
Phân tích hình ảnh bằng AI giúp máy móc không chỉ nhìn thấy hình ảnh mà còn hiểu, diễn giải và đưa ra quyết định thông minh từ dữ liệu thị giác. Từ phát hiện kệ hàng trống trong bán lẻ đến nhận diện đối tượng, đọc văn bản và phân tích ngữ cảnh, công nghệ này đang trở thành nền tảng quan trọng cho các hệ thống AI hiện đại, hỗ trợ doanh nghiệp tối ưu vận hành và ra quyết định theo thời gian thực. Bài viết này sẽ giúp bạn hiểu rõ phân tích hình ảnh AI là gì, cách công nghệ này hoạt động phía sau các mô hình thị giác máy tính.
>>> Xem thêm các bài viết:
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
- Cách tạo ứng dụng AI với vibe coding trên Google AI Studio đơn giản
- Cách sử dụng AI trong phát triển phần mềm như thế nào?
- Hướng dẫn triển khai AI trong ứng dụng di động đơn giản
Mở đầu
Hãy cùng khám phá cách phân tích hình ảnh AI biến những bức ảnh thông thường thành các quyết định thông minh trong kinh doanh. Trước hết, hãy bắt đầu với một tình huống quen thuộc:
Đó là một sáng thứ Bảy đông đúc tại siêu thị. Người quản lý cửa hàng đang đi về phía quầy hàng số năm, với kỳ vọng rằng các kệ snack đã được lấp đầy để phục vụ lượng khách cuối tuần. Nhưng ngay cả khi chưa kịp tới nơi, máy tính bảng của anh rung lên với một thông báo: “Kệ khoai tây chiên trống – Hàng 3, Khu B.”
Anh mở thông báo và thấy hình ảnh trực tiếp từ camera lắp phía trên lối đi. Một khung màu đỏ đánh dấu chính xác vị trí đang thiếu sản phẩm. Không cần đi kiểm tra từng kệ hay chờ nhân viên phát hiện ra vấn đề, mọi thứ đã được hệ thống xử lý trước đó.
Lý do là vì một hệ thống phân tích hình ảnh AI đang liên tục theo dõi các kệ hàng. Hệ thống này có thể nhận biết khi sản phẩm hết hàng, đối chiếu với sơ đồ bố trí của cửa hàng và thậm chí xác định khoảng thời gian kệ đã trống. Trước đây, việc bổ sung hàng hóa chậm trễ khiến khách hàng rời đi trong thất vọng và doanh thu bị thất thoát. Ngày nay, nhờ AI phân tích hình ảnh, các kệ hàng luôn được duy trì đầy đủ và hoạt động vận hành trở nên trơn tru hơn.
Camera giờ đây không chỉ đơn thuần là thiết bị ghi hình. Chúng có khả năng phân tích, so sánh và đưa ra quyết định. Trong lĩnh vực bán lẻ, phân tích hình ảnh AI có thể theo dõi mức tồn kho, lập bản đồ hành vi di chuyển của khách hàng và thậm chí phát hiện các hành vi bất thường.
Vậy công nghệ này hoạt động như thế nào? Làm sao một hệ thống máy tính có thể nhận biết rằng một sản phẩm đang bị thiếu trên kệ hàng chỉ thông qua hình ảnh?
>>> Xem thêm các bài viết liên quan:
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
Phân tích hình ảnh bằng AI là gì?
Phân tích hình ảnh bằng AI là quá trình sử dụng trí tuệ nhân tạo (AI) để tự động phân tích, diễn giải và trích xuất thông tin có ý nghĩa từ hình ảnh kỹ thuật số. Công nghệ này giúp máy móc có khả năng “nhìn” và hiểu dữ liệu thị giác theo cách mô phỏng, thậm chí vượt qua con người trong một số tác vụ cụ thể.
Nói cách khác, phân tích hình ảnh AI ứng dụng các kỹ thuật machine learning và deep learning để tự động xử lý và hiểu nội dung hình ảnh, cho phép hệ thống thực hiện các tác vụ sau:
- Phát hiện và phân loại đối tượng như con người, xe cộ, động vật
- Nhận diện khuôn mặt và cảm xúc
- Xác định mẫu hình, điểm bất thường hoặc lỗi trong hình ảnh
- Nhận dạng và trích xuất văn bản từ ảnh (OCR)
- Phân đoạn hình ảnh thành các vùng khác nhau (ví dụ: phân biệt mô khối u và mô khỏe mạnh trong ảnh y tế)
Có AI nào có thể phân tích hình ảnh không?
Có. AI hiện đại đã phát triển đến mức không chỉ có thể nhìn hình ảnh mà còn hiểu, diễn giải và phân tích hình ảnh tương tự con người — thậm chí tốt hơn con người trong một số tác vụ cụ thể. Năng lực này được gọi là phân tích hình ảnh AI (AI Image Analysis) và được vận hành bởi các mô hình deep learning chuyên xử lý dữ liệu thị giác.
Nhờ AI phân tích hình ảnh, các hệ thống có thể thực hiện nhiều tác vụ phức tạp trên hình ảnh, bao gồm:
- Nhận diện đối tượng (ví dụ: mèo, xe hơi, khối u)
- Phân loại bối cảnh/khung cảnh (bãi biển, rừng, siêu thị…)
- Phân đoạn hình ảnh (tách đối tượng như con chó ra khỏi nền)
- Phát hiện bất thường hoặc lỗi (vết nứt trong máy móc, lỗi sản phẩm)
- Hiểu và trích xuất văn bản trong ảnh
- Trả lời câu hỏi dựa trên hình ảnh (ví dụ: “Có bao nhiêu người trong bức ảnh này?”)
Hiện nay, AI có thể phân tích hình ảnh thường được chia thành các nhóm chính sau:
- Các mô hình nền tảng thị giác máy tính
- Mô hình ngôn ngữ thị giác
- Mô hình đa phương thức
- LLM có khả năng xử lý hình ảnh
Các mô hình nền tảng thị giác máy tính
Đây là các mô hình được huấn luyện chỉ trên dữ liệu hình ảnh, chủ yếu xây dựng dựa trên Mạng nơ-ron tích chập (Convolutional Neural Networks – CNNs) hoặc Vision Transformers (ViTs). Đây đều là những kiến trúc mô hình thị giác máy tính tiên tiến nhất hiện nay, có thể sử dụng ngay để huấn luyện với bộ dữ liệu tùy chỉnh của bạn.
Các mô hình này được thiết kế để giải quyết những bài toán thị giác cụ thể như:
- Phân loại hình ảnh (classification)
- Phát hiện đối tượng (detection)
- Phân đoạn ảnh (segmentation)
- Nhận thức và hiểu không gian 3D (3D understanding)
Dựa trên nhiệm vụ mà mô hình có thể thực hiện, chúng được chia thành các nhóm con sau:
Mô hình phân loại hình ảnh
Mô hình phân loại hình ảnh được dùng để gán một nhãn duy nhất cho toàn bộ hình ảnh. Ví dụ điển hình là ResNet-50, một mô hình CNN phổ biến trong các bài toán nhận diện và phân loại hình ảnh.
>>> Xem thêm:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất

Mô hình phát hiện đối tượng
Các mô hình phát hiện đối tượng có khả năng xác định vị trí và phân loại nhiều đối tượng trong một hình ảnh thông qua bounding box (khung bao).
Ví dụ: RF-DETR

Mô hình phân đoạn hình ảnh
Các mô hình phân đoạn hình ảnh gán nhãn cho từng pixel trong ảnh, bao gồm:
- Semantic Segmentation (phân đoạn ngữ nghĩa)
- Instance Segmentation (phân đoạn theo từng thực thể)
Ví dụ: YOLOv8 Instance Segmentation
>>> Xem thêm:
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
- Các mô hình phát hiện đối tượng tốt nhất

Mô hình phát hiện keypoint / ước lượng tư thế
Các mô hình này phát hiện các keypoint (điểm mốc) như khớp xương hoặc landmark khuôn mặt để phân tích chuyển động, tư thế hoặc hành vi của cơ thể.
Ví dụ: YOLO NAS Pose, YOLOv8 Pose Estimation

Vision-Language Model (VLM)
VLM (Mô hình Thị giác – Ngôn ngữ) là các mô hình được huấn luyện sẵn, được thiết kế để xử lý đồng thời hình ảnh và ngôn ngữ. VLM đóng vai trò như mô hình nền tảng để fine-tune cho nhiều tác vụ hạ nguồn như:k
- Tạo mô tả hình ảnh
- Hỏi đáp dựa trên hình ảnh
- Truy xuất ảnh – văn bản
Các VLM được huấn luyện trên tập dữ liệu lớn gồm các cặp hình ảnh – văn bản và thường được sử dụng như xương sống trong các hệ thống AI đa phương thức, đặc biệt trong phân tích hình ảnh A
Mô hình đa phương thức
Mô hình đa phương thức là hệ thống AI có khả năng suy luận trên nhiều loại dữ liệu khác nhau, chẳng hạn như:
- Văn bản
- Hình ảnh
- Âm thanh
- Video
Do có khả năng hiểu hình ảnh, các mô hình đa phương thức có thể được sử dụng hiệu quả cho AI phân tích hình ảnh, đồng thời mở rộng sang các tác vụ phức tạp hơn kết hợp nhiều nguồn dữ liệu.
Ví dụ: GPT-4o, Google Gemini
Mô hình ngôn ngữ lớn có khả năng xử lý hình ảnh
Đây là các mô hình ngôn ngữ lớn (Large Language Models – LLMs) như GPT hoặc Claude, được mở rộng để chấp nhận hình ảnh làm dữ liệu đầu vào, đồng thời có khả năng phân tích và suy luận về nội dung thị giác bằng ngôn ngữ tự nhiên.
Đặc điểm của nhóm mô hình này:
- Kiến trúc lấy ngôn ngữ làm trung tâm , sau đó tích hợp thêm giao diện xử lý thị giác
- Được huấn luyện hoặc fine-tune trên tập dữ liệu cặp ảnh – văn bản
- Phù hợp cho các tác vụ phân tích hình ảnh AI mang tính diễn giải và suy luận
Có AI nào có thể mô tả hình ảnh không?
Có, hiện nay đã có AI có khả năng mô tả hình ảnh. Việc mô tả hình ảnh là một phần quan trọng của phân tích hình ảnh bằng AI, thuộc nhóm kỹ thuật được gọi là Image Captioning hoặc Vision–Language Understanding (Hiểu thị giác – ngôn ngữ).
Trong quá trình mô tả hình ảnh, AI sẽ tự động tạo ra các mô tả bằng văn bản cho hình ảnh đầu vào bằng cách hiểu nội dung xuất hiện trong ảnh. Các hệ thống AI này kết hợp:
- Thị giác máy tính (Computer Vision) để phân tích và diễn giải hình ảnh
- Xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) để diễn đạt nội dung hình ảnh bằng ngôn ngữ con người
Nhờ đó, máy móc không chỉ có thể “nhìn” mà còn hiểu và giải thích dữ liệu thị giác dưới dạng văn bản dễ đọc.
Quá trình mô tả hình ảnh bằng AI thường được thực hiện theo các bước sau:
Bước 1: Phân tích hình ảnh để nhận diện đối tượng, con người, bối cảnh, hành động và các mối quan hệ không gian.
Bước 2: Hiểu ngữ cảnh tổng thể của hình ảnh (ví dụ: điều gì đang xảy ra, ai đang làm gì).
Bước 3: Sinh ra một câu mô tả mạch lạc phản ánh chính xác nội dung mà hệ thống đã hiểu.
Nó bao gồm các thành phần sau:
- Phát hiện đối tượng: Trong ảnh có những đối tượng nào?
- Nhận diện hành động: Các đối tượng đang làm gì?
- Hiểu bối cảnh: Sự việc diễn ra ở đâu?
- Quan hệ thị giác: Các đối tượng trong ảnh liên hệ với nhau như thế nào?
Vì vậy, mô tả hình ảnh không chỉ đơn thuần là một bài toán ngôn ngữ, mà bản chất là một bài toán phân tích hình ảnh AI chuyên sâu, dựa trên nền tảng thị giác máy tính.
>>> Xem thêm:
- LLMs.txt là gì? Có nên sử dụng không?
- TOP 30 công cụ AI miễn phí, phổ biến, hỗ trợ học tập và làm việc hiệu quả
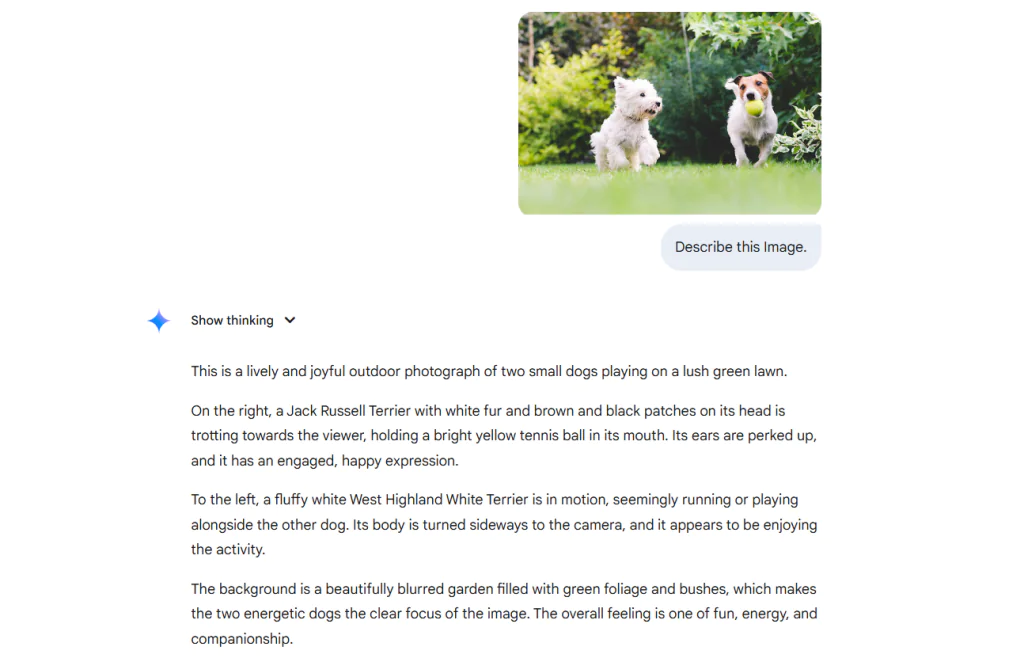
AI mô tả hình ảnh hoạt động như thế nào?
Hãy cùng tìm hiểu cách AI mô tả hình ảnh hoạt động thông qua ví dụ về PaliGemma – một Vision-Language Model (VLM) do Google phát triển, sở hữu khả năng đa phương thức. Nhờ khả năng xử lý đồng thời hình ảnh và ngôn ngữ, PaliGemma có thể được sử dụng để mô tả nội dung hình ảnh.
Sơ đồ minh họa cách PaliGemma xử lý hình ảnh đầu vào kết hợp với prompt văn bản để tạo ra phản hồi bằng ngôn ngữ tự nhiên, thể hiện rõ khả năng suy luận đa phương thức của mô hình. Đặc biệt, cơ chế này rất phù hợp cho các tác vụ như hỏi–đáp dựa trên hình ảnh.
>>> Xem thêm:
- Học Máy Là Gì Và Tại Sao Học Máy Lại Quan Trọng?
- Khả năng thị giác của Chat GPT-5 và Cách Prompt hiệu quả
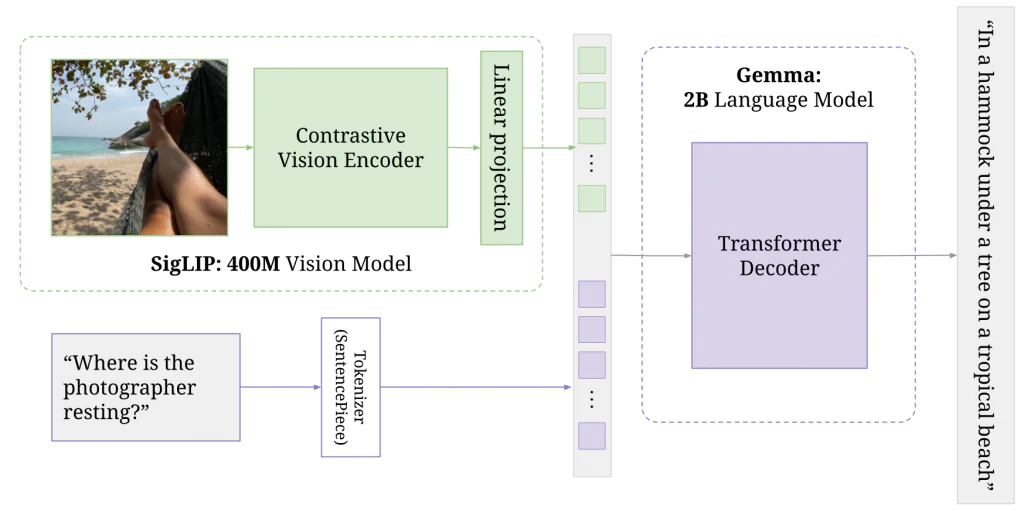
Quy trình được minh họa trong hình trên cho thấy cách PaliGemma xử lý hình ảnh kết hợp với một câu hỏi bằng ngôn ngữ tự nhiên để tạo ra phản hồi thông minh và có cơ sở ngữ cảnh. Dữ liệu đầu vào bao gồm một bức ảnh chụp một người đang nằm nghỉ trên võng tại một bãi biển nhiệt đới, cùng với prompt văn bản hỏi: “Nhiếp ảnh gia đang nghỉ ngơi ở đâu?”.
Hình ảnh này trước tiên được đưa qua SigLIP — một contrastive vision encoder (bộ mã hóa thị giác đối chiếu) nhỏ gọn với 400 triệu tham số. SigLIP trích xuất các đặc trưng thị giác cấp cao từ hình ảnh (như võng, cây, bàn chân và bãi biển), sau đó chuyển chúng thành các biểu diễn số dạng vector dày. Các embedding thị giác này tiếp tục được biến đổi thông qua phép chiếu tuyến tính để phù hợp với định dạng đầu vào mà bộ giải mã yêu cầu, giúp căn chỉnh thông tin thị giác và ngôn ngữ.
Song song đó, câu hỏi văn bản được token hóa bằng SentencePiece — một subword tokenizer chia câu thành các token nhỏ hơn mà mô hình có thể xử lý. Cả đặc trưng thị giác và câu hỏi đã được token hóa đều được đưa vào mô hình ngôn ngữ Gemma, một transformer decoder có 2 tỷ tham số.
Gemma sử dụng ngữ cảnh đa phương thức này kết hợp những gì mô hình nhìn thấy và được hỏi để sinh ra một câu trả lời mạch lạc và chính xác theo ngữ cảnh. Cuối cùng, mô hình tạo ra phản hồi: “trên một chiếc võng dưới gốc cây tại một bãi biển nhiệt đới.”
Ví dụ này minh họa cách PaliGemma thực hiện suy luận đa phương thức, không chỉ đơn thuần nhận diện đối tượng hay tạo mô tả chung chung, mà còn kết nối nội dung hình ảnh với ngôn ngữ tự nhiên để đưa ra các câu trả lời chi tiết và có ý nghĩa, một năng lực cốt lõi trong phân tích hình ảnh AI hiện đại..
Vai trò của thị giác máy tính trong phân tích hình ảnh bằng AI là gì?
Thị giác máy tính (Computer Vision) đóng vai trò là nền tảng cốt lõi phía sau các hệ thống phân tích hình ảnh bằng AI, cho phép máy móc nhận biết và hiểu nội dung dữ liệu thị giác như hình ảnh và video. Về bản chất, thị giác máy tính giúp chuyển đổi các giá trị pixel thô thành những biểu diễn có ý nghĩa, để hệ thống AI có thể diễn giải và đưa ra hành động phù hợp.
Điều này đạt được nhờ các thuật toán tiên tiến và mô hình deep learning (ví dụ: Convolutional Neural Networks – CNNs, Vision Transformers – ViTs) có khả năng nhận diện mẫu hình, hình dạng, cạnh, kết cấu và màu sắc trong ảnh. Những đặc trưng thị giác được học này là nền tảng cho các tác vụ hạ nguồn như nhận diện đối tượng, phân đoạn hình ảnh và hiểu bối cảnh.
Một trong những vai trò quan trọng nhất của computer vision là phát hiện và nhận diện đối tượng (object detection & recognition). Tác vụ này cho phép hệ thống AI xác định và định vị các đối tượng khác nhau trong hình ảnh (như con người, phương tiện, động vật hoặc công cụ) bằng cách vẽ bounding box và gán nhãn lớp (class label) cho từng đối tượng.
Ngoài phát hiện đối tượng, thị giác máy tính còn hỗ trợ:
- Semantic segmentation: Gán nhãn cho từng pixel theo lớp đối tượng (ví dụ: bầu trời, mặt đường, xe hơi).
- Instance segmentation: Phân biệt các cá thể khác nhau trong cùng một lớp đối tượng.
Thị giác máy tính cũng giữ vai trò then chốt trong nhiều bài toán phân tích chuyên sâu:
- Nhận dạng ký tự quang học: Cho phép AI phát hiện và trích xuất văn bản từ hình ảnh, hỗ trợ số hóa tài liệu và dịch ngôn ngữ.
- Ước lượng tư thế: Giúp xác định và theo dõi các keypoint trên cơ thể người, được ứng dụng trong fitness app, nhận diện cử chỉ và tương tác người – máy.
Computer vision cũng là thành phần cốt lõi của các hệ thống AI đa phương thức, nơi dữ liệu thị giác được kết hợp với văn bản hoặc âm thanh để thực hiện các tác vụ phức tạp hơn. Ví dụ, trong các mô hình như PaliGemma, computer vision chính là thành phần giúp mô hình có thể “nhìn” hình ảnh. Cụ thể, vision encoder SigLIP xử lý hình ảnh đầu vào (ví dụ: một người đang nằm nghỉ trên võng tại bãi biển) và trích xuất các đặc trưng thị giác cấp cao như võng, cây, cát.
Nhờ thị giác máy tính, mô hình không chỉ nhận diện đối tượng mà còn hiểu toàn cảnh và ngữ cảnh, từ đó tạo ra các phản hồi phù hợp với nội dung hình ảnh. Đây chính là nền tảng thị giác cho suy luận đa phương thức thông minh, đặc biệt trong các tác vụ mô tả hình ảnh như PaliGemma thực hiện.
Theo mô tả trong bài báo nghiên cứu, SigLIP được xây dựng dựa trên nền tảng của CLIP. Kiến trúc SigLIP bao gồm:
- Image Encoder (bộ mã hóa hình ảnh)
- Text Encoder (bộ mã hóa văn bản)
- Hàm mất mát dựa trên sigmoid (sigmoid-based loss function)
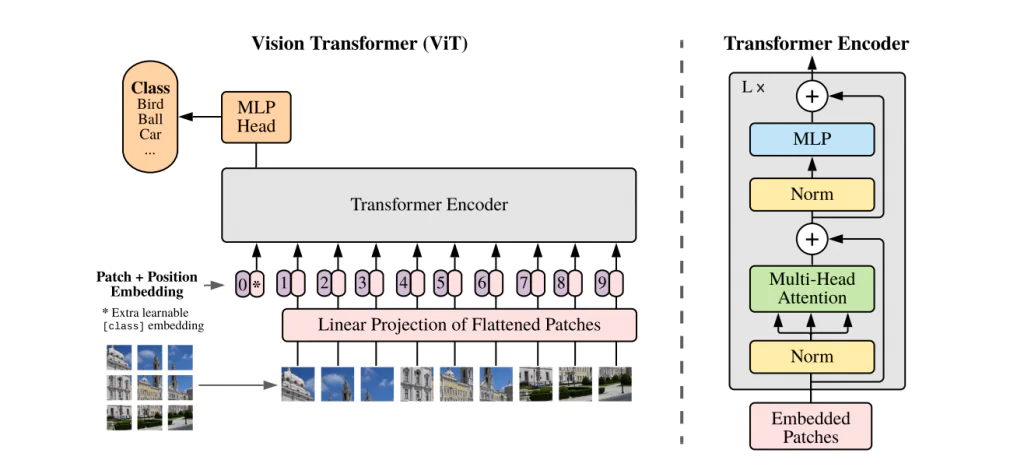
SigLIP sử dụng Vision Transformer (ViT) làm image encoder. ViT xử lý hình ảnh bằng cách chia ảnh thành các patch có kích thước cố định, sau đó embedding tuyến tính và đưa vào transformer encoder. Cách tiếp cận này giúp mô hình nắm bắt được cả quan hệ cục bộ và toàn cục trong hình ảnh.
Do đó, ViT – một kiến trúc áp dụng Transformer cho các bài toán thị giác máy tính đóng vai trò là thành phần nền tảng trong việc hiểu hình ảnh của SigLIP.
>>> Xem thêm:
- Hệ thống kiểm tra thị giác (VIS) là gì?
- Các Nhiệm Vụ Của Thị Giác Máy Tính và cách thực hiện chúng nhanh chóng
Vision Transformer (ViT) được thiết kế chuyên biệt cho các tác vụ computer vision, xử lý hình ảnh bằng cách chia nhỏ thành patch và áp dụng kiến trúc Transformer. Điều này cho phép ViT:
- Nắm bắt quan hệ cục bộ và toàn cục trong ảnh
- Hoạt động hiệu quả cho các tác vụ như:
- Phân loại hình ảnh (Image Classification)
- Phát hiện đối tượng (Object Detection)
- Phân đoạn hình ảnh (Image Segmentation)
- Tác vụ đa phương thức (kết hợp hình ảnh với văn bản cho image captioning, visual question answering)
Ví dụ phân tích hình ảnh bằng AI
Phân tích hình ảnh bằng AI là quá trình trích xuất thông tin có ý nghĩa từ dữ liệu thị giác. Dưới đây là các tác vụ phân tích hình ảnh AI phổ biến. Trong các ví dụ này, chúng tôi sử dụng Roboflow Workflows.
Đọc văn bản từ hình ảnh (Optical Character Recognition – OCR)
Đọc văn bản từ hình ảnh bao gồm việc phát hiện và trích xuất ký tự in hoặc viết tay từ nội dung thị giác. Tác vụ này yêu cầu:
- Xác định vùng chứa văn bản
- Nhận dạng từng ký tự
- Chuyển đổi thành văn bản máy có thể đọc
Hệ thống OCR được huấn luyện để xử lý nhiều loại font chữ, kích thước, hướng chữ, kể cả hình ảnh nhiễu hoặc chất lượng thấp. Quy trình OCR thường bao gồm phát hiện văn bản, nhận dạng văn bản và hậu xử lý định dạng.
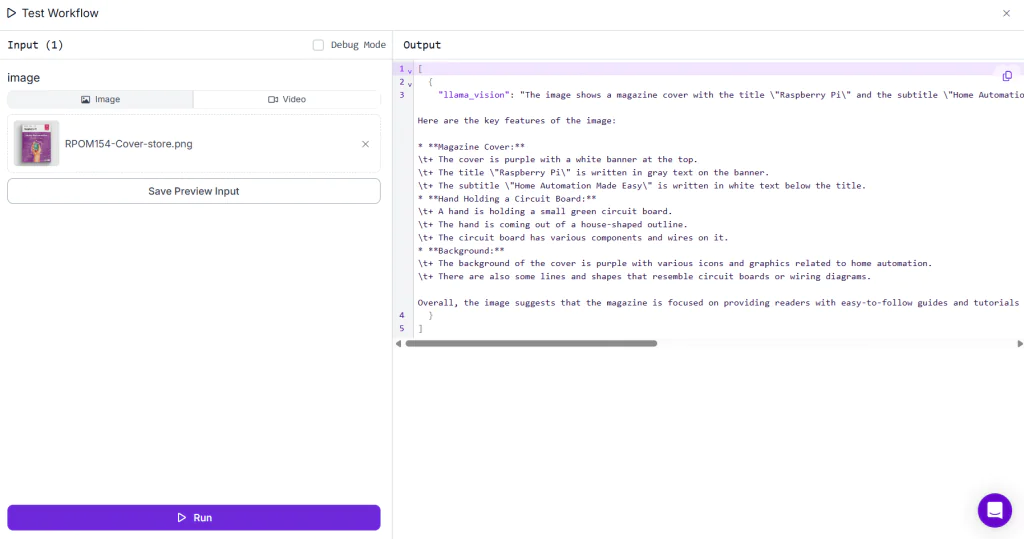
Trong ví dụ này, chúng tôi sử dụng mô hình Llama 3.2 Vision để trích xuất văn bản từ hình ảnh, thông qua workflow với cấu hình Llama 3.2 Vision.
>>> Xem thêm:
- Phát hiện đối tượng trong video với RF-DETR
- Suy Luận Trong Thị Giác Máy Tính: Cách Thực Hiện & Triển Khai Mô Hình AI
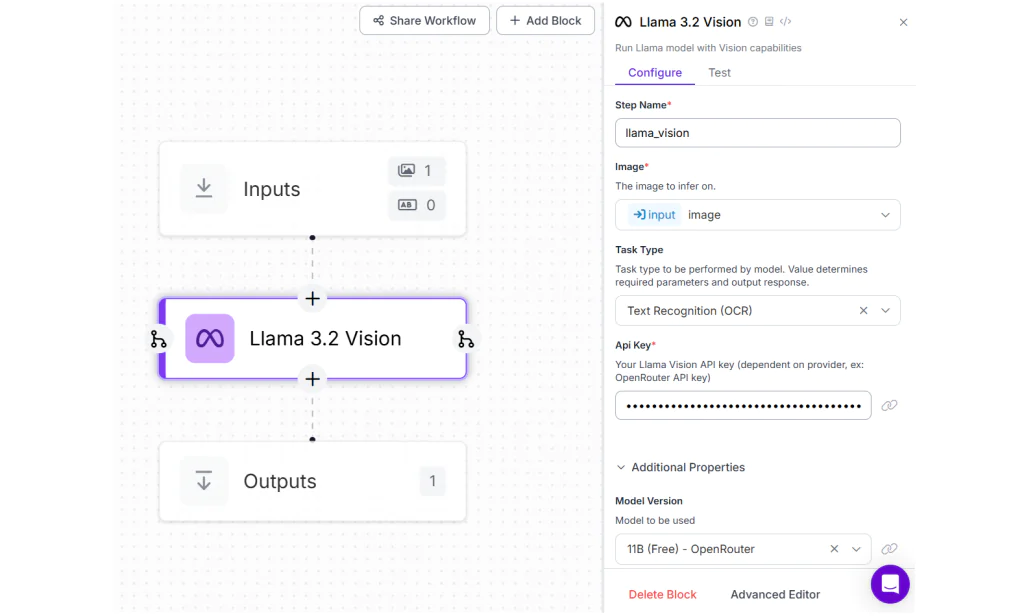
Khi chạy workflow và tải lên bất kỳ hình ảnh có văn bản, bạn sẽ nhận được kết quả đầu ra tương tự như minh họa.
Phát hiện con người trong hình ảnh
Phát hiện con người trong hình ảnh là quá trình xác định và định vị các cá thể con người trong một khung cảnh. Tác vụ này sử dụng object detection để vẽ bounding box quanh từng người và gán nhãn “person”.
Ngoài ra, tác vụ này còn có thể mở rộng sang:
- Đếm số người
- Theo dõi chuyển động
- Phân tích tư thế
Các mô hình được huấn luyện trên dataset đa dạng để xử lý nhiều góc nhìn, điều kiện ánh sáng, trang phục và che khuất khác nhau. Ứng dụng phổ biến gồm giám sát an ninh, phân tích đám đông và hệ thống tự hành.
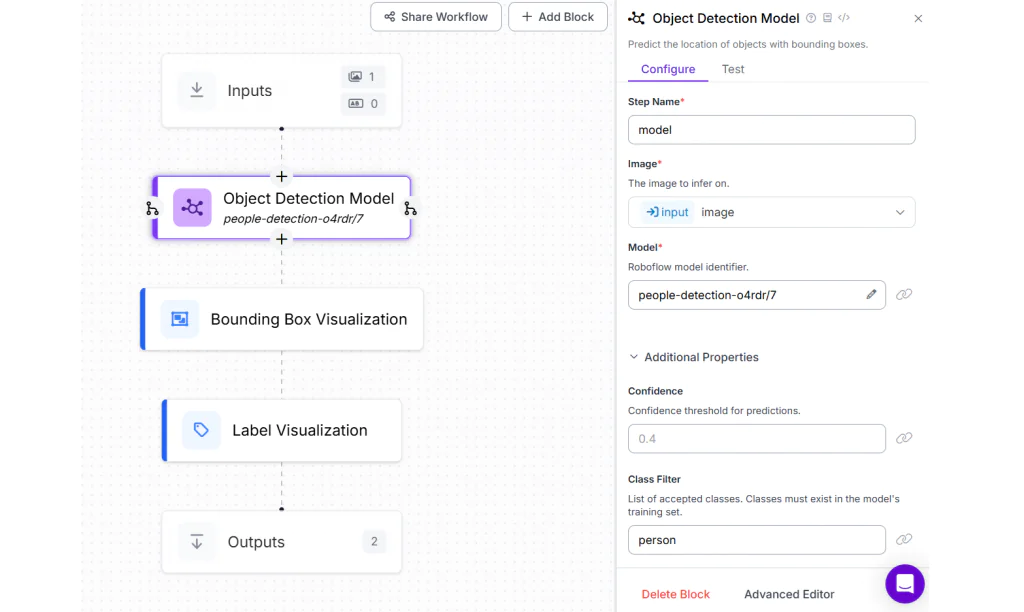
Trong ví dụ này, chúng tôi sử dụng People Detection model của Roboflow. Hãy tạo một Roboflow workflow với:
- Khối object detection cấu hình mô hình phát hiện người
- Bộ lọc lớp (class filter) là “person”
- Thêm Bounding Box Visualization và Label Visualization
Workflow hoàn chỉnh sẽ có cấu trúc tương tự như hình minh họa.
>>> Xem thêm:
- TOP 20 công cụ Chat AI tiếng Việt miễn phí thông minh phổ biến
- Character AI là gì? Trò chuyện cùng nhân vật ảo trên mô hình mới
Chạy Workflow sẽ tạo ra kết quả tương tự như sau.

Phát hiện đối tượng trong hình ảnh
Phát hiện đối tượng à nhiệm vụ xác định và định vị nhiều đối tượng khác nhau trong một hình ảnh, mỗi đối tượng được biểu diễn bằng bounding box (khung bao) và nhãn (label). Nhiệm vụ này bao gồm việc nhận diện các lớp đối tượng khác nhau như xe cộ, con người, động vật, công cụ và xác định vị trí chính xác của chúng trong ảnh.
Khác với phân loại hình ảnh chỉ gán một nhãn duy nhất cho toàn bộ hình ảnh – object detection có thể trả về nhiều kết quả phát hiện trong cùng một ảnh. Kỹ thuật này được ứng dụng rộng rãi trong robot học, bán lẻ, sản xuất và xe tự hành.
Trong ví dụ này, chúng ta sẽ sử dụng Workflow tương tự như trên, chỉ cần thay đổi mô hình sang RF-DETR Base và đặt class filter là “football”, vì lần này chúng ta đang phát hiện một đối tượng thay vì con người.
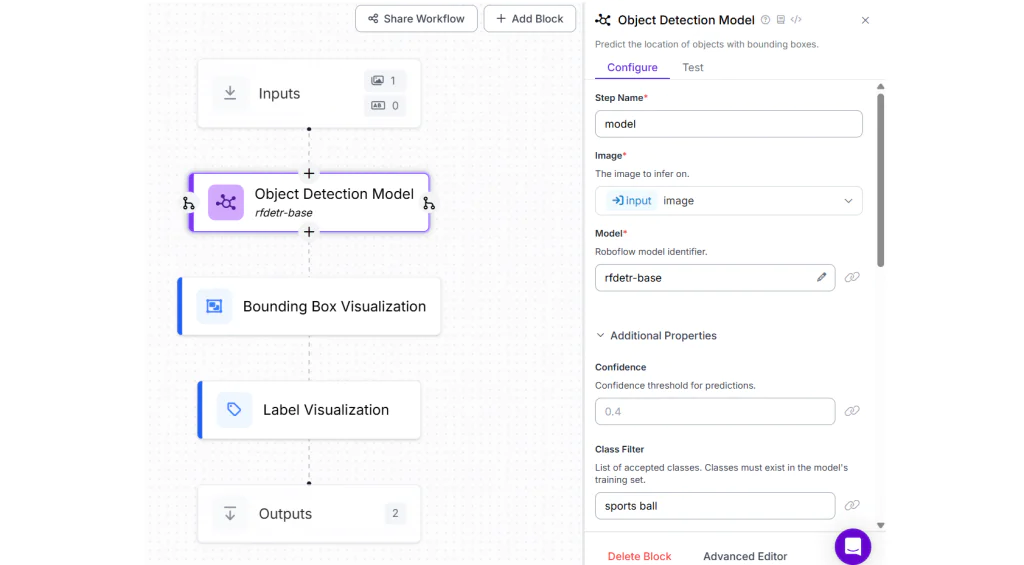
Bạn sẽ thấy kết quả đầu ra tương tự như sau.

Phát hiện điểm mốc trong hình ảnh (Ước lượng tư thế / Nhận diện landmark)
Phát hiện keypoint là nhiệm vụ xác định các điểm có ý nghĩa trên một đối tượng hoặc con người trong hình ảnh, chẳng hạn như các khớp (khuỷu tay, đầu gối) trong ước lượng tư thế con người hoặc các landmark khuôn mặt (mắt, mũi, miệng).
Những điểm này được sử dụng để hiểu tư thế, hướng chuyển động hoặc cấu trúc của đối tượng. Keypoint detection được ứng dụng rộng rãi trong nhận diện hành động, theo dõi luyện tập thể dục, nhận diện khuôn mặt, điều khiển bằng cử chỉ và hoạt hình.
Trong ví dụ này, hãy tạo một Workflow và thêm Keypoint Detection Block, cấu hình với mô hình YOLOv8 Nano Pose từ danh sách các mô hình công khai. Sau đó, thêm Keypoint Visualization Block và đặt thuộc tính Annotator Type thành “vertex_label”.
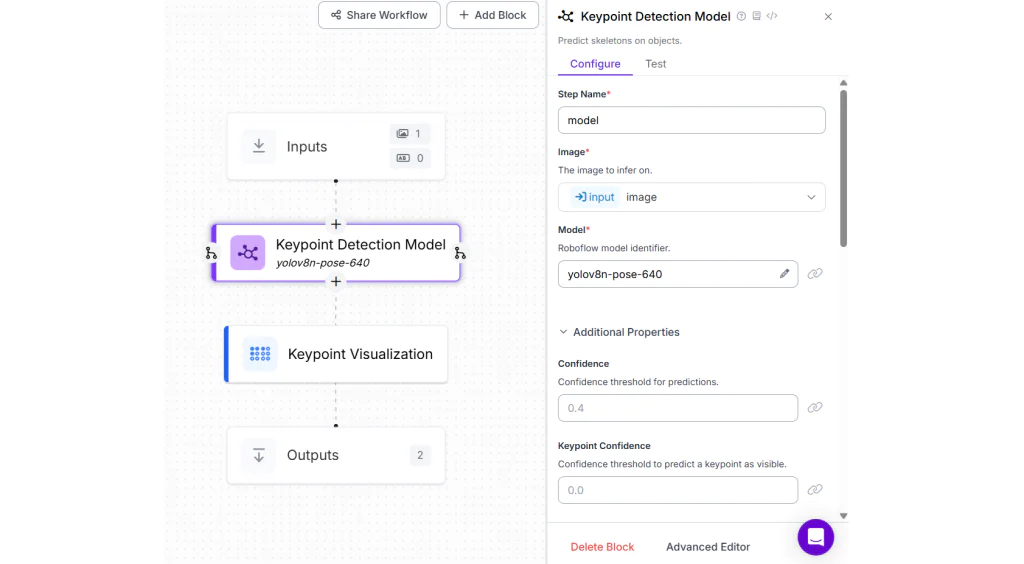
Khi chạy Workflow, bạn sẽ thấy kết quả đầu ra như sau.

Phân đoạn đối tượng trong hình ảnh
Phân đoạn hình ảnhlà quá trình chia hình ảnh thành các vùng riêng biệt bằng cách gán nhãn cho từng pixel dựa trên đối tượng mà nó thuộc về. Có hai loại phân đoạn chính:
- Semantic segmentation (phân đoạn ngữ nghĩa): Gán nhãn mỗi pixel theo lớp đối tượng (ví dụ: “car”, “tree”).
- Instance segmentation (phân đoạn theo thực thể): Phân biệt các thực thể khác nhau của cùng một lớp đối tượng (ví dụ: hai người khác nhau đều thuộc lớp “person”).
Segmentation cung cấp mức độ hiểu chi tiết hơn nhiều so với bounding box và đóng vai trò quan trọng trong các lĩnh vực như chẩn đoán hình ảnh y tế, xe tự hành, nông nghiệp thông minh và robot học.
Trong ví dụ này, hãy tạo một Roboflow Workflow bằng cách thêm Instance Segmentation Block và chọn mô hình YOLOv8 Nano Segmentation từ các mô hình công khai có sẵn. Đặt thuộc tính Class filter của block này thành “sports ball”, vì chúng ta sẽ phân đoạn quả bóng thể thao được phát hiện trong hình ảnh.
Để trực quan hóa mặt nạ phân đoạn, hãy thêm Mask Visualization Block.
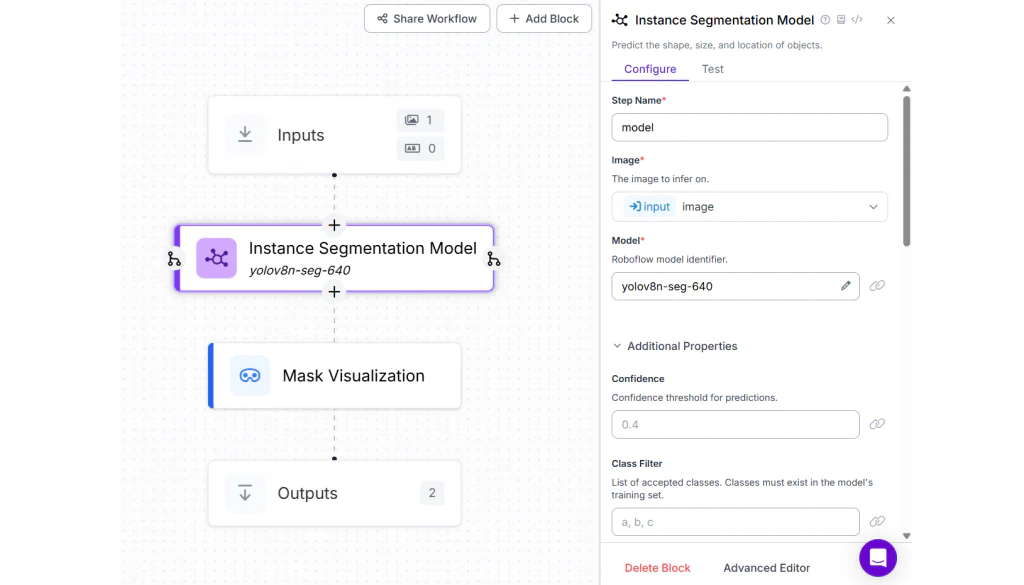
Khi bạn chạy Workflow này, bạn sẽ thấy kết quả đầu ra tương tự như hình ảnh bên dưới, hiển thị đối tượng đã được phân đoạn.

AI xử lý tài liệu
AI xử lý tài liệu là lĩnh vực phân tích thông minh các tài liệu có cấu trúc và phi cấu trúc nhằm trích xuất thông tin quan trọng. Công nghệ này kết hợp OCR, phân tích bố cục và xử lý ngôn ngữ tự nhiên để hiểu các biểu mẫu, bảng biểu, hóa đơn và báo cáo.
Hệ thống có thể nhận diện các thành phần như tiêu đề, cặp khóa–giá trị, bảng và ghi chú viết tay. Document AI được sử dụng rộng rãi để tự động hóa các quy trình như xử lý hóa đơn, phân tích hợp đồng và xác minh danh tính.
Trong ví dụ này, hãy tạo một Roboflow Workflow và thêm Object Detection Model block. Sau đó, cấu hình block này với mô hình Table and Figure Identification được công khai trên Roboflow Universe. Tiếp theo, thêm Dynamic Crop block để phát hiện và cắt bảng và/hoặc hình minh họa được dự đoán.
Cuối cùng, thêm OpenAI block và chọn model type là “gpt-4o”. OpenAI block này sẽ nhận hình ảnh đã được cắt từ Dynamic Crop block và mô tả nội dung bảng hoặc hình ảnh trong tài liệu.
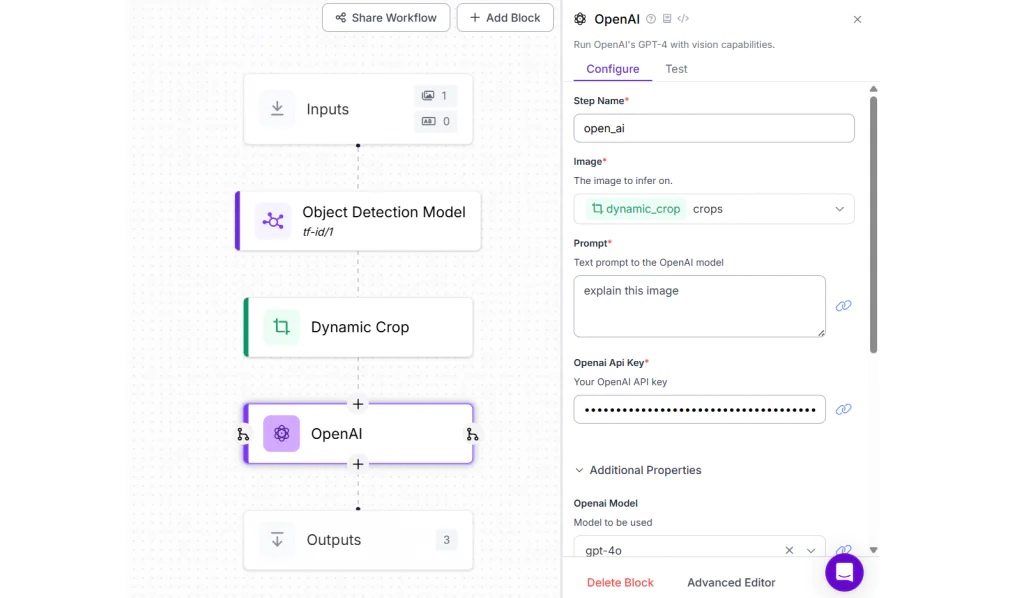
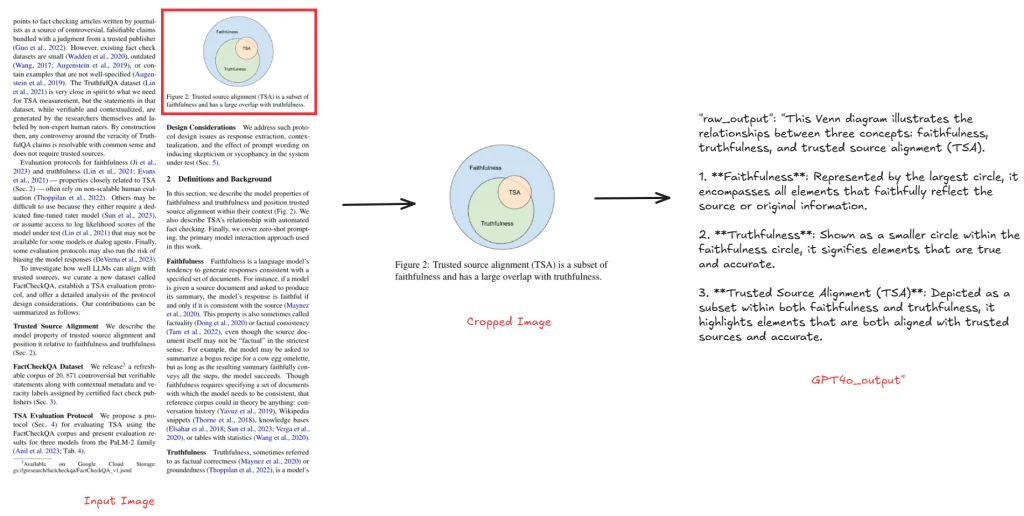
Như minh họa trong hình bên dưới, khi bạn chạy workflow với ảnh đầu vào là một trang tài liệu có chứa bảng hoặc hình, phần bảng/hình được phát hiện sẽ được cắt ra và giải thích bởi “gpt-4o”.
Tạo mô tả hình ảnh
Tạo mô tả hình ảnh là nhiệm vụ phân tích hình ảnh và tạo ra một đoạn mô tả bằng văn bản thể hiện các yếu tố chính và ngữ cảnh của hình ảnh. Nhiệm vụ này đòi hỏi mô hình phải hiểu các đối tượng, hành động và mối quan hệ trong hình, sau đó chuyển chúng thành một câu hoàn chỉnh, mạch lạc bằng ngôn ngữ tự nhiên. Mục tiêu là tạo ra một câu mô tả toàn bộ hình ảnh một cách tự nhiên và chính xác.
Trong ví dụ này, hãy tạo một Roboflow Workflow bằng cách thêm OpenAI block và chọn Model Version là “gpt-4o”.
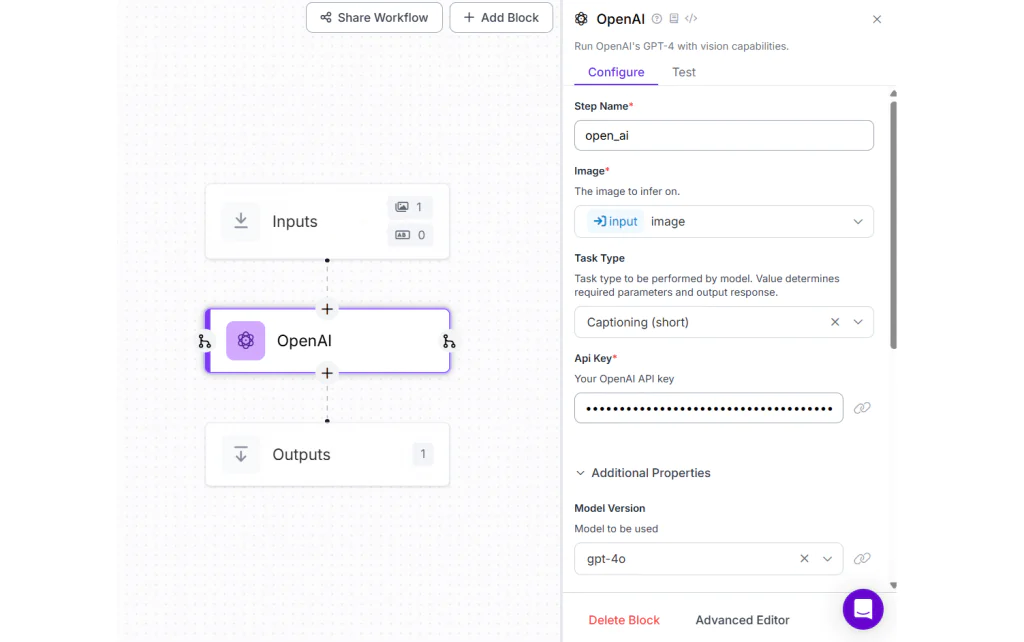
Chạy workflow với hình ảnh đầu vào như sau.

Bạn sẽ thấy kết quả phản hồi như sau.

Hỏi – đáp dựa trên hình ảnh
VQA là nhiệm vụ kết hợp việc hiểu nội dung hình ảnh và nội dung câu hỏi bằng văn bản, sau đó tạo ra câu trả lời chính xác dựa trên các manh mối trực quan trong hình. Mục tiêu là trả lời một câu hỏi cụ thể về hình ảnh thông qua lập luận thị giác (visual reasoning).
Trong ví dụ này, hãy tạo một Roboflow Workflow với input block chấp nhận hình ảnh và một câu hỏi văn bản. Sau đó, thêm Google Gemini Block, chọn Task Type là “Visual Question Answering”, và liên kết thuộc tính Prompt với biến prompt đã được khai báo trong input block.
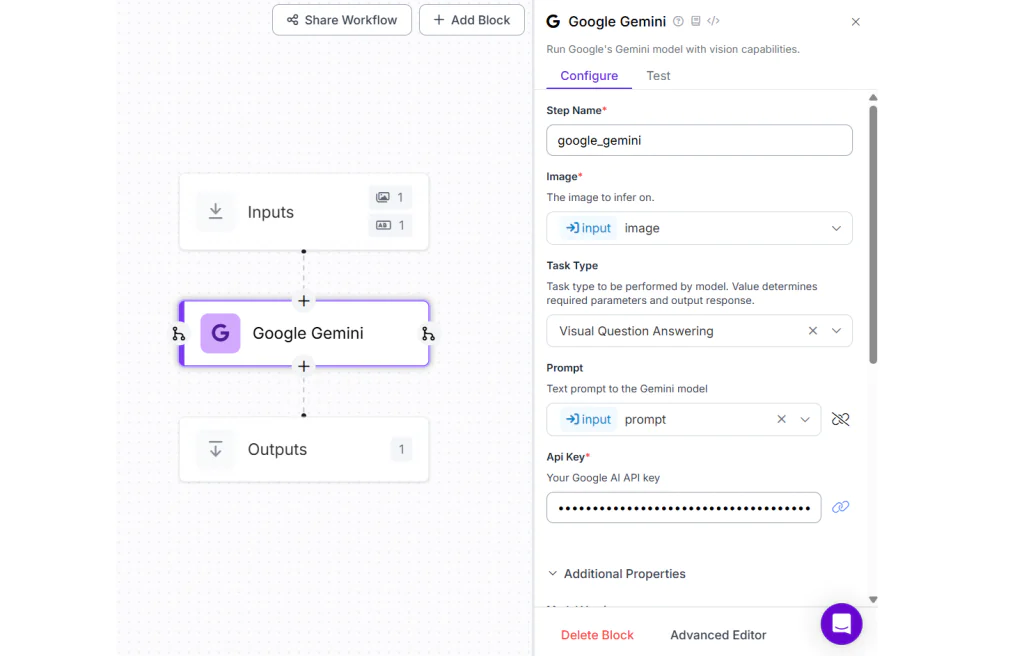
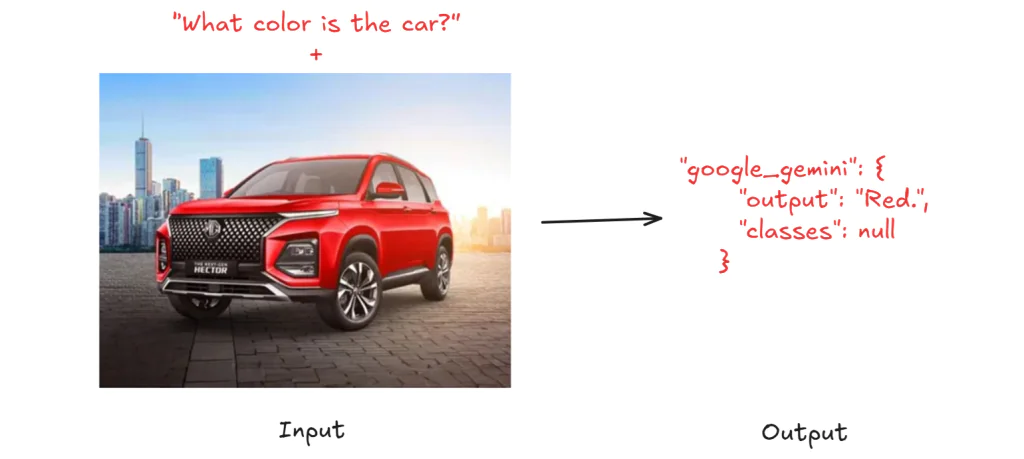
Như minh họa trong hình bên dưới, khi bạn chạy workflow với hình ảnh một chiếc xe màu đỏ và câu hỏi “What color is the car?”, bạn sẽ nhận được kết quả đầu ra là “car”.
Lập luận thị giác / Sinh biểu thức tham chiếu
Nhiệm vụ này liên quan đến việc xác định và mô tả các đối tượng hoặc vùng cụ thể trong hình ảnh dựa trên ngữ cảnh hoặc câu hỏi. Nó đòi hỏi mô hình phải hiểu các mối quan hệ và thuộc tính của đối tượng trong hình. Mục tiêu là mô tả hoặc chỉ ra chính xác một đối tượng hay khu vực cụ thể trong hình ảnh dựa trên ngữ cảnh hoặc câu lệnh đầu vào.
Trong ví dụ này, hãy tạo một Roboflow Workflow với input block chấp nhận hình ảnh và một câu lệnh văn bản. Sau đó, thêm Google Gemini Block, chọn Task Type là “Open Prompt”, và liên kết thuộc tính Prompt với biến prompt đã khai báo.
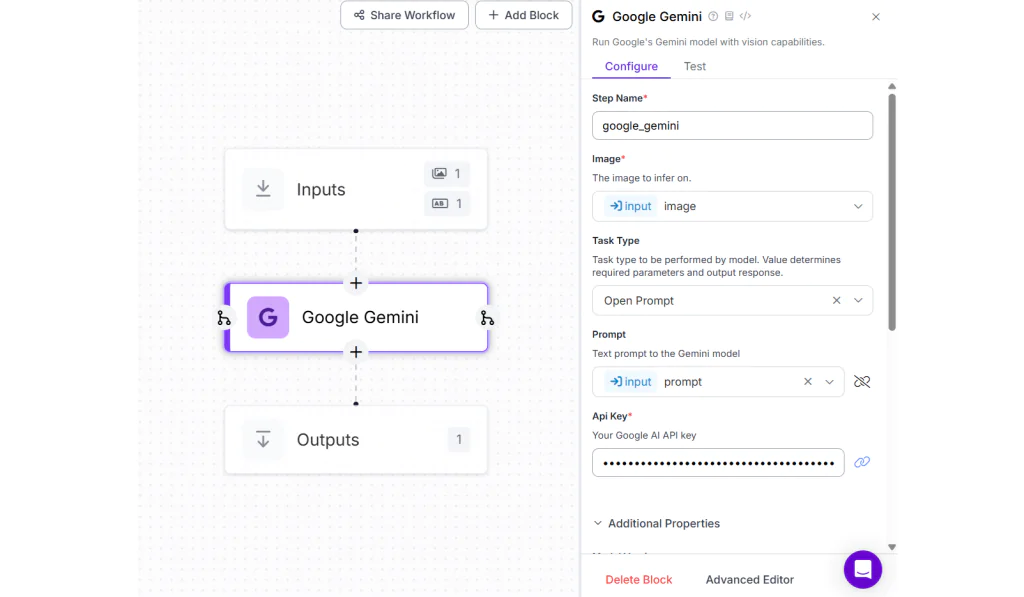
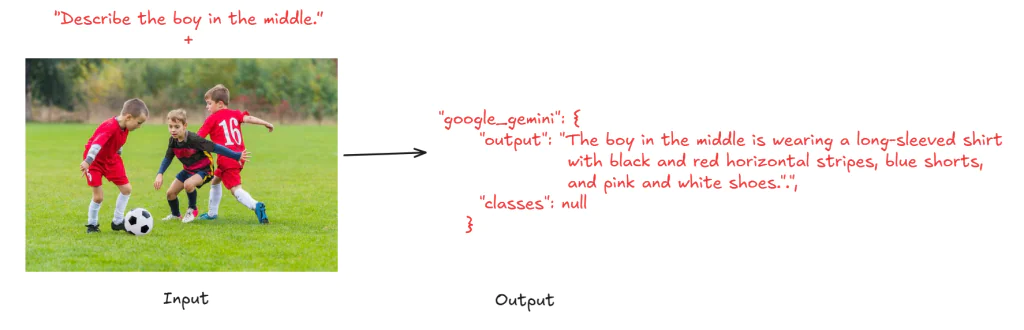
Khi bạn chạy workflow với hình ảnh đầu vào và câu lệnh “Describe the boy in the middle.” (bên trái), bạn sẽ nhận được kết quả đầu ra là: “The boy in the middle is wearing a long-sleeved shirt with black and red horizontal stripes, blue shorts, and pink and white shoes.” (bên phải).
Trong bài viết này, chúng ta đã khám phá Phân tích hình ảnh bằng AI, làm rõ cách trí tuệ nhân tạo cho phép máy móc diễn giải, hiểu và hành động dựa trên dữ liệu hình ảnh. Từ giám sát kệ hàng bán lẻ đến các mô hình lập luận đa phương thức phức tạp như PaliGemma, bài viết đã minh họa các ứng dụng thực tế cũng như các nhóm mô hình, từ computer vision cốt lõi đến vision-language AI nâng cao.
Những điểm chính về phân tích hình ảnh bằng AI
AI đang thay đổi cách chúng ta hiểu hình ảnh, từ việc nhận diện sản phẩm trên kệ hàng đến việc hiểu các cảnh trực quan phức tạp thông qua ngôn ngữ. Dưới đây là những điểm nổi bật thể hiện sức mạnh và chiều sâu của AI image analysis:
- Tự động hóa tác vụ thị giác bằng AI: AI có thể phát hiện sản phẩm bị thiếu, nhận diện đối tượng, đọc văn bản và giám sát hoạt động của con người thông qua camera thời gian thực, giúp nâng cao hiệu quả trong các lĩnh vực như bán lẻ, y tế, sản xuất và an ninh.
- Từ mô hình AI cơ bản đến nâng cao: Các mô hình phân tích hình ảnh trải dài từ CNNs và Vision Transformers (ViTs) cho các tác vụ phân loại và phát hiện, đến các Vision-Language Models tiên tiến (ví dụ: CLIP, PaliGemma) có khả năng phân tích hình ảnh, tạo mô tả, trả lời câu hỏi và thực hiện lập luận phức tạp.
- Trí tuệ đa phương thức là tương lai: AI đa phương thức như PaliGemma kết hợp dữ liệu hình ảnh với khả năng hiểu ngôn ngữ tự nhiên để tạo ra các câu trả lời theo ngữ cảnh, vượt xa các tác vụ phát hiện đơn thuần để tiến tới lập luận và đối thoại.
- Roboflow hỗ trợ xây dựng workflow AI thực tế: Với Roboflow Workflows, bạn có thể thực hiện OCR, phát hiện đối tượng, phân đoạn hình ảnh, ước lượng tư thế, phân tích tài liệu, tạo mô tả hình ảnh và nhiều tác vụ khác. Bạn có thể bắt đầu hoàn toàn miễn phí.
Phân tích hình ảnh bằng AI đang dần trở thành nền tảng cốt lõi cho nhiều ứng dụng thực tiễn, giúp doanh nghiệp không chỉ “nhìn thấy” mà còn hiểu và suy luận từ dữ liệu thị giác. Sự phát triển từ các mô hình thị giác truyền thống đến AI đa phương thức đã mở ra khả năng tự động hóa thông minh, ra quyết định chính xác hơn và mở rộng quy mô vận hành hiệu quả. Với những nền tảng như Roboflow, việc triển khai AI image analysis không còn là bài toán phức tạp, mà trở nên linh hoạt, dễ tiếp cận và sẵn sàng cho các kịch bản ứng dụng thực tế trong tương lai.
Nguồn tham khảo: AI Image Analysis
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Hoàng Diệu, Phường 12, Quận 4, Thành phố Hồ Chí Minh, Việt Nam







