
Các mô hình ngôn ngữ lớn (Large Language Models – LLMs) như GPT-4o, Google Gemini và Anthropic Claude đã phát triển vượt xa khả năng xử lý văn bản đơn thuần. Những mô hình này hiện là đa phương thức, có khả năng hiểu và tích hợp nhiều loại đầu vào khác nhau, bao gồm hình ảnh và video cùng với văn bản. Khả năng này cho phép chúng giải quyết nhiều bài toán thị giác máy tính như phát hiện đối tượng, nhận dạng văn bản và trả lời câu hỏi về hình ảnh. Bài viết này sẽ hướng dẫn bạn cách tạo prompt cho LLM trong thị giác máy tính một cách hiệu quả để giải quyết các tác vụ thị giác máy tính bằng các Mô hình Đa phương thức Lớn (Large Multimodal Models – LMMs)
>>> Xem thêm các bài viết:
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
- Tối ưu website bằng AI là gì? Cách tối ưu SEO và các công cụ AI
- Cách sử dụng AI trong phát triển phần mềm như thế nào?
- Cách ứng dụng AI tối ưu trải nghiệm khách hàng
- Hướng dẫn cách sử dụng Google AI Studio hiệu quả, nhanh chóng
Khả năng của LLM trong thị giác máy tính
- Phát hiện đối tượng và vị trí của chúng trong hình ảnh
- Trích xuất văn bản từ hình ảnh bằng OCR (Optical Character Recognition)
- Trả lời câu hỏi về nội dung hình ảnh thông qua Visual Question Answering (VQA)
- Hiểu ngữ cảnh và phân tích thông tin trong hình ảnh
- Tạo mô tả chi tiết hoặc tóm tắt cho hình ảnh
- Tích hợp thông tin văn bản và hình ảnh cho suy luận phức tạp
Mô hình đa phương thức lớn: Google Gemini
Trong bài viết này, chúng ta sẽ sử dụng Google Gemini để minh họa kỹ thuật tạo prompt cho LLM trong thị giác máy tính.
Google Gemini là một nhóm các mô hình đa phương thức lớn (LMM) được phát triển bởi Google DeepMind, được thiết kế đặc biệt cho tính đa phương thức. Gemini bao gồm các phiên bản như Gemini 2.5 Pro, Gemini 2.5 Flash, Gemini 2.5 Flash-Lite, mỗi phiên bản được tối ưu cho các trường hợp sử dụng khác nhau.
Các mô hình Gemini miễn phí sử dụng nhưng yêu cầu API key, bạn có thể dễ dàng lấy miễn phí từ Google AI Studio.
Truy cập và tích hợp Google Gemini qua API
Đoạn code dưới đây mô tả cách truy cập mô hình Google Gemini thông qua API với một hình ảnh ví dụ:
import requests
import base64
import json
def gemini_inference(image, prompt, model_id, temperature, api_key):
"""
Perform Gemini inference using Google Gemini API with text + image input.
"""
API_URL = f"https://generativelanguage.googleapis.com/v1beta/models/{model_id}:generateContent?key={api_key}"
payload = {
"contents": [
{
"role": "user",
"parts": [
{"text": prompt},
{"inlineData": {"mimeType": "image/jpeg", "data": image}},
],
}
],
"generationConfig": {"temperature": temperature}
}
headers = {"Content-Type": "application/json"}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
return result["candidates"][0]["content"]["parts"][0]["text"]
if __name__ == "__main__":
# Encode image to base64 in one line
base64_image = base64.b64encode(open("test.jpg", "rb").read()).decode("utf-8")
# Run inference
output = gemini_inference(
base64_image,
prompt="Count the number of objects in the image.",
model_id="gemini-2.5-flash", # Gemini variant
temperature=0.0,
api_key="YOUR_GEMINI_API_KEY"
)
print(output)Ảnh ví dụ dùng trong đoạn code trên như sau:

Kết quả đầu ra được tạo bởi đoạn code trên, sử dụng prompt “Count the number of objects in the image” sẽ như sau:
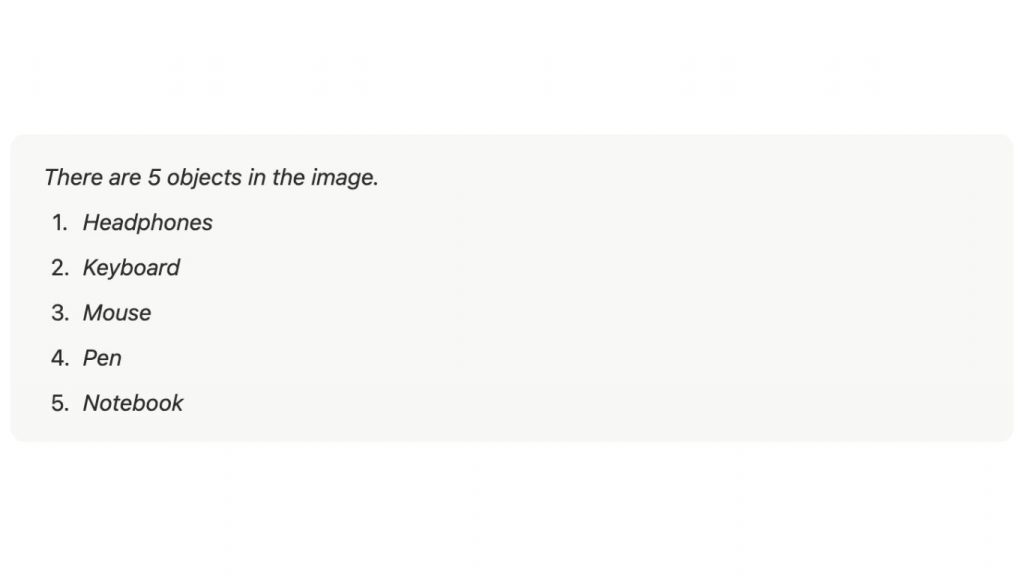
>> Xem thêm:
- AI nhận diện ảnh là gì? Thuật toán và ứng dụng phổ biến
- Học Máy Là Gì Và Tại Sao Học Máy Lại Quan Trọng?
- TOP 10 AI thiết kế website miễn phí, trả phí, hiệu quả năm 2026
Tận dụng Google Gemini trong Roboflow Workflows
Google Gemini có sẵn dưới dạng block tích hợp trong Roboflow Workflows. Roboflow Workflows là một nền tảng no-code dựa trên web để xây dựng chuỗi các tác vụ thị giác máy tính như phát hiện đối tượng, cắt xén động và trực quan hóa bounding box, với mỗi tác vụ được biểu diễn dưới dạng một block riêng lẻ.
Để bắt đầu, hãy tạo một tài khoản Roboflow miễn phí và đăng nhập. Tiếp theo, tạo một workspace, sau đó nhấp vào “Workflows” trong thanh bên trái và nhấp vào Create Workflow.
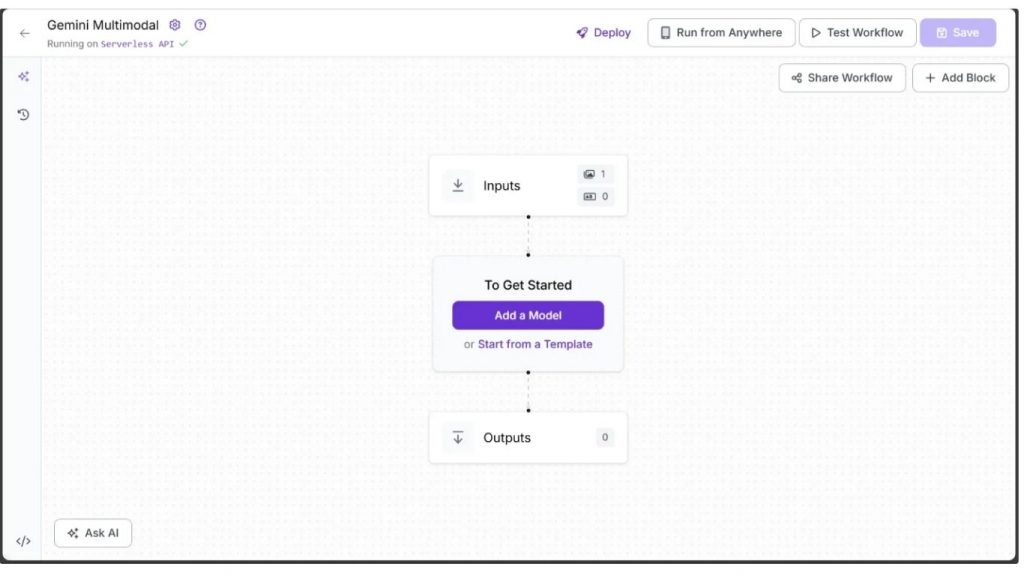
Bạn sẽ được đưa đến trình chỉnh sửa workflow trống, sẵn sàng để bạn xây dựng workflow hỗ trợ AI của mình. Tại đây, bạn sẽ thấy hai block workflow: Inputs và Outputs, như hình dưới đây:
Để thêm Google Gemini vào workflow của bạn, hãy nhấp ‘Add a Model’, tìm kiếm ‘Google Gemini’, chọn và nhấp ‘Add Model’ để chèn block vào workflow của bạn, như hình dưới đây:
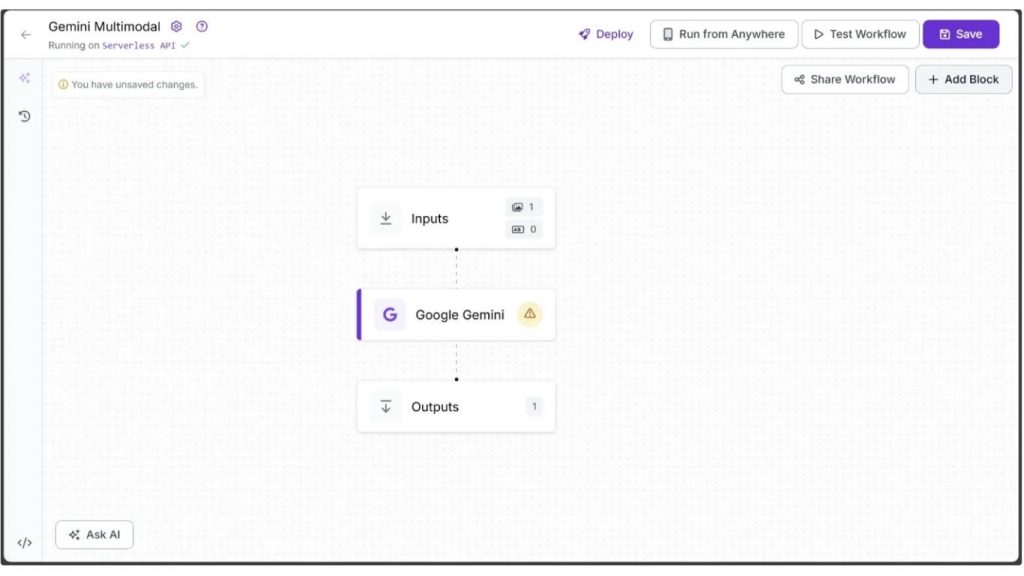
Bây giờ hãy cập nhật ‘API Key’ bằng khóa của bạn trong tab Configure, có thể truy cập bằng cách nhấp vào block ‘Google Gemini’ trong workflow.
Bên cạnh ‘API Key’, tab cấu hình bao gồm các tham số như temperature, phiên bản model và max tokens, tất cả đều có thể dễ dàng điều chỉnh thông qua giao diện Roboflow Workflow UI.
Bây giờ bạn có thể chạy workflow như dưới đây:
Cách tạo prompt cho LLM để thực hiện các tác vụ thị giác máy tính
Dưới đây là các chiến lược thực tế để tạo prompt hiệu quả, giúp bạn cải thiện độ chính xác và giảm thiểu ảo giác:
Cung cấp thông tin ngữ cảnh cụ thể
Ngữ cảnh giúp LLM nắm bắt ý định của người dùng và tạo ra kết quả chính xác hơn. Việc cung cấp thông tin chi tiết về tình huống hoặc bối cảnh cho phép mô hình tạo ra các dự đoán phù hợp và chính xác hơn.
Sự khác biệt được minh họa dưới đây, trong đó hai prompts khác nhau được áp dụng cho cùng một hình ảnh:

Prompt không có ngữ cảnh
Prompt dưới đây không cung cấp chi tiết về ngữ cảnh mà mô tả nên được tạo ra.
Give me a description of the image.Đầu ra của prompt không có ngữ cảnh
Kết quả dưới đây dựa trên prompt thiếu ngữ cảnh ở trên, cung cấp một mô tả chung chung về hình ảnh mà không nhấn mạnh bất kỳ mục đích hoặc đối tượng cụ thể nào. Chỉ liệt kê các đối tượng và chi tiết một cách đơn thuần nhưng không làm nổi bật những đặc điểm giúp hình ảnh trở nên hấp dẫn cho một ngữ cảnh cụ thể.

Prompt có ngữ cảnh
Prompt bên dưới cung cấp ngữ cảnh cụ thể cho mô tả, hướng dẫn mô hình tập trung vào những yếu tố quan trọng như diện tích, ánh sáng, phong cách thiết kế và độ thoải mái, phù hợp cho một danh mục bất động sản
Describe the image for a real estate catalog that highlights its best features such as space, lighting, style, and comfort etc.Đầu ra của prompt có ngữ cảnh
Kết quả này dựa trên prompt có ngữ cảnh ở trên, được điều chỉnh phù hợp với ngữ cảnh đã cung cấp. Kết quả nhấn mạnh các đặc điểm như không gian, ánh sáng, phong cách và sự thoải mái, sử dụng ngôn ngữ thuyết phục và hấp dẫn phù hợp cho một danh mục bất động sản, thay vì chỉ liệt kê các đối tượng trong hình ảnh.

>> Xem thêm:
- AI Data Labeling: Hướng dẫn gán nhãn dữ Liệu AI
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
Hướng dẫn hệ thống (System Instructions)
Thay vì bao gồm tất cả thông tin ngữ cảnh trong một prompt duy nhất, bạn có thể sử dụng System Instructions để cung cấp ngữ cảnh bổ sung cùng với prompt chính của bạn.
Bằng cách tách hướng dẫn thành instruction riêng của nó, system instructions đơn giản hóa prompt chính trong khi vẫn định hướng các đầu ra hiệu quả hơn. Ví dụ, payload dưới đây cho Gemini Inference minh họa điều này:
payload = {
"systemInstruction": {
"role": "system",
"parts": [
{"text": "You are a professional real estate copywriter. Always describe spaces in a way that highlights their value, comfort, and uniqueness. Use engaging, persuasive, yet natural language that helps potential buyers envision themselves in the home"}
]
},
"contents": [
{
"role": "user",
"parts": [
{"text": "Give me a description of the image."},
{"inlineData": {"mimeType": "image/jpeg", "data": image}},
],
}
],
"generationConfig": {"temperature": temperature}
}Tận dụng các ví dụ
Việc thêm các ví dụ vào prompt giúp LLM hiểu rõ câu trả lời đúng trông như thế nào. Few-shot prompts cung cấp nhiều ví dụ, trong khi zero-shot prompts không cung cấp ví dụ nào. Các ví dụ được chọn tốt giúp hướng dẫn định dạng, cách diễn đạt và phạm vi của mô hình, nâng cao cả độ chính xác và chất lượng của các đầu ra.
Sự khác biệt được minh họa dưới đây, trong đó hai prompts khác nhau được áp dụng cho cùng một hình ảnh:

Zero-shot prompt
Prompt dưới đây không cung cấp ví dụ nào để mô hình làm theo, hoàn toàn dựa vào hiểu biết chung của nó về mô tả hình ảnh:
Give me a description of the scene in the image.Đầu ra của zero-shot prompt
Đầu ra này, dựa trên Zero-Shot Prompt ở trên, cung cấp mô tả tổng quát về khung cảnh mà không có hướng dẫn cụ thể. Kết quả này nắm bắt được bối cảnh tổng thể và tâm trạng nhưng có thể thiếu các gợi ý phong cách hoặc định dạng cụ thể.

Few-shot prompt
Prompt dưới đây cung cấp các ví dụ cụ thể để hướng dẫn mô hình, minh họa cách cấu trúc mô tả, bao gồm bối cảnh, ánh sáng, góc nhìn camera và tâm trạng:
Give me a description of the scene in the image. Consider these examples:
Example 1 – Rainy Alley Setting: Narrow city alley at night. Lighting: Flickering neon signs, wet reflections. Camera: Low-angle tracking shot. Mood: Tense, mysterious.
Example 2 – Morning Beach Setting: Empty beach at sunrise. Lighting: Soft, warm sunlight; gentle highlights on waves. Camera: Wide shot, slow pan along shoreline. Mood: Calm, serene.Đầu ra của few-shot prompt
Đầu ra này, dựa trên Few-Shot Prompt ở trên, có cấu trúc và chi tiết hơn. Few-shot prompt truyền đạt cấu trúc và các gợi ý phong cách trong đầu ra mà không cần phải nêu rõ chúng trong prompt.

Phương pháp tốt nhất để tận dụng prompts với ví dụ
- Sử dụng các ví dụ minh họa cho mô hình thấy hành vi bạn mong muốn. Điều này thường rõ ràng hơn và dẫn đến kết quả tốt hơn.
- Tránh sử dụng các ví dụ minh họa cho mô hình những điều cần tránh. Có thể gây nhầm lẫn và đôi khi phản tác dụng.
- Giữ các ví dụ trong few-shot prompts đồng nhất, đặc biệt về XML tags, khoảng trắng, dòng mới và dấu phân cách.
>>> Xem thêm:
- Cách sử dụng chatbot cho giáo dục đại học và học tập
- Tạo web bán hàng bằng AI miễn phí, chuẩn SEO, hiệu quả nhất
Sử dụng Structured Output (Đầu ra có cấu trúc)
Hầu hết các LLM đều hỗ trợ Function Calling, đảm bảo các phản hồi JSON nhất quán với tất cả các khóa bắt buộc. Nó thực thi một định dạng có cấu trúc, bảo toàn các kiểu dữ liệu và cho phép các prompt mô tả cho mỗi khóa để nắm bắt lý luận chi tiết, đảm bảo trích xuất insights đáng tin cậy từ hình ảnh.
Đoạn code dưới đây minh họa Function Calling trong Gemini, với phần lớn prompting xảy ra trong function_declarations.
import requests
import base64
import json
def gemini_inference(image, prompt, model_id, temperature, api_key, function_declarations):
"""
Perform Gemini inference using Google Gemini API with text + image input.
Uses function calling with a provided schema.
"""
API_URL = f"https://generativelanguage.googleapis.com/v1beta/models/{model_id}:generateContent?key={api_key}"
payload = {
"contents": [
{
"role": "user",
"parts": [
{"text": prompt},
{"inlineData": {"mimeType": "image/jpeg", "data": image}},
],
}
],
"generationConfig": {"temperature": temperature},
"tools": [{"functionDeclarations": function_declarations}],
}
headers = {"Content-Type": "application/json"}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
fn_call = result["candidates"][0]["content"]["parts"][0]["functionCall"]
return fn_call["args"]
if __name__ == "__main__":
# Encode image to base64
base64_image = base64.b64encode(open("test.jpg", "rb").read()).decode("utf-8")
# Define function schema with descriptions
function_declarations = [
{
"name": "list_objects",
"description": "Identify objects present in the given image.",
"parameters": {
"type": "object",
"properties": {
"objects": {
"type": "array",
"description": "A list of objects detected in the image.",
"items": {
"type": "object",
"properties": {
"label": {
"type": "string",
"description": "The name of the detected object."
}
},
"required": ["label"],
"description": "Details about a single object detected in the image."
}
}
},
"required": ["objects"],
"description": "The structured output containing all detected objects."
}
}
]
# Run inference
output = gemini_inference(
base64_image,
prompt="Identify the objects in the image.",
model_id="gemini-2.5-flash",
temperature=0.0,
api_key="YOUR_GEMINI_API_KEY",
function_declarations=function_declarations,
)
print(json.dumps(output, indent=2))Đầu ra của đoạn code cho prompt “Identify the objects in the image” trong hình ảnh văn phòng phẩm được cung cấp trước đó là:
{
"objects": [
{
"label": "headphones"
},
{
"label": "keyboard"
},
{
"label": "mouse"
},
{
"label": "pen"
},
{
"label": "notebook"
}
]
}Bạn có thể sử dụng khả năng Function Calling trong Roboflow Workflows với block Google Gemini mà không cần viết bất kỳ mã nào bằng cách đặt Task Type thành ‘Structured Output Generation’ và cung cấp cấu trúc đầu ra bên dưới, sử dụng cùng các function declarations từ đoạn code trước đó dưới dạng một chuỗi thô.
{
"output_schema": "{\"name\":\"list_objects\",\"description\":\"Identify objects present in the given image.\",\"parameters\":{\"type\":\"object\",\"properties\":{\"objects\":{\"type\":\"array\",\"description\":\"A list of objects detected in the image.\",\"items\":{\"type\":\"object\",\"properties\":{\"label\":{\"type\":\"string\",\"description\":\"The name of the detected object.\"}},\"required\":[\"label\"],\"description\":\"Details about a single object detected in the image.\"}}},\"required\":[\"objects\"],\"description\":\"The structured output containing all detected objects.\"}}"
}Video workflow dưới đây minh họa điều này:
>> Xem thêm:
- Các nhiệm vụ chính của thị giác máy tính
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Hướng dẫn triển khai AI trong ứng dụng di động đơn giản
Kỹ thuật phát hiện đối tượng đúng cách
LMMs có thể thực hiện phát hiện đối tượng zero-shot, xác định một hoặc nhiều lớp đồng thời mà không cần bất kỳ fine-tuning nào, chỉ sử dụng prompts. Chúng thậm chí có thể suy luận về việc liệu một đối tượng có nên được phát hiện hay không.
Khi thực hiện phát hiện đối tượng với Gemini, luôn bao gồm hướng dẫn: “Return just box_2d, label and no additional text.” trong prompt của bạn. Để có kết quả tốt nhất, tránh sử dụng khả năng Function Calling của Gemini cho phát hiện đối tượng và thay vào đó dựa vào khả năng tạo văn bản của nó.
Ngoài ra, các tọa độ bounding box được tạo ra cần được chuẩn hóa trước khi sử dụng. Đoạn code dưới đây minh họa chức năng này sử dụng mô hình Gemini:
# Ensure OpenCV is installed before running this script:
# You can install it via: pip install opencv-python-headless
import requests
import json
import base64
import cv2
def clean(results):
"""
Clean the raw JSON output from the Gemini API.
"""
return results.strip().removeprefix("```json").removesuffix("```").strip()
def gemini_inference(image, prompt, model_id, temperature, api_key):
"""
Perform object detection using Google Gemini API.
"""
# Fixed, plotting function depends on this.
bounding_box_prompt = "Return just box_2d, label and no additional text."
API_URL = f"https://generativelanguage.googleapis.com/v1beta/models/{model_id}:generateContent?key={api_key}"
payload = {
"contents": [
{
"role": "user",
"parts": [
{"text": prompt + bounding_box_prompt},
{"inlineData": {"mimeType": "image/jpeg", "data": image}},
],
}
],
"generationConfig": {"temperature": temperature}
}
headers = {"Content-Type": "application/json"}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
return result["candidates"][0]["content"]["parts"][0]["text"]
if __name__ == "__main__":
# Encode image to base64
image = "test.jpg"
with open(image, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
# Run inference
output = gemini_inference(
base64_image,
prompt="Detect only the analog objects in the image with correct labels.",
model_id="gemini-2.5-flash",
temperature=0.0,
api_key="YOUR_GEMINI_API_KEY"
)
boxes = json.loads(clean(output))
print(boxes)
# Load image with OpenCV
image_cv2 = cv2.imread(image)
h, w, _ = image_cv2.shape
for item in boxes:
# Gemini model returns [y1, x1, y2, x2] normalized to 0-1000
y1, x1, y2, x2 = item["box_2d"]
y1 = int(y1 / 1000 * h)
x1 = int(x1 / 1000 * w)
y2 = int(y2 / 1000 * h)
x2 = int(x2 / 1000 * w)
# Draw green rectangle
rectangle_thickness = 16
cv2.rectangle(image_cv2, (x1, y1), (x2, y2), (0, 255, 0), thickness=rectangle_thickness)
# Draw text directly
text = item["label"]
font_scale = 3
font_thickness = 6
cv2.putText(image_cv2, text, (x1, max(0, y1 - 4)), cv2.FONT_HERSHEY_SIMPLEX, font_scale, (255, 0, 0), font_thickness)
# Save and display annotated image_cv2
cv2.imwrite("annotated_image.jpg", image_cv2)Bạn cũng có thể tích hợp đoạn code trên vào Roboflow workflows bằng cách sử dụng các block Custom Python code. Đầu ra của đoạn code cho prompt “Detect only the analog objects in the image with correct labels” là:

Chia prompts phức tạp thành các tác vụ nhỏ hơn
Trong một số trường hợp khi suy luận trên các tác vụ hình ảnh phức tạp thì bạn có thể chia nó thành nhiều bước hơn để làm cho nó dễ quản lý hơn.
Ví dụ, để thực hiện một tác vụ OCR trên hình ảnh dưới đây:

Với prompt, “List all the contents of the shelf labels in the image,” đầu ra dưới đây đã được tạo ra:
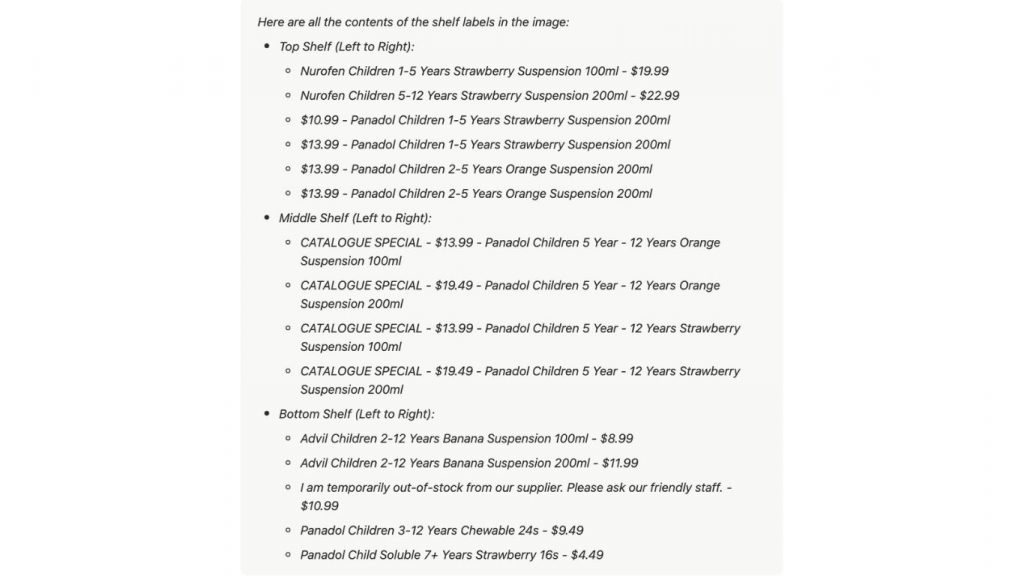
Trong đầu ra trên, có thể quan sát thấy nhiều lỗi và hiện tượng bất thường trong tên sản phẩm. OCR đã tạo ra kết quả không chính xác, chẳng hạn như giá trị mililít không chính xác, và một số từ trong tên sản phẩm đầy đủ đã bị bỏ sót.
Để giải quyết vấn đề này, thay vì tạo một prompt dài chi tiết mọi hướng dẫn và ngoại lệ, có thể dẫn đến ảo giác và kết quả không nhất quán giữa các hình ảnh, hiệu quả hơn là đầu tiên thực hiện phát hiện đối tượng trên các nhãn kệ để xác định bounding boxes của chúng, và sau đó sử dụng các bounding boxes này để cắt các hình ảnh nhãn kệ, như hình dưới đây:

Các hình ảnh đã cắt sau đó có thể được xử lý trước để nâng cao chất lượng của chúng và xử lý riêng lẻ với một LMM cho OCR. Cách tiếp cận này cải thiện đáng kể độ chính xác của OCR và độ tin cậy tổng thể.
Tận dụng grounding search để giảm ảo giác
Grounding search trong Google Gemini cải thiện thị giác máy tính bằng cách liên kết những gì mô hình nhìn thấy trong một hình ảnh với kiến thức thế giới thực từ Google Search, đảm bảo nhận dạng chính xác, cập nhật và đáng tin cậy hơn trong khi giảm ảo giác.
Ví dụ, xem xét hình ảnh:

Trong hình ảnh này, chúng ta có thể sử dụng suy luận Gemini để phát hiện thương hiệu điện thoại và áp dụng grounding search để truy xuất giá mới nhất cho thương hiệu đó.
Prompt chúng ta sẽ sử dụng là: “Identify the image and retrieve real-time prices from the web with sources.” Đoạn mã dưới đây minh họa cách sử dụng prompt này với grounding search cho suy luận Gemini.
import requests
import base64
import json
def gemini_inference(image, prompt, model_id, temperature, api_key):
"""
Perform Gemini inference using Google Gemini API with text + image input,
and apply grounding search (Google Search Retrieval).
"""
API_URL = f"https://generativelanguage.googleapis.com/v1beta/models/{model_id}:generateContent?key={api_key}"
payload = {
"contents": [
{
"role": "user",
"parts": [
{"text": prompt},
{"inlineData": {"mimeType": "image/jpeg", "data": image}},
],
}
],
"generationConfig": {"temperature": temperature},
"tools": [
{
"google_search": {} # Enable grounding search
}
]
}
headers = {"Content-Type": "application/json"}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
return result["candidates"][0]["content"]["parts"][0]["text"]
if __name__ == "__main__":
# Encode image to base64
base64_image = base64.b64encode(open("phone.webp", "rb").read()).decode("utf-8")
# Run inference with grounding search
output = gemini_inference(
base64_image,
prompt="Identify the image and get me real-time prices from the web with sources.",
model_id="gemini-2.5-flash", # Gemini variant
temperature=1,
api_key="YOUR_GEMINI_API_KEY"
)
print(output)Đầu ra của đoạn code trên sẽ tương tự như sau:

>> Xem thêm:
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất 2025
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
Thử nghiệm với các tham số
LMM như Google Gemini cung cấp nhiều tham số có thể được sử dụng cùng với một prompt để tinh chỉnh các đầu ra. Các tham số này bao gồm:
- Thinking Budget: Ngân sách suy nghĩ thiết lập số lượng tokens mô hình có thể sử dụng để suy luận. Các giá trị cao hơn cho phép các phản hồi chi tiết hơn, trong khi các giá trị thấp hơn làm giảm độ trễ. Đặt nó thành 0 vô hiệu hóa suy nghĩ, và -1 cho phép điều chỉnh động dựa trên độ phức tạp của yêu cầu.
- Temperature: Temperature kiểm soát tính ngẫu nhiên của việc chọn token trong quá trình lấy mẫu. Các giá trị thấp hơn làm cho các phản hồi xác định hơn, trong khi các giá trị cao hơn tăng tính đa dạng và sáng tạo. Một temperature là 0 luôn chọn phản hồi có xác suất cao nhất.
- Top P: topP chọn các tokens có xác suất tích lũy đạt giá trị topP. Ví dụ, với topP=0.5, chỉ các tokens đóng góp 50% xác suất được xem xét, và temperature xác định lựa chọn cuối cùng.
- Top K: topK giới hạn việc chọn token đến K tùy chọn có xác suất cao nhất. Ví dụ, topK=1 chọn token duy nhất có khả năng cao nhất (greedy decoding), trong khi topK=3 lấy mẫu từ 3 tokens hàng đầu, với temperature và topP được áp dụng cho lựa chọn cuối cùng.
- Stop Sequences: Định nghĩa các chuỗi ký tự làm cho mô hình ngừng tạo. Tránh sử dụng các chuỗi có khả năng xuất hiện trong đầu ra.
- Max Output Tokens: Chỉ định số lượng tokens tối đa có thể được tạo trong phản hồi. Một token xấp xỉ bốn ký tự. 100 tokens tương ứng với khoảng 60-80 từ.
Dưới đây là từ điển generationConfig, cho thấy cách các tham số trên có thể được sử dụng với Gemini Inference bên trong payload:
"generationConfig": {
"temperature": 0,
"topK": 5,
"topP": 0.9,
"maxOutputTokens": 8000,
"stopSequences": ["<THE END>"], # The LLM stops generating when this sequence appears.
"thinkingConfig": {
"thinkingBudget": -1 # Dynamic thinking enabled
}
}Kết luận về mẹo tạo prompt cho LLMs có khả năng thị giác
Các mô hình đa phương thức lớn như Google Gemini đã biến đổi thị giác máy tính bằng cách tích hợp hiểu biết về văn bản và hình ảnh. Bằng cách cẩn thận cấu trúc prompts, tận dụng các gợi ý ngữ cảnh và ví dụ, và sử dụng các đầu ra có cấu trúc hoặc grounding search, bạn có thể cải thiện đáng kể độ chính xác trong các tác vụ như phát hiện đối tượng, OCR và trả lời câu hỏi về hình ảnh.
Ngoài ra, Roboflow Workflows cung cấp một giao diện no-code với nhiều blocks mô hình đa phương thức, bao gồm các tùy chọn closed-source như Google Gemini và GPT-4, cũng như các mô hình open-source như CogVLM, LLaVA-1.5 và PHI-4, giúp dễ dàng phát triển nhanh chóng các ứng dụng thị giác máy tính.
Nguồn tham khảo: Prompting Tips for Large Language Models with Vision Capabilities
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam







