
GPT-5 đứng #1 trong bài kiểm tra Vision Checkup bao gồm hơn 80 prompt viết tay được thiết kế xoay quanh các tác vụ thực tế. Bài đánh giá giúp chúng ta tìm hiểu về khả năng thị giác của chat GPT-5, từ việc phân tích dây chuyền lắp ráp để phát hiện vật thể bị treo lơ lửng cho đến việc phân tích và hiểu các bố cục dạng lưới phức tạp, chẳng hạn như vị trí các quân cờ trên bàn cờ vua.
Toàn bộ 5 vị trí đầu tiên trên bảng xếp hạng các nhiệm vụ thị giác đều thuộc về các mô hình của OpenAI, tiếp theo là Gemini 2.5, các mô hình Claude 4 của Anthropic, và nhiều mô hình khác. Điều này cho thấy chất lượng trong quy trình huấn luyện của OpenAI, đặc biệt là đối với các khả năng thị giác.
Chúng tôi đã công bố một bài blog vào ngày hôm qua, chia sẻ các kết quả ban đầu. Tuy nhiên, sau khi có thêm thời gian trải nghiệm mô hình, chúng tôi có thêm nhiều nhận định sâu hơn để chia sẻ.
Nhìn chung, khả năng thị giác của ChatGPT-5 không tạo ra một bước nhảy vọt mang tính đột phá về hiệu năng trong các nhiệm vụ thị giác. Liệu đây có phải là một mô hình phù hợp để sử dụng hằng ngày cho các tác vụ thị giác đa phương thức không? Có. Mô hình có hoạt động tốt trong các tác vụ thực tế không? Có. Có những lĩnh vực mà mô hình chưa được cải thiện không? Có. Chúng tôi sẽ phân tích chi tiết điểm mạnh và điểm yếu của GPT-5 ở phần bên dưới.
>>> Xem thêm:
- Hướng dẫn cách sử dụng Google AI Studio hiệu quả, nhanh chóng
- Hướng dẫn triển khai AI trong ứng dụng di động đơn giản
- Cách sử dụng AI trong phát triển phần mềm như thế nào?
GPT-5 trong thực tế: Tiềm năng suy luận mạnh mẽ
GPT-5 thể hiện khả năng ổn định trong các bài toán VQA (Visual Question Answering – Hỏi đáp dựa trên hình ảnh) và trong việc hiểu mối quan hệ không gian giữa các đối tượng. Mô hình cho thấy hiệu suất hạn chế trong phát hiện đối tượng (object detection), tuy nhiên GPT-5 không được huấn luyện chuyên biệt cho nhiệm vụ này, vì vậy mức độ ảnh hưởng của hạn chế này là tương đối.
>>> Xem thêm các bài viết khác:
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
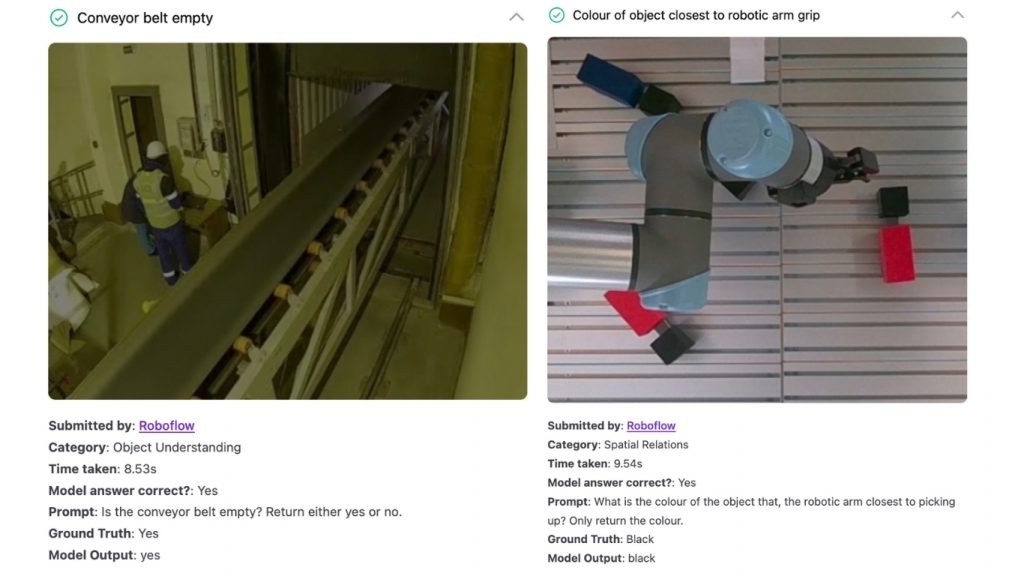
Trong ví dụ bên phải phía trên, chúng tôi đặt một câu hỏi phức tạp, nhiều bước về màu sắc của đối tượng mà cánh tay robot sắp nhặt lên. Mô hình đã trả lời chính xác là “đen”. Đây là một bài toán khó vì có nhiều đối tượng khác nhau xung quanh cánh tay robot. Việc hoàn thành tốt nhiệm vụ này cho thấy khả năng suy luận không gian (spatial reasoning) rất mạnh của mô hình.
Tuy nhiên, GPT-5 lại gặp khó khăn với các tác vụ như:
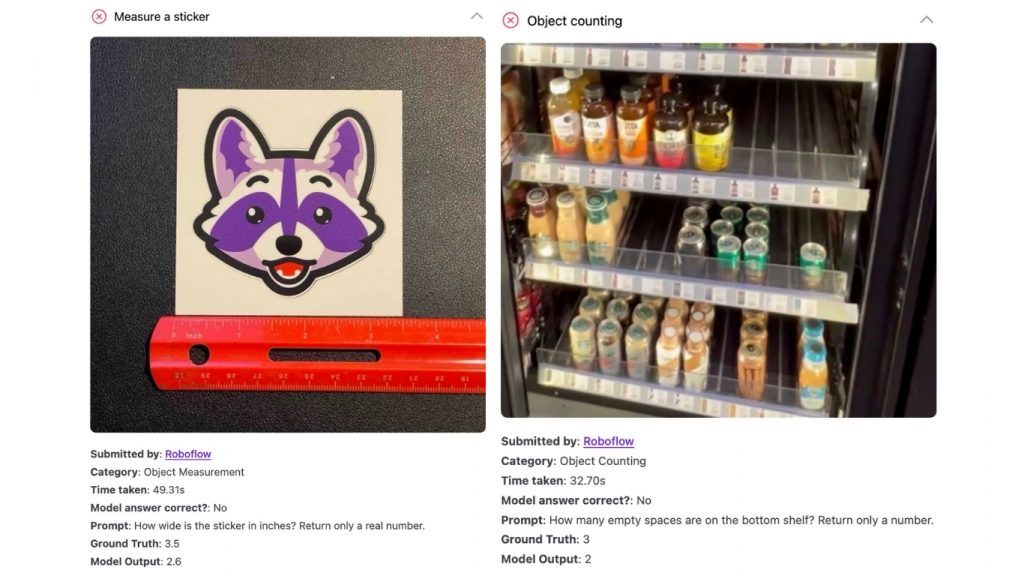
- Đếm số lượng đối tượng (ví dụ: “có bao nhiêu con vít trong hình?”)
- Đo lường kích thước dựa trên vật tham chiếu (ví dụ: “miếng sticker rộng bao nhiêu?”)
Đây là những bài toán mà chúng tôi nhận thấy các mô hình đa phương thức thường xuyên gặp khó khăn.
>>> Xem thêm:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Vertex AI là gì? Nền tảng học máy của Google Cloud
Thông báo chính thức của OpenAI tập trung nhiều hơn vào khả năng âm thanh (audio) trong bộ năng lực đa phương thức của mô hình, cũng như các cải tiến về khả năng lập trình.
Nói cách khác, dựa trên thông báo ban đầu, chúng tôi không kỳ vọng một sự cải thiện lớn về chất lượng thị giác, nhưng hiệu suất kém kéo dài trong các bài kiểm tra “vibe check” về đếm đối tượng và đo lường đối tượng cho thấy vẫn còn những khoảng trống về nghiên cứu hoặc dữ liệu cần được cải thiện để nâng cao hiệu năng trên các nhiệm vụ thị giác khác nhau.
Tiến trình phát triển của khả năng hiểu thị giác: Nhìn lại lịch sử
Quay trở lại năm 2023, chúng tôi đã thử nghiệm GPT-4 with Vision, mô hình GPT đa phương thức đầu tiên của OpenAI có khả năng xử lý hình ảnh. Khi đó, người dùng có thể đặt câu hỏi về nội dung của một hình ảnh. Chúng tôi thực sự ấn tượng, và niềm tin mà chúng tôi theo đuổi trong nhiều năm đã trở thành hiện thực: đột phá trong mô hình ngôn ngữ sẽ nhanh chóng lan sang lĩnh vực thị giác máy tính.
Bằng cách kết hợp khả năng ngôn ngữ với thị giác, các mô hình GPT có thể tận dụng ngữ nghĩa phong phú học được từ văn bản và mối liên hệ ngữ cảnh giữa hình ảnh và văn bản để đưa ra các câu trả lời chi tiết. Những tác vụ như OCR chữ viết tay vốn trước đây cực kỳ khó nếu không xây dựng pipeline phức tạp đã trở nên dễ dàng và phổ biến thông qua các ứng dụng miễn phí.
Tiến bộ trong khả năng thị giác của Chat GPT-5
Kể từ năm 2023, chúng ta đã tiến rất xa. GPT-4 with Vision có khả năng OCR ấn tượng và một số năng lực hiểu tài liệu, nhưng vẫn thất bại trong nhiều bài kiểm tra, chẳng hạn như đếm tiền xu hoặc hiểu hóa đơn một cách ổn định.
Khi các mô hình mới lần lượt ra mắt – Gemini, Qwen-VL 2.5, các mô hình GPT “o” thiên về suy luận – các bài kiểm tra thủ công trước đây của chúng tôi nhanh chóng trở nên lỗi thời. Các mô hình ngày càng làm tốt hơn trong các tác vụ VQA tổng quát và OCR.
Tuy vậy, vẫn có một số lĩnh vực liên tục tỏ ra khó khăn:
- Đếm đối tượng
- Đo lường đối tượng dựa trên tham chiếu
- Phát hiện đối tượng
>>> Xem thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Các mô hình phát hiện đối tượng tốt nhất
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
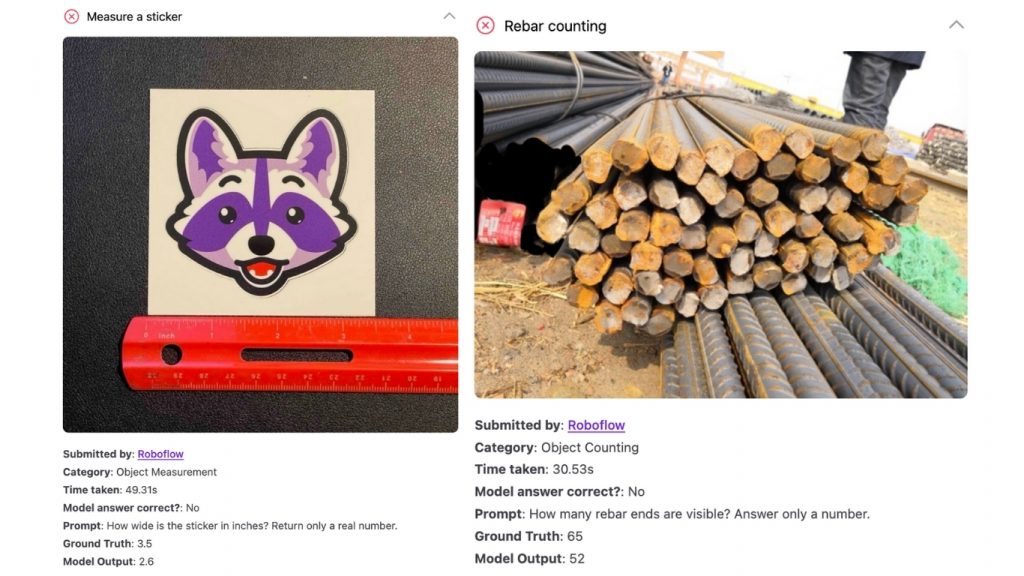
Trong số đó, phát hiện đối tượng là một điểm mù rõ rệt, đặc biệt với các mô hình đa phương thức không được huấn luyện chuyên biệt cho nhiệm vụ này. OpenAI đã phát hành khả năng fine-tune GPT-4o cho object detection, nhưng hiệu suất còn hạn chế và không khả thi cho môi trường production do chi phí cao.
Khi được benchmark trên RF100-VL một bộ benchmark phát hiện đối tượng đa lĩnh vực, GPT-5 xếp sau Gemini 2.5 Pro. Trong bài đánh giá ban đầu, chúng tôi ghi nhận:
mAP50:95 của GPT-5 đạt 1.5, thấp hơn đáng kể so với SOTA hiện tại của Gemini 2.5 Pro là 13.3.
Ngoài ra, chúng tôi cũng nhận thấy sự không ổn định về hiệu suất của các mô hình. Sau khi GPT-4 with Vision ra mắt, chúng tôi đã xây dựng một website để theo dõi hiệu năng của mô hình và các phiên bản cải tiến của OpenAI, bằng cách chạy cùng một bộ đánh giá mỗi ngày. Trong một số trường hợp, mô hình trả lời đúng ở lần chạy này nhưng lại sai khi được hỏi lại.
Điều này càng rõ rệt khi chúng tôi thử nghiệm GPT-5. Chúng tôi phải chạy các bài đánh giá nhiều lần do kết quả không đồng nhất. Dù cỡ mẫu nhỏ (~80 prompt) khiến mỗi câu trả lời sai có tác động lớn đến độ biến thiên, chúng tôi nhận thấy rằng GPT-5 tuy ổn định ở nhiều nhiệm vụ, nhưng vẫn không nhất quán ở một số nhiệm vụ khác tương tự các mô hình đa phương thức hiện nay.
Điều này dẫn đến một bài học quan trọng khi làm việc với GPT-5: khi các mô hình suy luận ngày càng phổ biến, việc benchmark nhiều lần và đảm bảo kết quả luôn chính xác là điều thiết yếu cho bất kỳ tác vụ nào yêu cầu đầu ra đáng tin cậy mà thực tế thì đa số các bài toán trong thế giới thực đều như vậy.
>>> Xem thêm:
- Cách ứng dụng AI tối ưu trải nghiệm khách hàng
- 18 cách ứng dụng AI cho ecommerce đạt hiệu quả cao
Hướng đi tiếp theo
GPT-5 là một mô hình mạnh về khả năng hiểu đa phương thức. Tuy nhiên, mô hình không mang đến các tính năng mới như cải thiện rõ rệt trong phát hiện đối tượng, đếm, phân đoạn, hay nhiều nhiệm vụ khác (trong đó phát hiện và phân đoạn là những nhiệm vụ mà các mô hình Gemini hiện đang làm tốt hơn).
Những đánh giá của chúng tôi phù hợp với “cảm nhận chung” của cộng đồng: khả năng thị giác của chat GPT-5 mạnh ở nhiều tác vụ, nhưng vẫn tồn tại những hạn chế đáng kể. Riêng về thị giác, cùng một prompt có thể cho ra hai câu trả lời khác nhau, và mô hình vẫn gặp khó khăn với đếm và đo lường.
Chúng tôi luôn hào hứng khi thử nghiệm các mô hình mới. Lịch sử phát triển các mô hình đa phương thức của OpenAI cho thấy chúng ta có thể tiến xa đến mức nào chỉ trong thời gian ngắn. Chỉ trong hai năm, quan niệm của chúng ta về những gì có thể làm được với mô hình đa phương thức đã thay đổi hoàn toàn. GPT-5 không phải là bước nhảy vọt cho thị giác, nhưng câu hỏi đặt ra là: còn mô hình tiếp theo thì sao? Chúng tôi sẽ tiếp tục theo dõi, kiểm thử định tính và cập nhật khi các mô hình mới ra mắt, cũng như khi hiểu biết của cộng đồng về khả năng thị giác của Chat GPT-5 ngày càng đầy đủ hơn.
Nguồn tham khảo: Reflections on GPT-5 Vision Capabilities
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Hoàng Diệu, Phường 12, Quận 4, Thành phố Hồ Chí Minh, Việt Nam







