Trong bối cảnh AI đa phương thức ngày càng phát triển, các hệ thống không chỉ xử lý văn bản mà còn cần hiểu hình ảnh một cách sâu sắc. Trong bài viết này, hãy cùng tìm hiểu mô hình ngôn ngữ thị giác là gì, các mô hình VLM phổ biến hiện nay và những ứng dụng tiêu biểu trong thực tế.
>> Tham khảo thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Các mô hình ngôn ngữ thị giác chạy cục bộ tốt nhất
- Cách so sánh các mô hình thị giác máy tính một cách trực quan
- Low Code là gì? Giải pháp phát triển phần mềm và xu hướng tương lai
Mô hình ngôn ngữ thị giác là gì?
Mô hình ngôn ngữ thị giác (Vision Language Model – VLM) là một hệ thống trí tuệ nhân tạo tiên tiến được thiết kế để xử lý và kết hợp dữ liệu thị giác (hình ảnh) và dữ liệu văn bản (ngôn ngữ). Các mô hình ngôn ngữ thị giác nằm ở giao điểm giữa Computer Vision (thị giác máy tính) và NLP (xử lý ngôn ngữ tự nhiên), cho phép máy móc hiểu, diễn giải và tạo ra nội dung liên quan đồng thời đến cả hình ảnh và văn bản.
Các mô hình ngôn ngữ (LMs) có thể được phân loại là Generative AI (AI tạo sinh) khi chúng được thiết kế để tạo ra đầu ra, chẳng hạn như mô tả văn bản, hình ảnh hoặc câu trả lời, dựa trên đầu vào là dữ liệu thị giác hoặc văn bản. Các mô hình ngôn ngữ thị giác là một tập con của các mô hình đa phương thức vì chúng xử lý và tích hợp nhiều loại dữ liệu khác nhau, cụ thể là dữ liệu thị giác (hình ảnh, video) và dữ liệu văn bản (ngôn ngữ).

Một số ví dụ định tính được tạo bởi Qwen-VL-Chat VLM (Nguồn: arXiv)
Các mô hình ngôn ngữ thị giác hoạt động như thế nào?
Các mô hình ngôn ngữ thị giác (VLMs) được thiết kế để xử lý và tích hợp thông tin thị giác và văn bản, cho phép chúng thực hiện các tác vụ đòi hỏi sự hiểu biết đồng thời về hình ảnh và văn bản. Kiến trúc của VLM bao gồm nhiều thành phần chính phối hợp với nhau để đạt được khả năng hiểu đa phương thức này. Kiến trúc tổng quát của VLM dựa trên Transformer được minh họa trong hình bên dưới.
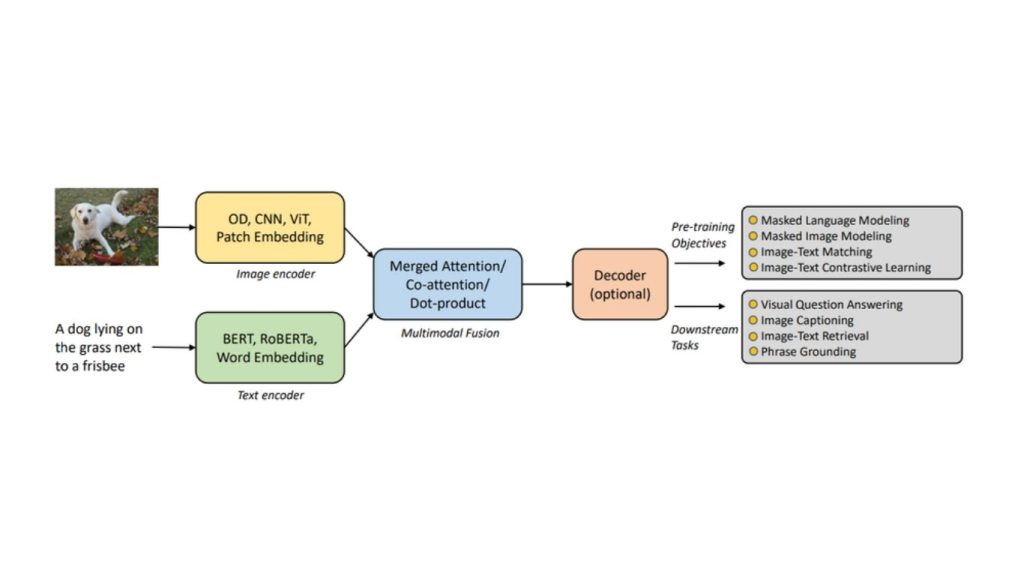
Kiến trúc tổng quát của VLM dựa trên Transformer (Nguồn: arXiv)
Các thành phần cốt lõi của kiến trúc VLM tổng quát bao gồm:
- Image Encoder (Mã hóa hình ảnh)
- Text Encoder (Mã hóa văn bản)
- Multimodal Fusion (Tích hợp đa phương thức)
- Decoder (Giải mã)
Mã hóa hình ảnh (mã hóa thị giác)
Mã hóa hình ảnh xử lý dữ liệu thị giác (ví dụ: hình ảnh) và chuyển đổi chúng thành các biểu diễn đặc trưng dạng số có thể được sử dụng cho học tập đa phương thức. Mã hóa thị giác được phân thành ba loại, gồm Object Detection (bộ phát hiện đối tượng), Convolutional Neural Network (mạng nơ-ron tích chập) và Vision Transformer (biến đổi thị giác).
Bộ phát hiện đối tượng (OD)
Bộ phát hiện đối tượng xác định và định vị các đối tượng trong hình ảnh bằng cách tạo ra các biểu diễn vùng. Nó mã hóa các đặc trưng thị giác và thông tin vị trí không gian, điều này rất quan trọng để hiểu mối quan hệ giữa các đối tượng trong các tác vụ ngôn ngữ thị giác.
>> Tìm hiểu thêm: Các mô hình phát hiện đối tượng tốt nhất
Mạng nơ-ron tích chập (CNN)
CNN trích xuất các đặc trưng thị giác theo dạng phân cấp từ hình ảnh, từ các mẫu đơn giản đến các cấu trúc phức tạp. CNN đóng vai trò là nền tảng cho các tác vụ yêu cầu biểu diễn hình ảnh giàu đặc trưng, giúp cải thiện hiệu suất cho các ứng dụng hạ lưu.
Biến đổi thị giác (ViT)
ViT xử lý hình ảnh dưới dạng các chuỗi các mảng, giúp nắm bắt bối cảnh toàn cục và các mối quan hệ giữa các thành phần. Nó cung cấp tính linh hoạt trong việc mô hình hóa các mối quan hệ thị giác phức tạp, khiến nó đặc biệt hiệu quả cho việc tiền huấn luyện giữa thị giác và ngôn ngữ.
>> Tìm hiểu thêm:
- Các nhiệm vụ của thị giác máy tính
- Phát hiện chuyển động bằng thị giác máy tính – Cách hoạt động và logic phát hiện
Mã hóa văn bản
Mã hóa văn bản xử lý đầu vào văn bản để tạo ra các biểu diễn giàu tính năng cho các tác vụ học tập đa phương thức. Nó chuyển đổi các câu đầu vào thành chuỗi các vectơ nắm bắt thông tin ngữ nghĩa và bối cảnh.
Hợp nhất đa phương thức
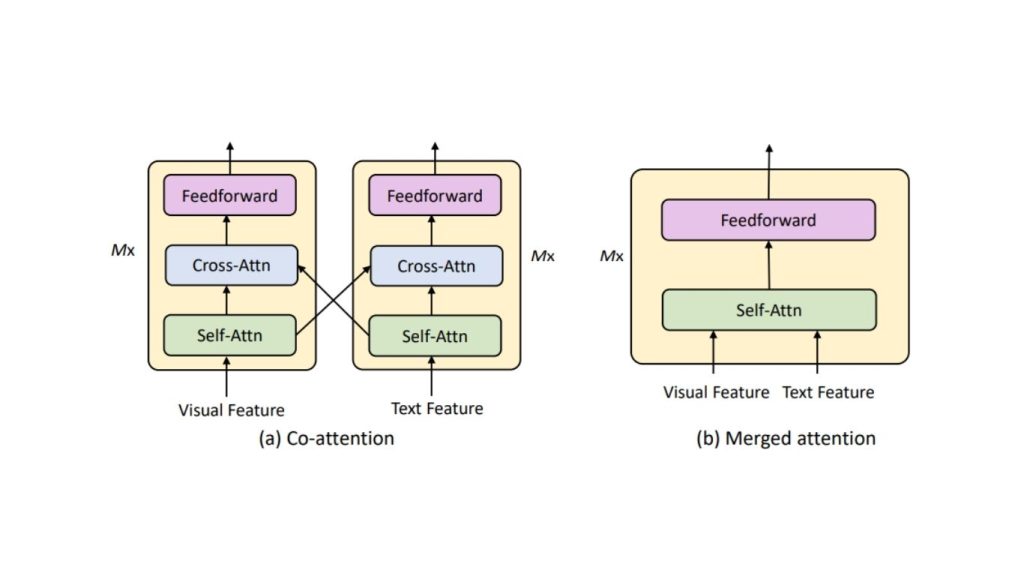
Hợp nhất đa phương thức (multimodal fusion) kết hợp các bộ mã hoá hình ảnh và bộ mã hoá văn bản để tạo ra các biểu diễn nhúng, từ đó hình thành một biểu diễn thống nhất tích hợp cả hai phương thức. Kết quả là một biểu diễn nhúng đa phương thức đã được hợp nhất, có khả năng nắm bắt mối quan hệ giữa các yếu tố thị giác và văn bản. Cơ chế này sử dụng các phương thức sau:
- Chú ý kết hợp (Merged Attention): Đồng bộ hóa các đặc trưng của hình ảnh và văn bản bằng cách tập trung vào các vùng liên quan của hình ảnh và từ trong văn bản cùng một lúc.
- Chú ý đồng thời (Co-Attention): Chú ý đồng thời là cơ chế cho phép tương tác đồng thời giữa các mô hình hình ảnh và văn bản, giúp mô hình tập trung vào các phần liên quan của cả hình ảnh và văn bản.
- Sản phẩm chấm (Dot-Product): Đo lường độ tương đồng giữa các biểu diễn hình ảnh và văn bản trong không gian biểu diễn chung, thường được sử dụng trong các tác vụ tìm kiếm.
Bộ giải mã
Bộ giải mã tạo ra đầu ra cuối cùng dựa trên biểu diễn đa phương thức đã được hợp nhất.
Các mô hình thị giác ngôn ngữ phổ biến
Trong phần này, chúng ta sẽ khám phá một số mô hình ngôn ngữ thị giác phổ biến cùng với các khả năng chính của chúng.
PaliGemma-2
PaliGemma 2 là một mô hình ngôn ngữ thị giác do Google phát triển, xây dựng dựa trên phiên bản tiền nhiệm PaliGemma. Nó tích hợp bộ mã hóa thị giác SigLIP-So400m với các mô hình ngôn ngữ Gemma 2, tạo nên một hệ thống đa năng có khả năng hiểu và tạo ra cả dữ liệu thị giác và văn bản.
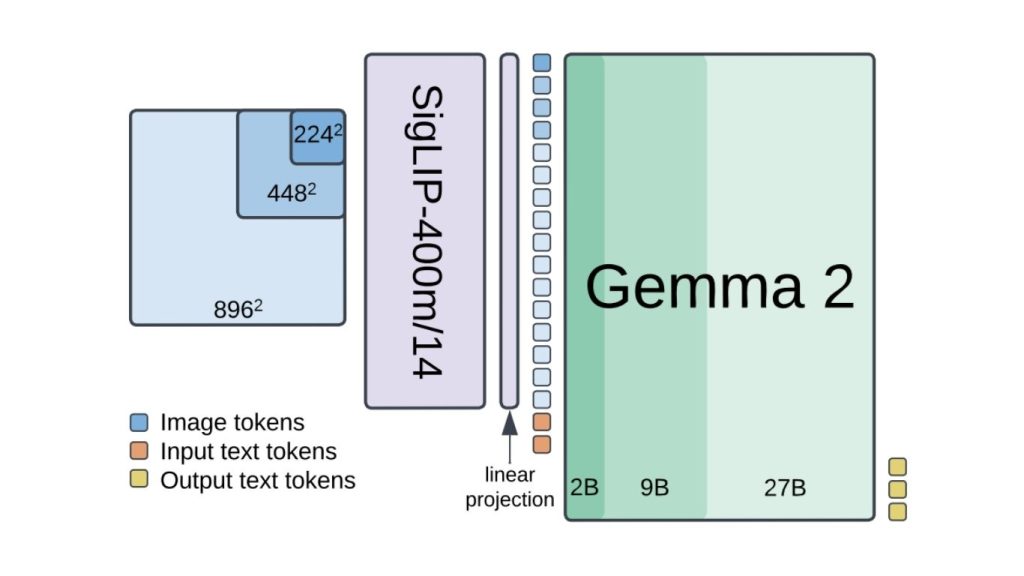
Dưới đây là các tính năng chính của PaliGemma-2:
- Chú thích hình ảnh: PaliGemma 2 có thể tạo ra các chú thích chi tiết và phù hợp với ngữ cảnh cho hình ảnh.
- Trả lời câu hỏi dựa trên hình ảnh (VQA): Mô hình có thể trả lời các câu hỏi liên quan đến nội dung hình ảnh với sự hiểu biết sâu sắc về bối cảnh hình ảnh.
- Nhận dạng ký tự quang học (OCR): PaliGemma 2 xuất sắc trong việc nhận dạng và xử lý văn bản trong hình ảnh, giúp nó hiệu quả cho các tác vụ phân tích tài liệu và trích xuất văn bản.
- Phát hiện và phân đoạn đối tượng: PaliGemma 2 có thể phát hiện và nhận diện các đối tượng trong hình ảnh. PaliGemma 2 cũng hỗ trợ tác vụ phân đoạn đối tượng.
- Ứng dụng chuyên biệt: PaliGemma 2 đã chứng minh hiệu suất dẫn đầu trong các lĩnh vực chuyên biệt như nhận dạng công thức hóa học, nhận dạng bản nhạc, suy luận không gian và tạo báo cáo X-quang ngực.
- Điều chỉnh và khả năng thích ứng: Paligemma 2 có thể được điều chỉnh trên tập dữ liệu tùy chỉnh cho các tác vụ phát hiện và phân đoạn đối tượng, cho phép thích ứng với nhiều tác vụ hạ lưu khác nhau.
Florence-2
Florence-2 là một mô hình nền tảng thị giác do Microsoft phát triển. Mô hình này được thiết kế để xử lý đa dạng tác vụ thị giác máy tính và ngôn ngữ thị giác thông qua một cách tiếp cận thống nhất dựa trên prompt. Florence-2 có thể diễn giải prompt văn bản để thực hiện các tác vụ như tạo chú thích hình ảnh, phát hiện đối tượng, định vị và phân đoạn hình ảnh.
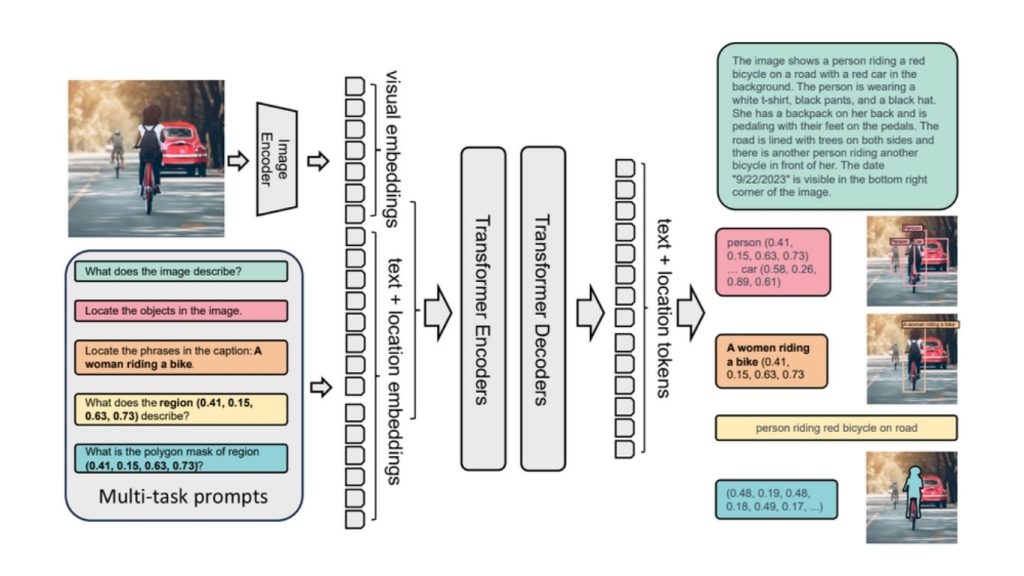
Dưới đây là các tính năng chính của Florence-2:
- Mô tả hình ảnh: Florence-2 có thể tạo ra các mô tả chi tiết về hình ảnh bằng cách nắm bắt cả các bối cảnh tổng quan và chi tiết nhỏ.
- Phát hiện đối tượng: Mô hình xác định và định vị nhiều đối tượng trong hình ảnh, cung cấp khung giới hạn và nhãn cho từng đối tượng được phát hiện.
- Định vị hình ảnh: Florence-2 liên kết các cụm từ văn bản với các vùng tương ứng trong hình ảnh, cho phép nó tập trung vào các yếu tố cụ thể dựa trên prompt mô tả.
- Phân đoạn hình ảnh: Florence-2 có thể được sử dụng cho các tác vụ phân đoạn. Nó xác định và vẽ đường viền cho các đối tượng hoặc khu vực trong hình ảnh ở cấp độ pixel.
- Đại diện dựa trên lời nhắc thống nhất: Florence-2 hiểu nhiều tác vụ khác nhau thông qua các chỉ dẫn văn bản đơn giản. Phương pháp này cho phép mô hình tạo ra các đầu ra mong muốn như tạo chú thích, OCR, định vị hình ảnh, phát hiện đối tượng hoặc phân đoạn,…
>> Xem thêm: Vertex AI là gì? Nền tảng học máy của Google Cloud
CogVLM
CogVLM là một mô hình nền tảng ngôn ngữ thị giác mã nguồn mở, được thiết kế cho các tác vụ kết hợp ngôn ngữ – thị giác. CogVLM tích hợp dữ liệu thị giác và văn bản bằng cách tích hợp mô-đun chuyên gia thị giác có thể huấn luyện vào các lớp mạng thần kinh chú ý và truyền thẳng của mô hình ngôn ngữ đã được huấn luyện trước.
Phương pháp tích hợp sâu này cho phép CogVLM kết hợp hiệu quả các đặc trưng hình ảnh và ngôn ngữ mà không làm giảm hiệu suất trên các tác vụ xử lý ngôn ngữ tự nhiên. Mô hình đạt được kết quả hàng đầu trên nhiều bộ dữ liệu đa phương thức.
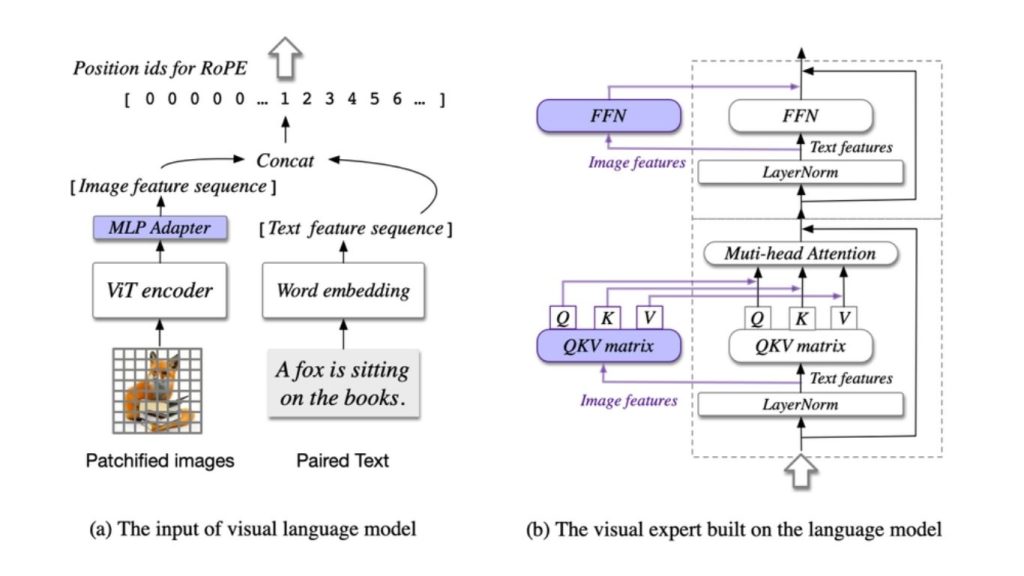
Dưới đây là các tính năng chính của CogVLM:
- Mô tả chi tiết: CogVLM cung cấp các mô tả chi tiết và có ngữ cảnh về nội dung thị giác.
- Trả lời câu hỏi dựa trên thị giác: CogVLM có thể phân tích thị giác để trả lời các câu hỏi phức tạp kèm ngữ cảnh.
- Lập luận không cần OCR: CogVLM thực hiện suy luận trên hình ảnh mà không cần phụ thuộc vào đầu ra OCR rõ ràng.
- Lập trình với đầu vào hình ảnh: CogVLM có thể sử dụng dữ liệu thị giác làm đầu vào để thực hiện các tác vụ lập trình.
- Kết nối với chú thích: Mô hình liên kết các mô tả văn bản với tọa độ cụ thể trong hình ảnh. Nó có thể phát hiện các đối tượng trong hình ảnh và cung cấp tọa độ chính xác của chúng.
- Kết nối trả lời câu hỏi hình ảnh: CogVLM kết nối các chi tiết thị giác cụ thể khi trả lời câu hỏi. Ví dụ, xác định màu sắc của quần áo mà một người mặc trong hình ảnh bằng cách xác định các đối tượng và thuộc tính liên quan.
- Hiểu biết về hình ảnh: CogVLM có khả năng cao trong việc hiểu những gì có trong hình ảnh. Nó có thể xử lý các biểu diễn hình ảnh của cấu trúc dữ liệu (như danh sách liên kết) trong hình ảnh và tạo ra các giải pháp lập trình phù hợp trong một ngôn ngữ được chỉ định. CogVLM cũng có thể phân tích các biểu đồ và ký hiệu toán học và đưa ra lý giải.
Llama 3.2-Vision
Llama 3.2-Vision là một phiên bản mở rộng đa phương thức của họ mô hình Llama do Meta phát triển. Nó được thiết kế để xử lý cả dữ liệu văn bản và thị giác bằng cách tích hợp bộ mã hóa hình ảnh với kiến trúc ngôn ngữ của Llama. Llama 3.2-Vision có thể thực hiện các tác vụ như nhận dạng đối tượng, hiểu bối cảnh, tạo chú thích hình ảnh và trả lời câu hỏi hình ảnh. Trong quá trình thực hiện các tác vụ này, nó vẫn duy trì khả năng mạnh mẽ của Llama trong việc hiểu và sinh ra văn bản.
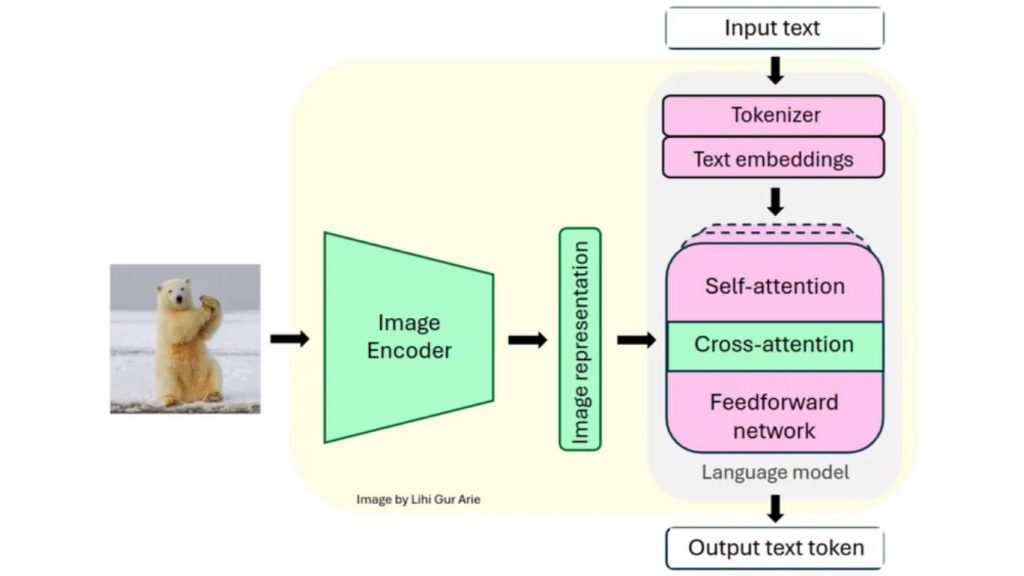
Dưới đây là các khả năng chính của Llama 3.2-Vision:
- Nhận dạng thị giác và suy luận hình ảnh: Llama 3.2-Vision có thể phân tích hình ảnh để nhận diện đối tượng, giải thích cảnh và hiểu bối cảnh hình ảnh. Khả năng này cho phép mô hình thực hiện các tác vụ như nhận diện đối tượng và phân tích cảnh.
- Ghi chú hình ảnh: Mô hình có thể tạo ra các chú thích mô tả cho hình ảnh và tóm tắt nội dung hình ảnh một cách hiệu quả. Nó được sử dụng để tạo mô tả cho hình ảnh.
- Trả lời câu hỏi về thị giác (VQA): Llama 3.2-Vision có thể trả lời các câu hỏi liên quan đến nội dung hình ảnh. Nó có khả năng hiểu cả các yếu tố thị giác và các truy vấn văn bản liên quan. Điều này bao gồm các tác vụ như xác định các đối tượng cụ thể trong hình ảnh hoặc giải thích các cảnh thị giác.
- Nhận dạng ký tự quang học (OCR): Llama 3.2-Vision có khả năng nhận dạng và giải thích văn bản trong hình ảnh để chuyển đổi ghi chú viết tay, tài liệu in hoặc văn bản trong ảnh. Nó được sử dụng để số hóa nội dung viết tay và trích xuất thông tin từ hình ảnh.
- Phân tích biểu đồ và bảng: Llama 3.2-Vision có thể giải thích và phân tích các biểu diễn dữ liệu thị giác như biểu đồ và bảng, trích xuất thông tin có ý nghĩa từ đó và cung cấp tóm tắt hoặc giải thích về dữ liệu được trình bày.
- Nhận dạng chữ viết tay: Llama 3.2-Vision có thể chuyển đổi chính xác văn bản viết tay từ hình ảnh, hỗ trợ trong việc số hóa ghi chú và tài liệu viết tay.
Qwen-VL
Qwen-VL là một mô hình ngôn ngữ thị giác quy mô lớn do Alibaba Cloud phát triển, được thiết kế để xử lý và hiểu cả thông tin văn bản và thị giác. Dựa trên nền tảng Qwen-LM, mô hình này tích hợp khả năng xử lý thị giác thông qua kiến trúc và quy trình đào tạo được thiết kế cẩn thận. Có các biến thể khác nhau của Qwen-VL, chẳng hạn như Qwen-VL, Qwen-VL-Chat và Qwen-VL-Max. Đây là các phiên bản chuyên biệt được thiết kế cho các ứng dụng cụ thể.
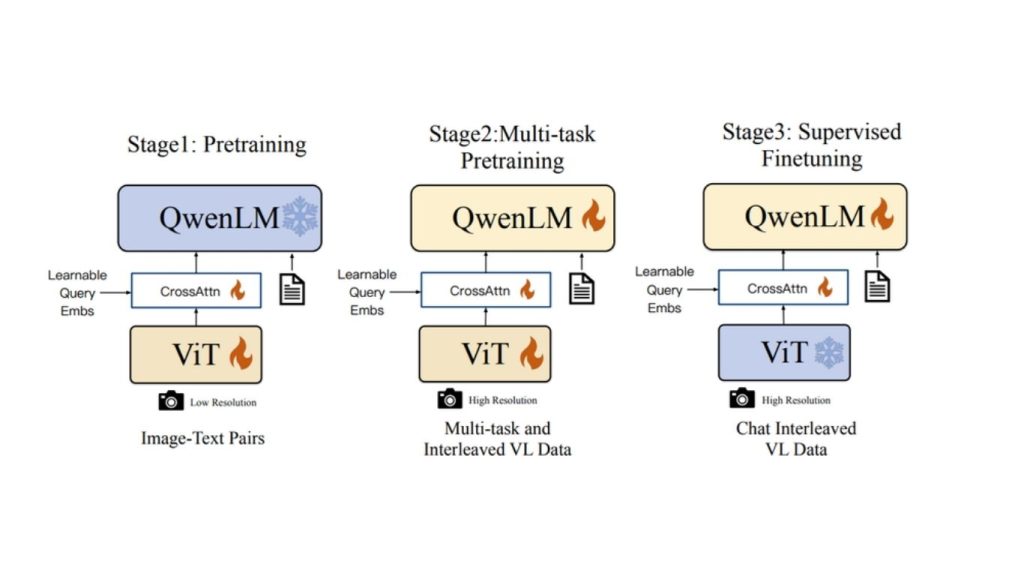
Dưới đây là các tính năng chính của Qwen-VL:
- Nhận dạng và mô tả hình ảnh: Qwen-VL có thể nhận diện và mô tả các yếu tố khác nhau trong hình ảnh đầu vào, bao gồm các vật thể thông thường, người nổi tiếng và các địa danh,…
- Trả lời câu hỏi hình ảnh (VQA): Qwen-VL trả lời các câu hỏi liên quan đến nội dung hình ảnh bằng cách hiểu bối cảnh hình ảnh. Nó phản hồi các câu hỏi về các vật thể hoặc cảnh cụ thể được thể hiện trong hình ảnh.
- Định vị thị giác: Qwen-VL tìm và xác định vùng tương ứng trong hình ảnh dựa trên các cụm từ văn bản. Nó cung cấp khung giới hạn và nhãn cho vùng khớp với các cụm từ văn bản.
- Nhận dạng văn bản (OCR): Qwen-VL hiệu quả trích xuất và xử lý văn bản từ hình ảnh, bao gồm bảng và tài liệu.
- Hỗ trợ đa ngôn ngữ: Qwen-VL hỗ trợ tự nhiên tiếng Anh, tiếng Trung và các cuộc trò chuyện đa ngôn ngữ, đồng thời thúc đẩy việc nhận dạng văn bản song ngữ trong hình ảnh từ đầu đến cuối.
- Lý luận hình ảnh nâng cao: Ngoài mô tả hình ảnh cơ bản, Qwen-VL có thể giải thích và phân tích các biểu diễn hình ảnh như sơ đồ luồng, biểu đồ và hệ thống ký hiệu. Nó có thể thực hiện các tác vụ giải quyết vấn đề từ dữ liệu thị giác, bao gồm lý luận toán học và phân tích sâu các biểu đồ và đồ thị.
Ngoài các mô hình VLMs đã liệt kê ở trên, chúng ta cũng có thể sử dụng Gemini, GPT-4o và Claude Multimodal Models làm VLMs vì các mô hình này cũng có khả năng xử lý thị giác.
>>> Xem thêm: Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
Các trường hợp sử dụng Mô hình ngôn ngữ thị giác
Trong phần này, chúng ta sẽ khám phá các tác vụ thị giác máy tính có thể thực hiện bằng mô hình ngôn ngữ thị giác. Chúng ta sẽ sử dụng hai VLMs phổ biến là Meta Llama 3.2V và Google Gemini cho các ví dụ của mình. Chúng ta sẽ sử dụng Roboflow Workflows cho các ví dụ này để minh họa cách sử dụng VLMs cho các tác vụ khác nhau.
Phân loại hình ảnh
Phân loại hình ảnh là tác vụ cơ bản trong thị giác máy tính. Nó giống như việc đưa cho mô hình một bức ảnh và hỏi “Đây là gì?” Mô hình phân tích hình ảnh và gán nó vào một hoặc nhiều danh mục đã được định nghĩa trước.
Ví dụ, khi được hiển thị một bức ảnh của một con chó golden retriever, mô hình sẽ phân loại nó là “chó” hoặc cụ thể hơn là “chó golden retriever” Đây là một tác vụ cơ bản và là nền tảng cho các tác vụ hiểu biết thị giác phức tạp hơn. Chúng ta có thể xây dựng ứng dụng phân loại hình ảnh với Roboflow Workflow mà không cần viết mã.
Để thực hiện điều này, hãy tạo một workflow mới và thêm Llama 3.2 Vision, VLM làm bộ phân loại và các khối hiển thị nhãn phân loại như minh họa bên dưới.
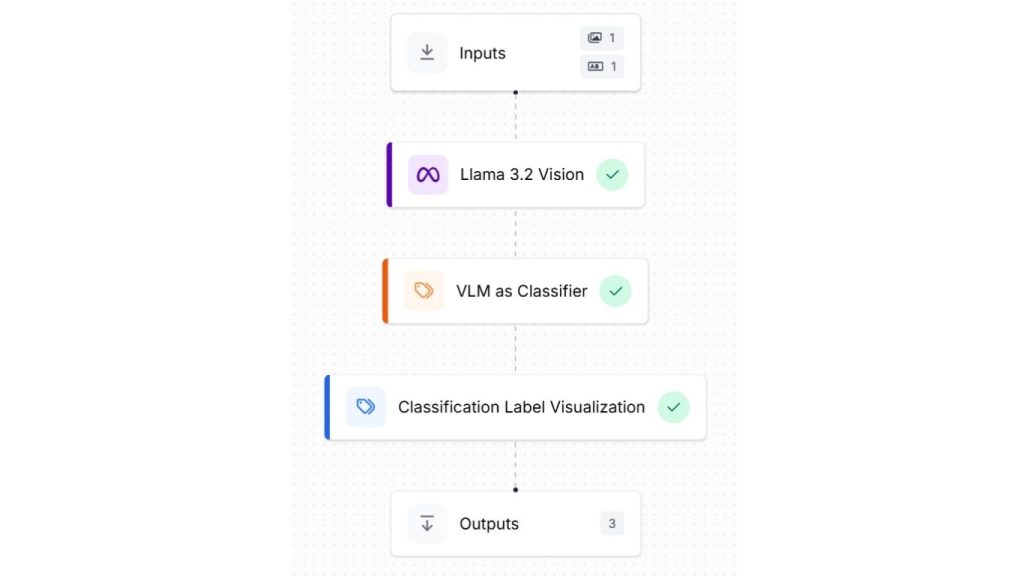
Trước tiên, block Input cần được cấu hình để chấp nhận nhãn lớp trong tham số “labels” và hình ảnh trong tham số “image”. Trong ví dụ này, hai lớp mặc định đã được khai báo trong tham số “labels” dưới dạng một danh sách Python.
Bây giờ chúng ta sẽ xem các cấu hình cho từng khối. Khối đầu vào (Input block) cần được cấu hình để chấp nhận nhãn lớp trong tham số “labels” và hình ảnh trong tham số “image”. Trong ví dụ dưới đây, cũng được chỉ định hai lớp mặc định trong tham số “labels” dưới dạng đối tượng danh sách Python.
>> Tìm hiểu thêm: Xây dựng ứng dụng phát hiện đối tượng bằng Python chỉ trong vài phút với Roboflow
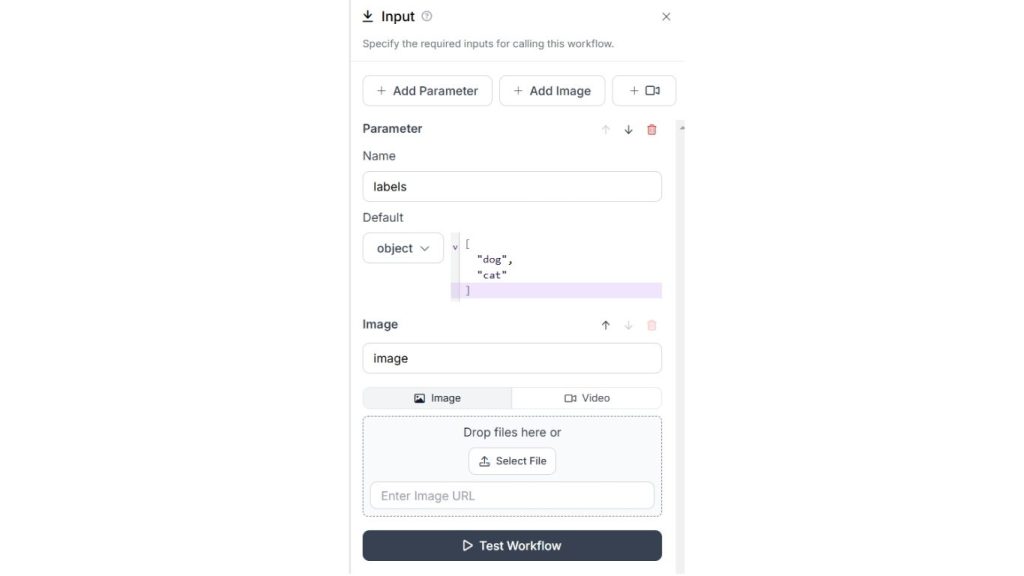
Tiếp theo, bạn cần cấu hình khối Llama 3.2 Vision. Trong khối này, hãy chỉ định loại tác vụ là “Single-Label Classification”, trường “classes” phải được được liên kết với tham số “labels” mà chúng ta đã chỉ định trong khối đầu vào ở bước trên. Đồng thời, hãy nhập khóa API của Llama Vision mà bạn đã nhận được từ OpenRouter. Khối Llama 3.2 Vision sẽ có cấu hình như sau.
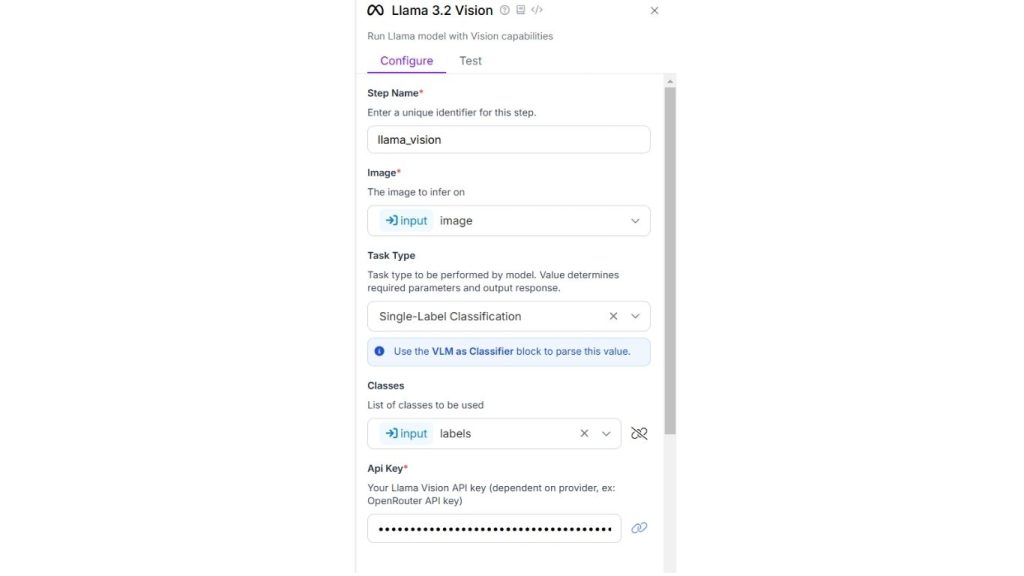
Khối tiếp theo là VLM với vai trò là khối phân loại. Khối này nhận đầu vào chuỗi từ khối Vision Llama 3.2. Đầu vào sau đó được phân tích để dự đoán phân loại và trả về dưới dạng đầu ra của khối. Dưới đây là cấu hình cho khối này.
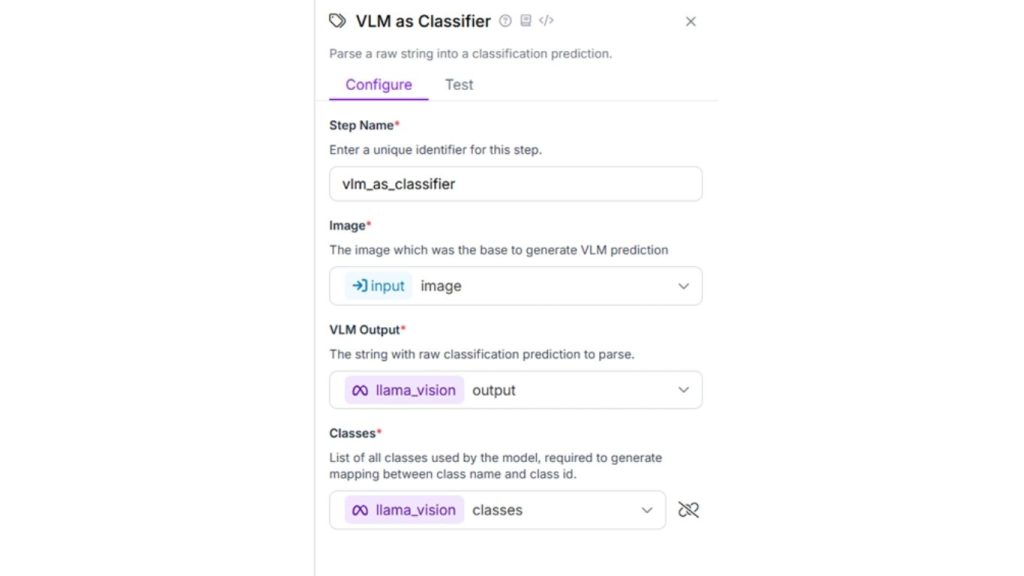
Tiếp theo, hãy cấu hình khối hiển thị nhãn phân loại. Khối này trực quan hóa kết quả phân loại đơn nhãn và đa nhãn với các tùy chọn hiển thị có thể tùy chỉnh. Sử dụng các cấu hình sau và giữ nguyên các thiết lập mặc định khác.
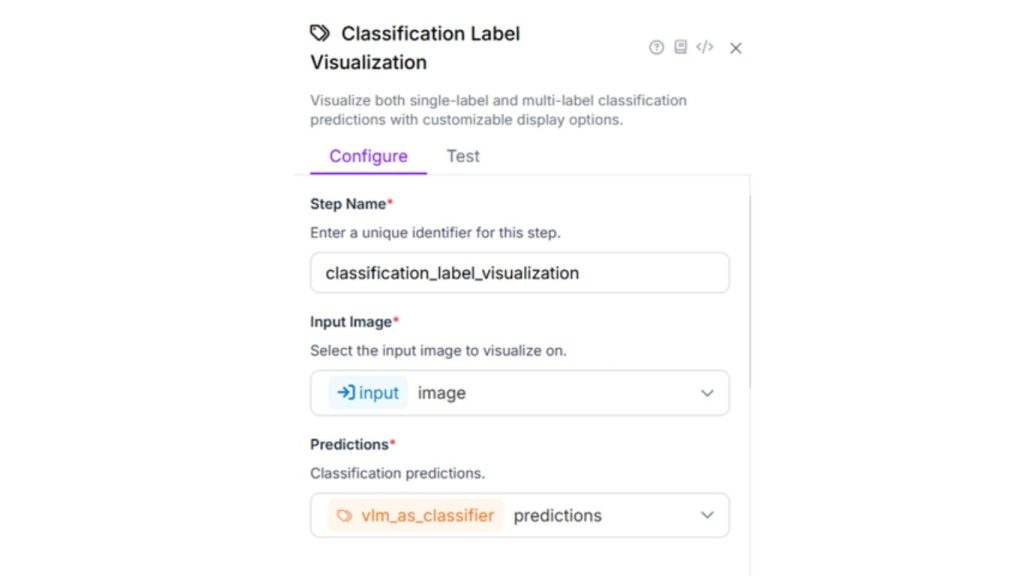
Cuối cùng, khối đầu ra sẽ có cấu hình như hình dưới đây.
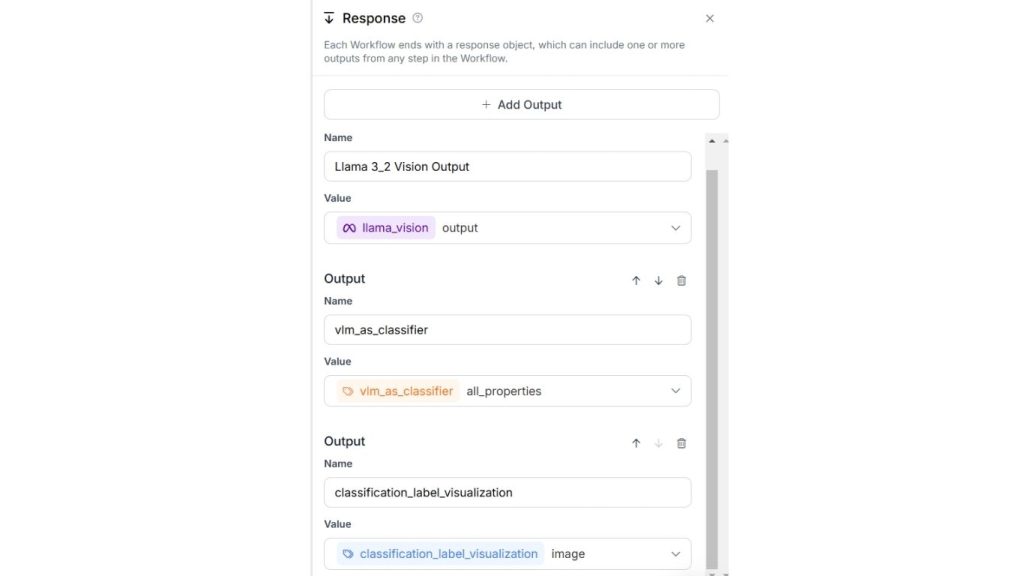
Dưới đây là kết quả sau khi chạy Workflow. Một hình ảnh “dog” đã được tải lên và mô hình phân loại nó là “dog” với độ tin cậy cao. Bạn có thể thử với bất kỳ hình ảnh nào khác và chỉ định các nhãn lớp mới. Trong đầu ra của workflow này, bạn sẽ thấy hình ảnh kèm theo nhãn phân loại.
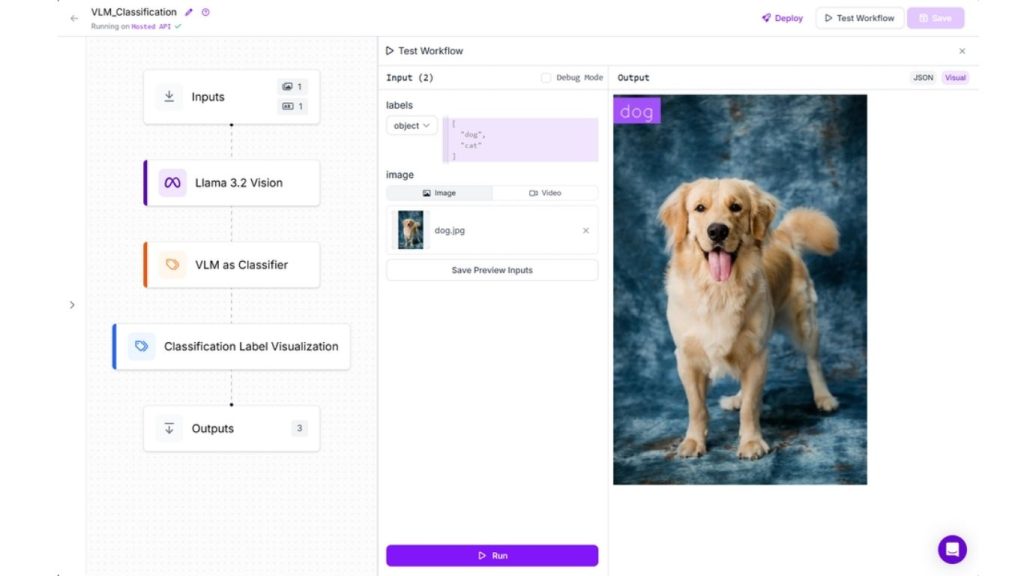
>>> Xem thêm:
- Phân tích hình ảnh bằng AI là gì? Cách AI hiểu và diễn giải hình ảnh
- AI nhận diện ảnh là gì? Thuật toán và ứng dụng phổ biến
Phát hiện đối tượng
Phát hiện đối tượng (Object Detection) đưa phân loại hình ảnh tiến thêm một bước bằng cách không chỉ xác định các đối tượng xuất hiện trong hình ảnh mà còn xác định vị trí của chúng. Mô hình sẽ vẽ các hộp giới hạn xung quanh các đối tượng được phát hiện và gán nhãn cho từng đối tượng.
Hãy tưởng tượng một bức ảnh đường phố đông đúc, mô hình sẽ xác định và vẽ khung bao quanh xe hơi, người đi bộ, đèn giao thông và các đối tượng khác, đồng thời gắn nhãn cho từng đối tượng. Tác vụ này yêu cầu mô hình hiểu được cả đối tượng là gì và vị trí không gian của chúng so với nhau.
Để minh họa phát hiện đối tượng bằng VLM, chúng ta sẽ sử dụng mô hình Google Gemini với Roboflow Workflow. Quy trình làm việc tạo ra cho ví dụ này sẽ trông như sau:
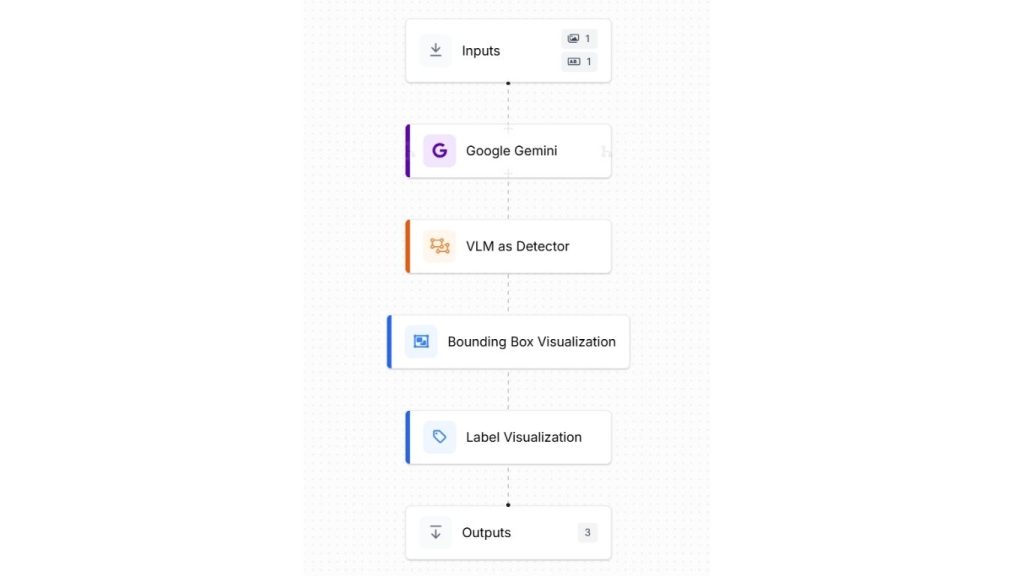
Khối đầu vào tương tự như ví dụ trên với nhãn lớp và hình ảnh tải lên
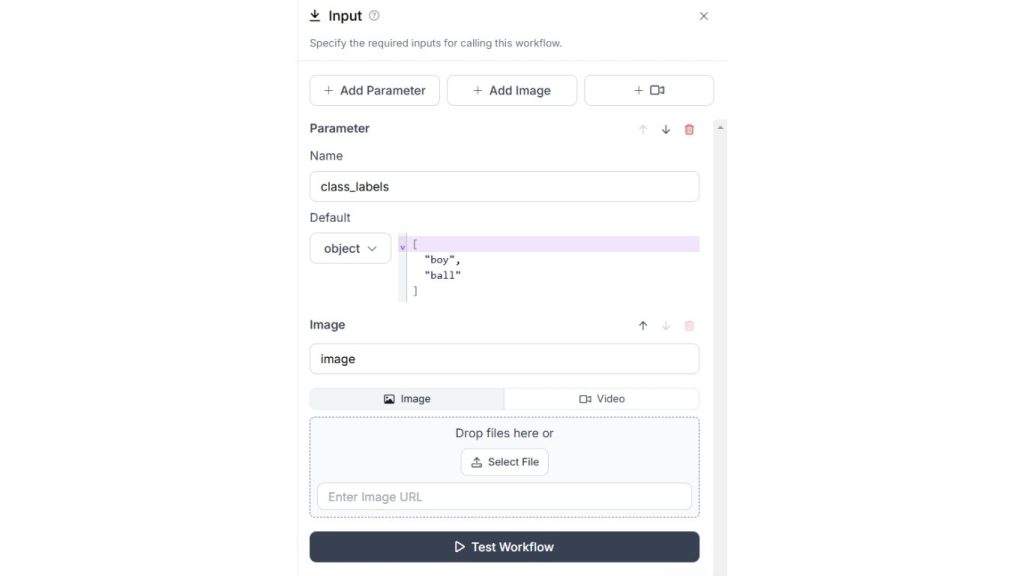
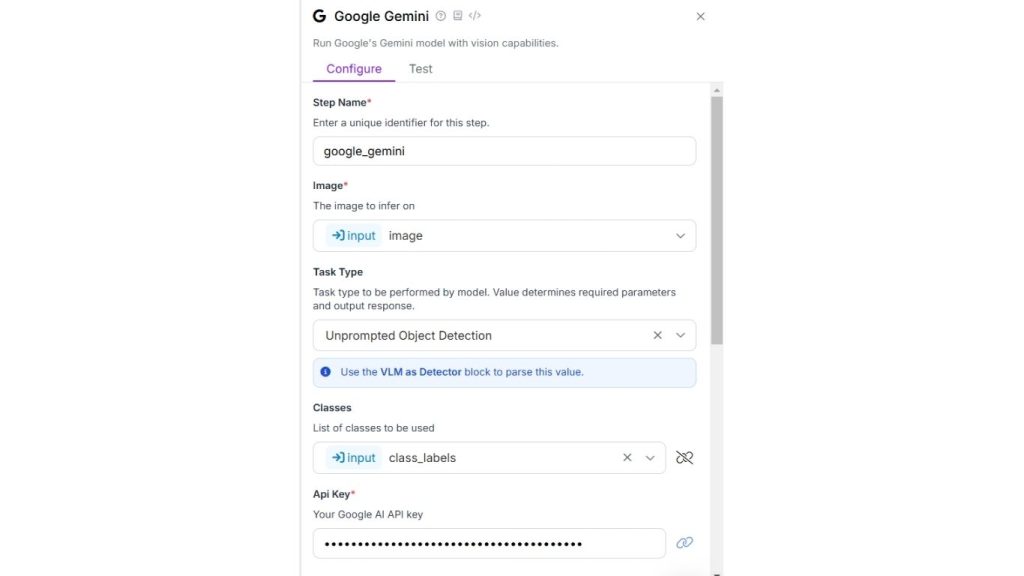
Thêm các khối Google Gemini, VLM làm bộ phát hiện và hiển thị nhãn, cũng như hiển thị khung giới hạn vào quy trình làm việc của bạn. Chúng ta sẽ sử dụng Google Gemini cho loại tác vụ “Unprompted Object Detection – Phát hiện đối tượng không cần gợi ý” vì chúng ta muốn phát hiện đối tượng bằng cách chỉ định nhãn lớp trong khối đầu vào. Dưới đây là cấu hình cho khối Google Gemini.
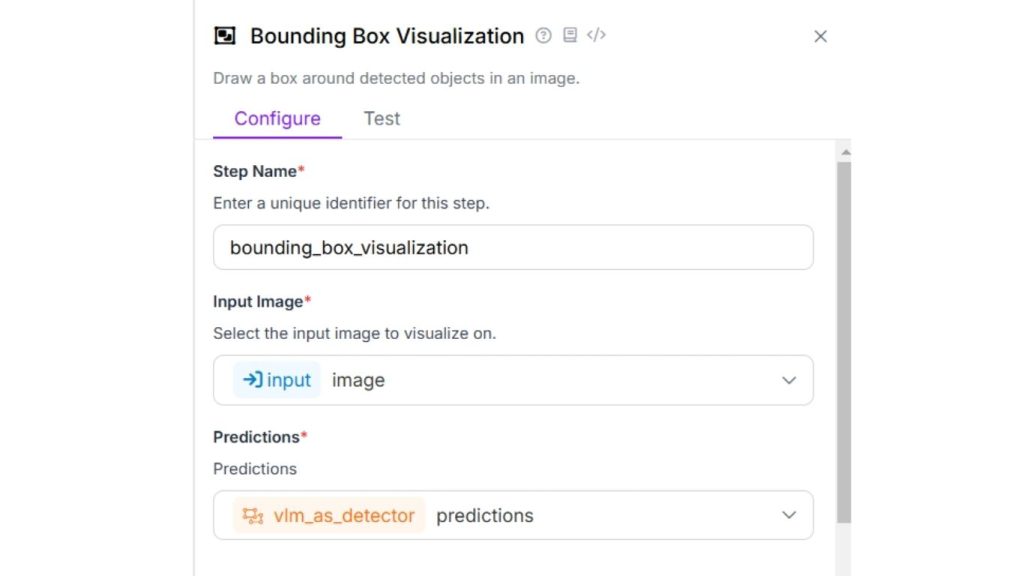
Bây giờ hãy cấu hình khối hiển thị hộp giới hạn như minh họa bên dưới.
Sau đó, cấu hình khối hiển thị nhãn để hiển thị nhãn kèm theo khung giới hạn trong hình ảnh đầu ra.
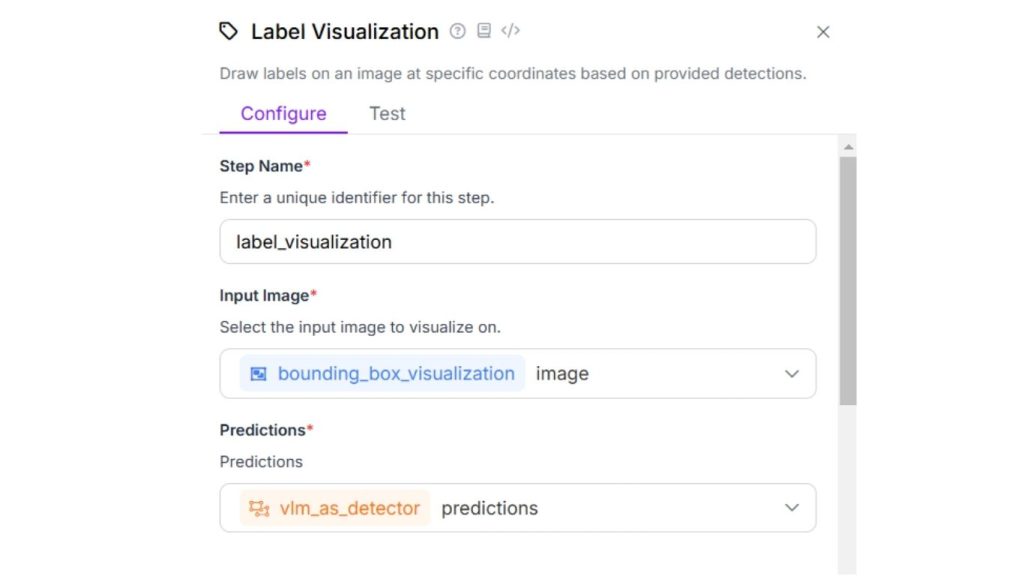
Ngoài các thuộc tính mặc định của khối hiển thị nhãn, bạn có thể thiết lập “Lớp và Độ tin cậy” cho thuộc tính văn bản để hiển thị cả nhãn lớp và điểm tin cậy tương ứng.
Cuối cùng, khối đầu ra nên trông như sau.
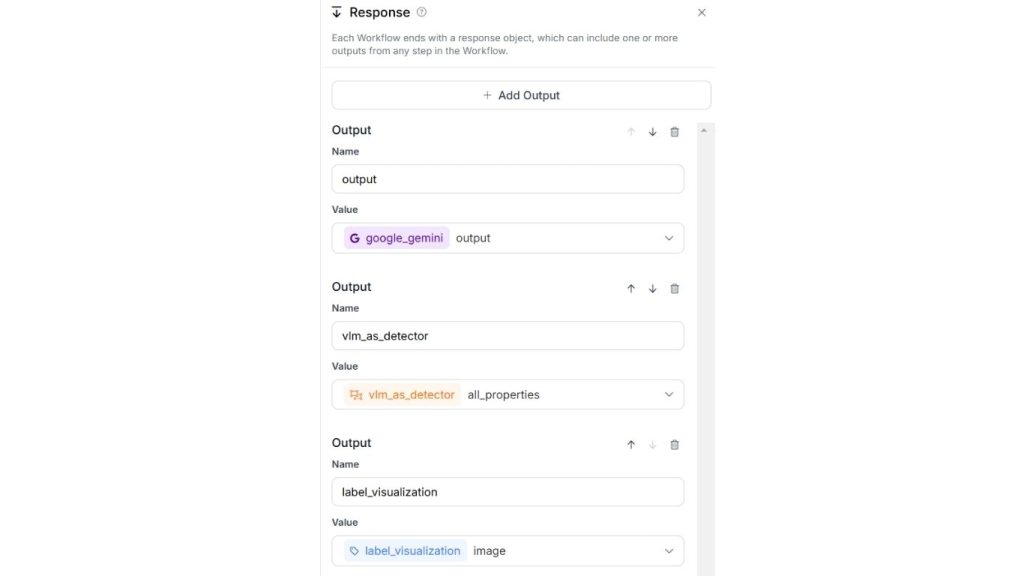
Khi bạn chạy quy trình làm việc này, bạn sẽ thấy kết quả đầu ra như sau.
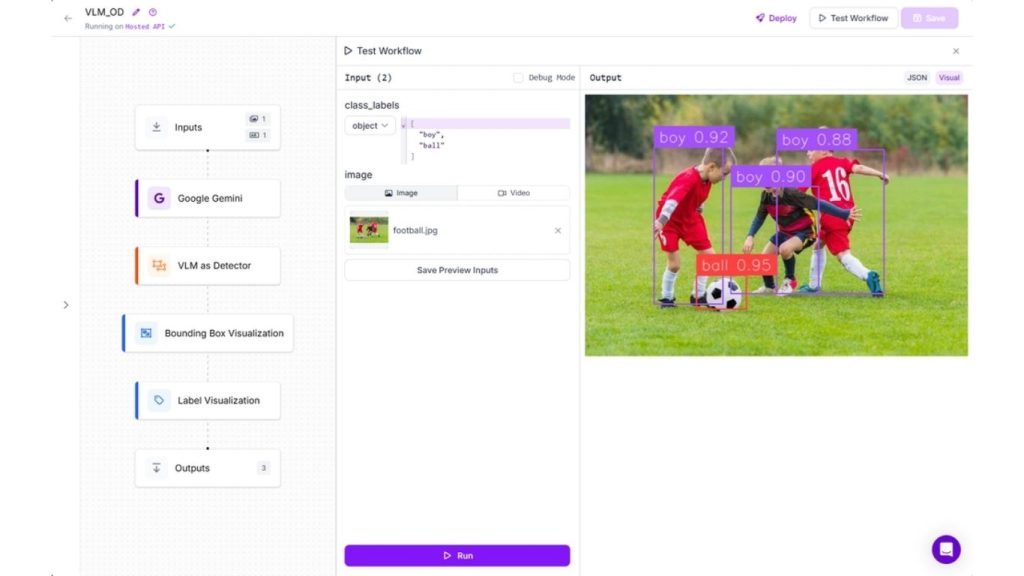
>> Tìm hiểu thêm: Phát hiện đối tượng trong video với RF-DETR
Chú thích hình ảnh
Chú thích hình ảnh là tác vụ tạo ra mô tả bằng văn bản cho một hình ảnh. Mô hình sẽ sinh ra một câu mô tả những gì nó nhìn thấy trong hình ảnh. Ví dụ, với một bức ảnh công viên, mô hình có thể tạo ra câu: “Một gia đình trẻ đang tổ chức picnic dưới một cây sồi lớn vào một ngày nắng đẹp”.
Tác vụ này không chỉ yêu cầu nhận diện đối tượng mà còn phải hiểu mối quan hệ và ngữ cảnh của chúng để tạo ra mô tả mạch lạc và có ý nghĩa.
Trong ví dụ này, chúng ta sẽ tạo quy trình chú thích hình ảnh sử dụng khối Llama 3.2 Vision. Cấu hình “Loại tác vụ” là “Chú thích ngắn” hoặc “Chú thích” trong khối Llama 3.2 Vision. Khi chạy quy trình, bạn sẽ thấy kết quả như sau.
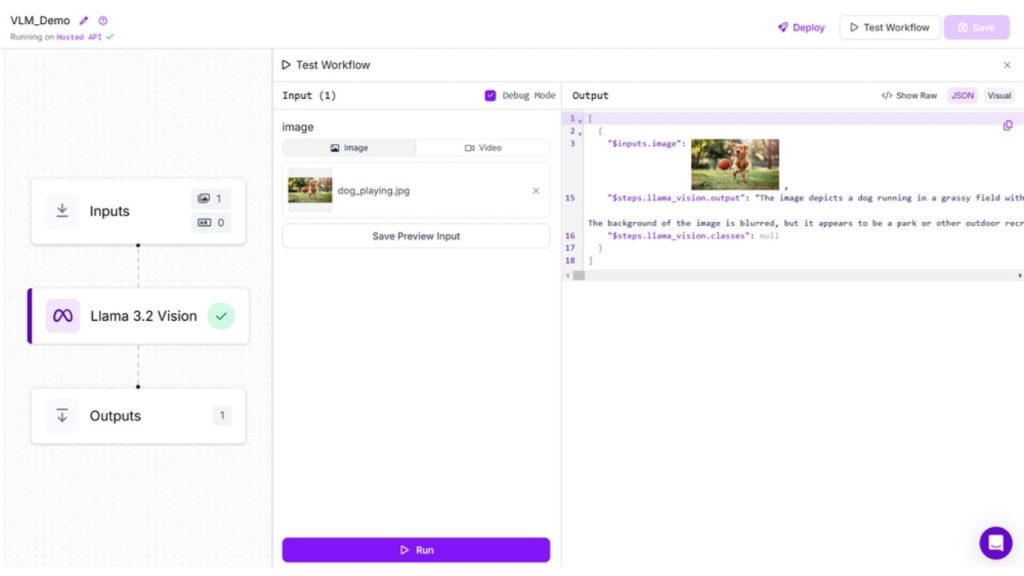
Trả lời câu hỏi hình ảnh (VQA)
Trả lời câu hỏi hình ảnh (VQA) đại diện cho một hình thức tương tác hơn trong việc hiểu hình ảnh. Mô hình phải trả lời các câu hỏi cụ thể về hình ảnh, yêu cầu nó hiểu đồng thời nội dung thị giác và câu hỏi bằng ngôn ngữ tự nhiên.
Ví dụ, với một hình ảnh nhà bếp và câu hỏi: “Tủ lạnh có màu gì?”, mô hình cần xác định vị trí tủ lạnh, nhận diện màu sắc của nó và đưa ra câu trả lời. Điều này thể hiện mức độ hiểu và suy luận hình ảnh sâu hơn.
Trong ví dụ này, chúng ta sẽ tạo một luồng làm việc VQA sử dụng khối Llama 3.2 Vision. Đầu tiên, cấu hình khối đầu vào với tham số “câu hỏi” và đầu vào hình ảnh.
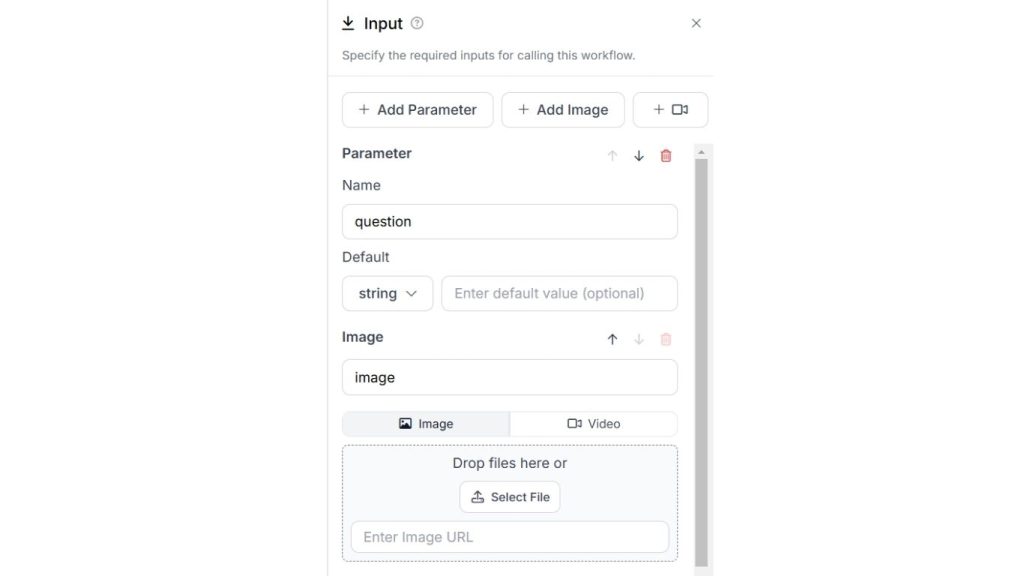
Sau đó, thêm khối Llama 3.2 Vision và cấu hình nó với loại tác vụ là “Trả lời câu hỏi bằng hình ảnh” và liên kết trường prompt với tham số “question”.
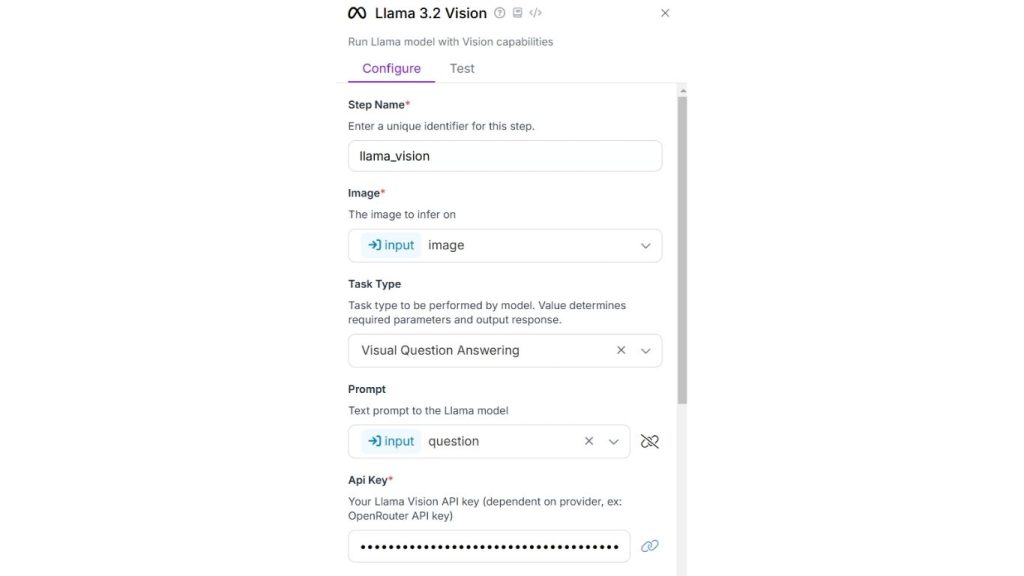
Chạy quy trình làm việc, thêm câu hỏi và tải lên hình ảnh. Bạn sẽ thấy kết quả sau đây.
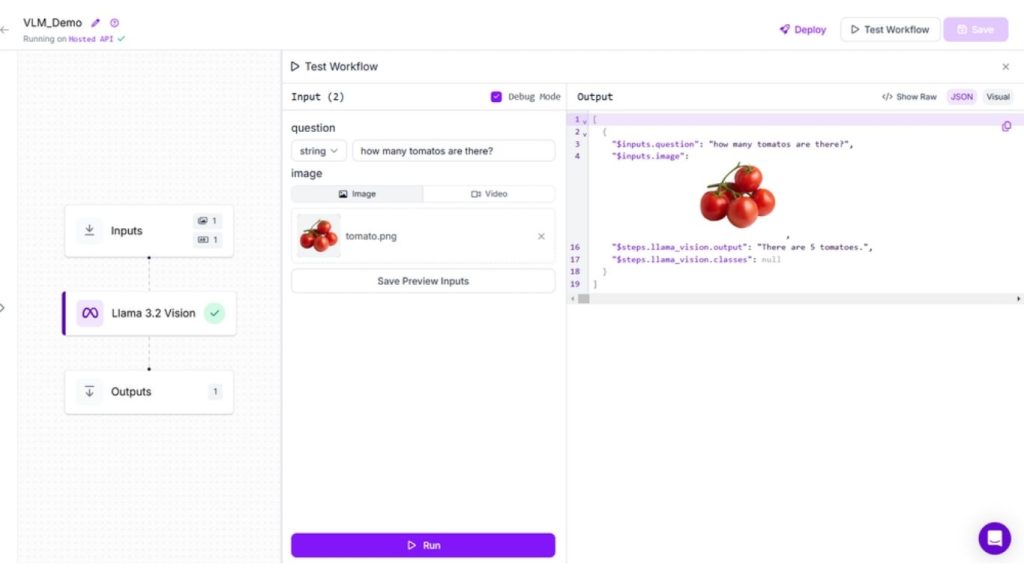
Nhận dạng văn bản (OCR)
Nhận dạng văn bản, thường được gọi là Nhận dạng ký tự quang học (OCR), là quá trình phát hiện và chuyển đổi văn bản trong hình ảnh thành văn bản có thể đọc được bởi máy tính.
Trong ví dụ của chúng ta, chúng ta sẽ tạo một quy trình Nhận dạng văn bản (OCR) sử dụng khối Llama 3.2 Vision. Cấu hình “Loại tác vụ” là “Nhận dạng văn bản (OCR)” trong khối Llama 3.2 Vision. Khi chạy quy trình, bạn sẽ thấy kết quả sau.
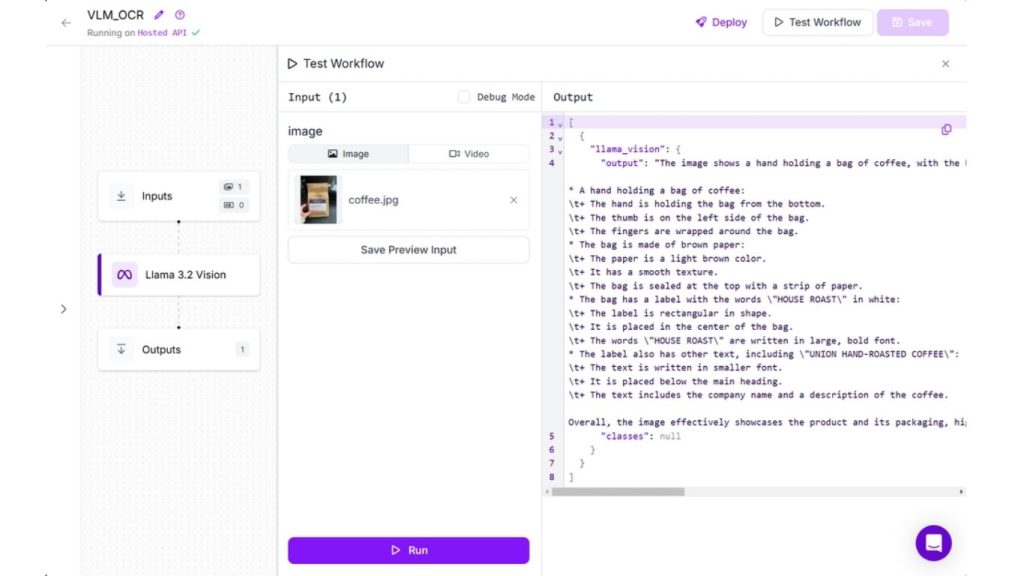
Đối với các tác vụ khác như Phân đoạn và Visual Grounding – Định vị thị giác (Phrase Grounding), bạn có thể tạo quy trình làm việc với khối Florence-2. Tuy nhiên, để sử dụng Florence-2 trong các quy trình làm việc Roboflow, bạn cần thiết lập một triển khai chuyên dụng với GPU hoặc chạy quy trình làm việc trên thiết bị hỗ trợ GPU.
>> Xem thêm:
- Thiết kế website bằng AI miễn phí, chuẩn SEO, hiệu quả
- Hướng dẫn tạo website bán hàng online miễn phí, chuyên nghiệp
Khi nào và tại sao bạn nên tinh chỉnh mô hình ngôn ngữ thị giác?
Trong giai đoạn ban đầu, được gọi là giai đoạn huấn luyện ban đầu, VLM được huấn luyện trên các tập dữ liệu lớn bao gồm cả hình ảnh và văn bản. Mục tiêu của giai đoạn này là học các biểu diễn tổng quát, nắm bắt mối quan hệ rộng giữa dữ liệu thị giác và văn bản. Ví dụ, các mô hình như Pali Gemma-2 học cách căn chỉnh hình ảnh và chú thích tương ứng bằng cách tối đa hóa độ tương đồng giữa các cặp phù hợp.
Tinh chỉnh mô hình ngôn ngữ thị giác là quá trình lấy một mô hình đã được huấn luyện trước trên các tập dữ liệu lớn, chung chung và điều chỉnh nó để thực hiện một tác vụ cụ thể hoặc hoạt động tốt trong một lĩnh vực cụ thể. Quá trình này bao gồm việc huấn luyện (hoặc “tinh chỉnh”) mô hình đã được huấn luyện trước trên một tập dữ liệu nhỏ hơn, chuyên biệt cho tác vụ, cho phép mô hình điều chỉnh các tham số của mình để có thể xử lý tác vụ mới một cách hiệu quả hơn.
Vì thế, sau giai đoạn tiền huấn luyện, mô hình sẽ tiếp tục được huấn luyện trên một tập dữ liệu nhỏ hơn, tập trung vào tác vụ cụ thể. Việc tinh chỉnh điều chỉnh các biểu diễn đã học để cải thiện một tác vụ mục tiêu, chẳng hạn như mô tả hình ảnh, VQA hoặc thậm chí các tác vụ chuyên biệt trong các lĩnh vực cụ thể như hình ảnh y tế hoặc hình ảnh vệ tinh,…
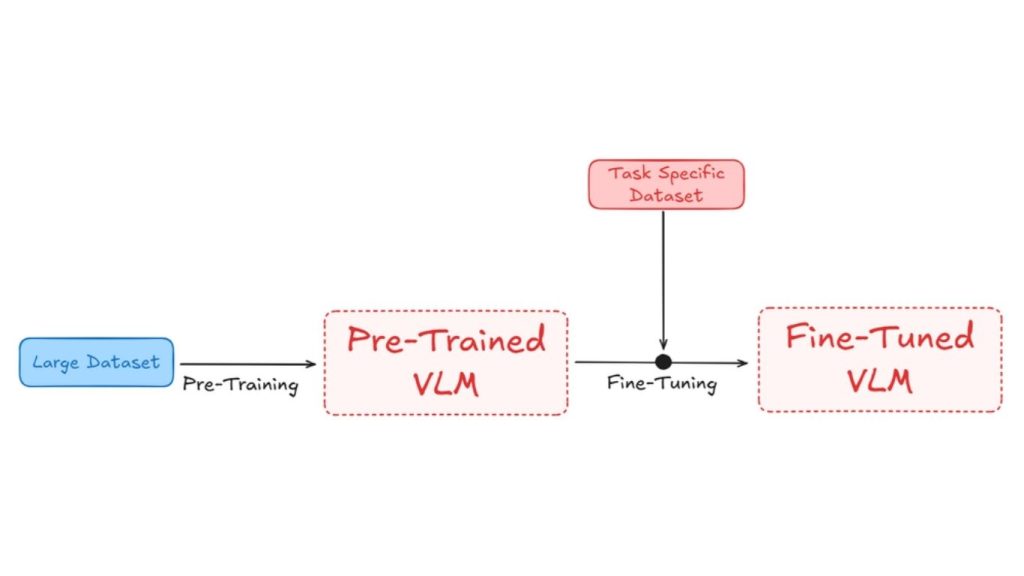
Điều chỉnh mô hình VLM có thể cần thiết vì nhiều lý do, chẳng hạn như:
Thích ứng miền
Thích ứng miền là quá trình điều chỉnh mô hình đã được huấn luyện sẵn để hoạt động hiệu quả trong một miền mới, chuyên biệt (domain) nơi dữ liệu khác biệt so với dữ liệu ban đầu mà mô hình được huấn luyện. Điều này quan trọng vì các miền khác nhau thường có đặc điểm riêng biệt, như từ vựng, cụm từ hoặc phong cách hình ảnh đặc trưng.
Ví dụ, trong môi trường công nghiệp, một mô hình tổng quát có thể gặp khó khăn khi phát hiện lỗi máy móc, nhưng khi được tinh chỉnh mô hình bằng các hình ảnh cụ thể, khả năng phát hiện sẽ được cải thiện đáng kể.
Hiệu suất chuyên biệt cho từng tác vụ
Tinh chỉnh mô hình giúp nó tập trung vào một tác vụ cụ thể bằng cách điều chỉnh kiến thức chung của mô hình để phù hợp với yêu cầu của công việc đó. Điều này cải thiện độ chính xác và mức độ liên quan của mô hình.
Ví dụ, bạn có một mô hình nhận diện hình ảnh đã được huấn luyện sẵn có thể nhận diện các vật thể thông thường như mèo, chó và xe hơi. Bây giờ, bạn muốn sử dụng nó để phát hiện các lỗi trong sản phẩm sản xuất (ví dụ: vết xước trên các bộ phận kim loại). Mô hình có thể không hoạt động tốt ban đầu vì nó không được đào tạo cho tác vụ cụ thể này.
Bằng cách tinh chỉnh mô hình trên tập dữ liệu hình ảnh sản phẩm có khuyết tật và không có khuyết tật, mô hình học cách tập trung vào các đặc điểm quan trọng cho việc phát hiện khuyết tật, như vết xước hoặc vết lõm, và trở nên tốt hơn nhiều trong tác vụ cụ thể này.
Hiệu quả và sử dụng tài nguyên
Tinh chỉnh mô hình hiệu quả hơn so với việc đào tạo mô hình từ đầu vì nó dựa trên những gì mô hình đã biết. Điều này giảm bớt nhu cầu về tập dữ liệu khổng lồ và sức mạnh tính toán, đồng thời mô hình học nhanh hơn.
Ví dụ, thay vì đào tạo hệ thống nhận diện hình ảnh cho xe tự lái từ đầu, việc tinh chỉnh mô hình nhận diện đối tượng chung bằng hình ảnh liên quan đến lái xe sẽ đẩy nhanh quá trình và giảm chi phí.
Tùy chỉnh và linh hoạt
Tinh chỉnh cho phép bạn điều chỉnh mô hình cho các tác vụ mới hoặc cải thiện hiệu suất mà không cần bắt đầu lại từ đầu. Điều này làm cho mô hình linh hoạt và có thể tùy chỉnh cho các nhu cầu khác nhau.
Ví dụ, một chatbot được đào tạo trên dữ liệu trò chuyện chung có thể không hiểu thuật ngữ pháp lý. Tinh chỉnh nó bằng các tài liệu pháp lý cho phép nó cung cấp các phản hồi tốt hơn cho các câu hỏi liên quan đến pháp luật.
>> Xem thêm:
- Cách tích hợp chatbot vào website, miễn phí, bán hàng hiệu quả
- Top 20 phần mềm chatbot tốt nhất, miễn phí, phổ biến hiện nay
Sử dụng các mô hình ngôn ngữ thị giác tốt nhất
Các mô hình ngôn ngữ thị giác (VLMs) kết hợp công nghệ thị giác máy tính và xử lý ngôn ngữ tự nhiên, cho phép máy móc hiểu và tạo nội dung liên quan đến cả hình ảnh và văn bản. Các mô hình này có thể thực hiện nhiều tác vụ, như nhận diện đối tượng trong hình ảnh, đọc văn bản từ hình ảnh (OCR) hoặc trả lời câu hỏi về hình ảnh.
Một số mô hình VLMs phổ biến bao gồm PaliGemma-2, Florence-2, CogVLM và Llama 3.2-Vision. Việc tinh chỉnh các mô hình này giúp chúng hoạt động hiệu quả hơn trong các tác vụ cụ thể, từ đó trở nên hữu ích hơn cho các ứng dụng chuyên biệt.
Kết luận
Hy vong qua bài viết trên đã giúp bạn hiểu khái niệm “mô hình ngôn ngữ thị giác là gì”. Mô hình ngôn ngữ thị giác (VLM) đang dần trở thành nền tảng cốt lõi của AI đa phương thức, giúp hệ thống không chỉ nhìn thấy hình ảnh mà còn hiểu, suy luận và tương tác với chúng bằng ngôn ngữ tự nhiên. Sự phát triển của các mô hình như PaliGemma-2, Florence-2, CogVLM hay Llama 3.2-Vision đã mở ra nhiều ứng dụng giá trị, từ phân tích hình ảnh, OCR đến trả lời câu hỏi và tự động hóa thông minh.
Do đó, việc lựa chọn và tinh chỉnh VLM phù hợp sẽ là chìa khóa giúp doanh nghiệp và nhà phát triển khai thác hiệu quả dữ liệu thị giác cho các bài toán cụ thể.
>>> Nguồn tham khảo: What is a Vision Language Model?
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com🏢 Địa chỉ:31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam







