
Phrase Grounding, còn được gọi là visual grounding hoặc referring expressions, là một nhiệm vụ tại giao điểm giữa thị giác máy tính và xử lý ngôn ngữ tự nhiên (NLP). Nó liên quan đến việc kết nối các cụm từ hoặc biểu thức cụ thể trong một mô tả văn bản với các vùng tương ứng trong hình ảnh. Trong bài viết dưới đây, chúng ta sẽ tìm hiểu về Phrase Grounding là gì và cách hoạt động của nó, dựa trên một số mô hình tiên tiến trong lĩnh vực này.
>> Xem thêm các bài viết:
- Trí tuệ nhân tạo (AI) là gì? Hiểu đúng về khái niệm & ứng dụng
- AI tạo sinh là gì? Cách hoạt động và Ứng dụng thực tế
- Thiết kế website bằng AI (trí tuệ nhân tạo) miễn phí
- Predictive AI là gì? Lợi ích và cách AI dự đoán hoạt động
- Hướng dẫn tạo app bằng Low Code đơn giản, hiệu quả nhất
Phrase Grounding là gì?
Phrase Grounding là một quá trình trong xử lý ngôn ngữ tự nhiên và thị giác máy tính, trong đó các từ hoặc cụm từ cụ thể trong một câu được kết nối với các vùng tương ứng trong hình ảnh. Nhiệm vụ này liên quan đến việc xác định vị trí không gian hoặc hộp giới hạn trong hình ảnh phù hợp với ý nghĩa của một cụm từ cho trước, cho phép các mô hình kết nối dữ liệu hình ảnh và văn bản.
Phrase Grounding cho phép máy móc hiểu và liên kết ngôn ngữ với nội dung hình ảnh ở mức độ chi tiết, tạo điều kiện cho việc tích hợp sâu hơn giữa các phương thức thị giác và ngôn ngữ. Mục tiêu của Phrase Grounding là hiểu và ánh xạ phần nào của hình ảnh đang được đề cập bởi các cụm từ cụ thể trong mô tả văn bản.
Phrase Grounding hữu ích cho nhiều nhiệm vụ hiểu hình ảnh và đa phương thức như Trả lời Câu hỏi Hình ảnh (VQA), Tạo Chú thích Hình ảnh, Tương tác Người-Máy (HCI), Tìm kiếm Hình ảnh, Nhận dạng Biểu thức Tham chiếu và nhiều hơn nữa.
Ví dụ, trong hình ảnh dưới đây, cụm từ “một con chó chơi với một quả bóng” sẽ được grounded bằng cách kết nối “một con chó” với vùng mà con chó xuất hiện trong hình ảnh và “một quả bóng” với vị trí của quả bóng.
>> Xem thêm:
- Top 20 công ty thiết kế app uy tín, chuyên nghiệp nhất
- AI agent là gì? Cách Agentic AI hoạt động trong hệ thống trí tuệ nhân tạo
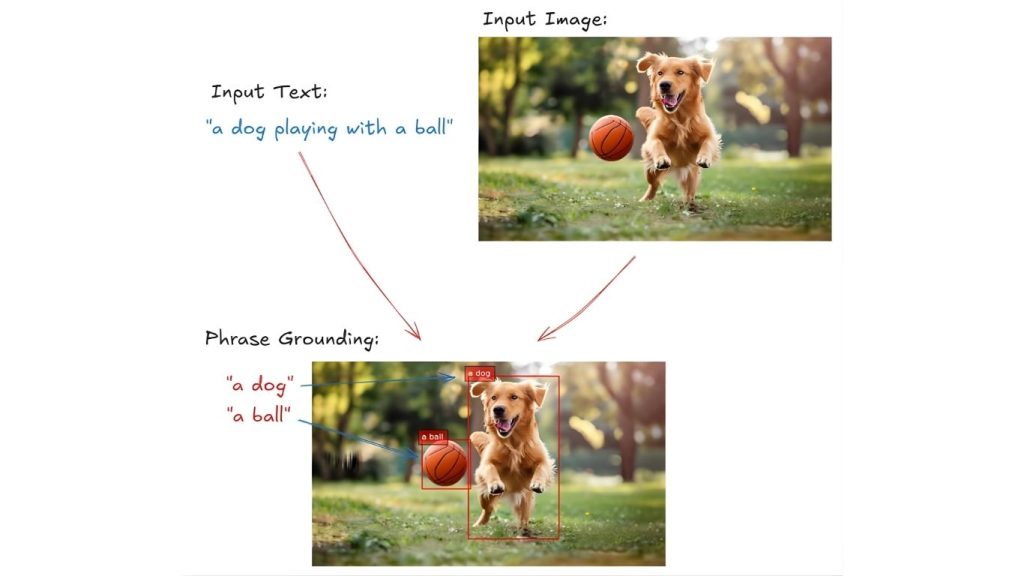
Cách thức hoạt động của Phrase Grounding
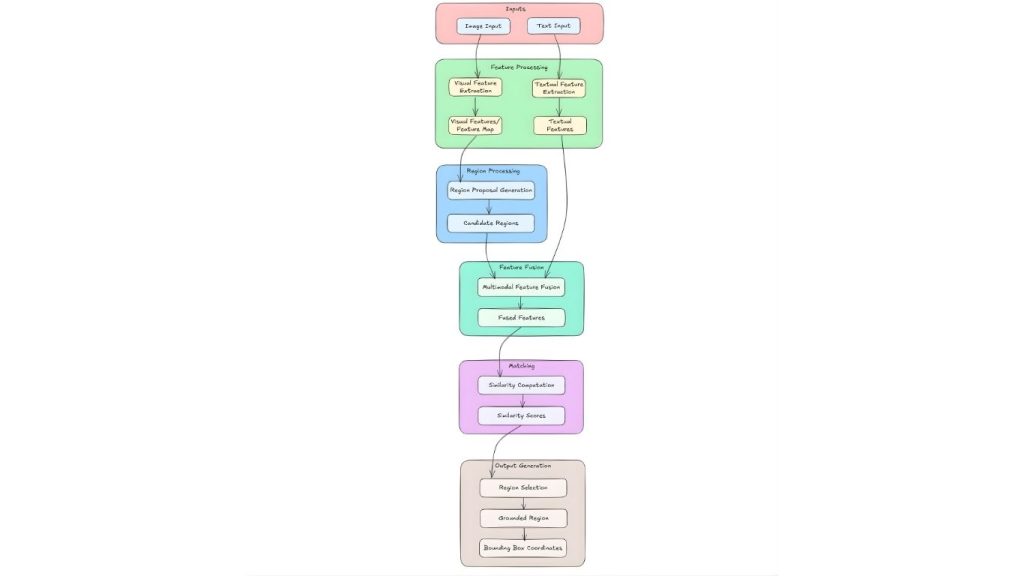
Phrase Grounding là nhiệm vụ căn chỉnh các cụm từ văn bản với các vùng tương ứng trong hình ảnh. Điều này bao gồm một số giai đoạn chính, mỗi giai đoạn chịu trách nhiệm cho các nhiệm vụ cụ thể để đạt được sự căn chỉnh chính xác. Mặc dù các triển khai cụ thể có thể khác nhau, quy trình làm việc chung trên hầu hết các mô hình bao gồm các bước sau:
Đầu vào
- Đầu vào hình ảnh: Một hình ảnh được cung cấp làm đầu vào. Hình ảnh này đóng vai trò là bối cảnh trực quan để làm rõ phần mô tả bằng văn bản.
- Đầu vào văn bản: Cụm từ hoặc câu cần được liên kết với hình ảnh. Nó cung cấp thông tin ngữ nghĩa để xác định các vùng liên quan trong hình ảnh.
Xử lý tính năng
Cả hai đầu vào đều tuân theo các đường xử lý ban đầu riêng biệt để trích xuất các đặc trưng liên quan.
- Trích xuất đặc trưng hình ảnh
Sử dụng Convolutional Neural Network (CNN) để xử lý hình ảnh. Bản đồ đặc trưng được tạo ra ghi lại thông tin không gian và hình ảnh từ các vùng khác nhau của hình ảnh. Những đặc trưng này rất cần thiết để xác định các khu vực tiềm năng tương ứng với mô tả văn bản.
- Trích xuất đặc trưng văn bản
Sử dụng các mô hình như mạng Long Short-Term Memory (LSTM) hoặc Transformer để xử lý đầu vào văn bản. Văn bản được chuyển đổi thành các vectơ đặc trưng ngữ nghĩa bao gồm ý nghĩa và ngữ cảnh của cụm từ đầu vào. Những vectơ này rất quan trọng để khớp văn bản với các đặc trưng hình ảnh liên quan.
Xử lý vùng
- Tạo đề xuất vùng
Bước này sử dụng các đặc trưng hình ảnh từ mạng CNN để tạo ra nhiều khung giới hạn tiềm năng. Các vùng có thể chứa đối tượng hoặc các vùng hình ảnh liên quan được xác định. Bước này thu hẹp không gian tìm kiếm xuống các vùng ứng cử viên cụ thể có khả năng tương ứng với mô tả văn bản.
- Vùng ứng cử viên
Đây là tập hợp các vùng được đề xuất có thể phù hợp với mô tả văn bản. Mỗi vùng ứng cử viên được liên kết với các đặc điểm hình ảnh được trích xuất từ phần tương ứng của ảnh.
Hợp nhất tính năng
- Kết hợp đặc trưng đa phương thức
Kết hợp các đặc trưng hình ảnh từ các vùng ứng viên với các đặc trưng văn bản để tạo ra một biểu diễn chung. Sự kết hợp này nắm bắt cả thông tin hình ảnh và văn bản, tạo điều kiện so sánh hiệu quả giữa văn bản và các vùng hình ảnh. Các kỹ thuật như cơ chế chú ý được sử dụng để đánh trọng số tầm quan trọng của các đặc trưng khác nhau trong quá trình kết hợp.
- Đặc trưng kết hợp
Đây là biểu diễn thống nhất kết quả từ quá trình kết hợp. Nó cho phép mô hình đánh giá mức độ liên quan của mỗi vùng ứng viên liên quan đến văn bản đầu vào.
Ghép nối
- Tính toán độ tương đồng
Bước này bao gồm việc tính toán mức độ phù hợp của từng vùng ứng cử viên với mô tả văn bản. Sử dụng các thước đo độ tương đồng hoặc cơ chế chú ý để định lượng sự căn chỉnh giữa các đặc trưng đã kết hợp và văn bản. Bước này tạo ra các điểm số độ tương đồng cho biết mức độ khớp cho mỗi vùng.
- Điểm tương đồng
Đây là các giá trị số đại diện cho mức độ tương ứng giữa mỗi vùng ứng viên và văn bản. Điểm số cao hơn cho thấy sự khớp mạnh hơn, hướng dẫn việc chọn vùng liên quan nhất.
Tạo đầu ra
- Lựa chọn vùng
Tại đây, vùng (hoặc các vùng) phù hợp nhất dựa trên điểm số tương đồng sẽ được chọn. Có thể chọn nhiều vùng nếu cụm từ mô tả nhiều đối tượng. Bước này hoàn tất quá trình xác định vùng ảnh tương ứng với dữ liệu văn bản.
- Vùng được chọn
Đây là vùng cuối cùng được chọn phù hợp nhất với mô tả văn bản. Những vùng này được làm nổi bật hoặc chú thích để chỉ ra sự tương ứng của chúng với cụm từ đầu vào.
- Tọa độ hộp giới hạn
Kết quả đầu ra dưới dạng tọa độ x, y xác định ranh giới của vùng được đặt trên mặt đất. Những tọa độ này có thể được sử dụng để hiển thị hoặc các tác vụ xử lý tiếp theo.
Quy trình làm việc này là phổ biến trên các mô hình Phrase Grounding khác nhau, với sự khác biệt chủ yếu ở các kiến trúc và phương pháp cụ thể được sử dụng để trích xuất đặc trưng, hợp nhất và tính toán độ tương tự.
>> Xem thêm:
- Cách sử dụng AI tối ưu trải nghiệm khách hàng: Xu hướng
- Hướng dẫn quy trình viết app mobile đơn giản, chi tiết từ A – Z
Các mô hình Phrase Grounding
Dưới đây là một số mô hình và phương pháp tiêu biểu được sử dụng cho Phrase Grounding:
Florence-2
Florence-2 là một mô hình nền tảng thị giác được phát triển bởi Microsoft, được thiết kế để xử lý nhiều nhiệm vụ thị giác máy tính và thị giác-ngôn ngữ thông qua một phương pháp dựa trên prompt thống nhất.
Trong ngữ cảnh của Phrase Grounding, Florence-2 xuất sắc trong việc giải thích các prompt văn bản để xác định và định vị các cụm từ cụ thể trong hình ảnh. Được đào tạo trên tập dữ liệu FLD-5B rộng lớn, bao gồm 5,4 tỷ chú thích trên 126 triệu hình ảnh, mô hình này kết nối hiệu quả các cụm từ văn bản với các vùng hình ảnh tương ứng.
Florence-2 hỗ trợ các nhiệm vụ như caption-to-phrase grounding, trong đó nó căn chỉnh các phân đoạn của một chú thích được tạo với các vùng cụ thể trong hình ảnh. Kiến trúc sequence-to-sequence của nó cho phép nó thực hiện các nhiệm vụ như phát hiện đối tượng, phân đoạn và visual grounding bằng cách tạo ra các đầu ra văn bản mô tả hoặc xác định các yếu tố trong hình ảnh.
Khả năng này cho phép Florence-2 ánh xạ chính xác các cụm từ với các đối tác hình ảnh của chúng, nâng cao các ứng dụng yêu cầu sự căn chỉnh chính xác giữa văn bản và hình ảnh.
>> Xem thêm:
- TOP 15+ công ty lập trình phần mềm lớn, uy tín hàng đầu Việt Nam
- Top 9 phần mềm thiết kế app mobile bán hàng miễn phí, dễ sử dụng nhất
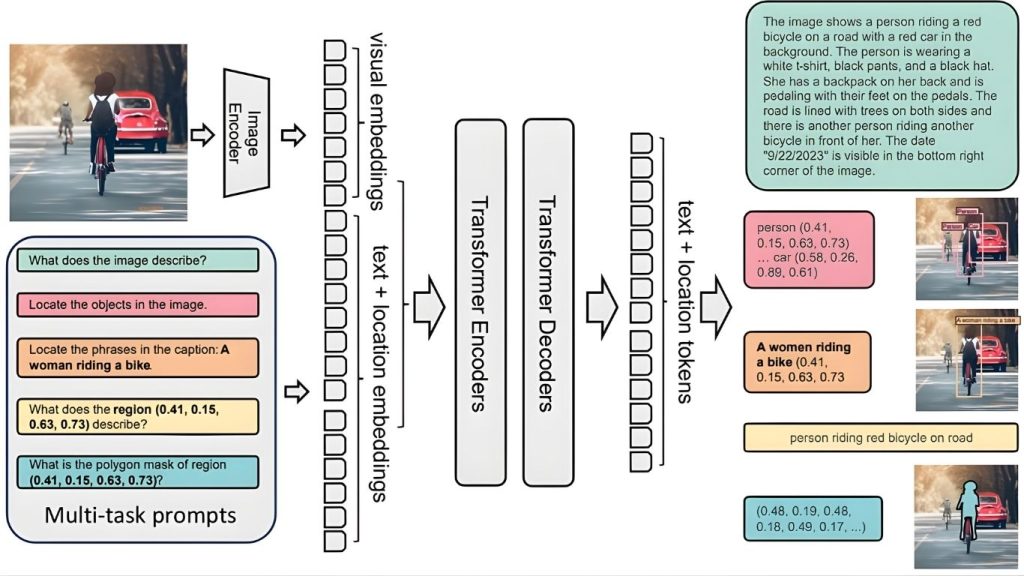
Florence-2 bao gồm một bộ mã hóa hình ảnh và một bộ mã hóa-giải mã đa phương thức tiêu chuẩn, được huấn luyện bằng tập dữ liệu FLD-5B trong một thiết lập học đa nhiệm thống nhất. Cách tiếp cận này tạo ra một mô hình nền tảng thị giác linh hoạt có khả năng xử lý nhiều tác vụ thị giác khác nhau.
Grounding DINO
Grounding DINO là một mô hình phát hiện đối tượng open-set tiên tiến tích hợp đầu vào ngôn ngữ, như tên danh mục hoặc biểu thức tham chiếu, vào quá trình phát hiện, căn chỉnh hiệu quả các cụm từ văn bản với các vùng hình ảnh tương ứng.
Bằng cách kết hợp một bộ mã hóa văn bản vào kiến trúc DINO dựa trên Transformer, Grounding DINO cho phép phát hiện các đối tượng tùy ý được chỉ định bởi đầu vào của con người, do đó tăng cường khả năng Phrase Grounding.
Sự tích hợp này cho phép mô hình hiểu và định vị các đối tượng dựa trên các cụm từ mô tả, tạo điều kiện cho các nhiệm vụ như hiểu biểu thức tham chiếu và phát hiện từ vựng mở. Kiến trúc của mô hình bao gồm một bộ tăng cường đặc trưng, lựa chọn truy vấn được hướng dẫn bởi ngôn ngữ và một bộ giải mã đa phương thức, tất cả đều góp phần vào khả năng kết nối các mô tả văn bản với các yếu tố hình ảnh.
Grounding DINO đã thể hiện hiệu suất đáng chú ý trên các benchmark khác nhau, bao gồm các tập dữ liệu COCO, LVIS và RefCOCO, nhấn mạnh hiệu quả của nó trong các ứng dụng Phrase Grounding.
>> Xem thêm:
- Hướng dẫn tạo ứng dụng AI với vibe coding trên Google AI Studio dễ dàng
- Cách sử dụng chatbot cho giáo dục đại học và học tập
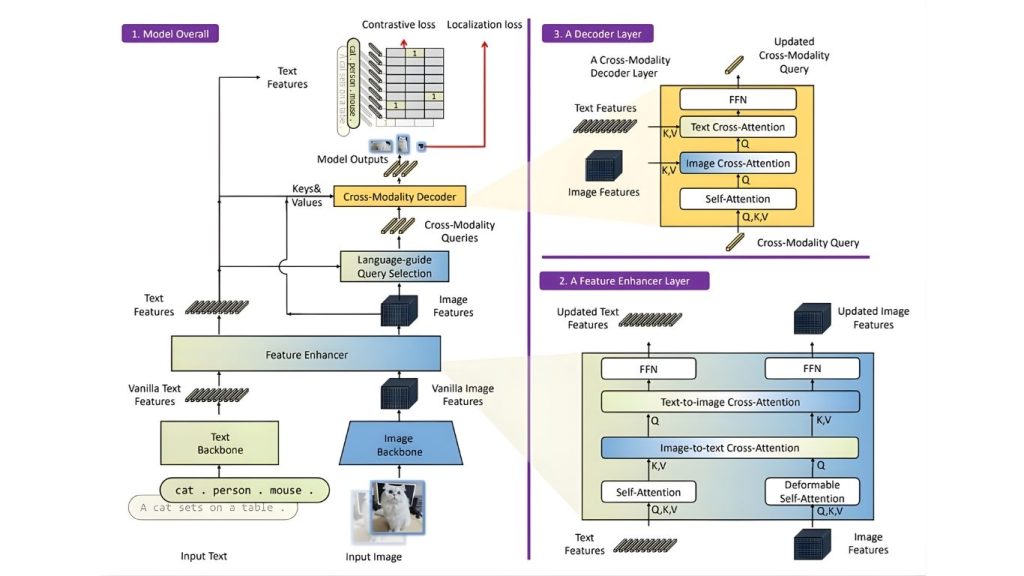
Khung Grounding DINO bao gồm ba khối chính: khối 1 mô tả kiến trúc tổng thể của hệ thống, khối 2 là lớp tăng cường đặc trưng, và khối 3 là lớp bộ giải mã.
MM-Grounding-DINO
MM-Grounding-DINO là một framework mã nguồn mở được thiết kế để nâng cao Phrase Grounding bằng cách tích hợp đầu vào ngôn ngữ vào các mô hình phát hiện đối tượng.
Được xây dựng trên kiến trúc Grounding DINO, nó sử dụng bộ công cụ MMDetection để tạo ra một pipeline toàn diện và thân thiện với người dùng. Framework này tận dụng các tập dữ liệu thị giác mở rộng để pre-training và fine-tuning, cho phép nó kết nối hiệu quả các cụm từ văn bản với các vùng hình ảnh tương ứng.
Bằng cách kết hợp các module như bộ tăng cường đặc trưng, lựa chọn truy vấn được hướng dẫn bởi ngôn ngữ và bộ giải mã đa phương thức, MM-Grounding-DINO cải thiện sự căn chỉnh giữa các mô tả văn bản và các yếu tố hình ảnh.
Các đánh giá trên các benchmark như COCO, LVIS và RefCOCO chứng minh khả năng của nó trong các nhiệm vụ Phrase Grounding, nổi bật tiềm năng của nó cho các ứng dụng yêu cầu sự tương ứng chính xác giữa văn bản và hình ảnh.
>> Xem thêm:
- Top 20 công ty thiết kế website TPHCM theo yêu cầu, trọn gói, uy tín
- Cách viết app Android/iOS chi tiết, dễ dàng, không cần kiến thức lập trình
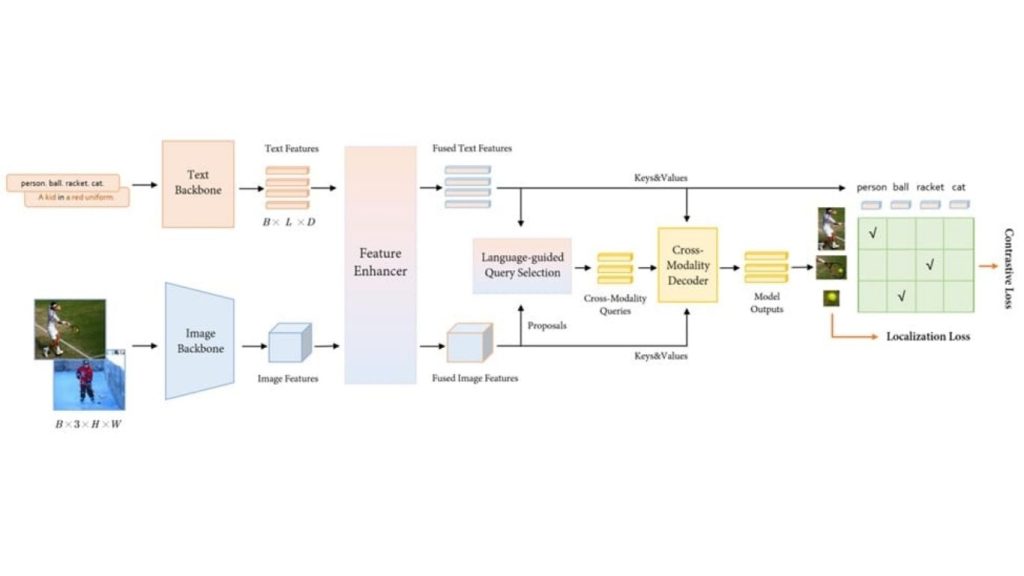
MM-Grounding-DINO trích xuất đặc trưng văn bản và hình ảnh thông qua các backbone tương ứng, sau đó hợp nhất chúng bằng mô-đun tăng cường đặc trưng. Cơ chế lựa chọn truy vấn có hướng dẫn bởi ngôn ngữ sẽ trích xuất các truy vấn liên mô thức, và bộ giải mã sử dụng các truy vấn này để dự đoán các hộp đối tượng cùng với các cụm từ tương ứng.
GLaMM
Mô hình GLaMM (Grounding Large Multimodal Model) cho phép Phrase Grounding bằng cách tích hợp xử lý ngôn ngữ tự nhiên với hiểu biết hình ảnh chi tiết. Nó tạo ra các phản hồi ngôn ngữ tự nhiên đan xen với các mặt nạ phân đoạn đối tượng tương ứng, cho phép căn chỉnh chính xác giữa các cụm từ văn bản và các vùng hình ảnh cụ thể. GLaMM chấp nhận cả prompt văn bản và hình ảnh tùy chọn, cho phép người dùng tương tác ở nhiều mức độ chi tiết khác nhau trong cả lĩnh vực văn bản và hình ảnh.
Để hỗ trợ khả năng của GLaMM, các tác giả đã giới thiệu Grounding-anything Dataset (GranD), một tập dữ liệu được chú thích dày đặc bao gồm 7,5 triệu khái niệm duy nhất được ground trong 810 triệu vùng với các mặt nạ phân đoạn. Tập dữ liệu mở rộng này cung cấp một nền tảng vững chắc để đào tạo và đánh giá các mô hình Phrase Grounding.
Bằng cách cung cấp sự căn chỉnh cấp pixel giữa văn bản và hình ảnh, xử lý đầu vào linh hoạt và giới thiệu các nhiệm vụ và tập dữ liệu mới, GLaMM đã đẩy mạnh đáng kể lĩnh vực Phrase Grounding.
>> Xem thêm:
- Character AI là gì? Trò chuyện cùng nhân vật ảo trên mô hình mới
- Vision AI Agents là gì? Cách xây dựng Vision AI Agents với Roboflow
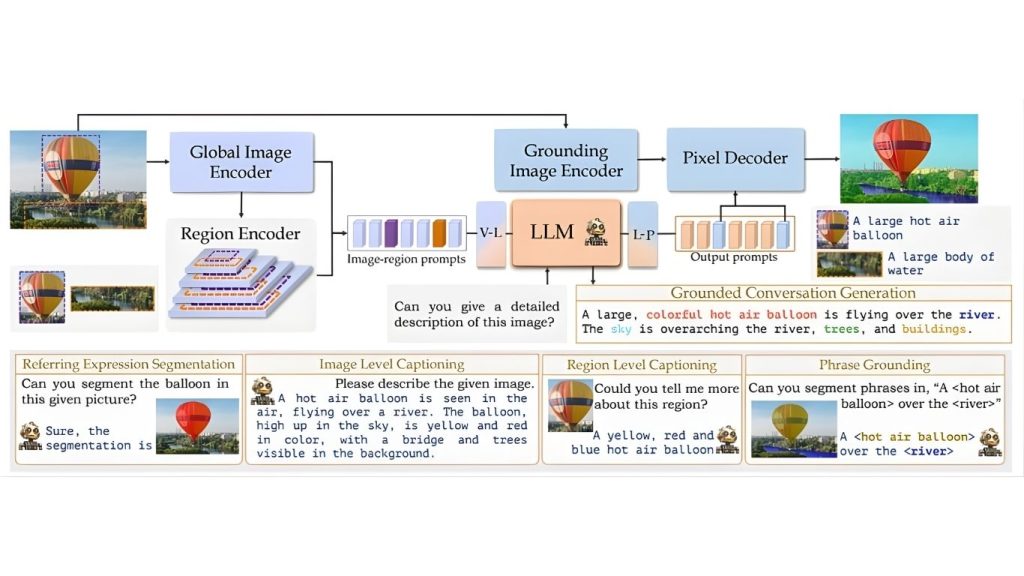
Kiến trúc của GLaMM cung cấp khả năng hiểu ở cấp độ cảnh, vùng và pixel cho các tác vụ xử lý ngôn ngữ hình ảnh. Nó sử dụng bộ mã hóa hình ảnh và ngôn ngữ, bộ giải mã pixel và các lớp chiếu để lập bản đồ đặc trưng và phân đoạn. GLaMM hỗ trợ các tác vụ như tạo hội thoại dựa trên ngữ cảnh, xác định ngữ cảnh cụm từ và nhiều ứng dụng chú thích khác nhau.
KOSMOS-2
KOSMOS-2 là một mô hình ngôn ngữ lớn đa phương thức (MLLM) cho phép Phrase Grounding bằng cách tích hợp thông tin hình ảnh và văn bản. Nó biểu diễn các biểu thức tham chiếu dưới dạng liên kết kiểu Markdown, kết nối các đoạn văn bản với các hộp giới hạn, cho phép mô hình ánh xạ hiệu quả các cụm từ văn bản vào các vùng hình ảnh cụ thể.
Được đào tạo trên tập dữ liệu GrIT, một bộ sưu tập quy mô lớn các cặp hình ảnh-văn bản đã ground, KOSMOS-2 cho thấy hiệu suất được cải thiện trong các nhiệm vụ như hiểu biểu thức tham chiếu và Phrase Grounding. Biểu diễn thống nhất và dữ liệu đào tạo toàn diện của nó góp phần vào khả năng căn chỉnh các cụm từ văn bản với nội dung hình ảnh, đẩy mạnh lĩnh vực hiểu đa phương thức.
>> Xem thêm:
- Mẹo tạo prompt cho LLM trong thị giác máy tính để tăng độ chính xác
- Data Annotation Platforms: Nền tảng gán nhãn dữ liệu cho thị giác máy tính tốt nhất
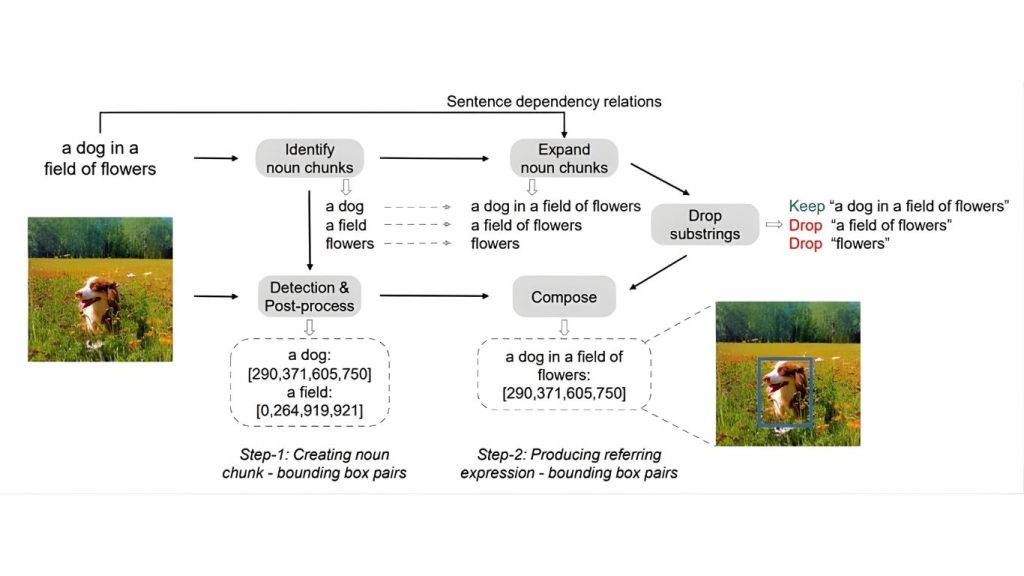
Quy trình KOSMOS-2 bao gồm hai bước chính.
- Bước 1:
Các cụm danh từ được trích xuất từ các chữ thích hình ảnh và được so khớp với các vùng hình ảnh bằng cách sử dụng một bộ phát hiện được huấn luyện trước. Các cụm từ trừu tượng được lọc ra, và một mô hình grounding tạo ra các hộp giới hạn cho các cụm này. Các hộp có độ trùng lặp cao được loại bỏ, và chỉ những cặp cụm danh từ-hộp giới hạn có độ tin cậy cao được giữ lại.
- Bước 2
Các cụm danh từ được mở rộng thành các biểu thức tham chiếu bằng cách duyệt qua các quan hệ phụ thuộc trong câu. Các biểu thức độc nhất được giữ lại, và các hộp giới hạn từ các cụm danh từ được gán cho các biểu thức mở rộng này.
GLIP
GLIP (Grounded Language-Image Pre-training) là một mô hình thống nhất phát hiện đối tượng và Phrase Grounding để tăng cường sự căn chỉnh giữa các cụm từ văn bản và các vùng hình ảnh tương ứng. Bằng cách tái định dạng phát hiện đối tượng như một nhiệm vụ Phrase Grounding, GLIP xử lý hình ảnh cùng với các prompt văn bản mô tả các danh mục ứng viên, cho phép nó kết nối hiệu quả các vùng hình ảnh với các cụm từ cụ thể.
Được đào tạo trên một tập dữ liệu đáng kể gồm 27 triệu dữ liệu grounding, bao gồm 3 triệu được chú thích bởi con người và 24 triệu cặp hình ảnh-văn bản được thu thập từ web, GLIP thể hiện khả năng chuyển giao zero-shot và few-shot mạnh mẽ cho nhiều nhiệm vụ nhận dạng cấp đối tượng. Đáng chú ý, nó đạt 49,8 AP trên COCO và 26,9 AP trên LVIS mà không tiếp xúc trước với các tập dữ liệu này trong quá trình pre-training, vượt qua nhiều baseline được giám sát.
Cách tiếp cận thống nhất này cho phép GLIP tận dụng cả dữ liệu phát hiện và grounding, tạo ra các biểu diễn hình ảnh giàu ngữ nghĩa cải thiện hiệu suất trên nhiều nhiệm vụ.
>> Xem thêm:
- Chi phí thiết kế app, duy trì app trên CH Play, App Store
- 18 cách ứng dụng AI cho ecommerce đạt hiệu quả cao
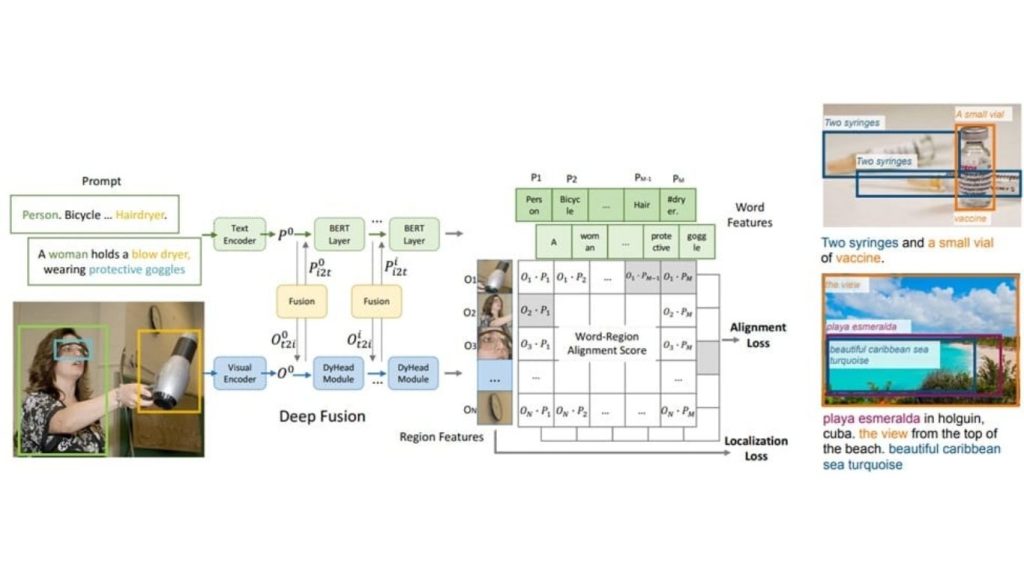
GLIP là một khung thống nhất giúp định hình lại việc phát hiện đối tượng như một nhiệm vụ định vị, liên kết các vùng ảnh với các cụm từ trong lời nhắc văn bản. Nó huấn luyện các bộ mã hóa hình ảnh và ngôn ngữ cùng với sự kết hợp đa phương thức để tạo ra biểu diễn hình ảnh có nhận thức về ngôn ngữ, cho phép phát hiện các thực thể hiếm và các cụm từ trừu tượng.
MDETR
MDETR (Modulated Detection for End-to-End Multi-Modal Understanding) là một mô hình được thiết kế để nâng cao Phrase Grounding bằng cách tích hợp phát hiện đối tượng với hiểu ngôn ngữ tự nhiên. Không giống như các hệ thống truyền thống dựa vào các bộ phát hiện đối tượng được đào tạo trước với từ vựng cố định, MDETR sử dụng kiến trúc dựa trên transformer để xử lý hình ảnh và truy vấn văn bản cùng nhau.
Cách tiếp cận end-to-end này cho phép mô hình phát hiện các đối tượng trong hình ảnh dựa trên các đầu vào văn bản tự do, chẳng hạn như chú thích hoặc câu hỏi, cho phép nó nắm bắt một loạt các khái niệm hình ảnh được thể hiện bằng ngôn ngữ tự nhiên.
Được đào tạo trên một tập dữ liệu lớn gồm 1,3 triệu cặp văn bản-hình ảnh với sự căn chỉnh rõ ràng giữa các cụm từ và đối tượng, MDETR đạt được hiệu suất tiên tiến trên các benchmark như Flickr30k cho Phrase Grounding và RefCOCO/+/g cho hiểu biểu thức tham chiếu. Khả năng tổng quát hóa của nó cho các kết hợp mới của các danh mục đối tượng và thuộc tính làm cho nó trở thành một bước tiến đáng kể trong lĩnh vực hiểu đa phương thức.
>> Xem thêm:
- AI nghiên cứu khoa học (Scientific Research AI): Mở khóa dữ liệu hình ảnh
- Vertex AI là gì?
- Low Code là gì? Giải pháp phát triển phần mềm và xu hướng tương lai
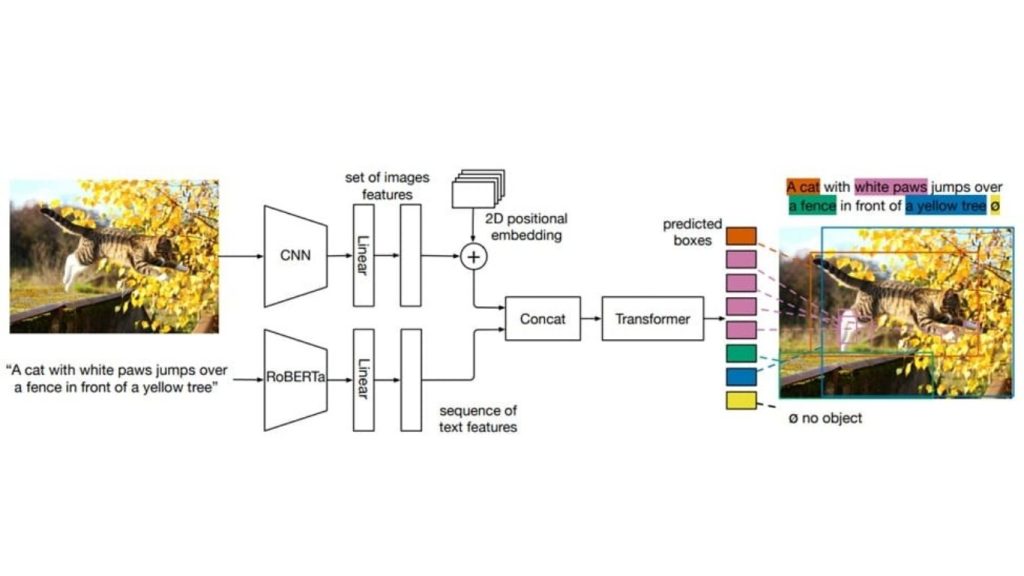
MDETR sử dụng kiến trúc mạng tích chập cho các đặc trưng hình ảnh và mô hình ngôn ngữ như RoBERTa cho các đặc trưng văn bản, chiếu cả hai vào một không gian chung. Các đặc trưng kết hợp này được xử lý bởi bộ mã hóa-giải mã Transformer để dự đoán các hộp giới hạn đối tượng và vị trí văn bản tương ứng của chúng.
ZSGNet
Zero-Shot Grounding of Objects from Natural Language Queries (ZSGNet) là một mô hình được thiết kế để giải quyết thách thức của Phrase Grounding, đặc biệt trong các kịch bản zero-shot khi các danh mục đối tượng không có trong dữ liệu đào tạo.
Các hệ thống Phrase Grounding truyền thống thường dựa vào các bộ phát hiện đối tượng được đào tạo trước giới hạn ở các danh mục cụ thể, điều này hạn chế khả năng tổng quát hóa của chúng đối với các đối tượng chưa thấy. ZSGNet vượt qua giới hạn này bằng cách sử dụng một mạng một giai đoạn tích hợp các nhiệm vụ phát hiện đối tượng và grounding.
ZSGNet xử lý các đề xuất dày đặc và dự đoán điểm phân loại và tham số hồi quy, cho phép định vị các đối tượng được mô tả bằng các danh từ mới không gặp phải trong quá trình đào tạo. Mô hình được đào tạo end-to-end trên các tập dữ liệu grounding mà không dựa vào các bộ phát hiện đối tượng bên ngoài, cho phép nó tổng quát hóa hiệu quả cho các danh mục đối tượng mới.
Các đánh giá trên các tập dữ liệu như Flickr30k Entities và Visual Genome cho thấy rằng ZSGNet đạt được hiệu suất tiên tiến trong các nhiệm vụ Phrase Grounding truyền thống và cho thấy những cải thiện đáng kể trong các kịch bản grounding zero-shot, nổi bật tính vững chắc và khả năng thích ứng của nó.
>> Xem thêm:
- Cách tạo chatbot AI bán hàng hiệu quả, không cần lập trình
- AI Data Labeling: Hướng dẫn gán nhãn dữ Liệu AI
- Ứng dụng AI trong bán hàng online: TOP 10 công cụ AI & cách triển khai hiệu quả
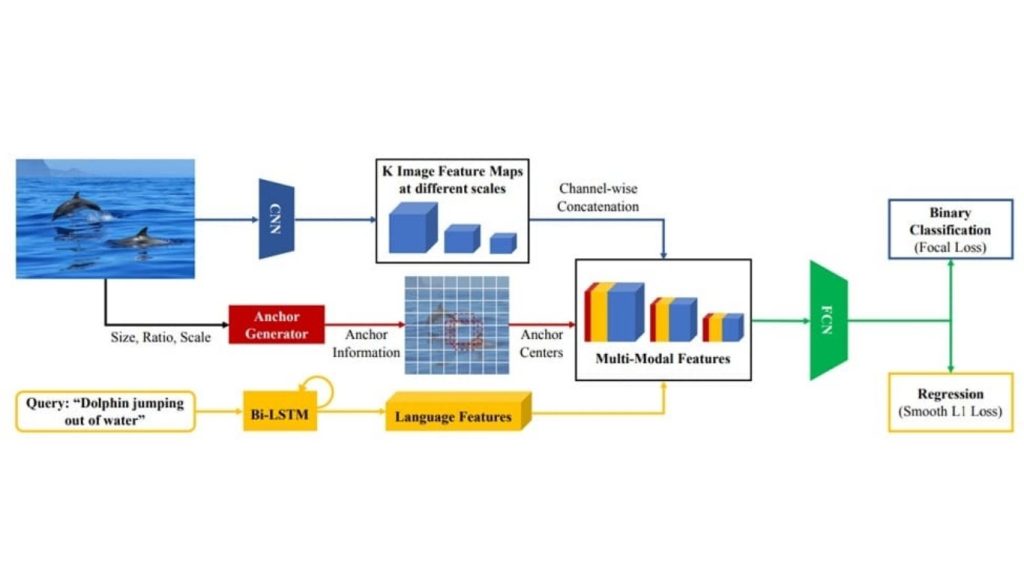
Kiến trúc ZSGNet nhận một cặp hình ảnh-truy vấn làm đầu vào, tạo ra các bản đồ đặc trưng hình ảnh đa tỷ lệ, và nối thêm các tâm neo cũng như các đặc trưng truy vấn được mã hóa. Các bản đồ đa phương thức này được xử lý bởi một FCN để dự đoán điểm số và các tham số hồi quy, được huấn luyện với hàm mất mát focal và SmoothL1.
SeqGROUND
Mô hình SeqGROUND (Neural Sequential Phrase Grounding) cho phép Phrase Grounding bằng cách coi nó như một quá trình tuần tự và theo ngữ cảnh.
Không giống như các phương pháp truyền thống ground độc lập từng cụm từ, SeqGROUND sử dụng hai ngăn xếp các tế bào Bộ nhớ Ngắn hạn Dài (LSTM) để mã hóa các đề xuất vùng và cụm từ, cùng với các cặp cụm từ-vùng đã được ground trước đó.
Kiến trúc này nắm bắt thông tin ngữ cảnh, cho phép mô hình sử dụng các quyết định grounding trước đó để thông báo cho các quyết định tiếp theo. Đáng chú ý, SeqGROUND hỗ trợ khớp nhiều-nhiều, cho phép một vùng hình ảnh tương ứng với nhiều cụm từ và ngược lại. Các đánh giá trên tập dữ liệu benchmark Flickr30K chứng minh hiệu suất cạnh tranh của nó, xác nhận hiệu quả của phương pháp grounding tuần tự và các lựa chọn thiết kế kiến trúc của nó.
>> Xem thêm:
- TOP 10 công cụ AI thiết kế website miễn phí, trả phí, hiệu quả
- Dịch vụ thiết kế website trọn gói theo yêu cầu uy tín chuyên nghiệp
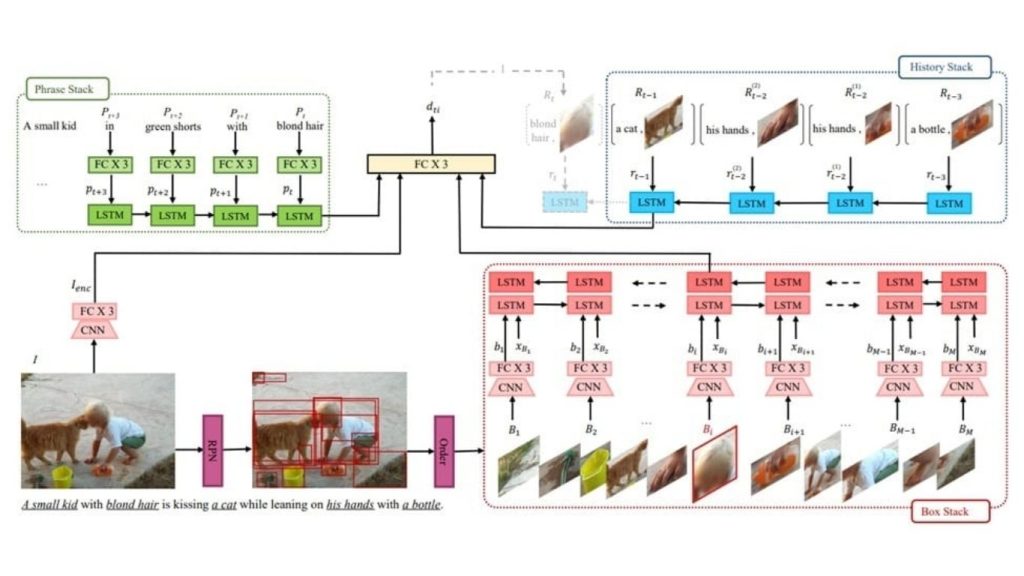
Kiến trúc SeqGROUND xử lý các cụm từ theo trình tự, sử dụng các chồng LSTM để mã hóa các mối quan hệ ngôn ngữ và chuỗi hộp gắn liền với hình ảnh. Các quyết định liên kết xem xét trạng thái hiện tại của chồng LSTM và biểu diễn hình ảnh đầy đủ, cập nhật chồng LSTM lịch sử với các cặp cụm từ-hộp mới được liên kết.
Align2Ground
Mô hình Align2Ground liên quan đến việc kết nối các cụm từ văn bản với các vùng tương ứng trong hình ảnh cho Phrase Grounding. Nó hoạt động dưới sự giám sát yếu, sử dụng các cặp hình ảnh-chú thích mà không có chú thích rõ ràng về vùng-cụm từ.
Mô hình sử dụng quy trình hai giai đoạn: đầu tiên, nó suy ra các tương ứng tiềm ẩn giữa các vùng quan tâm (RoI) trong hình ảnh và các cụm từ trong chú thích, tạo ra một biểu diễn hình ảnh phân biệt dựa trên các RoI được khớp này. Biểu diễn đã học này được căn chỉnh với toàn bộ chú thích, tạo điều kiện thuận lợi cho việc khớp hình ảnh-chú thích hiệu quả.
Các đánh giá thực nghiệm đã chứng minh rằng Align2Ground đạt được những cải tiến đáng kể trong việc định vị cụm từ, vượt trội hơn các phương pháp tiên tiến trước đây trên các tập dữ liệu như VisualGenome và Flickr30k Entities.
>> Xem thêm:
- Thiết kế website thương mại điện tử chuyên nghiệp với 7 chi tiết
- 30 mẫu thiết kế website nhà hàng – thực phẩm chuyên nghiệp, chuẩn SEO
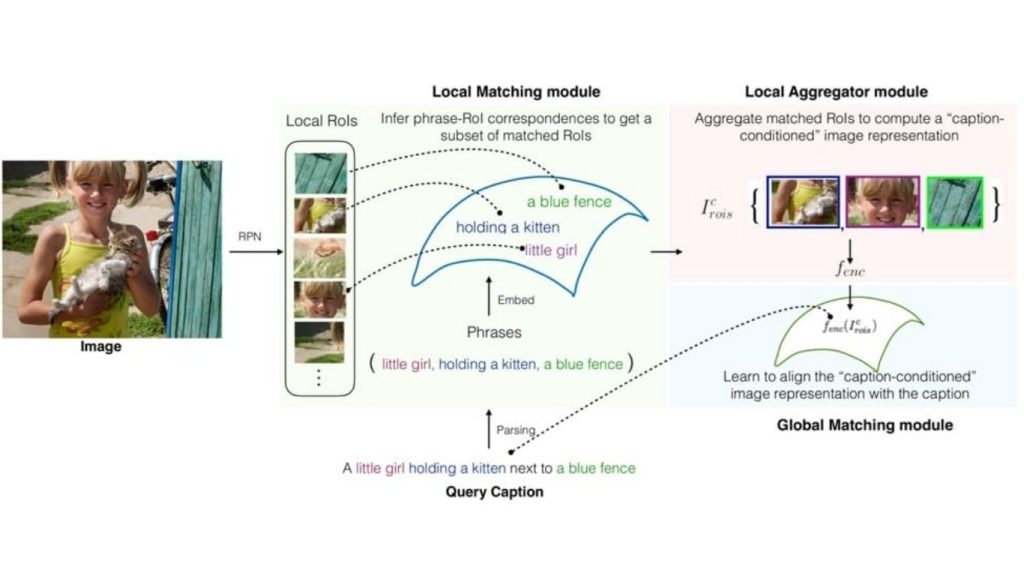
Hình này phác thảo kiến trúc của Align2Ground. Đầu ra của Mạng đề xuất vùng (RoIs) và các cụm từ đã được phân tích cú pháp được xử lý bởi mô-đun Đối sánh cục bộ để suy ra sự tương ứng giữa cụm từ và RoI. Mô-đun Tổng hợp cục bộ tinh chỉnh các RoI đã được đối sánh này để xây dựng một biểu diễn trực quan dựa trên chú thích, sau đó được căn chỉnh với các cặp hình ảnh-chú thích trong mô-đun Đối sánh toàn cục.
MultiGrounding
Không gian ngữ nghĩa chung đa phương thức đa cấp độ cho Grounding Cụm từ-Hình ảnh giới thiệu một mô hình được thiết kế cho tác vụ grounding cụm từ bằng cách học một không gian ngữ nghĩa được chia sẻ giữa các phương thức văn bản và hình ảnh.
Phương pháp này sử dụng nhiều cấp độ của các bản đồ đặc trưng từ một mạng nơ-ron tích chập sâu để nắm bắt các khái niệm hình ảnh và mô hình khác nhau. Đồng thời, nó sử dụng các embedding từ và câu được ngữ cảnh hóa từ một mô hình ngôn ngữ dựa trên ký tự để biểu diễn thông tin văn bản.
Bằng cách áp dụng các ánh xạ phi tuyến tính chuyên dụng cho cả các đặc trưng hình ảnh ở mỗi cấp độ và các embedding văn bản, mô hình tạo ra nhiều thể hiện của một không gian ngữ nghĩa chung. Trong không gian này, các so sánh giữa nội dung văn bản và hình ảnh được thực hiện bằng cách sử dụng độ tương tự cosine. Một cơ chế chú ý đa phương thức đa cấp độ hướng dẫn mô hình tập trung vào các đặc trưng hình ảnh có liên quan ứng với các cụm từ cụ thể.
Các thử nghiệm trên các bộ dữ liệu công khai cho thấy những cải thiện hiệu suất đáng kể so với các phương pháp trạng thái hiện tại trong định vị cụm từ, làm nổi bật hiệu quả của phương pháp đa cấp độ, đa phương thức này đối với grounding cụm từ.
>> Xem thêm:
- TOP 20 công cụ Chat AI tiếng Việt miễn phí thông minh phổ biến
- TOP 25 công cụ AI miễn phí, phổ biến, tốt nhất hiện nay
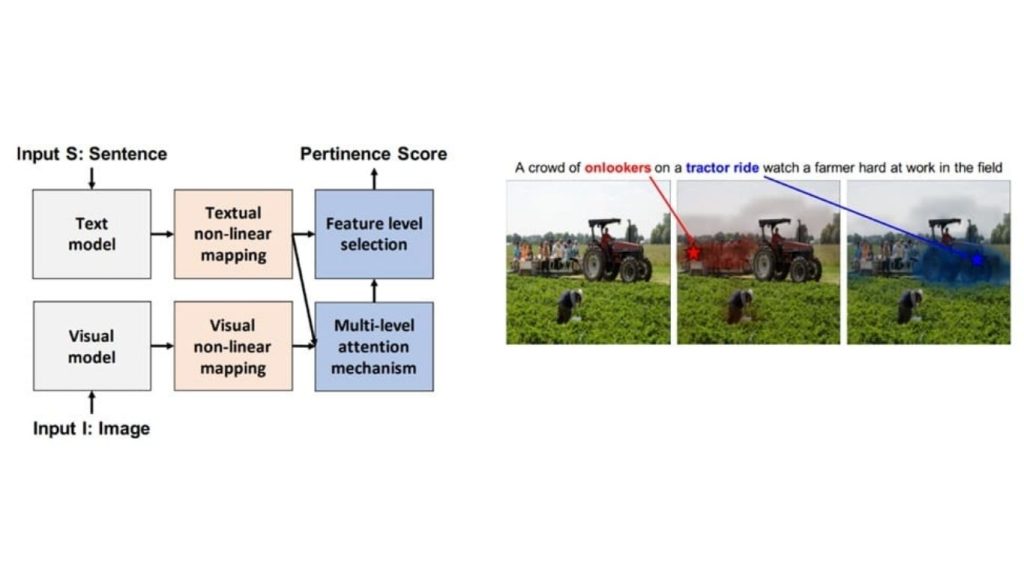
Phương pháp này xử lý văn bản và hình ảnh bằng cách sử dụng các mô hình được huấn luyện trước, ánh xạ chúng đến một không gian ngữ nghĩa được chia sẻ, và áp dụng chú ý đa cấp độ để tính điểm mức độ liên quan giữa chúng. Mô hình được huấn luyện bằng cách sử dụng giám sát yếu từ các cặp hình ảnh-câu.
GroundeR
GroundeR, giới thiệu một phương pháp tiên phong cho grounding cụm từ, sử dụng một cơ chế chú ý cho phép mô hình tập trung vào các vùng hình ảnh cụ thể có liên quan đến một cụm từ nhất định. Trong quá trình huấn luyện, GroundeR học cách tái tạo các cụm từ đầu vào bằng cách chú ý đến các vùng hình ảnh thích hợp, hiệu quả căn chỉnh thông tin văn bản và hình ảnh.
Phương pháp này cho phép mô hình hoạt động dưới các mức độ giám sát khác nhau, bao gồm cài đặt không giám sát, bán giám sát và đầy đủ giám sát. Các đánh giá trên các bộ dữ liệu như Flickr30k Entities và ReferItGame đã chứng minh rằng GroundeR vượt trội hơn các phương pháp trước đó, làm nổi bật hiệu quả của nó trong việc grounding các cụm từ trong hình ảnh một cách chính xác.
>> Xem thêm:
- Computer Vision Software: Các phần mềm thị giác máy tính miễn phí
- 7 Bước tích hợp chatbot (AI) vào website, dễ dàng, chốt đơn nhanh
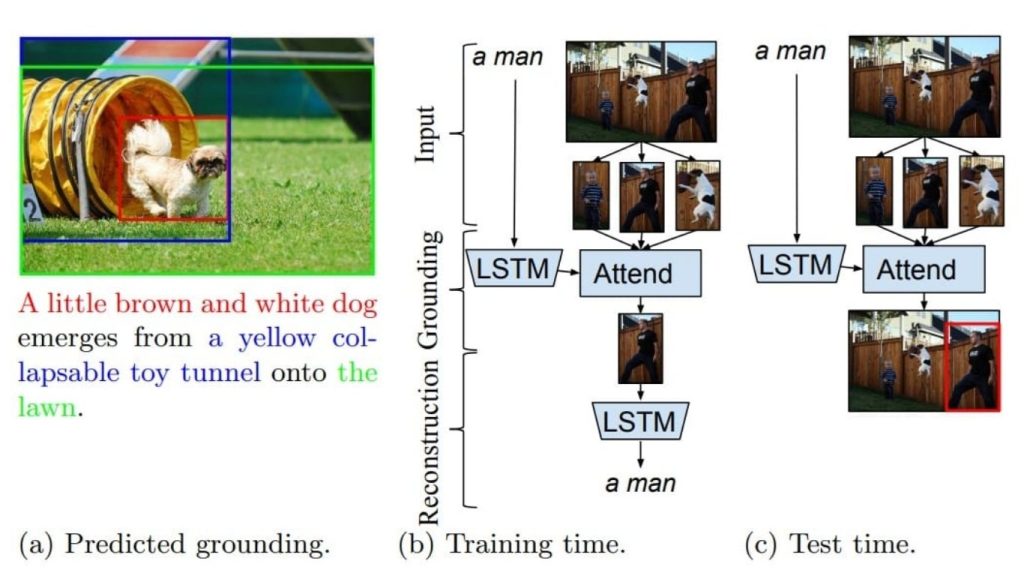
GroundeR là một mô hình có thể liên kết các cụm từ ngôn ngữ tự nhiên với các vùng cụ thể trong hình ảnh mà không cần các chú thích hộp giới hạn trong quá trình huấn luyện. Nó đạt được điều này bằng cách học cách tập trung vào các vùng hình ảnh chính xác để tái tạo chính xác các cụm từ được cung cấp.
Ví dụ về Phrase Grounding
Bây giờ chúng ta sẽ xem cách thực hiện Phrase Grounding bằng Grounding DINO và Florence-2.
Phrase Grounding sử dụng Grounding DINO
Đây là mã để thực hiện Phrase Grounding bằng Grounding DINO. Trong ví dụ, chúng ta sử dụng hình ảnh đầu vào sau:

Các bước triển khai Phrase Grounding bằng Grounding DINO như sau:
Bước 1: Tải hình ảnh
image_path = "/content/dog.jpg" # Replace with your image path
image_source, image = load_image(image_path)Bước 2: Tải mô hình
model = load_model("groundingdino/config/GroundingDINO_SwinT_OGC.py", "weights/groundingdino_swint_ogc.pth")Bước 3: Định nghĩa text prompt
text_prompt = "a dog with ball." Lưu ý: Text prompt là một cụm từ/câu mô tả đối tượng hoặc vùng bạn muốn định vị trong hình ảnh. Đầu vào này được xử lý bởi mô hình để trích xuất các đặc trưng ngữ nghĩa sẽ được so sánh với các đặc trưng hình ảnh.
Bước 4: Đặt ngưỡng
box_threshold = 0.35
text_threshold = 0.25Lưu ý: box_threshold xác định điểm số tối thiểu để một vùng được coi là khung giới hạn hợp lệ và text_threshold đặt ngưỡng để xác định xem cụm từ có khớp với một vùng trong hình ảnh hay không.
Bước 5: Thực hiện dự đoán
boxes, logits, phrases = predict(
model=model,
image=image,
caption=text_prompt,
box_threshold=box_threshold,
text_threshold=text_threshold
)Bước 6: Chú thích hình ảnh
annotated_image = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases)Đoạn mã tạo ra kết quả đầu ra sau, trong đó chỉ có một con chó đang cầm quả bóng được đặt trên mặt đất như đã nêu trong câu lệnh.

>> Xem thêm:
- Viết phần mềm theo yêu cầu tại Hà Nội – Chuyên nghiệp, giá tốt
- Vulnerability Assessment là gì? Giải pháp đánh giá lỗ hổng bảo mật
Phrase Grounding sử dụng Florence-2
Phrase grounding có thể được thực hiện bằng cách sử dụng Florence-2. Điều này được thực hiện bằng cách sử dụng prompt <CAPTION_TO_PHRASE_GROUNDING>.
Prompt này hướng dẫn mô hình để xác định vị trí và làm nổi bật các vùng trong hình ảnh tương ứng với các cụm từ cụ thể trong một chú thích được cung cấp.
Đầu vào bao gồm prompt theo sau là một chú thích mô tả về hình ảnh. Mô hình xuất ra các hộp giới hạn và nhãn chỉ ra vị trí của các cụm từ được đề cập. Hãy xem hình ảnh dưới đây.

Sử dụng prompt <CAPTION_TO_PHRASE_GROUNDING>, Florence-2 xử lý hình ảnh và chú thích để xác định và định vị các cụm từ đã cho trong hình ảnh. Mô hình xuất ra các hộp giới hạn hoặc mặt nạ phân đoạn làm nổi bật các vùng tương ứng với mỗi cụm từ được xác định. Dưới đây là các bước triển khai:
Bước 1: Tải hình ảnh
image_path = "livingroom.jpg"
image = Image.open(image_path)Bước 2: Khởi tạo bộ xử lý và mô hình
processor = AutoProcessor.from_pretrained("microsoft/Florence-2-large", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("microsoft/Florence-2-large", trust_remote_code=True).eval()Bước 3: Xác định lời nhắc và tiêu đề
prompt = "<CAPTION_TO_PHRASE_GROUNDING>"
caption = "A serene living space showcasing a modern armchair, a leafy potted plant, and a standing lamp casting a warm glow."Bước 4: Chuẩn bị dữ liệu đầu vào
inputs = processor(text=prompt + " " + caption, images=image, return_tensors="pt").to(device)Bước 5: Tạo ra các kết quả đầu ra
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=512,
num_beams=3,
do_sample=False,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]Bước 6: Xử lý hậu kỳ kết quả đầu ra
result = processor.post_process_generation(
generated_text,
task=prompt,
image_size=(image.width, image.height)
)Bước 7: Trích xuất khung giới hạn và nhãn
bboxes = result[prompt]['bboxes']
labels = result[prompt]['labels']Bước 8: Trực quan hóa kết quả
# Create a figure and axis
fig, ax = plt.subplots(1, figsize=(12, 8))
# Display the image
ax.imshow(image)
# Add bounding boxes and labels
for bbox, label in zip(bboxes, labels):
# Unpack the bounding box coordinates
x1, y1, x2, y2 = bbox
# Calculate width and height
width = x2 - x1
height = y2 - y1
# Get the color for the current label
color = label_colors[label]
# Create a rectangle patch
rect = patches.Rectangle((x1, y1), width, height, linewidth=2, edgecolor=color, facecolor='none')
# Add the rectangle to the plot
ax.add_patch(rect)
# Add the label with a matching background color
plt.text(x1, y1 - 10, label, color='white', fontsize=12,
bbox=dict(facecolor=color, edgecolor='none', alpha=0.7))
# Remove axis
plt.axis('off')
# Show the plot
plt.show()Kết quả đầu ra sau đây sẽ được tạo ra.

Trong Florence-2, thay vì chỉ định chú thích một cách rõ ràng, chúng ta cũng có thể sử dụng bất kỳ prompt nào (ví dụ: <CAPTION>, <DETAILED_CAPTION>, <MORE_DETAILED_CAPTION>) để tạo mô tả văn bản cho hình ảnh ở các mức độ chi tiết khác nhau và sau đó sử dụng prompt Phrase Grounding <CAPTION_TO_PHRASE_GROUNDING> cho tác vụ Phrase Grounding.
Đây,
- <CAPTION> Lệnh nhắc nhở hướng dẫn mô hình đưa ra mô tả ngắn gọn, tổng quát về hình ảnh, nắm bắt nội dung chính mà không cần quá nhiều chi tiết. Ví dụ : “Một phòng khách với một chiếc ghế và một chiếc đèn”
- <DETAILED_CAPTION> Lệnh nhắc nhở hướng dẫn mô hình tạo ra mô tả toàn diện hơn, bao gồm các chi tiết bổ sung về khung cảnh, đối tượng và mối quan hệ giữa chúng. Ví dụ : “Hình ảnh cho thấy một phòng khách với một chiếc ghế, cây cảnh, thảm trải sàn, đèn và bức tường ở phía sau. Căn phòng được chiếu sáng bởi đèn, tạo ra một bầu không khí ấm áp và dễ chịu.”
- <MORE_DETAILED_CAPTION> Lời nhắc hướng dẫn mô hình cung cấp mô tả chi tiết hơn, bao gồm các chi tiết nhỏ và các khía cạnh tinh tế của hình ảnh.
Ví dụ : “Hình ảnh cho thấy một góc phòng với sàn gỗ và tường màu be. Ở phía bên trái của hình ảnh, có một chậu cây lớn với lá xanh và một chậu trắng có một cây nhỏ bên trong. Bên cạnh cây, có hai bàn nhỏ đặt hai chậu cây. Ở giữa phòng là một chiếc ghế bành màu trắng với lưng và tay vịn có đính hạt. Sàn nhà được làm bằng ván gỗ màu sáng và tường được sơn màu be nhạt. Một chiếc đèn sàn có chụp đèn màu trắng được đặt cạnh ghế bành. Một tấm thảm trải sàn màu xám được đặt trên sàn trước ghế. Phong cách tổng thể của không gian là hiện đại và tối giản.
Đầu tiên, hãy sử dụng <CAPTION> gợi ý để lấy chú thích mô tả cho hình ảnh.
# Define the captioning prompt
caption_prompt = "<CAPTION>"
# Prepare inputs for captioning
inputs = processor(text=caption_prompt, images=image, return_tensors="pt").to(device)
# Generate the caption
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=500,
num_beams=3,
do_sample=False,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Extract the generated caption
caption = generated_text.split(caption_prompt)[-1].strip()
print("Generated Caption:", caption)Sẽ tạo ra kết quả đầu ra sau đây.

Sau đó, áp dụng phương pháp Phrase Grounding bằng cách sử dụng <CAPTION_TO_PHRASE_GROUNDING> gợi ý kèm chú thích được tạo ra để xác định và định vị các cụm từ cụ thể trong hình ảnh.
# Define the phrase grounding prompt
grounding_prompt = "<CAPTION_TO_PHRASE_GROUNDING>"
# Prepare inputs for phrase grounding
inputs = processor(text=grounding_prompt + " " + caption, images=image, return_tensors="pt").to(device)
# Generate phrase grounding output
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=512,
num_beams=3,
do_sample=False,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
# Post-process the output
result = processor.post_process_generation(
generated_text,
task=grounding_prompt,
image_size=(image.width, image.height)
)
# Extract bounding boxes and labels
bboxes = result[grounding_prompt]['bboxes']
labels = result[grounding_prompt]['labels']Dưới đây là kết quả sau khi trực quan hóa.

Kết luận
Trong bài viết này, chúng ta đã tìm hiểu phrase grounding là gì, cách thức hoạt động của nó, và xem xét các mô hình cũng như phương pháp chính được sử dụng cho nó. Chúng ta cũng đã thấy cách thực hiện phrase grounding bằng cách sử dụng Grounding DINO và Florence-2.
Phrase grounding rất quan trọng vì nó giúp liên kết ngôn ngữ với hình ảnh. Khả năng này hữu ích trong nhiều lĩnh vực, chẳng hạn như tìm kiếm hình ảnh, tương tác giữa con người và máy tính, hệ thống tự động, và phân tích hình ảnh dựa trên nội dung của chúng. Bằng cách cho phép máy móc hiểu và so khớp ngôn ngữ với nội dung hình ảnh, phrase grounding làm cho các hệ thống AI trở nên chính xác hơn và hiểu bối cảnh tốt hơn, đưa nhận thức của máy gần hơn đến giao tiếp của con người.
Nguồn tham khảo: What is Phrase Grounding?
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam






