
Khi bạn xây dựng các ứng dụng thị giác máy tính, bạn sẽ chắc chắn bắt gặp thuật ngữ “suy luận (inference)”. Suy luận nghĩa là chạy mô hình của bạn trên một dữ liệu đầu vào để nhận về đầu ra.
Ví dụ, hãy xét một mô hình phát hiện đối tượng được huấn luyện để nhận diện lỗi trên nắp chai. “Chạy suy luận (running inference)” trên mô hình này tức là chạy mô hình với một ảnh đầu vào. Mô hình sau đó sẽ trả về các “bounding box” tương ứng với vị trí các đối tượng trong ảnh mà mô hình được huấn luyện để nhận diện. Trong hướng dẫn này, chúng ta sẽ tìm hiểu suy luận trong thị giác máy tính là gì, các cách tiếp cận khác nhau để chạy suy luận, và cách lựa chọn máy chủ suy luận .
>>> Xem thêm:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- TOP 10 AI thiết kế website miễn phí, trả phí, hiệu quả
- Tối ưu website bằng AI là gì? Cách tối ưu SEO và các công cụ AI
- Hướng dẫn tạo Landing Page bằng AI hiệu quả nhất hiện nay

Suy luận là gì?
Suy luận trong thị giác máy tính nghĩa là chạy một mô hình AI với dữ liệu đầu vào để nhận về một dạng đầu ra nhất định. Trong bối cảnh thị giác máy tính, suy luận nghĩa là đưa một hình ảnh vào mô hình để nhận về kết quả mà mô hình đã được huấn luyện để trả về. Một mô hình phát hiện đối tượng sẽ trả về các bounding box tương ứng với các đối tượng trong ảnh; một mô hình phân đoạn (segmentation) sẽ trả về các đa giác chuẩn từng pixel của các đối tượng trong ảnh; một mô hình phân loại (classification) sẽ trả về một hoặc nhiều nhãn cho toàn bộ hình ảnh.
Các bước suy luận
Quy trình suy luận bao gồm vài bước: tiền xử lý (pre-processing), chạy suy luận (running inference), và hậu xử lý (post-processing).
Trước khi chạy mô hình, bạn có thể cần tiền xử lý dữ liệu theo một cách nào đó. Nhiều máy chủ suy luận nơi cho phép bạn chạy mô hình, sẽ tự động thay đổi kích thước hình ảnh để phù hợp với độ phân giải mà mô hình yêu cầu.
Khi dữ liệu đầu vào đã sẵn sàng, mô hình có thể “suy luận” trên dữ liệu đó. Điều này liên quan đến việc chạy tất cả các thuật toán cấp thấp mà mô hình sử dụng để tạo ra đầu ra.
Sau khi chạy mô hình, nhiều mô hình hoặc máy chủ suy luận sẽ áp dụng – hoặc có thể áp dụng nếu được cấu hình – các kỹ thuật hậu xử lý khác nhau. Với phát hiện đối tượng, ví dụ, máy chủ suy luận có thể chạy Non-Maximum Suppression (NMS). Đây là thuật toán giúp loại bỏ các bounding box trùng lặp hoặc chồng lấn quá gần nhau.
Các bước tiền xử lý và hậu xử lý để đưa một ảnh qua mô hình (tức “chạy suy luận”) sẽ khác nhau tùy theo từng mô hình.
>>> Xem thêm các bài viết khác:
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
Sau khi suy luận
Khi bạn đã có kết quả từ bước suy luận (bounding box cho phát hiện đối tượng, mặt nạ phân đoạn cho segmentation, nhãn cho classification, v.v.), bước tiếp theo là tích hợp kết quả này vào ứng dụng của bạn. Trong bối cảnh ứng dụng doanh nghiệp, bước này có thể được hiểu là triển khai logic nghiệp vụ.
Ví dụ, bạn có thể đang chạy một mô hình phát hiện đối tượng được huấn luyện để nhận diện lỗi trên dây chuyền sản xuất. Nếu mô hình phát hiện lỗi, dây chuyền có thể được thiết lập để tự động chuyển sản phẩm lỗi sang khu vực kiểm tra thủ công. Lỗi này cũng có thể được ghi lại để dây chuyền theo dõi tỷ lệ xuất hiện lỗi theo thời gian.
Suy luận đồng bộ và bất đồng bộ
Các mô hình có thể được chạy theo thời gian thực (đồng bộ) hoặc theo lô (bất đồng bộ). Phương pháp bạn chọn phụ thuộc vào yêu cầu kinh doanh và tốc độ chạy của mô hình đã được huấn luyện.
Chạy suy luận theo thời gian thực
Nhiều mô hình thị giác máy tính tiên tiến có thể chạy trong thời gian thực. Ví dụ, RF-DETR – mô hình phát hiện đối tượng tiên tiến hiện nay – có thể chạy hàng chục khung hình mỗi giây trên GPU NVIDIA như T4.
Để chạy suy luận thời gian thực, bạn thường sẽ huấn luyện một mô hình nhỏ hơn. Trong thị giác máy tính, các mô hình nhỏ thường được gán nhãn như Nano hoặc Small. Mô hình càng nhỏ thì tốc độ chạy càng nhanh.
Có nhiều trường hợp mô hình cần chạy thời gian thực, ví dụ:
- Nếu bạn kiểm tra sản phẩm trên dây chuyền sản xuất, bạn cần hiệu năng thời gian thực.
- Nếu bạn giám sát camera an ninh qua đêm để phát hiện người ra vào tòa nhà, bạn sẽ cần khả năng xử lý thời gian thực.
- Nếu bạn xây dựng ứng dụng di động có tính tương tác, mô hình phải chạy thời gian thực để duy trì trải nghiệm người dùng.
Các mô hình có khả năng chạy thời gian thực thường xử lý trong vài mili-giây (ms). Đơn vị ms được sử dụng phổ biến để đo thời gian suy luận trong các bảng benchmark. Ví dụ, bản Nano của RF-DETR có thể trả về dự đoán trong 2.32ms trên GPU NVIDIA T4.
>>> Xem thêm: Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow
Chạy suy luận theo lô
Cũng có những trường hợp bạn muốn chạy mô hình theo cách bất đồng bộ. Điều này nghĩa là chạy mô hình vào bất kỳ thời điểm nào, chẳng hạn theo lịch trình định sẵn hàng ngày. Việc chạy mô hình trên dữ liệu theo lô được gọi là “xử lý theo lô” (batch processing).
Batch processing thường được dùng để xử lý lượng lớn dữ liệu đã thu thập, nơi bạn không cần kết quả ngay lập tức. Ví dụ, bạn có thể xử lý một kho lưu trữ lớn gồm video hoặc hình ảnh theo lô, hoặc xử lý toàn bộ dữ liệu thu thập trong ngày vào cuối ngày.
Chạy suy luận trong thị giác máy tính
Có hai cách chính để chạy một mô hình thị giác máy tính:
- Sử dụng SDK được cung cấp cùng mô hình, chẳng hạn như gói Python cho RF-DETR;
- Sử dụng một máy chủ suy luận (Inference Server) như Roboflow Inference.
Các SDK do mô hình cung cấp thường chứa sẵn mọi thứ bạn cần để chạy mô hình. Tuy nhiên, chúng thường thiếu một số tính năng cần thiết trong môi trường vận hành thực tế. Ví dụ, SDK thường phải bao bọc trong code bổ sung để triển khai thành REST API, hoặc cần mở rộng thêm để hỗ trợ xử lý video.
Đây chính là lúc máy chủ suy luận phát huy tác dụng.
Máy chủ suy luận cho phép bạn chạy mô hình như một “microservice”. Điều này nghĩa là mô hình của bạn có thể chạy như một endpoint mà mọi ứng dụng đều có thể gọi tới, thay vì chạy trực tiếp trong mã nguồn ứng dụng.
Chạy mô hình dưới dạng microservice mang lại nhiều lợi ích. Thứ nhất, microservice có thể mở rộng với công cụ hạ tầng hiện đại như Kubernetes để đáp ứng khối lượng xử lý thay đổi.
Thứ hai, microservice được tách biệt khỏi phần còn lại của ứng dụng, nghĩa là bạn có thể quản lý các dependencies của mô hình trong một môi trường riêng. Điều này đặc biệt quan trọng vì nhiều mô hình thị giác có rất nhiều dependencies và khó cấu hình, nhất là khi triển khai trên thiết bị edge GPU như NVIDIA Jetson với TensorRT.
Máy chủ suy luận còn tích hợp nhiều công cụ hỗ trợ xây dựng logic phía trên mô hình. Ví dụ, Roboflow Inference cho phép bạn chạy Workflows.
Workflows là các ứng dụng thị giác máy tính đa giai đoạn được xây dựng xoay quanh một mô hình. Bạn có thể xây dựng Workflows trong giao diện web bằng cách sử dụng trọng số mô hình của bạn, sau đó lấy mã nguồn để chạy Workflow trên phần cứng của mình.
>>> Xem thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Các mô hình phát hiện đối tượng tốt nhất
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
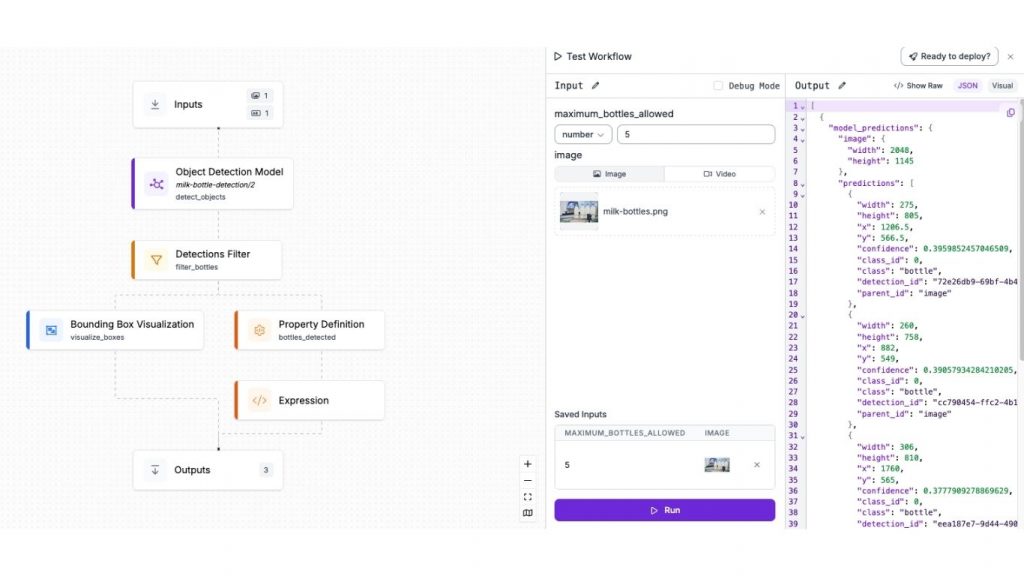
Bạn có thể dùng Roboflow Workflows để theo dõi đối tượng trong video, làm mượt dự đoán giữa các khung hình, lọc kết quả dự đoán, chạy thuật toán đồng thuận với nhiều mô hình, và nhiều hơn nữa.
Cần xem gì khi chọn máy chủ để suy luận
Hiện có nhiều máy chủ suy luận mà bạn có thể dùng để chạy mô hình. Khi lựa chọn, bạn cần chú ý một số yếu tố sau:
Đầu tiên, hãy xem máy chủ suy luận hỗ trợ những mô hình nào. Nó có hỗ trợ các mô hình tiên tiến không? Tiếp theo, hãy xem dữ liệu benchmark có sẵn. Máy chủ suy luận chạy nhanh đến mức nào? Nhiều máy chủ còn cho phép bạn tự chạy benchmark để đánh giá hiệu năng trên chính phần cứng của mình.
Sau đó, hãy xem các tính năng mà máy chủ cung cấp có phù hợp với yêu cầu của bạn không. Nếu bạn xử lý video, hãy chọn máy chủ có hỗ trợ tính năng video. Roboflow Inference hỗ trợ theo dõi đối tượng trong video, làm mượt dự đoán và nhiều công cụ khác.
Máy chủ suy luận cũng có thể cung cấp công cụ giám sát mô hình và thiết bị. Roboflow Inference có bản mở rộng dành cho doanh nghiệp giúp kiểm tra tình trạng thiết bị, cập nhật mô hình, thiết lập Workflows mới và nhiều chức năng tiện ích khác.
>>> Xem thêm:
- TOP 20 công cụ Chat AI tiếng Việt miễn phí thông minh phổ biến
- TOP 25 công cụ AI miễn phí, phổ biến, tốt nhất hiện nay
- Cách sử dụng AI trong phát triển phần mềm như thế nào?
- Ứng dụng AI trong bán hàng online: TOP 10 công cụ AI & cách triển khai hiệu quả
Kết luận về suy luận trong thị giác máy tính
Suy luận trong thị giác máy tính là quá trình chạy một mô hình.
Trước khi chạy suy luận, mô hình có thể tiền xử lý dữ liệu đầu vào (ví dụ: hình ảnh) để phù hợp với mô hình. Sau đó mô hình sẽ “chạy suy luận” và trả về dự đoán. Loại dự đoán sẽ thay đổi theo từng mô hình (bounding box cho object detection, mask cho segmentation, v.v.).
Kết quả từ suy luận có thể được tích hợp vào ứng dụng. Ví dụ, bạn có thể ghi log lại kết quả hoặc sử dụng kết quả trong logic nghiệp vụ tiếp theo.
Bạn có thể chạy mô hình trực tiếp bằng phần mềm của mô hình hoặc dùng máy chủ suy luận. Máy chủ suy luận không chỉ chạy mô hình mà còn cung cấp các tiện ích bổ sung như công cụ xử lý video, giám sát mô hình và thiết bị, v.v.
Sẵn sàng bắt đầu chạy suy luận trên mô hình chưa? Hãy xem bộ sưu tập 100+ template ứng dụng thị giác máy tính của chúng tôi. Tất cả template đều bao gồm mô hình có thể chạy ngay và logic bổ sung sử dụng đầu ra từ suy luận của mô hình.
Nguồn tham khảo: Inference in Computer Vision: How to Run & Deploy AI Models
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Hoàng Diệu, Phường 12, Quận 4, Thành phố Hồ Chí Minh, Việt Nam







