Với những tiến bộ trong các mô hình nền tảng đa phương thức, các kỹ thuật tự động phân đoạn, và tạo dữ liệu tổng hợp, việc gán nhãn dữ liệu AI chính xác vẫn là một cấu phần then chốt của các hệ thống AI có thể triển khai thực tế ở môi trường sản xuất. Các bộ dữ liệu “sạch”, được chú giải một cách chính xác và nhất quán, quyết định trực tiếp độ chính xác của mô hình, mức độ sẵn sàng tuân thủ, tốc độ lặp cải tiến, và cuối cùng là hiệu năng trong thế giới thực.
Ngày nay, các nhóm phát triển phải đối mặt với những tình huống gán nhãn phức tạp, bao gồm chú giải thủ công, công cụ bán tự động, và các pipeline thuần dữ liệu tổng hợp. Mỗi phương án đều có ưu và nhược điểm riêng về chi phí, độ chính xác, và khả năng mở rộng.
Làm chủ quy trình gán nhãn sẽ tạo lợi thế cạnh tranh mang tính quyết định cho tổ chức của bạn, dù bạn triển khai robot phẫu thuật đòi hỏi chú giải “đúng đến từng pixel”, hay huấn luyện mô hình phân tích bán lẻ với hàng triệu điểm dữ liệu.
>>> Xem thêm các bài viết khác:
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
- TOP 10 AI thiết kế website miễn phí, trả phí, hiệu quả
- Cách tạo ứng dụng AI với vibe coding trên Google AI Studio đơn giản
- Hướng dẫn triển khai AI trong ứng dụng di động đơn giản
Gán nhãn dữ liệu là gì và vì sao quan trọng?
Gán nhãn dữ liệu là thực hành chú giải ảnh, video, hoặc dữ liệu đa phương thức (ví dụ: chữ nằm trong ảnh, LiDAR, v.v.) bằng siêu dữ liệu hoặc các thẻ mô tả để các mô hình thị giác máy tính học được quy luật và khái quát hóa.
Các định dạng gán nhãn phổ biến bao gồm:
- Khung giới hạn: Chú giải hình chữ nhật đơn giản bao quanh đối tượng.
- Chú giải đa giác : Hình dạng phức tạp bao viền đối tượng chính xác.
- Phân đoạn ngữ nghĩa và phân đoạn theo cá thể: Mặt nạ theo mức pixel xác định lớp và từng cá thể.
- Gán nhãn điểm mốc: Đánh dấu các điểm riêng lẻ (ví dụ: khớp trong ước lượng tư thế).
- Chú thích mô tả và OCR: Nhãn văn bản mô tả hoặc phiên âm văn bản trong ảnh.
- Chú giải đa phương thức: Kết hợp nhiều dạng chú giải, ví dụ gắn prompt văn bản tương ứng với một vùng thị giác.
Gán nhãn chắc chắn và nhất quán cung cấp ngữ cảnh ngữ nghĩa cần thiết cho huấn luyện mô hình, giúp các ứng dụng AI diễn giải đầu vào thị giác chính xác hơn.
Vì sao gán nhãn dữ liệu vẫn quan trọng?
Các mô hình đa phương thức quy mô lớn có thể “nuốt” pixel, token và embedding, nhưng “sự thật chuẩn” của chúng vẫn bắt nguồn từ dữ liệu đã được gán nhãn. Ngay cả những mô hình thị giác–ngôn ngữ tốt nhất như SAM, Grounding-DINO, GPT-4o-vision, v.v. vẫn cần dữ liệu gán nhãn có độ trung thực cao cho:
- Tinh chỉnh/thích nghi miền: Căn chỉnh các bộ mã hóa tổng quát với các trường hợp biên của bạn.
- Đánh giá và kiểm thử hồi quy: Bạn không thể tin các chỉ số như mAP (mean Average Precision), ROUGE, BLEU nếu thiếu ground truth đáng tin.
- Chất lượng token: “Vision tokens” đưa vào mô hình ngôn ngữ lớn sẽ thừa hưởng mọi sai sót gán nhãn ở thượng nguồn.
Chỉ một định nghĩa lớp bị nhiễu hoặc một cụm bị gán nhãn sai cũng có thể làm lệch quá trình học đặc trưng và “âm thầm” đặt trần cho mAP/F1, bất kể backbone mạnh đến đâu.
Tóm lại, độ chính xác của nhãn chuyển hóa trực tiếp thành độ tin cậy mô hình trong thế giới thực, khả năng tuân thủ quy định, và niềm tin của người dùng.
Những xu hướng nào đang định hình gán nhãn dữ liệu hiện nay?
Có bốn xu hướng lớn đang làm tăng độ phức tạp và mức độ “tinh vi” của quy trình gán nhãn:
1. “Nhãn giả” do LLM tạo
- Các mô hình nền tảng đa phương thức và VLM tạo nhãn ban đầu, sau đó con người cải thiện để đảm bảo chất lượng cao.
- Ví dụ: SAM/Grounding-DINO xử lý mask và box, trong khi GPT-4o Vision xử lý caption và gợi ý bố cục.
- Lợi ích: Khởi tạo nhanh, rút ngắn giai đoạn “cold start”.
- Lưu ý: “Tin nhưng phải kiểm chứng”, vì lỗi mang tính hệ thống sẽ lan truyền nếu không được chặn.
2. Bùng nổ dữ liệu video tổng hợp và dữ liệu 3D
- Game engine (Blender, Unity), pipeline NeRF (Neural Radiance Fields), và bộ mô phỏng LiDAR tạo ra các trường hợp biên và sự kiện hiếm với nhãn hoàn hảo.
- Lợi ích: Đa dạng biến thiên dữ liệu lớn với chi phí thấp hơn.
- Lưu ý: Cần quản trị thích nghi miền cẩn thận để tránh suy giảm do lệch phân phối, tức “khoảng cách miền”.
3. Gia tăng các bài toán đa phương thức
- Các tác vụ phân tích đồng thời đầu vào thị giác, văn bản và cảm biến (ví dụ: grounding chữ-trong-ảnh, hỏi–đáp biểu đồ, căn chỉnh thị giác–ngôn ngữ) cho thấy nhãn cần biểu diễn ý nghĩa và quan hệ, không chỉ vị trí.
- Lợi ích: Rất phù hợp cho caption phục vụ tiếp cận và trích xuất thuộc tính sản phẩm.
- Lưu ý: Mỗi modality cần chiến lược gán nhãn “đồng bộ”, khiến công cụ và khung gán nhãn hợp nhất trở nên thiết yếu.
4. Yêu cầu tuân thủ và kiểm toán
Khi giám sát pháp lý tăng mạnh (đặc biệt trong các khung như EU AI Act), quy trình gán nhãn có khả năng truy vết trở thành bắt buộc. Quy định đòi hỏi:
- Nhãn có truy vết (ai gán, gán cái gì, lúc nào, bằng cách nào).
- Lược đồ có phiên bản và nhật ký kiểm toán (cũng quan trọng để theo dõi trôi nhãn/label drift ở phía phát triển).
- Dòng dõi dữ liệu: liên kết mỗi dự đoán của mô hình về lại một mẫu đã gán nhãn.
>>> Xem thêm:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- Cách ứng dụng AI tối ưu trải nghiệm khách hàng
Gán nhãn chính xác và minh bạch giờ đây vừa là yêu cầu tuân thủ, vừa là nhu cầu kỹ thuật.
Giới thiệu ba quy trình gán nhãn cốt lõi
Các nhóm hiện nay thường dùng một (hoặc pha trộn) các quy trình sau:
- Quy trình 1: Thủ công + giao diện hỗ trợ
Người gán nhãn thực hiện chính, dùng giao diện trực quan và công cụ (phím tắt, “snap”, mẫu/template) để tăng tốc. - Quy trình 2: Mô hình trong vòng lặp
Mô hình (ví dụ: SAM, truy hồi dựa CLIP) tạo nhãn trước; lấy mẫu theo bất định/đa dạng để đẩy các mẫu “khó” cho con người tinh chỉnh. - Quy trình 3: Ưu tiên tổng hợp
Tạo dữ liệu tổng hợp đã gán nhãn ở quy mô lớn; con người kiểm toán và hiệu chỉnh so với mẫu dữ liệu thật.
Ghi chú: Active learning là một vòng lặp có thể “phủ” lên hai quy trình đầu; ở đây được nêu riêng nhưng được xem là một phần của quy trình 2.
Việc chọn quy trình tối ưu phụ thuộc mạnh vào yêu cầu độ chính xác, độ phức tạp dữ liệu, ngân sách gán nhãn, và ràng buộc tuân thủ.
>>> Xem thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Các mô hình phát hiện đối tượng tốt nhất
- Tối ưu website bằng AI là gì? Cách tối ưu SEO và các công cụ AI

Quy trình #1: Công cụ gán nhãn dữ liệu AI có hỗ trợ
Khi từng pixel (hoặc từng ký tự) đều quan trọng, như trong ảnh y khoa, rà soát pháp lý, hoặc robot an toàn trọng yếu, bạn vẫn phải dựa vào con người.
Điểm mấu chốt là kết hợp người gán nhãn có chuyên môn với giao diện hỗ trợ, phím nóng, kiểm tra tự động, và vòng QA chặt để duy trì độ chính xác cao mà không “chảy máu” ngân sách.
Các trường hợp sử dụng
Quy trình thủ công + hỗ trợ phát huy trong các bối cảnh phức tạp, rủi ro cao như:
- Y tế và y sinh (ranh giới khối u, tiêu bản mô bệnh học): Chú giải các ảnh chẩn đoán nhạy cảm (X-quang, MRI) đòi hỏi độ chính xác và sự tinh tế diễn giải chỉ có thể đạt được qua đánh giá của chuyên gia.
- Tài liệu pháp lý và tuân thủ (OCR + độ chính xác che/redaction, gán thẻ điều khoản hợp đồng): Cần hiểu ngữ cảnh, đánh ranh giới chính xác, và sai số tối thiểu.
- Miền nhiều trường hợp biên (lỗi hiếm trong sản xuất, robot phẫu thuật, quốc phòng): Nhiệm vụ chuyên biệt hoặc phân biệt tinh tế mà mô hình tự động thường không làm ổn nếu thiếu trực giác người.
- Dự án “dao động lược đồ” (schema-volatile): Nhãn thay đổi thường xuyên; con người phải diễn giải sắc thái.
Những trường hợp này ưu tiên chất lượng và độ chính xác hơn là mở rộng bằng tự động hóa.
Các bẫy thường gặp
Tuy nhiên, phụ thuộc vào gán nhãn thủ công có các bất lợi:
- Mệt mỏi và thiếu nhất quán: Công việc lặp đi lặp lại, chi tiết cao làm giảm hiệu suất và tăng lỗi người, ảnh hưởng chất lượng tập dữ liệu.
- Schema creep: Định nghĩa lớp “trôi” âm thầm; nhãn cũ không còn khớp.
- Thiên lệch ẩn: Các người gán nhãn khác nhau diễn giải lớp mơ hồ khác nhau.
- Chi phí cao và thông lượng thấp: Thủ công thuần túy khó mở rộng nếu thiếu UI/UX tối ưu.
Các biện pháp giảm thiểu: Ca làm ngắn hơn, luân phiên người gán nhãn, bài hiệu chuẩn định kỳ (kiểm tra “golden set”), nhật ký thay đổi schema rõ ràng, và công cụ công thái học để giảm số click/thời gian.
Lớp hỗ trợ của Roboflow rút ngắn mỗi thao tác chú giải và tập trung QA. Cụ thể:
- Giao diện gán nhãn nhanh: Bộ chọn lớp, công cụ polygon, chỉnh mask, và “smart snapping” để người gán nhãn làm việc hiệu quả.
- Phím tắt và template: Áp nhãn hàng loạt, nhân bản/lan truyền chú giải giữa các khung (frames).
- Hàng đợi QA và rà soát chéo giữa người gán nhãn: Chỉ định người kiểm vòng 2, so sánh mức đồng thuận, gắn cờ xung đột để xử lý, và theo dõi tỷ lệ phê duyệt.
- Phiên bản hóa và lịch sử có thể kiểm toán: Mọi thay đổi đều được ghi; khác biệt schema hiển thị phục vụ tuân thủ.
Đảm bảo chất lượng và các thước đo
Trong gán nhãn thủ công, cơ chế QA mạnh và thước đo chất lượng rõ ràng là thiết yếu. Các nhóm nên theo dõi:
1. Mức đồng thuận giữa người gán nhãn (Inter-annotator agreement, IAA)
- Là gì: Mức độ mà các người gán nhãn khác nhau đồng ý với nhau.
- Đo như thế nào: Dùng Krippendorff’s α cho dữ liệu danh nghĩa/thứ bậc/khoảng (bền vững với nhiều người gán nhãn và dữ liệu thiếu).
- Mục tiêu: α ≥ 0,80 cho tác vụ thị giác máy tính nói chung (≥ 0,85 cho y tế/an toàn trọng yếu).
- Hành động: Nếu α giảm, kích hoạt phiên hiệu chuẩn hoặc làm rõ hướng dẫn.
2. Tỷ lệ lỗi trên “golden set”
Duy trì một tập con được chuyên gia gán nhãn (“golden set”). Định kỳ lấy mẫu sản phẩm gán nhãn và tính phần trăm lệch so với nhãn chuẩn.
- Ngưỡng lỗi: Lỗi > 2% thì cần điều tra mệt mỏi, schema mơ hồ, hoặc “ma sát” do công cụ.
- Khắc phục: Đào tạo lại, tinh chỉnh cho miền, hoặc cập nhật hướng dẫn.
3. Thời gian gán nhãn mỗi ảnh (KPI thông lượng)
Theo dõi trung vị giây/ảnh (hoặc theo đối tượng) để lượng hóa ROI của tính năng hỗ trợ.
- So sánh trước–sau khi thêm phím tắt/template, tính phần trăm giảm để biện minh đầu tư.
- Dùng “giây mỗi bbox/polygon” như vi-thước đo để phát hiện nút thắt UI.
Chỉ số tùy chọn
- Độ trễ rà soát: Thời gian từ nhãn vòng 1 đến phê duyệt QA. Phần đuôi dài báo tắc nghẽn nhân lực rà soát hoặc xử lý.
- Kiểm tra trôi schema: Theo dõi tần suất lớp và thay đổi định nghĩa theo thời gian. Dịch chuyển đột ngột có thể do hiểu sai hướng dẫn hoặc do phân phối thực sự đổi.
Những thước đo QA này giúp duy trì chuẩn gán nhãn cao, quản trị năng suất, và tạo mốc định lượng cho cải tiến liên tục.
>>> Xem thêm:
- Hướng dẫn tạo app bằng Low Code đơn giản, hiệu quả nhất
- Cách sử dụng chatbot cho giáo dục đại học và học tập
- Hướng dẫn cách sử dụng Google AI Studio hiệu quả, nhanh chóng
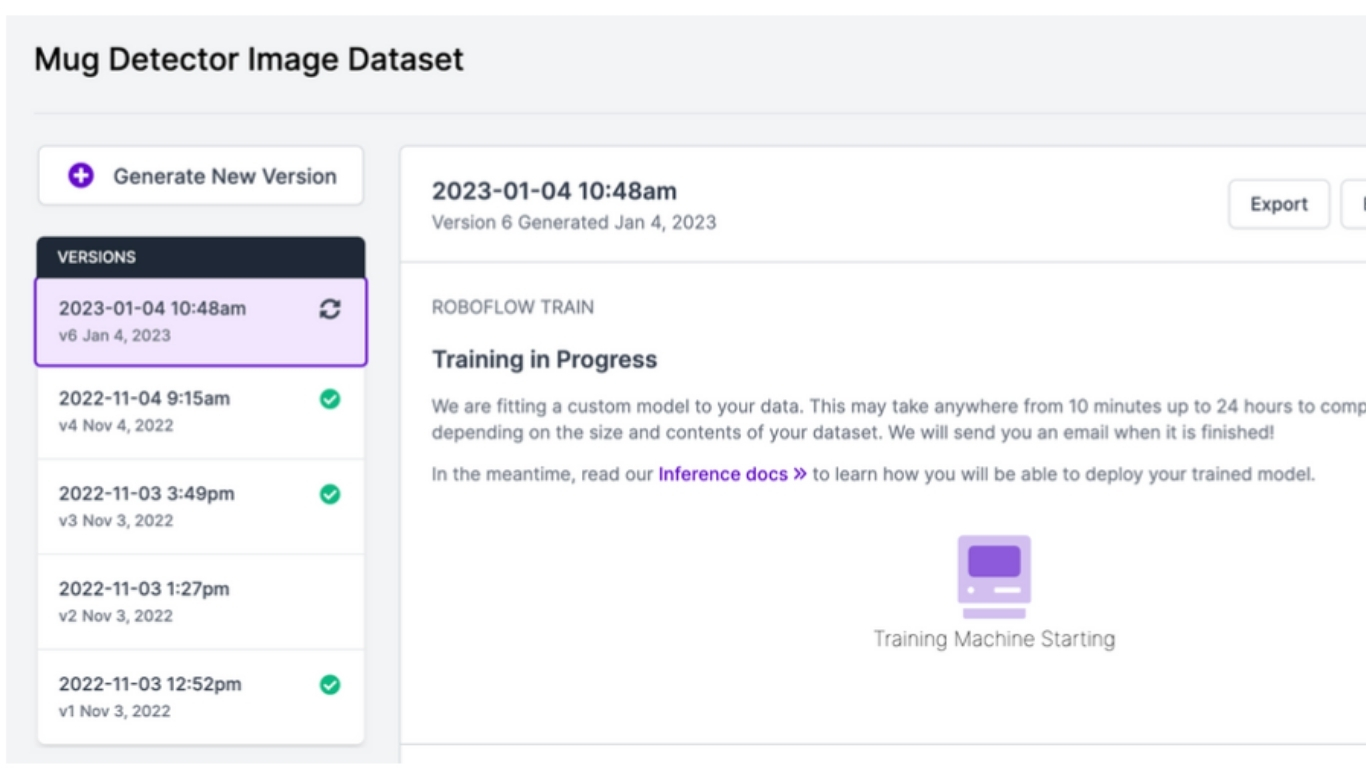
Quy trình 2: Gán nhãn bán tự động với SAM và CLIP + Active Learning
Gán nhãn bán tự động, hay “mô hình trong vòng lặp”, kết hợp chiến lược tốc độ của auto-label bằng AI với giám sát có mục tiêu từ con người. Quy trình này giảm đáng kể khối lượng gán nhãn thủ công (thường 3–5 lần) bằng cách dùng các mô hình nền tảng (SAM, CLIP) xử lý phần “thường lệ”, đồng thời dùng active learning để lôi ra các ca phức tạp cho chuyên gia rà soát.
Bạn “đổ tốc độ” ngay từ đầu (mask của SAM, bbox của detector, captioner) và chỉ dùng thời gian con người cho nơi mô hình không chắc chắn.
Label Assist của Roboflow trong thực tế
Label Assist của Roboflow dùng các mô hình nền tảng như SAM và Grounding-DINO (hoặc mô hình tùy chỉnh của bạn) để tạo nhanh các chú giải sơ bộ có độ chính xác tốt.
Sau đó, người gán nhãn tinh chỉnh các nhãn tự sinh này trong một phần nhỏ thời gian so với gán nhãn thủ công truyền thống. Label Assist chạy hàng loạt mask SAM, hiển thị điểm tin cậy, và đưa các mẫu “khó” vào hàng đợi thông qua Annotate.

Quy trình tổng quát theo từng bước:
- Tiền gán nhãn dựa mô hình: Chạy mô hình “mồi” (ví dụ: SAM cho mask, Grounding-DINO cho box) để tạo chú giải vòng 1.
- Lan truyền và nội suy nhãn: Với video/chuỗi ảnh, lan truyền chỉnh sửa sang khung kế cận; nội suy mask thay vì vẽ lại.
- Lấy mẫu theo độ tin cậy: Chỉ đưa ảnh “khó”/điểm tin cậy thấp cho con người; ảnh tin cậy cao chỉ cần kiểm tra điểm (spot check).
- Tinh chỉnh bằng thao tác click: Người gán nhãn chỉnh biên, gộp/tách instance chỉ bằng một cú click thay vì vẽ lại toàn bộ; chấp nhận/từ chối gợi ý trực tiếp.
Ví dụ: Trong phân tích nông nghiệp bằng drone, Roboflow tạo mask ban đầu cho ruộng hoặc vùng nhiễm sâu bệnh. Người gán nhãn chỉ cần sửa sai nhỏ bằng vài cú click, tăng mạnh thông lượng.
Vòng lặp Active Learning
Active learning cải thiện có hệ thống chất lượng tập dữ liệu và hiệu năng mô hình bằng cách lặp lại: xác định các điểm dữ liệu chưa gán nhãn “thông tin nhất” (thường là nơi mô hình kém chắc chắn nhất) và điều hướng sự chú ý của người gán nhãn đúng vào các ca trọng yếu. Tính năng Workflows của Roboflow hỗ trợ tích hợp quy trình này.
Cách active learning hoạt động (một chu trình lặp):
- Mô hình mồi: Huấn luyện trên tập con đã gán nhãn ban đầu.
- Dự đoán trên “pool” chưa gán nhãn: Chạy suy luận để lấy điểm số.
- Chấm điểm bất định và đa dạng:
- Bất định: entropy, margin sampling, hoặc phương sai dự đoán.
- Đa dạng: phân cụm dựa embedding (ví dụ CLIP) để tránh gán nhãn các mẫu gần trùng.
- Lai: lọc theo bất định trước, rồi tỉa để giữ tập con đa dạng.
- Chọn batch (2–5% của pool): Chỉ gửi các mẫu “thông tin nhất” cho con người (ví dụ top 2–5% vừa bất định vừa đa dạng).
- Con người tinh chỉnh và phê duyệt: Sửa lỗi mô hình; “khóa” nhãn chất lượng cao.
- Huấn luyện lại và đánh giá: Đo mức tăng mAP/IoU trên tập validation cố định.
- Lặp đến khi lợi ích bão hòa hoặc hết ngân sách: Ví dụ khi cải thiện < 0,5 mAP qua 2 chu kỳ.
KPI cho Active Learning
Các chỉ số giúp đo hiệu quả và tối ưu vòng lặp. Theo dõi theo từng vòng lặp (chu kỳ t so với t-1):
- Chênh lệch Precision/Recall giữa auto-label và nhãn người (Δ): Đo cải thiện so với tập validation ổn định sau mỗi chu kỳ để định lượng mức tăng; theo dõi hội tụ khi ΔPrecision, ΔRecall tiến về ~0.
- Mức tăng thông lượng gán nhãn: Số nhãn/giờ (ảnh/giờ hoặc mask/giờ) so với quy trình thuần thủ công. Kỳ vọng 3–5 lần hiệu quả.
- Đường cong mAP theo vòng lặp: Vẽ mAP (hoặc F1) theo chu kỳ; đánh dấu khi vượt ngưỡng chấp nhận; dự kiến lợi ích giảm dần nên cần tiêu chí dừng.
- Tỷ lệ “pool được gán nhãn” so với hiệu năng: Phần trăm các mẫu “bất định” được chọn thực sự chứa lỗi mô hình. KPI này phản ánh sampling có hiệu quả không (cho thấy bạn cần gán nhãn ít đến mức nào để đạt KPI sản xuất).
Rà soát KPI thường xuyên giúp nhìn rõ cải thiện năng suất và xác định khi active learning đi vào vùng lợi ích cận biên giảm dần.
>>> Xem thêm:
- Tạo web bán hàng bằng AI miễn phí, chuẩn SEO, hiệu quả nhất
- Low Code là gì? Giải pháp phát triển phần mềm và xu hướng tương lai
Quy trình 3: Pipeline tự động hoàn toàn và dữ liệu tổng hợp
Các pipeline tự động hoàn toàn và dữ liệu tổng hợp đem lại khả năng mở rộng tốt nhất, thời gian phản hồi nhanh, và không gian tùy biến rộng.
Khi bạn thiếu dữ liệu thật, các trường hợp biên cực hiếm, hoặc cần kiểm soát chặt yếu tố cảnh (ánh sáng, tư thế, che khuất, nền), pipeline “ưu tiên tổng hợp” có thể giảm mạnh thời gian từ lúc bắt đầu đến khi có mô hình đầu tiên, đồng thời tạo nhãn hoàn hảo. Tính linh hoạt này cũng rất phù hợp để bao phủ “đuôi dài” (long-tail) như lỗi hiếm, kịch bản lái xe nguy hiểm, và các ca y khoa hiếm gặp.
Dữ liệu tổng hợp có tiềm năng lớn, nhưng cũng có rủi ro, đặc biệt là “khoảng cách miền” và “trôi ngữ nghĩa”. Các nhóm làm tốt là các nhóm cân bằng đúng giữa tự động hóa và những điểm chèn QA có kế hoạch từ con người.
>>> Xem thêm: 18 cách ứng dụng AI cho ecommerce đạt hiệu quả cao
Tạo và thẩm định dữ liệu
Các chiến lược tạo dữ liệu tổng hợp đa dạng
Tổ chức ngày càng dùng các nền tảng tạo dữ liệu tổng hợp tiên tiến như Unity, Blender, NVIDIA Omniverse, và NeRF. Các nền tảng này mô phỏng kịch bản thực tế với biến thiên ánh sáng, vật liệu bề mặt, và góc camera, vốn thiết yếu cho huấn luyện AI bền vững.
Các cách tiếp cận phổ biến:
- Mô phỏng cảnh 3D: Tạo bản sao số của môi trường thực (kho, cửa hàng bán lẻ, đô thị).
- Ngẫu nhiên hóa miền: Ngẫu nhiên hóa texture, ánh sáng, nhiễu cảm biến, góc camera để tăng khả năng khái quát.
- Đồ thị cảnh lập trình: Kịch bản hóa vị trí đối tượng để đảm bảo cân bằng lớp và trường hợp biên.
- NeRF và 3D Gaussian splatting: Tái tạo cảnh từ dữ liệu thu thập thưa, rồi render góc nhìn mới để giám sát dày đặc.
- Tổng hợp video: Mô phỏng nhòe chuyển động, che khuất, và tính liên tục theo thời gian cho tác vụ tracking.
- Kết xuất dựa vật lý: Tạo ảnh tổng hợp hiện thực cao, quan trọng cho xe tự hành và ảnh y khoa.
Tự động gán nhãn “ground truth”
Một lợi thế quan trọng của dữ liệu tổng hợp là có thể tạo chú giải “đúng đến từng pixel” ngay trong phần mềm mô phỏng. Chú giải bao phủ bbox, polygon, mask phân đoạn, keypoint mà không cần can thiệp con người.
Các engine tổng hợp “phát” chú giải hoàn hảo theo cấu trúc dựng hình (bbox, polygon, mask, bản đồ độ sâu/depth maps, optical flow, keypoints) trực tiếp từ renderer. Do đó không cần người tạo nhãn; công việc chuyển sang kiểm chứng rằng các nhãn này “chuyển giao” tốt sang dữ liệu thật.
Mẹo: Xuất chú giải đúng lược đồ và định dạng bạn sẽ dùng ở hạ nguồn (COCO/YOLO/Pascal VOC) để tránh chuyển đổi gây mất mát và đẩy thẳng vào Roboflow cho huấn luyện & QA. Đồng thời phiên bản hóa cả cấu hình bộ sinh cảnh và nhãn xuất ra; xem renderer như “trình biên dịch dữ liệu” với các “bản build” tái lập.
Thẩm định bằng điểm tương đồng/độ trôi định lượng
- Lọc theo độ tương đồng embedding: Tính embedding ảnh (ví dụ CLIP ViT-L/14) cho dữ liệu tổng hợp so với tập validation dữ liệu thật; gắn cờ các mẫu nằm ngoài một phân vị đã tinh chỉnh (ví dụ < phân vị 5% về độ tương đồng).
- Thước đo khoảng cách miền:
- FID/KID giữa các phân phối đặc trưng (cho 2D).
- “Proxy” theo chỉ số hạ nguồn: huấn luyện mô hình proxy nhỏ trên tổng hợp, đánh giá trên tập validation thật nhỏ để ước lượng khoảng cách miền (ví dụ “mAP giảm 6,2 điểm”).
- LLM-Judge (tùy chọn/thực nghiệm):
- Dùng VLM (CLIP, GPT-4o-vision) kiểm tra căn chỉnh ngữ nghĩa giữa metadata cảnh (caption/prompt) và ảnh render.
- CLIPScore (tương đồng văn bản ↔ ảnh) có thể gắn cờ trôi ngữ nghĩa, nhưng cần đặt ngưỡng bằng thực nghiệm (ví dụ < phân vị 10% của phân phối dữ liệu thật thì chuyển sang người QA).
- Xem như heuristic để phân luồng, không phải trọng tài ground-truth.
Một workflow điển hình:
- Tạo dữ liệu tổng hợp (Unity/Blender).
- Tính CLIPScore: tính điểm tương đồng embedding giữa ảnh tạo và bộ dữ liệu thật tham chiếu.
- Gắn cờ ngoại lệ: tự động gắn thẻ ảnh có điểm thấp hơn ngưỡng định trước (ví dụ CLIPScore < 0,8) để con người rà soát, qua đó giảm rủi ro khi huấn luyện.
Khi nào cần chèn QA của con người?
Dù pipeline tổng hợp tự động giảm mạnh chi phí gán nhãn thủ công, thẩm định có mục tiêu từ con người vẫn thiết yếu, nhất là khi yêu cầu độ chính xác và tuân thủ cao. Sử dụng bảng quyết định dưới đây để xác định thời điểm can thiệp của con người là quan trọng.
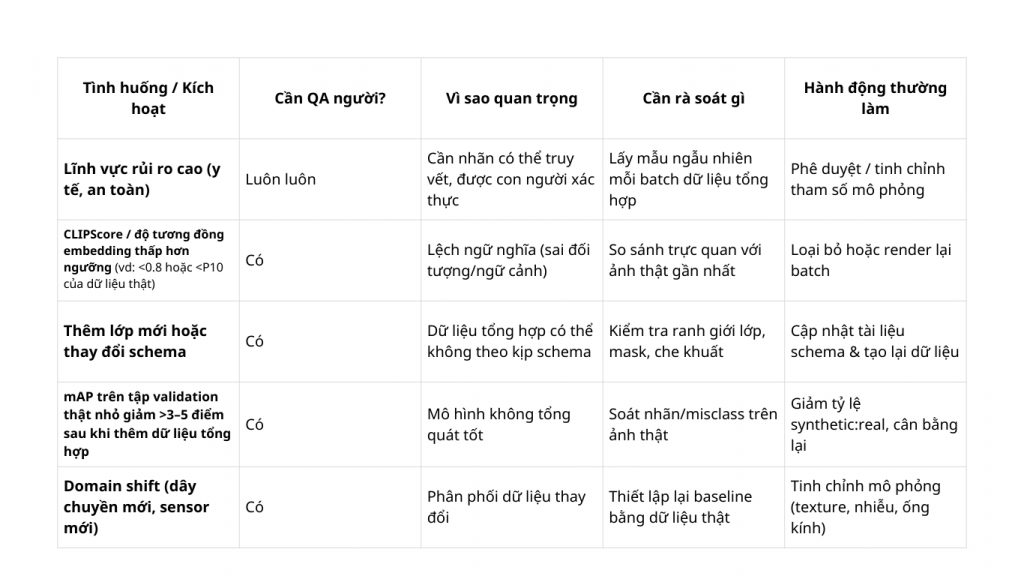
Quy tắc kinh nghiệm: Bắt đầu QA người cho 5–10% các lô tổng hợp. Nếu tỷ lệ chấp nhận > 98% trong 3 chu kỳ liên tiếp và mAP hạ nguồn trên dữ liệu thật ổn định, giảm xuống 1–2% kiểm tra điểm.
Chèn QA người một cách chiến lược tại các điểm kích hoạt này giúp đảm bảo tính toàn vẹn dữ liệu, sẵn sàng tuân thủ, và duy trì độ chính xác mô hình.
Pha trộn thực tiễn: Tổng hợp ↔ Thật
- Khởi động bằng seed dữ liệu thật nhỏ (500–2.000 ảnh) để hiệu chỉnh bộ sinh tổng hợp.
- Lịch tỷ lệ: Bắt đầu 70:30 tổng hợp:thật, rồi giảm dần về 50:50 (hoặc thấp hơn) khi mở rộng phản hồi dữ liệu thật.
- Huấn luyện có trọng số hoặc curriculum: Tăng trọng số loss cho mẫu thật hoặc huấn luyện theo giai đoạn (tiền huấn luyện trên tổng hợp → tinh chỉnh trên thật).
- Chuyển phong cách/thích nghi miền: Giảm “khoảng cách texture” (ví dụ AdaIN, CycleGAN) nếu độ hiện thực ảnh tổng hợp chưa đạt.
Các chỉ số và giám sát cần có
- Điểm khoảng cách miền: Chọn một chỉ số chính (ví dụ mức giảm mAP@0,5 trên tập validation thật, hoặc FID so với thật) và theo dõi theo vòng lặp.
- Điểm bao phủ/độ hiếm: Phần trăm kịch bản “đuôi dài” (lớp hiếm, tư thế cực đoan) được dữ liệu tổng hợp bao phủ.
- Tỷ lệ tổng hợp:thật theo thời gian: Ví dụ bắt đầu 80:20 → hội tụ 50:50 khi thu thập thêm phản hồi thật.
- Tỷ lệ “trúng” QA: Phần trăm mẫu tổng hợp không đạt kiểm tra của người; kỳ vọng giảm dần khi pipeline mô phỏng trưởng thành.
- Trôi nhãn sau triển khai: So sánh phân phối embedding của các mẫu sản xuất mới (được người gán nhãn) so với tập huấn luyện ban đầu.

Công cụ gán nhãn dữ liệu AI
Không phải mọi nền tảng gán nhãn đều giống nhau. Nếu bạn cần quản trị, khả năng kiểm toán, và tốc độ, nền tảng end-to-end của Roboflow (kèm Label Assist + bảng điều khiển QA) sẽ rút ngắn “thời gian đến giá trị” nhiều nhất.
Roboflow Annotate nổi bật như một trong các công cụ gán nhãn ảnh có hỗ trợ AI mạnh nhất. Nó cho phép người dùng tự vẽ bbox hoặc polygon, hoặc tăng hiệu suất bằng Label Assist (áp dụng checkpoint mô hình của chính bạn để tiền gán nhãn tự động). Với các tác vụ phân đoạn cần độ chính xác cao hơn, Roboflow cung cấp Smart Polygon, khai thác Segment Anything Model (SAM 2) của Meta để tạo chú giải “sạch” chỉ trong vài cú click.
Bên cạnh các công cụ chú giải thông minh, nền tảng còn có đầy đủ tính năng quản lý dữ liệu: tìm kiếm ngữ nghĩa, lọc lớp, phân tích tự động để tìm ca biên, và cộng tác theo vai trò với quy trình giao việc, hàng đợi phê duyệt, và lịch sử phiên bản. Nền tảng được xây để vận hành quy mô thực tế: xử lý hàng triệu ảnh qua nhiều nhóm mà vẫn giữ nhãn chính xác, hiệu quả, và có thể kiểm toán.
Kết luận về gán nhãn dữ liệu AI
Nhãn chất lượng cao vẫn là “đòn bẩy” đáng tin cậy nhất cho độ chính xác khi triển khai, tuân thủ, và tốc độ lặp cải tiến, ngay cả trong kỷ nguyên mô hình nền tảng, SAM, và dữ liệu tổng hợp.
Chiến lược thắng không phải là “thủ công hay tự động”, mà là điều phối đúng tổ hợp giữa: Manual + Assist, Model-in-the-Loop với active learning, và Synthetic-first, kèm các cổng chất lượng đo được và quản trị có thể kiểm toán.
Nếu bạn triển khai “playbook 10 bước” nêu trên, bạn có thể kỳ vọng:
- Giảm chi phí gán nhãn khoảng 20–40%,
- Tăng mAP thêm +2 đến +5 điểm nhờ active learning và vòng QA,
- Rút ngắn chu kỳ lặp bằng cách tự động hóa phần máy làm tốt nhất và dành con người cho những phần thực sự quan trọng.
Nguồn tham khảo: AI Data Labeling Guide – Roboflow
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Hoàng Diệu, Phường 12, Quận 4, Thành phố Hồ Chí Minh, Việt Nam