
Hãy tưởng tượng bạn có thể điều khiển máy tính chỉ bằng một cái vẫy tay đơn giản – không cần chuột, không cần bàn phím, chỉ bằng những cử chỉ trực quan. Với khả năng thị giác máy tính và phát hiện đối tượng của Roboflow, việc xây dựng một công cụ cho phép bạn điều khiển hệ điều hành chỉ bằng đôi tay giờ đây đã trở nên dễ dàng hơn bao giờ hết.
Trong bài viết này, chúng ta sẽ khám phá từng bước cách tạo một dự án nhận dạng cử chỉ với Vision AI, đồng thời chia sẻ cách bạn có thể cải thiện hoặc mở rộng dự án để đáp ứng nhu cầu cá nhân và gây ấn tượng với bạn bè.
>>> Xem thêm các bài viết liên quan:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất 2025
- Vertex AI là gì? Nền tảng học máy của Google Cloud
Tạo mô hình nhận dạng cử chỉ
Trước tiên, hãy truy cập Roboflow và tạo tài khoản nếu bạn là người dùng mới, hoặc đăng nhập nếu bạn đã có tài khoản. Tiếp theo, chọn hoặc tạo một workspace cá nhân để lưu trữ mô hình của bạn và chọn gói dịch vụ phù hợp. Trong dự án này, chúng ta sẽ sử dụng gói public. Khi đã vào workspace, hãy điều hướng đến mục Projects ở thanh bên trái và tạo một dự án mới.
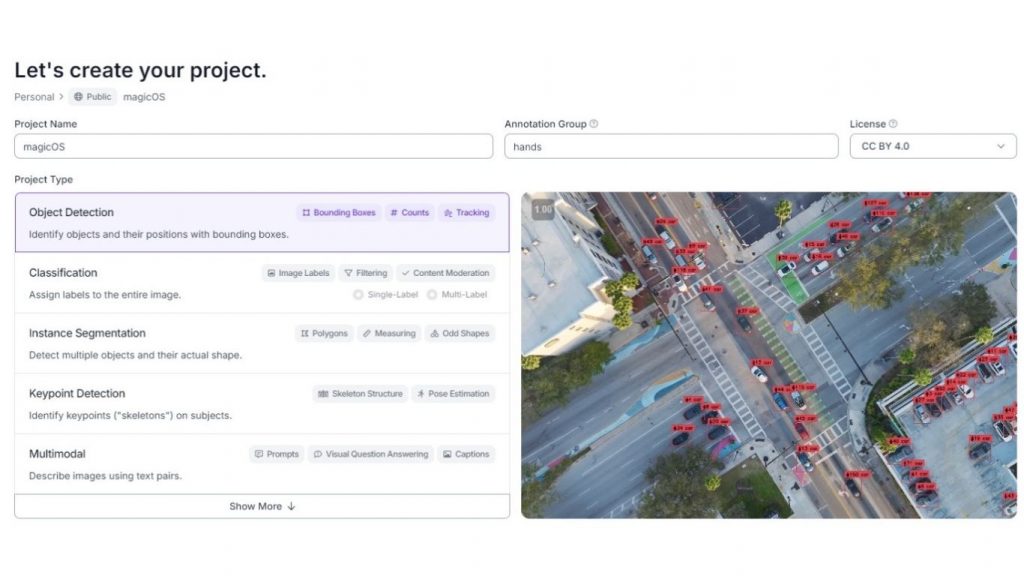
Bạn có thể đặt tên dự án tùy ý, nhưng hãy đảm bảo chọn loại dự án là Object Detection, vì đây chính là mục tiêu của mô hình nhận dạng cử chỉ. Ngoài ra, hãy đặt annotation group (nhóm dữ liệu cần gán nhãn) là “hands”, vì trong suốt quá trình, chúng ta sẽ gán nhãn cho các cử chỉ khác nhau của bàn tay.
Sau khi thiết lập xong dự án trên Roboflow, đã đến lúc cung cấp dữ liệu thực tế cho mô hình. Bạn có thể tìm nhiều dataset có sẵn trên Roboflow Universe, nhưng với dự án này, chúng ta có thể sử dụng video tự quay từ chính hệ thống của mình để đạt độ chính xác cao hơn và giảm lượng dữ liệu thô cần xử lý. Lý do là vì việc huấn luyện mô hình trên các frame có góc quay và hướng camera giống nhau sẽ giúp mô hình dự đoán tốt hơn các cử chỉ từ video live của đôi tay bạn – vốn cũng được ghi lại trong cùng điều kiện.
Lưu ý: Quay video ở chế độ grayscale (đen trắng) có thể giúp mô hình nhận dạng cử chỉ nhanh hơn và dễ mở rộng hơn, vì mô hình sẽ học hình dạng bàn tay thay vì màu sắc, điều không quan trọng trong bài toán nhận dạng cử chỉ với Vision AI.
Sau khi bạn đã ghi đủ dữ liệu (trong trường hợp này là video grayscale dài 15 giây, trích xuất ở 30 fps, chỉ thực hiện 2 cử chỉ: vuốt (swipe) và búng tay (snap)), hãy vào tab Upload Data trong dự án Roboflow và tải video lên. Nên chọn tốc độ khung hình từ 30–60 fps để đảm bảo ghi lại đầy đủ mọi frame của mỗi cử chỉ. Bạn hoàn toàn có thể tải thêm dữ liệu sau này nếu cần huấn luyện mô hình tốt hơn.
>>> Xem thêm:
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
- Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow
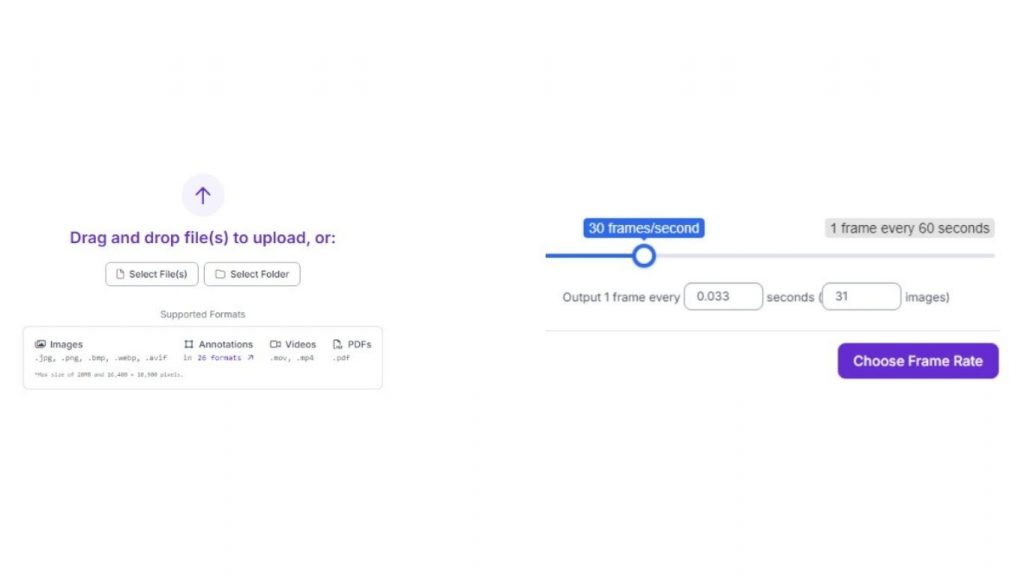
Sau khi ảnh được tải lên, hãy truy cập tab Classes and Tags của dự án. Tại đây, chúng ta sẽ tạo các class để gán nhãn cho từng frame, giúp mô hình học được những gì cần tìm khi nhận diện cử chỉ.
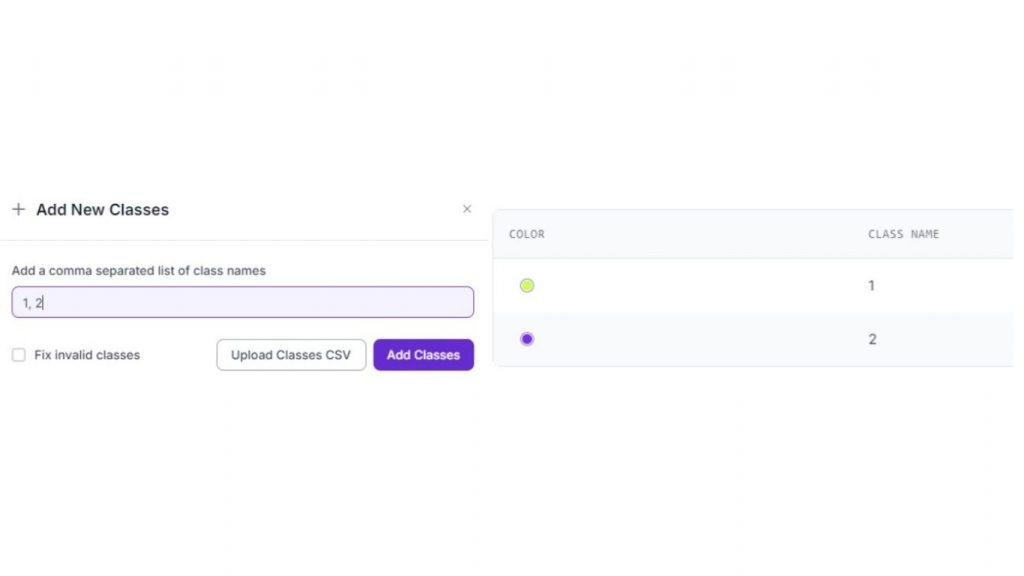
Nhấn Add, sau đó tạo một danh sách đánh số tương ứng với số lượng cử chỉ bạn muốn mô hình nhận dạng. Chọn cách này để gán nhãn nhanh hơn, nhưng về bản chất, mỗi mục trong danh sách chính là một đối tượng/cử chỉ mà bạn muốn mô hình nhận diện.
Ví dụ trong trường hợp này:
- “1” đại diện cho cử chỉ vuốt (swipe)
- “2” đại diện cho cử chỉ búng tay (snap)
>>> Xem thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Các mô hình phát hiện đối tượng tốt nhất năm 2025
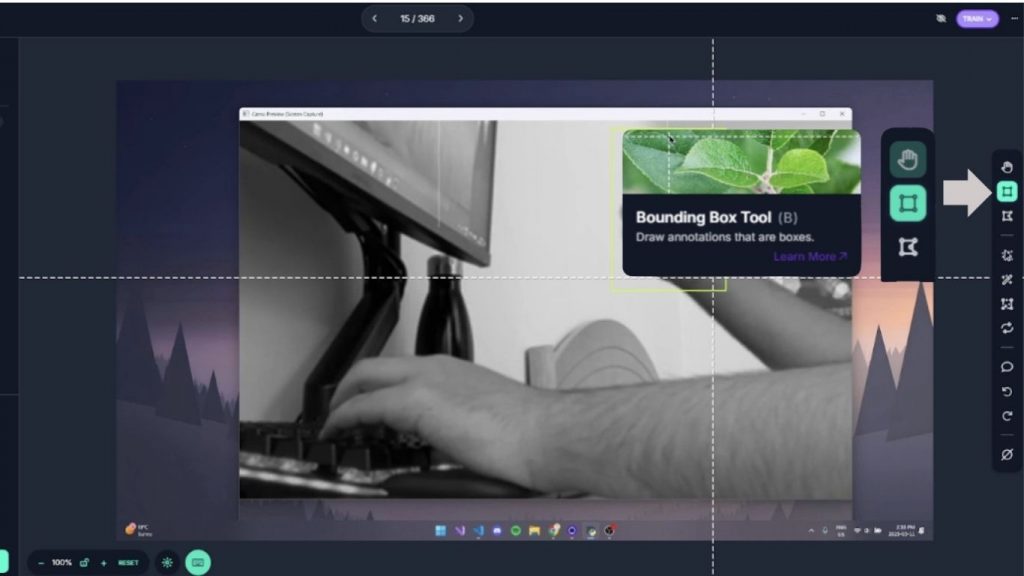
Tiếp theo, hãy chuyển sang tab Annotation của dự án và nhấn “Start Annotating” trên dữ liệu bạn đã tải lên. Quá trình gán nhãn sẽ bao gồm:
- Khoanh vùng bàn tay đang thực hiện cử chỉ
- Gán class tương ứng cho vùng đó
Khi vào trình chỉnh sửa annotation, hãy đảm bảo bạn đã chọn công cụ Bounding Box. Sau đó, vẽ một bounding box bao quanh bàn tay đang thực hiện cử chỉ. Nếu trong frame không có cử chỉ nào, bạn không cần gán nhãn. Trong ví dụ minh họa, một frame đang thực hiện cử chỉ vuốt, vì vậy chúng ta vẽ một bounding box vừa khít quanh bàn tay.
>>> Xem thêm:
- Các Mô Hình Ngôn Ngữ Thị Giác Chạy Cục Bộ Tốt Nhất
- Phát hiện đối tượng trong video với RF-DETR
Cuối cùng, hãy gán nhãn cho bounding box bằng số đại diện cho cử chỉ. Trước đó, đã quy ước: Class “1” = vuốt (swipe) Vì vậy, trong annotation editor, sẽ chọn 1. Điều này có thể thay đổi tùy theo loại cử chỉ mà bạn muốn mô hình nhận diện.
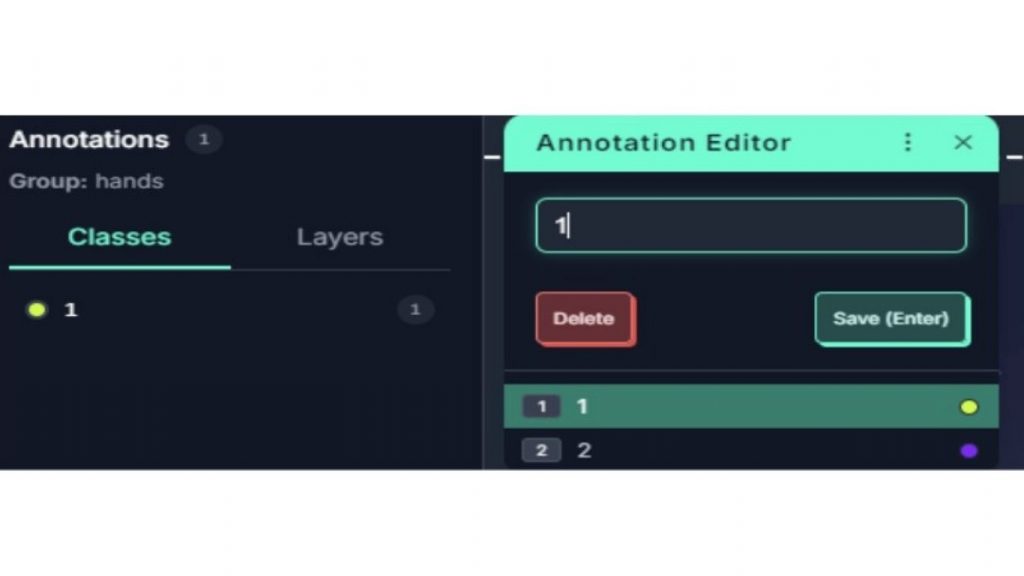
Sau khi bạn đã gán nhãn đủ số lượng ảnh cần thiết (trong trường hợp này là khoảng 500 ảnh để có mô hình chính xác với chỉ 2 cử chỉ), hãy thoát trình annotation và thêm các ảnh đã gán nhãn vào dataset.
Huấn luyện mô hình
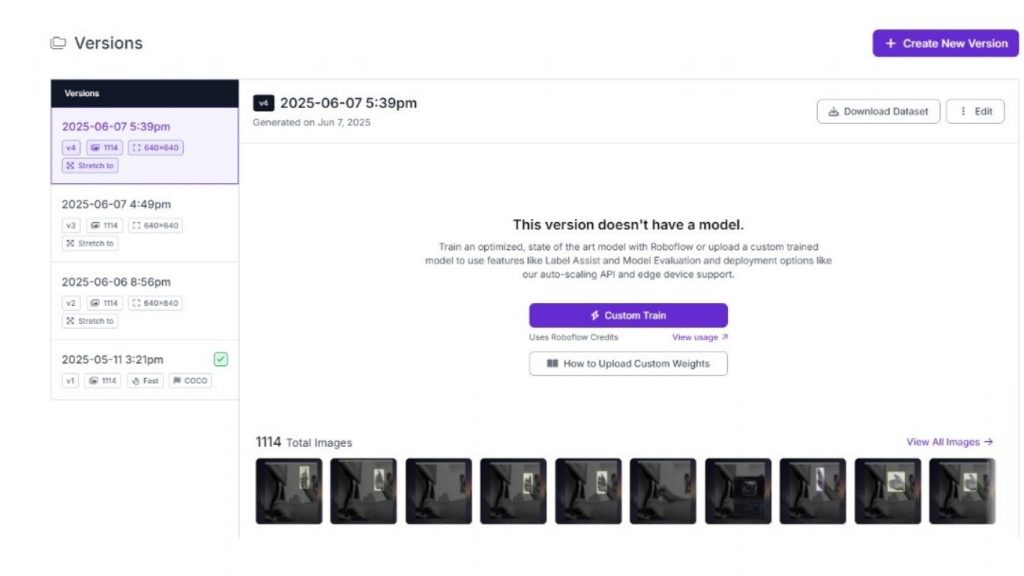
Truy cập vào tab Versions của dự án và tiếp tục sử dụng các thiết lập mặc định cho các bước preprocessing và augmentation. Nhấn “Create” để tạo một phiên bản mới của dự án.
>>> Xem thêm:
- Hệ thống kiểm tra thị giác (VIS) là gì?
- Suy Luận Trong Thị Giác Máy Tính: Cách Thực Hiện & Triển Khai Mô Hình AI
Trong version vừa tạo, nhấn vào “Custom Train” và chọn Roboflow 3.0 (YOLOv8) làm kiến trúc mô hình.
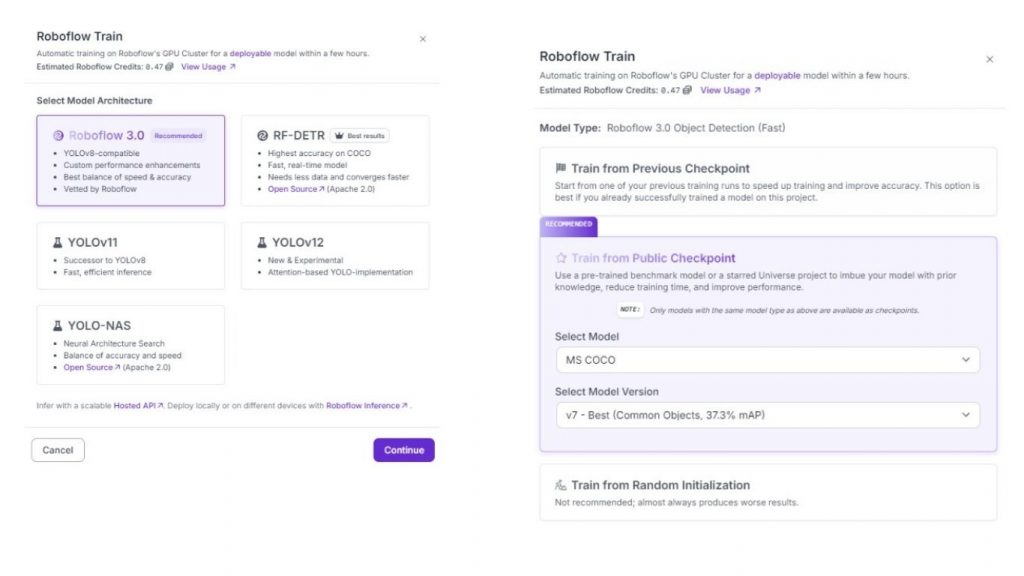
Ngoài ra, hãy đảm bảo bạn train từ một public checkpoint, vì điều này sẽ giúp quá trình huấn luyện nhanh hơn và cải thiện hiệu suất mô hình.
Hãy để mô hình hoàn tất quá trình huấn luyện. Trong lúc chờ đợi, chúng ta có thể bắt đầu với phần lập trình ứng dụng.
Thu thập hình ảnh trực tiếp của bàn tay
Tạo một thư mục/workspace mới cho dự án trên máy tính của bạn. Bên trong thư mục đó, tạo một file có tên main.py và mở nó bằng trình soạn thảo code mà bạn chọn.
>>> Xem thêm:
- Các Nhiệm Vụ Của Thị Giác Máy Tính và cách thực hiện chúng nhanh chóng
- Học Máy Là Gì Và Tại Sao Học Máy Lại Quan Trọng?
Lưu ý rằng bạn cần cài đặt Python cho dự án này. Nếu bạn chưa cài hoặc chưa thiết lập Python, hãy làm theo hướng dẫn sau trước: Microsoft Python Guide. File main.py sẽ là trung tâm của chương trình – chịu trách nhiệm thu thập video, gọi mô hình dự đoán và kích hoạt các hành động mà chúng ta muốn thực thi.
Có nhiều cách để lấy video trực tiếp bằng Python. Tuy nhiên, vì tôi sử dụng điện thoại làm camera, nên tôi chọn Camo Studio (Camo Studio Downloads) kết hợp với ứng dụng trên điện thoại để lấy hình ảnh.
Mở terminal và chạy các lệnh sau:
pip install numpy pygetwindow mss opencv-python roboflowSau đó, trong file main.py, thêm đoạn code sau:
import cv2
# Get the Camo Studio Window
window = gw.getWindowsWithTitle("Camo Studio")[0]
window.moveTo(-2780, -248)
window.resizeTo(500, 600)Khi Camo Studio đang mở và video trực tiếp đang được ghi, đoạn code này sẽ di chuyển và thay đổi kích thước cửa sổ đến một vị trí cố định. Điều này giúp việc lấy đúng vùng hình ảnh trở nên nhất quán trong những lần chạy chương trình sau.
Tiếp theo, để lấy các frame hình ảnh, hãy cập nhật main.py như sau:
import pygetwindow as gw
import cv2
import mss
# Get the Camo Studio Window
window = gw.getWindowsWithTitle("Camo Studio")[0]
window.moveTo(-2780, -248)
window.resizeTo(500, 600)
with mss.mss() as sct:
monitor = sct.monitors[0]
# Section being recorded
region = {
"top": monitor["top"] + 300,
"left": monitor["left"] + 200,
"width": 1500,
"height": 800
}
while True:
# Get the current frame
screenshot = sct.grab(region)
frame = np.array(screenshot)
frame = cv2.cvtColor(frame, cv2.COLOR_BGRA2RGB)Thư viện mss được sử dụng để chụp ảnh màn hình của cửa sổ Camo Studio mà chúng ta đã di chuyển và thay đổi kích thước ở bước trước. Vùng region có thể thay đổi tùy theo kích thước màn hình và vị trí cửa sổ của bạn, vì nó xác định tọa độ góc trên bên trái, chiều rộng và chiều cao của vùng được ghi lại.
Trong vòng lặp:
- mss chụp ảnh màn hình
- NumPy chuyển ảnh thành mảng dữ liệu
- OpenCV chuyển đổi ảnh sang hệ màu RGB – định dạng phù hợp hơn cho Roboflow xử lý
Khi đã có frame hình ảnh, chúng ta có thể bắt đầu dự đoán cử chỉ bàn tay.
Dự đoán cử chỉ tay
Trong cùng thư mục với file main.py, hãy tạo thêm một file mới tên là predict.py. File này sẽ chứa hàm dự đoán, và frame hình ảnh sẽ được truyền vào hàm này mỗi lần vòng lặp trong main.py chạy.
>>> Xem thêm:
- Khả năng thị giác của Chat GPT-5 và Cách Prompt hiệu quả
- LLMs.txt là gì? Có nên sử dụng không?
Quay lại dự án Roboflow của bạn và kiểm tra xem model đã huấn luyện xong chưa. Nếu đã xong, bạn có thể thêm đoạn code sau vào file predict.py:
from roboflow import Roboflow
import os
from dotenv import load_dotenv
load_dotenv()
# Roboflow model
rf = Roboflow(api_key=os.getenv("API_KEY"))
project = rf.workspace("personal-nh81v").project("magicos")
model = project.version(1).modelChúng ta đã sử dụng các thư viện dotenv và os để ẩn Roboflow API key. Để làm tương tự, bạn có thể tham khảo hướng dẫn: Environment Variables in Python.
Nếu bạn không có ý định công khai code hoặc không chia sẻ cho người khác, bạn có thể xóa các dòng import os, import dotenv và hàm load_dotenv(), sau đó thay thế tham số của hàm Roboflow bằng API key thật của bạn. API key có thể tìm thấy trong Workspace Settings của project.
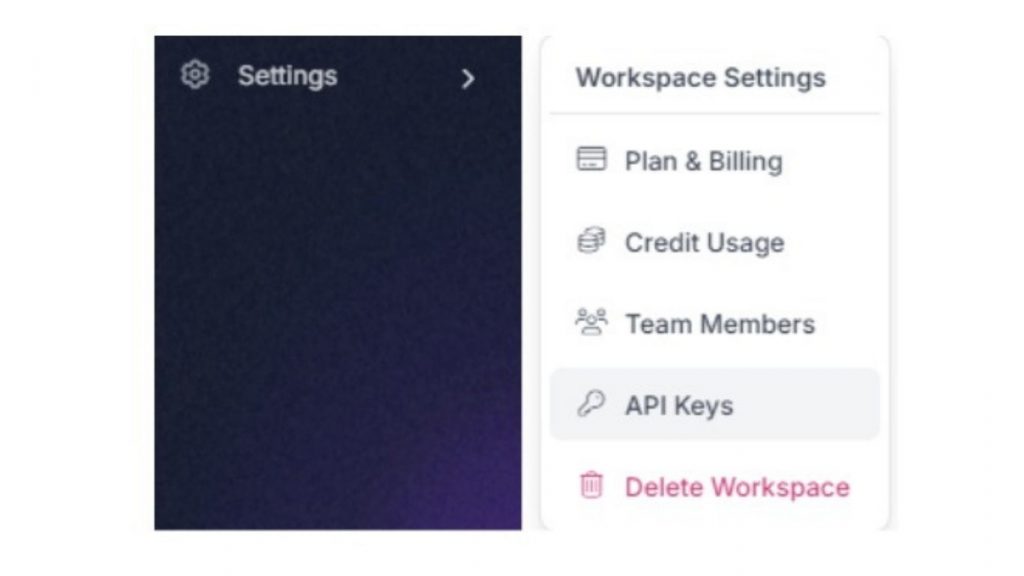
Ngoài ra, hãy thay thế tên workspace và project ID trong lệnh rf.workspace() bằng workspace name và project ID của bạn. Bạn có thể tìm các thông tin này trong URL và phần project highlight của project.
>>> Xem thêm:
- OP 30 công cụ AI miễn phí, phổ biến, hỗ trợ học tập và làm việc hiệu quả
- TOP 20 công cụ Chat AI tiếng Việt miễn phí thông minh phổ biến 2025
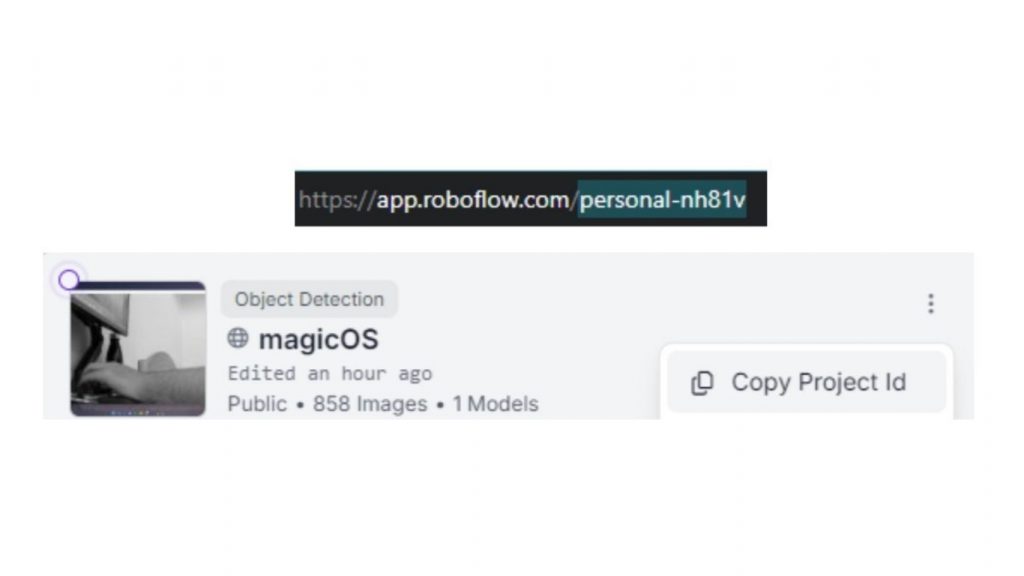
Nếu đây không phải phiên bản đầu tiên của model bạn huấn luyện, hãy đổi số trong project.version() cho khớp với version bạn đang sử dụng.
Sau khi load model xong, hãy định nghĩa một hàm dự đoán nhận đầu vào là một frame hình ảnh (frame này sẽ được truyền từ main.py ở bước sau).
from roboflow import Roboflow
import os
from dotenv import load_dotenv
load_dotenv()
# Roboflow model
rf = Roboflow(api_key=os.getenv("API_KEY"))
project = rf.workspace("personal-nh81v").project("magicos")
model = project.version(1).model
def predict(frame):
# Make prediction of the frame
predictions = model.predict(frame, confidence=40, overlap=30).json()
# Process predictions through rf model
for prediction in predictions['predictions']:
gesture = prediction['class']
confidence = prediction['confidence']
# Depending on what the model predicts
if gesture == "1" and confidence >= 0.8:
return "swipe"
elif gesture == "2" and confidence >= 0.8:
return "snap"
return "neutral"Hàm này sẽ trả về loại cử chỉ bạn đang thực hiện dựa trên từng frame hình ảnh. Lưu ý rằng có ngưỡng độ tin cậy, vì vậy hàm chỉ trả về kết quả dự đoán khi model thực sự tin rằng một cử chỉ đã được thực hiện. Ngưỡng này có thể được điều chỉnh, cũng như số lượng cử chỉ mà bạn muốn model trả về.
Trước đó, chúng ta chỉ huấn luyện model với hai cử chỉ là snap (búng tay) và swipe (quẹt tay), và gán chúng lần lượt với các dự đoán “1” và “2”. Bạn hãy thay đổi các điều kiện này cho phù hợp với các cử chỉ riêng của mình khi triển khai nhận dạng cử chỉ với Vision AI.
Tiếp theo, chúng ta sẽ lưu trữ hành động tương ứng với mỗi cử chỉ mà chúng ta gán.
Lưu dữ liệu cử chỉ trong file JSON
Trong thư mục gốc, hãy tạo một file có tên là gesture_mappings.json.
File này sẽ lưu trữ loại hành động mà chúng ta muốn thực hiện khi một cử chỉ được nhận dạng. Trong trường hợp trên, chúng ta thực hiện hai loại hành động khác nhau từ cử chỉ:
- Mở một ứng dụng
- Chạy một lệnh
Bên cạnh đó, chúng ta đã huấn luyện model chỉ để nhận dạng hai cử chỉ là snap (búng tay) và swipe (quẹt tay), vì vậy file gesture_mappings.json của chúng ta trông sẽ giống như sau:
{
"swipe": {
"type": "keybind",
"value": "alt+tab"
},
"snap": {
"type": "app",
"value": "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe"
}Ở đây, mỗi cử chỉ sẽ có:
- type: dùng để chỉ loại hành động mà bạn muốn thực hiện
- value: dùng để chỉ dữ liệu cần thiết cho hành động đó (ví dụ: đường dẫn ứng dụng, câu lệnh cần chạy, v.v.)
Tùy vào các cử chỉ khác nhau và những hành động bạn muốn thực hiện, bạn sẽ có mapping khác nhau. Tuy nhiên, việc sử dụng định dạng JSON giúp bạn quản lý toàn bộ cử chỉ và hành động rất dễ dàng. Bạn chỉ cần thay đổi thuộc tính type và value cho các cử chỉ mới được thêm vào là xong.
Một lưu ý nhỏ: ở các bước sau, chúng ta sẽ tạo một giao diện GUI bằng tkinter để gán lại cử chỉ ngay trong lúc chạy chương trình, giúp việc chỉnh sửa nhanh và tiện hơn rất nhiều so với việc phải sửa file JSON thủ công, đặc biệt hữu ích khi xây dựng hệ thống nhận dạng cử chỉ với Vision AI.
Thực hiện các thao tác thú vị với kết quả dự đoán
Quay lại file main.py và import hàm dự đoán mà chúng ta vừa tạo. Ngoài ra, giờ đây chúng ta có thể gọi hàm predict cho mỗi frame mà chương trình nhận được.
import pygetwindow as gw
import cv2
import mss
from predict import predict
# Get the Camo Studio Window
window = gw.getWindowsWithTitle("Camo Studio")[0]
window.moveTo(-2780, -248)
window.resizeTo(500, 600)
with mss.mss() as sct:
monitor = sct.monitors[0]
# Section being recorded
region = {
"top": monitor["top"] + 300,
"left": monitor["left"] + 200,
"width": 1500,
"height": 800
}
while True:
# Get the current frame
screenshot = sct.grab(region)
frame = np.array(screenshot)
frame = cv2.cvtColor(frame, cv2.COLOR_BGRA2RGB)
# Make a prediction with the predict function
gesture = predict(frame)Khi đã có kết quả dự đoán cử chỉ, chúng ta có thể đọc file JSON để xác định hành động nào sẽ được thực thi:
import pygetwindow as gw
import cv2
import mss
import json
from predict import predict
# Get the Camo Studio Window
window = gw.getWindowsWithTitle("Camo Studio")[0]
window.moveTo(-2780, -248)
window.resizeTo(500, 600)
with mss.mss() as sct:
monitor = sct.monitors[0]
# Section being recorded
region = {
"top": monitor["top"] + 300,
"left": monitor["left"] + 200,
"width": 1500,
"height": 800
}
while True:
# Get the current frame
screenshot = sct.grab(region)
frame = np.array(screenshot)
frame = cv2.cvtColor(frame, cv2.COLOR_BGRA2RGB)
# Make a prediction with the predict function
gesture = predict(frame)
# Read the JSON file to find the action
with open(MAPPINGS_FILE, "r") as f:
mappings = json.load(f)
action = mappings.get(gesture)Hãy đảm bảo rằng bạn đã import thư viện json.
Có thể bạn sẽ thắc mắc vì sao chúng ta đọc lại file JSON mỗi lần vòng lặp chạy. Lý do là vì file JSON có thể được thay đổi trong lúc chương trình đang chạy, nên việc đọc lại liên tục giúp chương trình không cần khởi động lại mà vẫn cập nhật được mapping cử chỉ mới.
Trong thư mục gốc, hãy tạo thêm một file có tên là execute.py. File này sẽ chứa hàm thực thi, nơi các hành động thực sự được thực hiện trên hệ điều hành (OS).
Hai hành động lựa chọn là:
- Mở một ứng dụng
- Chạy một lệnh (command)
Những hành động này yêu cầu sử dụng:
- Thư viện subprocess
- Thư viện keyboard
Thư viện subprocess đã có sẵn trong Python, vì vậy bạn chỉ cần cài đặt thư viện keyboard bằng cách chạy lệnh sau trong terminal:
pip install keyboardSau đó, thêm đoạn mã sau vào tệp execute.py:
import subprocess
import keyboard
def execute(action):
if action["type"] == "keybind":
keys = action.get("value", "")
if keys:
keyboard.send(keys)
elif action["type"] == "app":
app_path = action.get("value", "")
if app_path:
try:
subprocess.Popen(app_path)
except Exception as e:
print(f"Failed to launch application: {e}")Đoạn code này sẽ nhận hành động đã được xác định trong main.py và sử dụng các thư viện tương ứng để thực thi hành động đó trên hệ điều hành. Đối tượng action là một dictionary, vì vậy trong hàm chúng ta có thể truy cập cả type và value của hành động.
Toàn bộ quy trình làm việc với JSON và hàm execute giúp việc thay đổi, chỉnh sửa hoặc thêm mới cử chỉ trở nên cực kỳ dễ dàng, cho phép bạn mở rộng hệ thống nhận dạng cử chỉ với Vision AI mạnh mẽ hơn trong tương lai. Tuy nhiên, cần lưu ý rằng cách thực hiện hành động cụ thể có thể khác nhau, tùy thuộc vào loại hành động mà bạn muốn thực thi.
Khi các tính năng chính đã hoạt động, chúng ta cần thêm thời gian chờ giữa các cử chỉ để tránh việc các hành động bị kích hoạt chồng chéo lên nhau. Để làm điều này, hãy cập nhật lại file main.py:
import numpy as np
import mss
import pygetwindow as gw
import cv2
import time
import json
from predict import predict
from execute import execute
MAPPINGS_FILE = "gesture_mappings.json"
# Get the Camo Studio Window
window = gw.getWindowsWithTitle("Camo Studio")[0]
window.moveTo(-2780, -248)
window.resizeTo(500, 600)
# Cooldown
COOLDOWN_PERIOD = 2.0
last_action_time = 0
cooldown_active = False
with mss.mss() as sct:
monitor = sct.monitors[0]
# Section being recorded
region = {
"top": monitor["top"] + 300,
"left": monitor["left"] + 200,
"width": 1500,
"height": 800
}
while True:
# Get the current frame
screenshot = sct.grab(region)
frame = np.array(screenshot)
frame = cv2.cvtColor(frame, cv2.COLOR_BGRA2RGB)
gesture = predict(frame)
# Time for cooldown
current_time = time.time()
# If a gesture is made outside of cooldown
if not cooldown_active and gesture != "neutral":
print(f"Gesture detected: {gesture}")
# Execute necessary action
with open(MAPPINGS_FILE, "r") as f:
mappings = json.load(f)
action = mappings.get(gesture)
execute(action)
# Reset cooldown
cooldown_active = True
last_action_time = current_time
elif cooldown_active:
if current_time - last_action_time >= COOLDOWN_PERIOD:
cooldown_active = FalseĐoạn code này sử dụng thư viện time và đảm bảo rằng thời gian chờ (cooldown) không còn hiệu lực trước khi cho phép nhận diện và thực hiện một cử chỉ mới.
Tạo giao diện GUI bằng tkinter để quản lý mapping cử chỉ
Đến đây, dự án đã hoạt động hoàn chỉnh. Tuy nhiên, mỗi khi người dùng muốn thay đổi hành động gán cho một cử chỉ cụ thể, họ buộc phải mở và chỉnh sửa trực tiếp file JSON, điều này không thân thiện với người dùng. Chúng ta có thể khắc phục vấn đề này bằng cách tạo một giao diện GUI bằng tkinter để quản lý và chỉnh sửa file JSON, đồng thời chạy song song với main.py. Sau đó, mở terminal và chạy lệnh sau:
pip install ttkbootstrap winappsCác thư viện này sẽ giúp tạo giao diện đẹp hơn và cải thiện cách chọn ứng dụng khi người dùng muốn gán hành động chạy app.
Trong file gui.py, hãy thêm đoạn code sau:
import tkinter as tk
from tkinter import ttk, messagebox
from ttkbootstrap import Style
import winapps
import json
import threading
import keyboard
import os
MAPPINGS_FILE = "gesture_mappings.json"
class magicOSApp:
def __init__(self, root):
self.root = root
self.root.title("magicOS")
self.style = Style("darkly")
self.selected_gesture = tk.StringVar()
self.action_type = tk.StringVar(value="keybind")
self.selected_app = tk.StringVar()
self.keybind = tk.StringVar()
self.app_list = self.get_installed_apps()
self.create_layout()
def create_layout(self):
sidebar = ttk.Frame(self.root, width=200)
sidebar.pack(side="left", fill="y", padx=10, pady=10)
main_panel = ttk.Frame(self.root)
main_panel.pack(side="right", fill="both", expand=True, padx=10, pady=10)
ttk.Label(sidebar, text="Gestures", font=("Segoe UI", 12, "bold")).pack(pady=5)
gestures = ["swipe", "snap"]
for g in gestures:
ttk.Radiobutton(
sidebar,
text=g.capitalize(),
variable=self.selected_gesture,
value=g,
command=self.on_gesture_select,
style="success"
).pack(fill="x", pady=5)
ttk.Label(main_panel, text="Choose Action Type:", font=("Segoe UI", 11, "bold")).pack(anchor="w", pady=5)
ttk.Radiobutton(main_panel, text="Record Keybind", variable=self.action_type, value="keybind",
command=self.update_action_panel).pack(anchor="w", pady=2)
ttk.Radiobutton(main_panel, text="Open Application", variable=self.action_type, value="app",
command=self.update_action_panel).pack(anchor="w", pady=2)
self.action_container = ttk.Frame(main_panel)
self.action_container.pack(fill="x", pady=10)
self.save_btn = ttk.Button(main_panel, text="Save Mapping", command=self.save_mapping)
self.save_btn.pack(pady=10)
self.update_action_panel()
def on_gesture_select(self):
print(f"Selected gesture: {self.selected_gesture.get()}")
def record_keybind(self):
self.keybind_display.config(text="Listening... Press your combo")
def listen():
combo = keyboard.read_hotkey(suppress=True)
self.keybind.set(combo)
self.keybind_display.config(text=combo)
threading.Thread(target=listen, daemon=True).start()
def update_action_panel(self):
for widget in self.action_container.winfo_children():
widget.destroy()
if self.action_type.get() == "keybind":
ttk.Label(self.action_container, text="Press a key combination below:").pack(anchor="w")
self.keybind_display = ttk.Label(self.action_container, text="Not recorded", font=("Segoe UI", 10, "italic"))
self.keybind_display.pack(pady=5)
ttk.Button(self.action_container, text="Start Recording", command=self.record_keybind).pack()
else:
ttk.Label(self.action_container, text="Select an App to Launch:").pack(anchor="w")
self.app_dropdown = ttk.Combobox(self.action_container, textvariable=self.selected_app)
self.app_dropdown['values'] = [name for name, _ in self.app_list]
self.app_dropdown.pack(fill="x", pady=5)
def save_mapping(self):
gesture = self.selected_gesture.get()
if not gesture:
messagebox.showwarning("No gesture", "Please select a gesture to map.")
return
if self.action_type.get() == "keybind":
value = self.keybind.get().strip()
if not value:
messagebox.showwarning("Empty Keybind", "Please enter a keybind.")
return
else:
app_name = self.selected_app.get()
if not app_name:
messagebox.showwarning("No App", "Please select an application.")
return
# Find the corresponding winapps object
app_obj = next((app for name, app in self.app_list if name == app_name), None)
if not app_obj:
messagebox.showerror("Error", f"Application '{app_name}' not found.")
return
value = self.resolve_app_path(app_obj)
if not value:
messagebox.showerror("Error", f"Could not find executable for '{app_name}'.")
return
# Load existing mappings
try:
with open(MAPPINGS_FILE, "r") as f:
mappings = json.load(f)
except FileNotFoundError:
mappings = {}
mappings[gesture] = {
"type": self.action_type.get(),
"value": value
}
with open(MAPPINGS_FILE, "w") as f:
json.dump(mappings, f, indent=4)
messagebox.showinfo("Success", f"Mapped '{gesture}' to {self.action_type.get()}:\n{value}")
def get_installed_apps(self):
apps = list(winapps.list_installed())
return sorted([(app.name, app) for app in apps], key=lambda x: x[0]) or [("No apps found", None)]
def resolve_app_path(self, app):
if app.install_location and os.path.isdir(app.install_location):
for file in os.listdir(app.install_location):
if file.lower().endswith(".exe"):
return os.path.join(app.install_location, file)
return None
root = tk.Tk()
root.geometry("400x250")
root.resizable(False, False)
app = magicOSApp(root)
root.mainloop()Đoạn code này sẽ tạo ra một giao diện người dùng thân thiện, cho phép bạn quản lý các cử chỉ và hành động tương ứng một cách trực quan, thay vì phải chỉnh sửa file JSON thủ công.
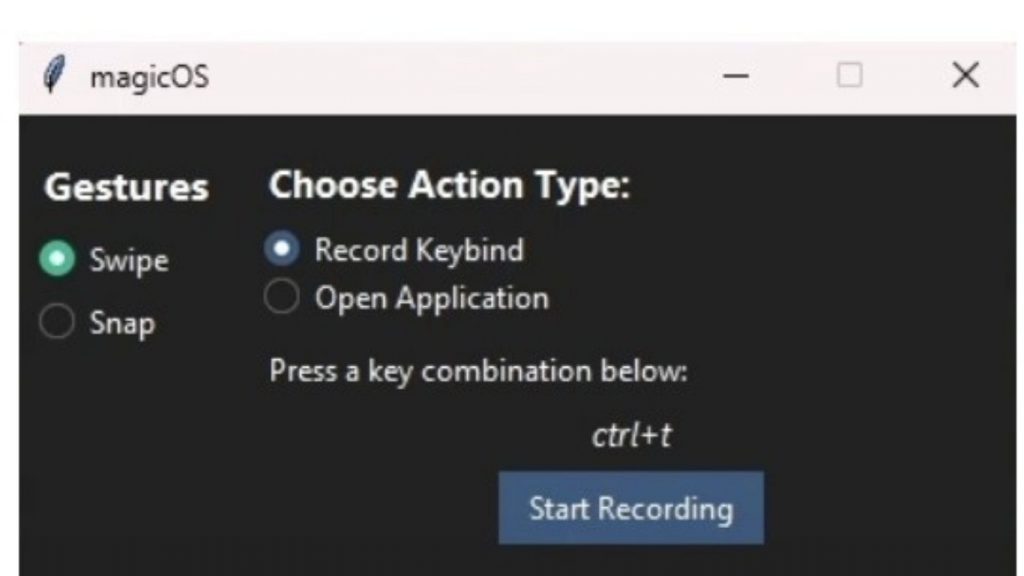
Vì trong hướng dẫn này chưa đi sâu vào cách sử dụng thư viện tkinter, nên nếu bạn có ý định thiết kế GUI bằng Python trong tương lai, bạn nên tham khảo thêm các tutorial chuyên sâu về tkinter để hiểu rõ hơn cách xây dựng giao diện và mở rộng ứng dụng.
Qua đó, dự án nhận dạng cử chỉ bằng Computer Vision của chúng ta đã hoàn thiện. Tuy nhiên, hệ thống này vẫn còn rất nhiều tiềm năng để mở rộng, đặc biệt khi bạn tiếp tục thu thập và huấn luyện với nhiều dữ liệu cử chỉ hơn, giúp mô hình ngày càng chính xác và linh hoạt. Dự án này cũng là nền tảng tốt để bạn phát triển thêm các tính năng nâng cao với Vision AI và Computer Vision. Chúc bạn thành công trên hành trình khám phá và ứng dụng AI vào các bài toán thực tế!
Nguồn tham khảo: Gesture Recognition Applications with Vision AI
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Hoàng Diệu, Phường Xóm Chiếu, Thành phố Hồ Chí Minh, Việt Nam







