tiễn trong các lĩnh vực như lâm nghiệp, an ninh, bán lẻ, y tế và nhiều ngành khác.
- Nhận diện hình ảnh: Máy tính diễn giải hình ảnh dưới dạng dữ liệu số, và thông qua quá trình huấn luyện, chúng học cách nhận diện các mẫu và đối tượng bằng mạng nơ-ron.
- Các loại mô hình: Có nhiều loại mô hình khác nhau cho các tác vụ như phân loại, phát hiện đối tượng, phân đoạn, phát hiện keypoint, nhận diện cử chỉ tay và hiểu thị giác–ngôn ngữ.
- Roboflow Workflows: Trình xây dựng pipeline trực quan no-code/low-code, cho phép người dùng kết hợp nhiều loại mô hình và chức năng để tạo ra hệ thống nhận diện hình ảnh hoàn chỉnh.
- Mô hình huấn luyện sẵn và mô hình tùy chỉnh: Roboflow hỗ trợ cả hai hình thức — sử dụng mô hình có sẵn hoặc tự huấn luyện mô hình trên bộ dữ liệu riêng thông qua AutoML.
- Ứng dụng thực tế: Từ đếm khúc gỗ, nhận diện cử chỉ tay theo thời gian thực, đến phát hiện đối tượng dựa trên prompt với VLM, nhận diện hình ảnh có phạm vi ứng dụng rất rộng.
- Triển khai linh hoạt: Roboflow hỗ trợ triển khai trên đám mây, thiết bị edge, thiết bị di động, cùng với API và SDK được host sẵn cho suy luận theo lô hoặc thời gian thực.
Nguồn tham khảo: What Is Image Recognition AI? Algorithms and Applications
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Hoàng Diệu, Phường 12, Quận 4, Thành phố Hồ Chí Minh, Việt Nam







