
Phát hiện đối tượng là một tác vụ trong thị giác máy tính dùng để nhận diện và xác định vị trí các đối tượng trong ảnh hoặc video. Tác vụ này không chỉ phân loại các đối tượng mà còn xác định chính xác vị trí của chúng thông qua toạ độ của các hộp giới hạn. Thông thường, điều này được thực hiện bằng một mô hình học máy dự đoán đồng thời cả nhãn và hộp giới hạn.
Một trong những mô hình như vậy là RF‑DETR, một mô hình phát hiện đối tượng thời gian thực mã nguồn mở. Đây là mô hình đầu tiên vượt mốc 60 Average Precision (AP) trên bộ dữ liệu chuẩn Microsoft COCO, cho thấy khả năng phát hiện đối tượng chính xác đồng thời sinh ra các hộp giới hạn có độ chuẩn xác cao. RF‑DETR cũng đạt hiệu năng state‑of‑the‑art trên RF100‑VL, một bộ benchmark được thiết kế để đánh giá khả năng thích ứng với dữ liệu thực tế, và liên tục vượt trội so với nhiều mô hình khác trên nhiều bộ đánh giá khác nhau.
RF‑DETR được thiết kế để phát hiện nhanh và chính xác, ngay cả khi tài nguyên tính toán hạn chế hoặc trong các môi trường yêu cầu độ trễ thấp, nhờ đó rất phù hợp để xây dựng các workflow phát hiện đối tượng trong video phục vụ bài toán thực tế. Trong bài viết này, chúng ta sẽ trình bày cách phát hiện đối tượng trong video bằng cách xây dựng một workflow sử dụng RF‑DETR.
>>> Xem thêm:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- Thiết kế website bằng AI (trí tuệ nhân tạo) miễn phí

Cách phát hiện đối tượng trong video bằng RF‑DETR
Chúng ta sẽ sử dụng Roboflow Workflows, một công cụ web để xây dựng ứng dụng AI thị giác, nhằm tạo workflow phát hiện đối tượng trong video dựa trên RF‑DETR.
Roboflow Workflows cho phép chúng ta kết nối nhiều tác vụ thị giác máy tính một cách liền mạch, chẳng hạn như phát hiện đối tượng, trực quan hóa hộp giới hạn và trực quan hóa nhãn , cùng với nhiều tác vụ khác. Mỗi tác vụ được biểu diễn dưới dạng một khối mô-đun dựng sẵn, giúp chúng ta có thể thiết kế và tùy chỉnh workflow trực quan. Bạn có thể chạy workflow này cả trên ảnh tĩnh lẫn video.
>>> Xem thêm các bài viết khác:
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất 2025
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
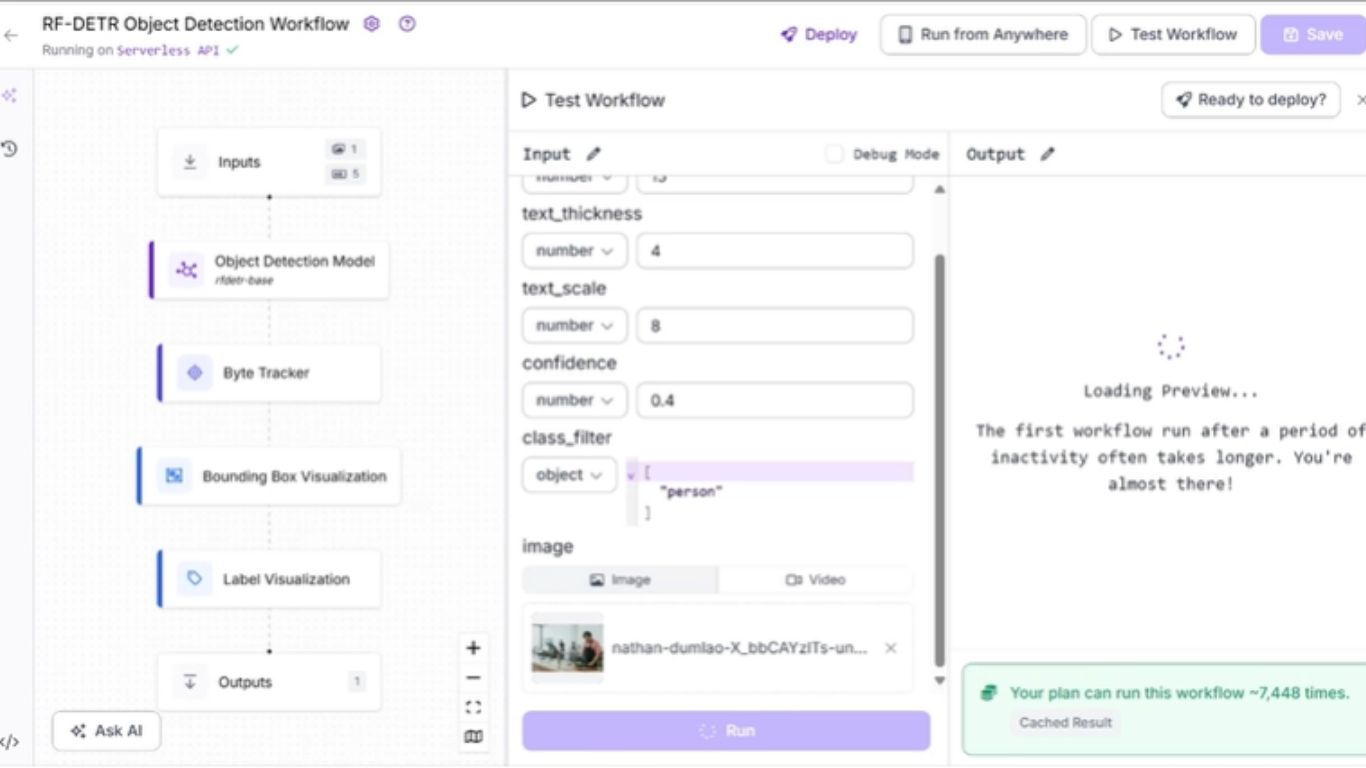
Thiết lập Roboflow Workflow
Đầu tiên, hãy tạo một tài khoản Roboflow miễn phí và đăng nhập. Tiếp theo, tạo một workspace, sau đó nhấp vào mục “Workflows” ở thanh điều hướng bên trái và chọn “Create Workflow”.
Bạn sẽ được đưa tới trình biên tập workflow trống, nơi bạn có thể bắt đầu xây dựng workflow AI của mình. Tại đây, bạn sẽ thấy hai khối workflow: Inputs và Outputs.
>>> Xem thêm:
- TOP 20 công cụ Chat AI tiếng Việt miễn phí thông minh phổ biến
- Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow
Bước 1: Định nghĩa các Input cho Workflow
Chúng ta muốn việc phát hiện đối tượng trong video do workflow thực hiện có thể cấu hình được. Để làm được điều này, ta định nghĩa các tham số đầu vào (input parameters) dùng để điều khiển cách workflow sinh ra đầu ra. Khi đó, workflow sẽ tự động thích ứng dựa trên giá trị được truyền vào cho các tham số này.
Workflow phát hiện đối tượng trong video này bao gồm các tham số đầu vào sau:
- image – Ảnh đầu vào cho tác vụ phát hiện đối tượng. Nếu video được truyền vào workflow, tham số này sẽ đại diện cho từng khung hình (frame) của video. Tham số image được thêm mặc định trong mọi workflow của Roboflow.
- class_filter – Xác định các đối tượng cần phát hiện, được cung cấp dưới dạng danh sách. Danh sách này có thể chỉ gồm một lớp COCO hoặc nhiều lớp, hoặc toàn bộ các lớp COCO nếu để danh sách rỗng.
- confidence – Thiết lập ngưỡng tin cậy tối thiểu để chấp nhận một phát hiện.
- text_scale – Điều chỉnh kích thước chữ của nhãn hiển thị.
- text_thickness – Điều chỉnh độ đậm của chữ hiển thị nhãn.
- bounding_box_thickness – Điều chỉnh độ dày của viền hộp giới hạn.
Để thêm các tham số này, chọn khối Inputs và nhấn “Add Parameter”. Mỗi tham số cần có một kiểu dữ liệu (type) và có thể khai báo thêm giá trị mặc định (default value).
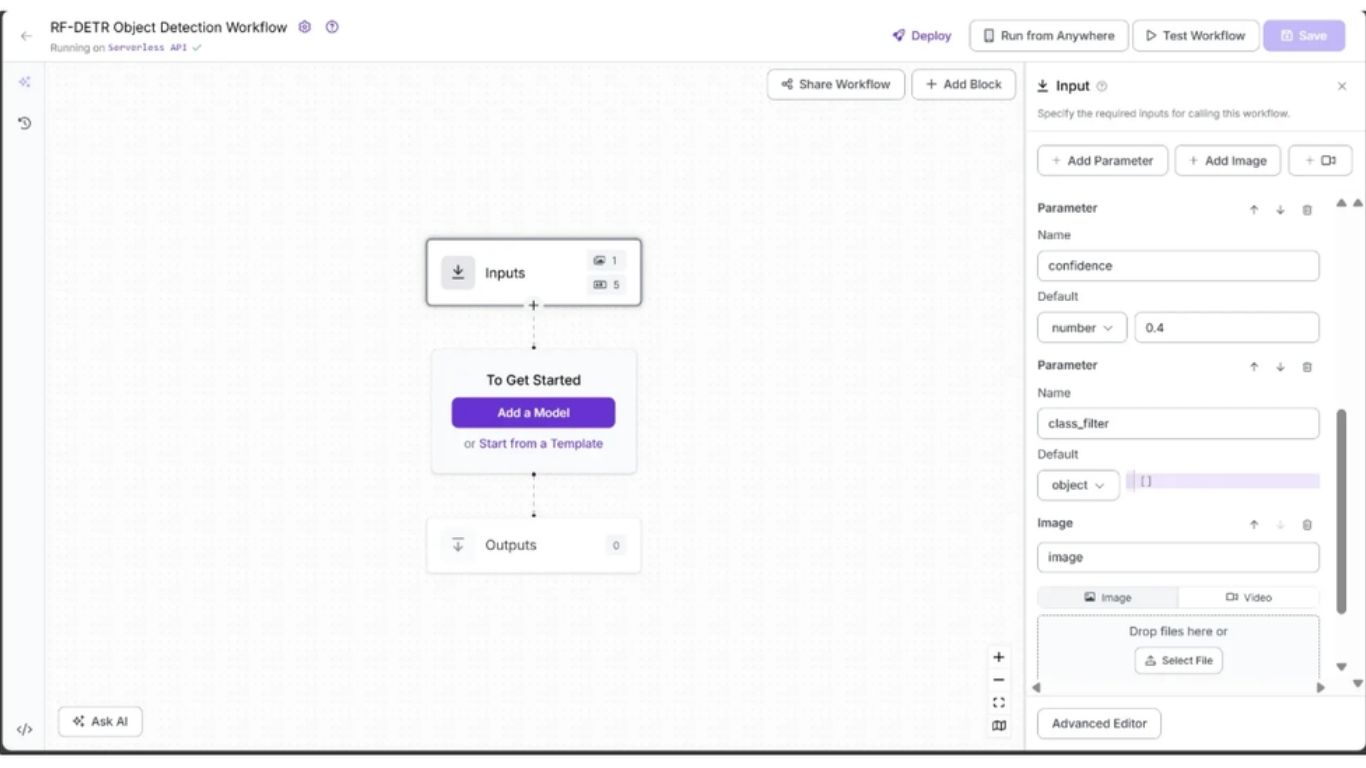
Hình minh họa cho thấy ba input của workflow: tham số image (được thêm mặc định), tham số confidence (kiểu số – numeric) với giá trị mặc định 0.4, và tham số class_filter (kiểu object) với giá trị mặc định là một danh sách rỗng.
>>> Xem thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Các mô hình phát hiện đối tượng tốt nhất
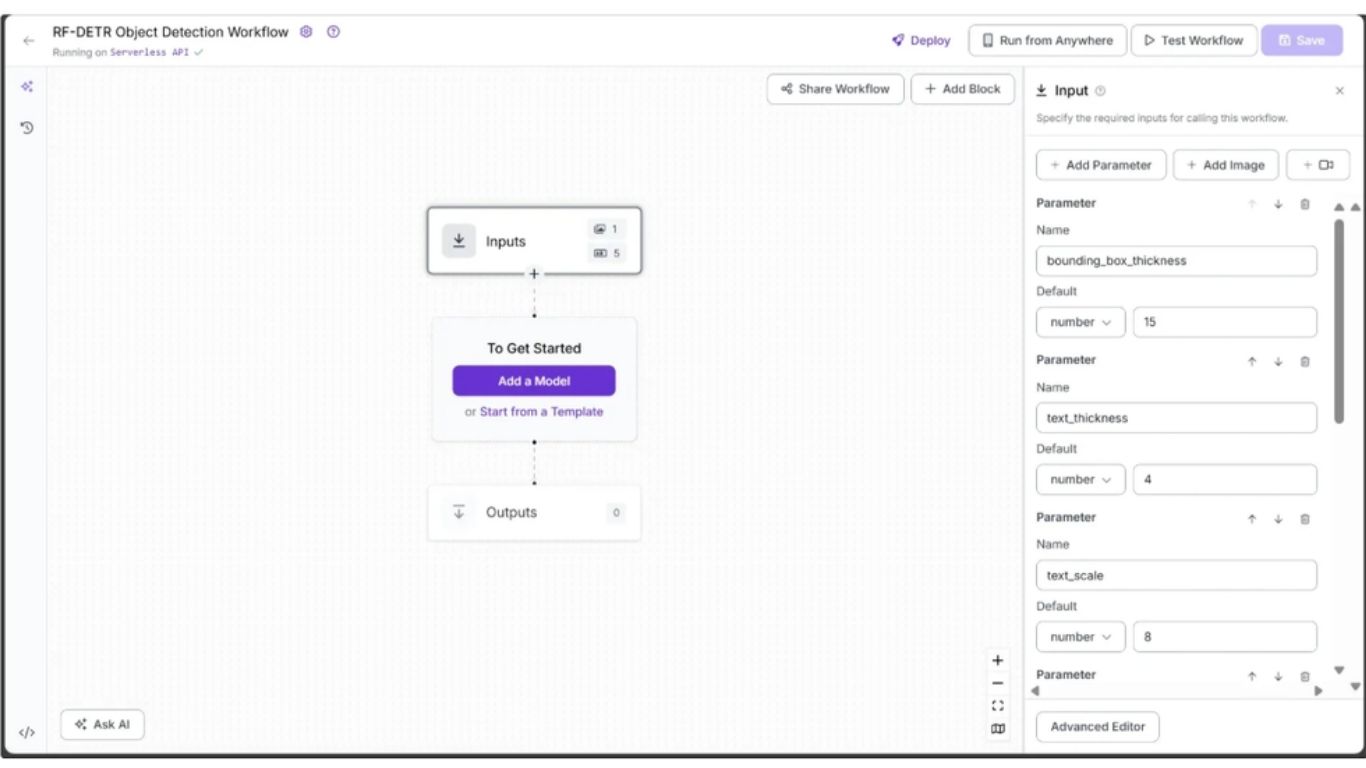
Hình tiếp theo thể hiện các input còn lại của workflow, tất cả đều là kiểu số: text_scale với giá trị mặc định 8, text_thickness với giá trị mặc định 4, và bounding_box_thickness với giá trị mặc định 15.
Toàn bộ các tham số trên sẽ được sử dụng làm input cho nhiều khối khác nhau trong workflow, nhằm điều khiển kết quả phát hiện đối tượng trong video.
Bước 2: Thêm khối Object Detection Model
Tiếp theo, chúng ta sẽ bổ sung khả năng phát hiện đối tượng cho workflow bằng cách sử dụng khối Object Detection Model. Khối workflow này trong Roboflow cho phép chúng ta sử dụng RF‑DETR để phát hiện đối tượng.
Để thêm khối, hãy nhấp vào “Add a Model”, sau đó chọn tùy chọn “Public Models”. Lúc này Roboflow sẽ hiển thị tất cả các mô hình phát hiện đối tượng có sẵn; trong đó, hãy nhấp chọn RF‑DETR.
>>> Xem thêm:
- TOP 20 công cụ Chat AI tiếng Việt miễn phí thông minh phổ biến
- Cách sử dụng AI trong phát triển phần mềm như thế nào?
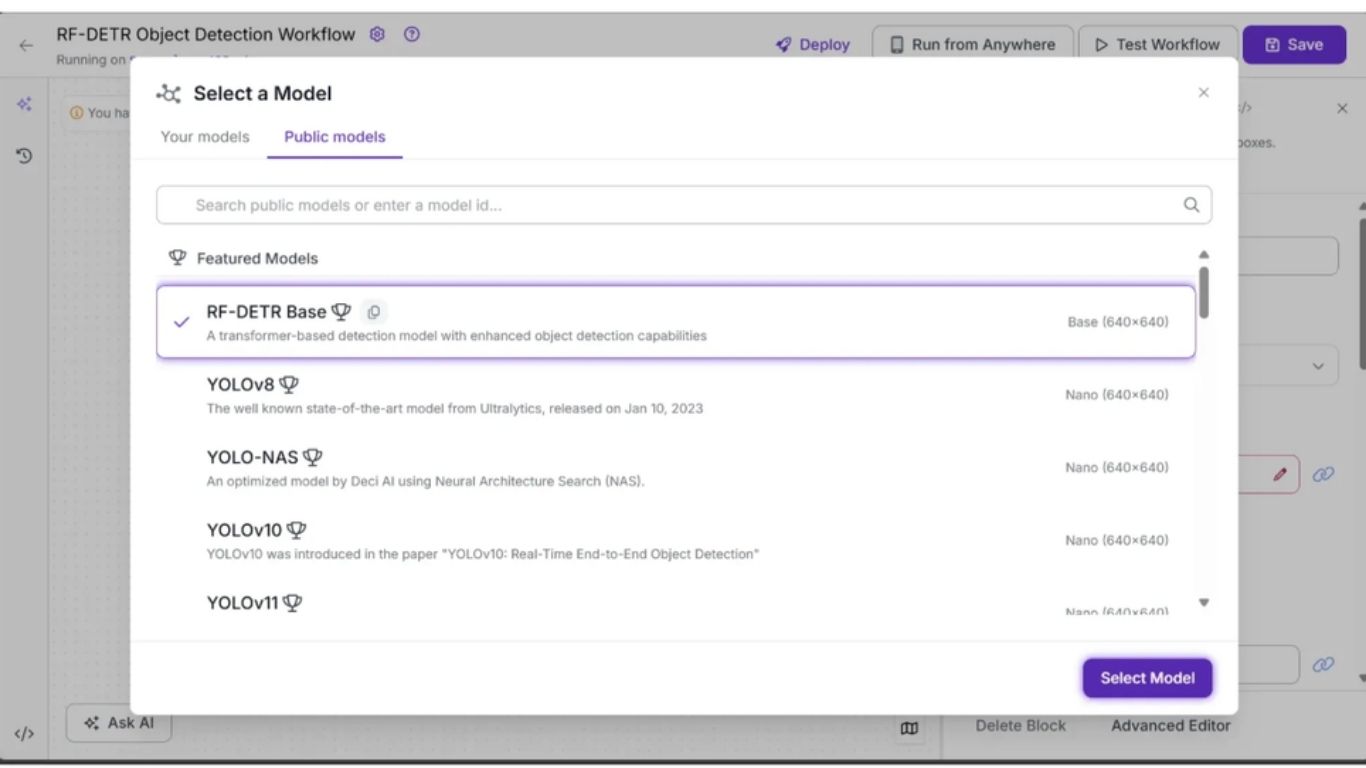
Tiếp theo, cấu hình khối Object Detection Model để sử dụng một số tham số từ khối Inputs như image, confidence và class_filter.
Để làm điều này, mở tab Configure của khối Object Detection Model, nhấp vào biểu tượng liên kết 🔗 bên cạnh từng tham số và chọn giá trị input tương ứng.

Cụ thể, trong tab Configure, các trường Image, Confidence và Class Filter cần được liên kết lần lượt với các tham số image, confidence và class_filter từ khối Inputs. Bạn có thể giữ nguyên các tham số còn lại ở giá trị mặc định.
Bước 3: Bật tính năng Tracking đối tượng giữa các khung hình video
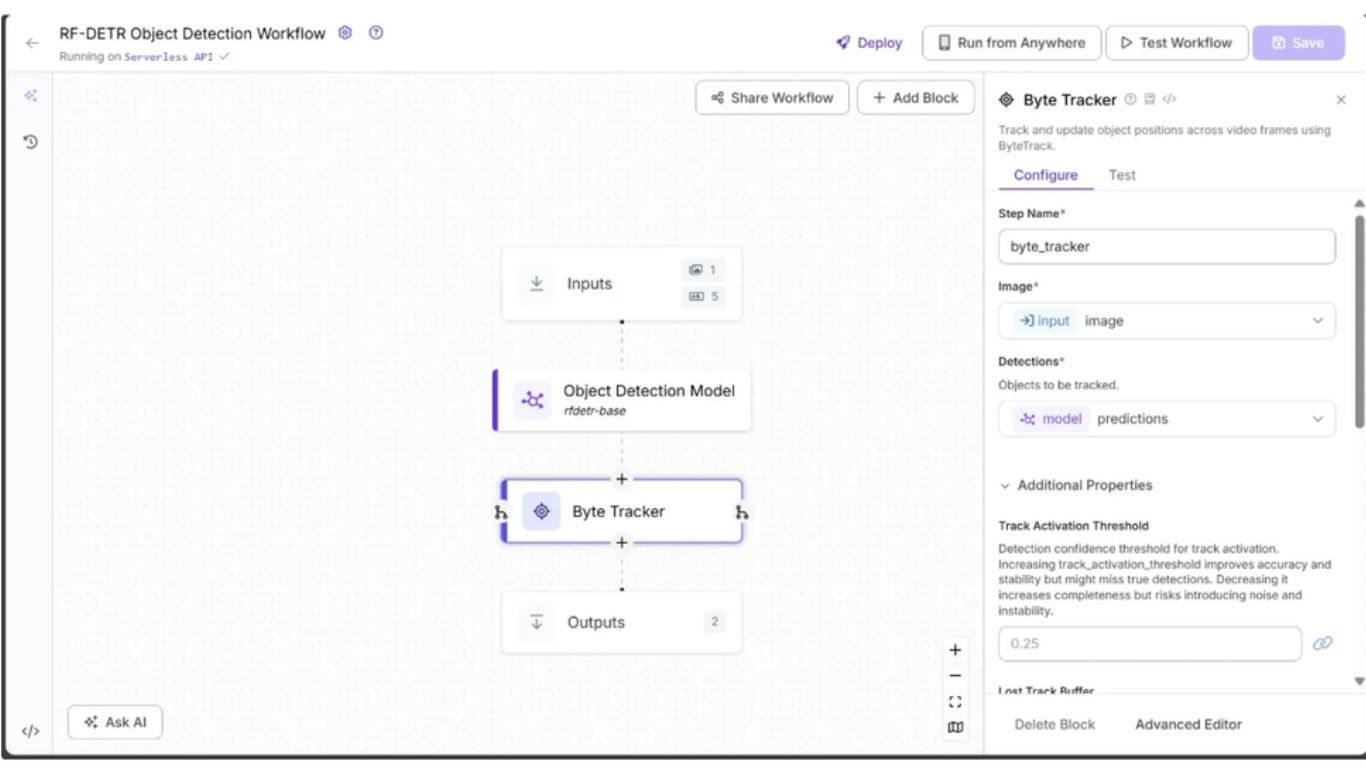
Để có thể theo dõi đối tượng xuyên suốt các khung hình video dựa trên kết quả dự đoán từ khối Object Detection Model, chúng ta thêm khối Byte Tracker vào workflow.
Khối này nhận đầu vào là các detection và các khung hình video tương ứng, sau đó khởi tạo bộ theo dõi cho từng detection. Bạn có thể cấu hình các tham số như ngưỡng kích hoạt track, bộ đệm cho track bị mất, ngưỡng khớp tối thiểu và tốc độ khung hình để điều khiển hành vi tracking.
Để thêm Byte Tracker, hãy di chuột lên khối Object Detection Model, nhấp vào biểu tượng dấu + xuất hiện bên dưới, sau đó tìm “Byte Tracker” và chèn khối này vào workflow. Sau khi thêm, workflow phát hiện đối tượng trong video của bạn sẽ trông như sau:
>>> Xem thêm:
- TOP 25 công cụ AI miễn phí, phổ biến, tốt nhất hiện nay
- Cách ứng dụng AI tối ưu trải nghiệm khách hàng
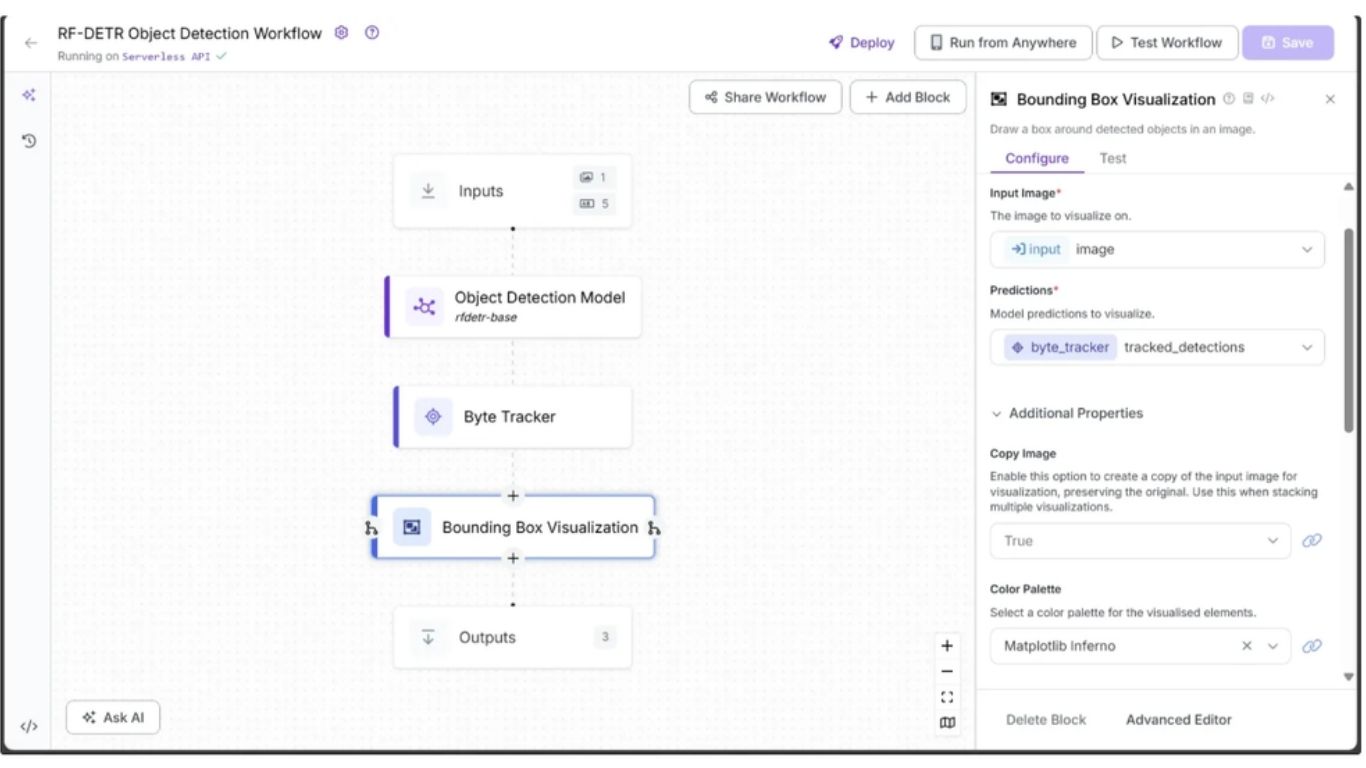
Bước 4: Trực quan hóa dự đoán bằng Bounding Box
Khối Object Detection Model trả về các đối tượng dự đoán (prediction objects). Các đối tượng này có thể được trực quan hóa thành các hộp giới hạn (bounding boxes) trên ảnh bằng khối Bounding Box Visualization.
Để thêm khối này, di chuột lên khối Object Detection Model, nhấn biểu tượng dấu +, tìm “Bounding Box Visualization” và thêm vào workflow.
Trong tab Configure, liên kết trường Image với tham số image từ khối Inputs và liên kết trường Predictions với output tracked_detections từ khối Byte Tracker. Chọn một Color Palette cho các bounding box; trong workflow này, chúng ta sử dụng bảng màu ‘Matplotlib Inferno’ như trong hình minh họa.
>>> Xem thêm:
- Các Mô Hình Ngôn Ngữ Thị Giác Chạy Cục Bộ Tốt Nhất
- 18 cách ứng dụng AI cho ecommerce đạt hiệu quả cao
Cuối cùng, liên kết tham số Thickness với input bounding_box_thickness từ khối Inputs như hình dưới.
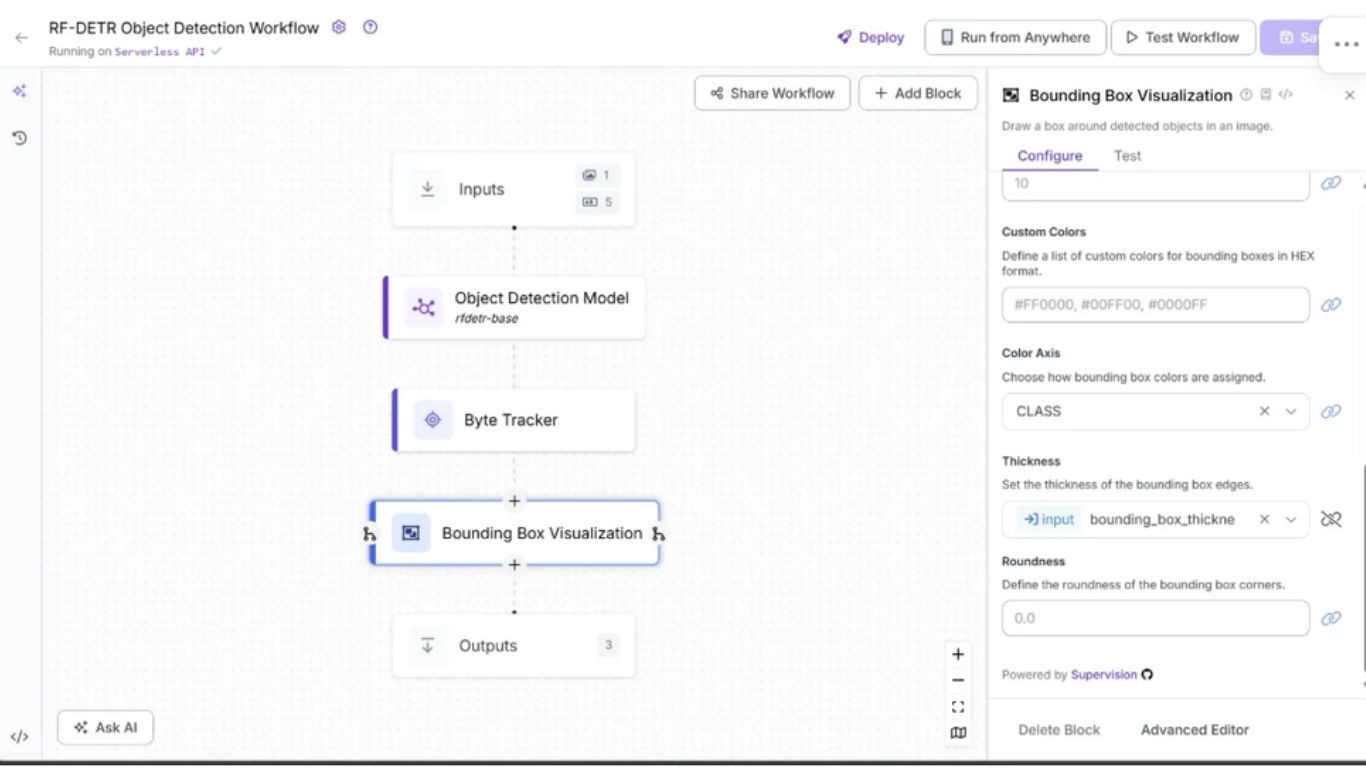
Bạn có thể giữ nguyên các tham số còn lại ở giá trị mặc định.
Bước 5: Thêm nhãn cho Bounding Box
Mỗi bounding box đại diện cho một đối tượng, vì vậy cần có nhãn để thể hiện lớp của đối tượng đó. Khối Label Visualization đảm nhiệm việc này và cho phép bạn cấu hình phong cách hiển thị thông qua nhiều tham số khác nhau.
Để thêm khối, di chuột lên khối Bounding Box Visualization, nhấn biểu tượng dấu +, tìm “Label Visualization” và thêm vào workflow.
Trong tab Configure, liên kết trường Image với output image từ khối Bounding Box Visualization và trường Predictions với output tracked_detections từ khối Byte Tracker. Chọn một bảng màu cho nhãn; trong workflow này, chúng ta dùng ‘Matplotlib Pastel2’.
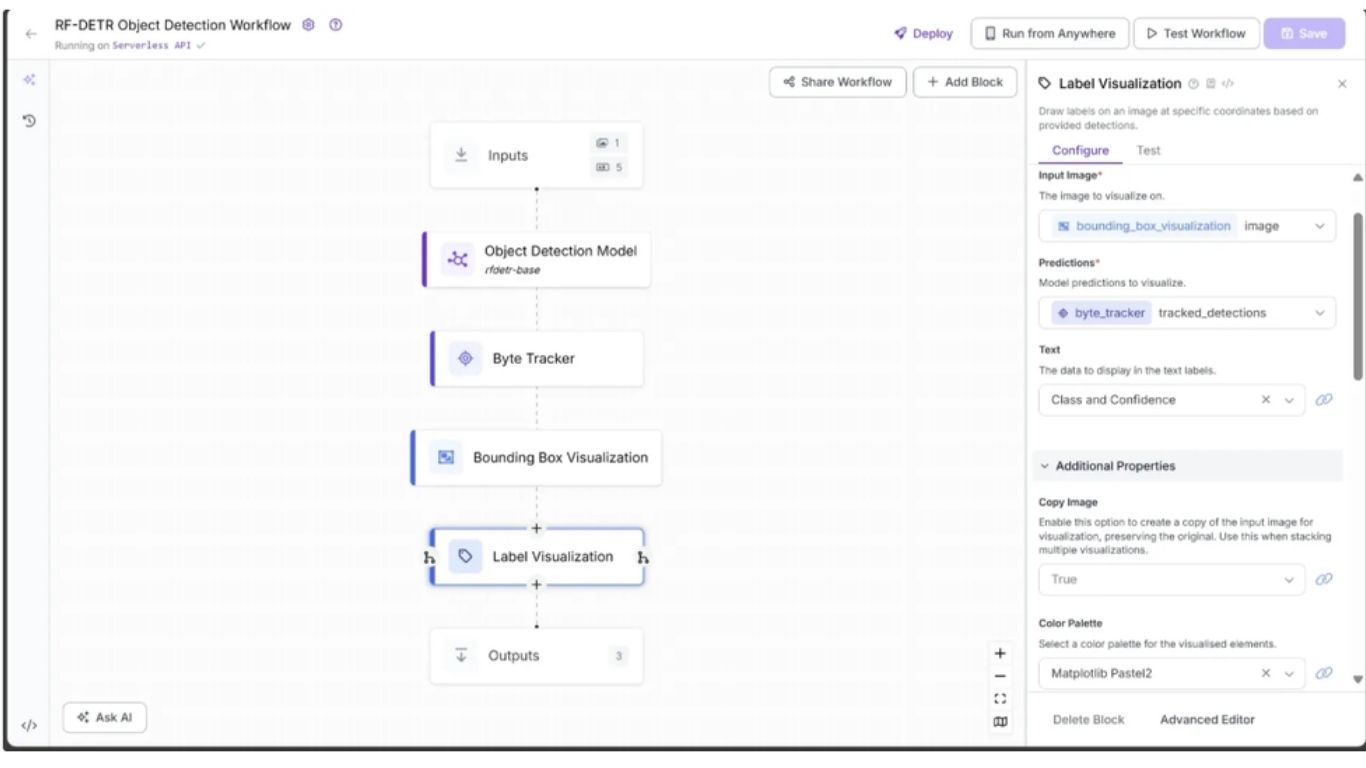
Cuối cùng, liên kết tham số Text Scale với input text_scale từ khối Inputs và tham số Text Thickness với input text_thickness. Bạn cũng có thể chỉ định Text Color và chọn Text Position như minh họa. Bạn có thể để các tham số khác ở giá trị mặc định.
Bước 6: Định nghĩa Output cho Workflow
Sau khi đã thêm đầy đủ các khối, workflow phát hiện đối tượng trong video đã hoàn chỉnh và chúng ta có thể định nghĩa các output mong muốn. Để làm điều này, chọn khối Outputs, mở tab Configure và nhấp “Add Output”. Xóa các output không cần dùng bằng biểu tượng thùng rác.

Đảm bảo rằng label_visualization được đặt làm output của workflow và được liên kết với trường image của khối Label Visualization – đây chính là ảnh kết quả cuối cùng thể hiện việc phát hiện đối tượng trong video.
Bước 7: Chạy Workflow
Bạn có thể chạy workflow trực tiếp từ giao diện người dùng, thông qua API, dòng lệnh hoặc các phương thức được hỗ trợ khác. Để xem mã nguồn cho từng cách chạy, hãy nhấp nút “Deploy” ở góc trên bên phải workflow.
Trong ví dụ này, chúng ta sẽ chạy workflow bằng Python. Trước hết, cài đặt package cần thiết trong môi trường Python:
pip install inference
Đoạn script dưới đây là một phiên bản đã được chỉnh sửa từ script Python dùng để deploy có sẵn trong mục “Deploy” rồi chọn “Video”. Phần chỉnh sửa cho phép script tự động điều chỉnh kích thước chữ và độ dày bounding box dựa trên độ phân giải video để truyền vào các tham số workflow, đồng thời thực hiện phát hiện đối tượng trong video trên một video kiểm thử:
from inference import InferencePipeline
from supervision.draw.utils import calculate_optimal_line_thickness, calculate_optimal_text_scale
import cv2
def my_sink(result, video_frame):
if result.get("label_visualization"): # Display a frame from the workflow response
cv2.imshow("Workflow frame", result["label_visualization"].numpy_image)
cv2.waitKey(1)
print(result) # do something with the predictions of each frame
# Function to dynamically get video resolution
def get_video_resolution(video_path):
cap = cv2.VideoCapture(video_path)
ret, frame = cap.read()
cap.release()
height, width = frame.shape[:2]
return (width, height)
video_path = "video.mp4"
resolution = get_video_resolution(video_path)
# Initialize a pipeline object
pipeline = InferencePipeline.init_with_workflow(
api_key="YOUR_ROBOFLOW_KEY",
workspace_name="YOUR_ROBOFLOW_WORKSPACE",
workflow_id="YOUR_ROBOFLOW_OBJECT_DETECTION_WORKFLOW",
video_reference=video_path, # Path to video, device id (int, usually 0 for built in webcams), or RTSP stream url
max_fps=30,
on_prediction=my_sink,
workflows_parameters={
"bounding_box_thickness": calculate_optimal_line_thickness(resolution),
"text_thickness": 1,
"text_scale": 1.1 * calculate_optimal_text_scale(resolution),
"confidence": 0.1,
"class_filter": ["car"]
}
)
pipeline.start() # start the pipeline
pipeline.join() # wait for the pipeline thread to finishTrong đoạn script trên, hãy thay YOUR_ROBOFLOW_KEY, YOUR_ROBOFLOW_WORKSPACE và YOUR_ROBOFLOW_OBJECT_DETECTION_WORKFLOW bằng các giá trị tương ứng lấy từ script Python trong mục “Deploy”. Khóa API Roboflow ẩn trong script deploy sẽ hiển thị khi bạn dán script vào một file cục bộ.
Bước 8: Ghép các khung hình đã trực quan hóa thành video
Giờ đây bạn có thể biên dịch các khung hình đã được workflow tạo ra để tạo thành một video cuối cùng, trong đó các đối tượng được tô sáng rõ ràng.
Đoạn script sau thực hiện việc này bằng cách lưu từng khung hình có trực quan hóa phát hiện đối tượng vào một thư mục tạm, sau đó ghép tất cả các khung hình đó lại với nhau theo đúng tốc độ khung hình của video gốc. Kết quả là một video phát hiện đối tượng trong video mượt mà, sẵn sàng để xem lại hoặc phục vụ phân tích sâu hơn.
from inference import InferencePipeline
from supervision.draw.utils import calculate_optimal_line_thickness, calculate_optimal_text_scale
import cv2
import os
import shutil
# Frame counter
frame_count = 0
def my_sink(result, video_frame):
global frame_count
if result.get("label_visualization"): # Save an frame from the workflow response
frame = result["label_visualization"].numpy_image
frame_path = os.path.join(temp_dir, f"frame_{frame_count:06d}.jpg")
cv2.imwrite(frame_path, frame)
frame_count += 1
print(result) # do something with the predictions of each frame
# Function to dynamically get video resolution
def get_video_resolution(video_path):
cap = cv2.VideoCapture(video_path)
ret, frame = cap.read()
cap.release()
height, width = frame.shape[:2]
return (width, height)
# Function to dynamically get video fps
def get_video_fps(video_path):
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
cap.release()
return fps
video_path = "video.mp4"
resolution = get_video_resolution(video_path)
fps = get_video_fps(video_path)
temp_dir = "temp_frames"
output_path = "object_detected_video.mp4"
# Ensure temp folder exists
os.makedirs(temp_dir, exist_ok=True)
# Initialize a pipeline object
pipeline = InferencePipeline.init_with_workflow(
api_key="YOUR_ROBOFLOW_KEY",
workspace_name="YOUR_ROBOFLOW_WORKSPACE",
workflow_id="YOUR_ROBOFLOW_OBJECT_DETECTION_WORKFLOW",
video_reference=video_path, # Path to video, device id (int, usually 0 for built in webcams), or RTSP stream url
max_fps=30,
on_prediction=my_sink,
workflows_parameters={
"bounding_box_thickness": calculate_optimal_line_thickness(resolution),
"text_thickness": 1,
"text_scale": 1.1 * calculate_optimal_text_scale(resolution),
"confidence": 0.1,
"class_filter": ["car"]
}
)
pipeline.start() # start the pipeline
pipeline.join() # wait for the pipeline thread to finish
# Prepare the final video writer to compile all frames
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
writer = cv2.VideoWriter(output_path, fourcc, fps, resolution)
# Loop through all saved frames and write them to the video
for i in range(frame_count):
frame_path = os.path.join(temp_dir, f"frame_{i:06d}.jpg")
frame = cv2.imread(frame_path)
writer.write(frame)
# Release the video writer
writer.release()
# Clean up temporary frames
shutil.rmtree(temp_dir)
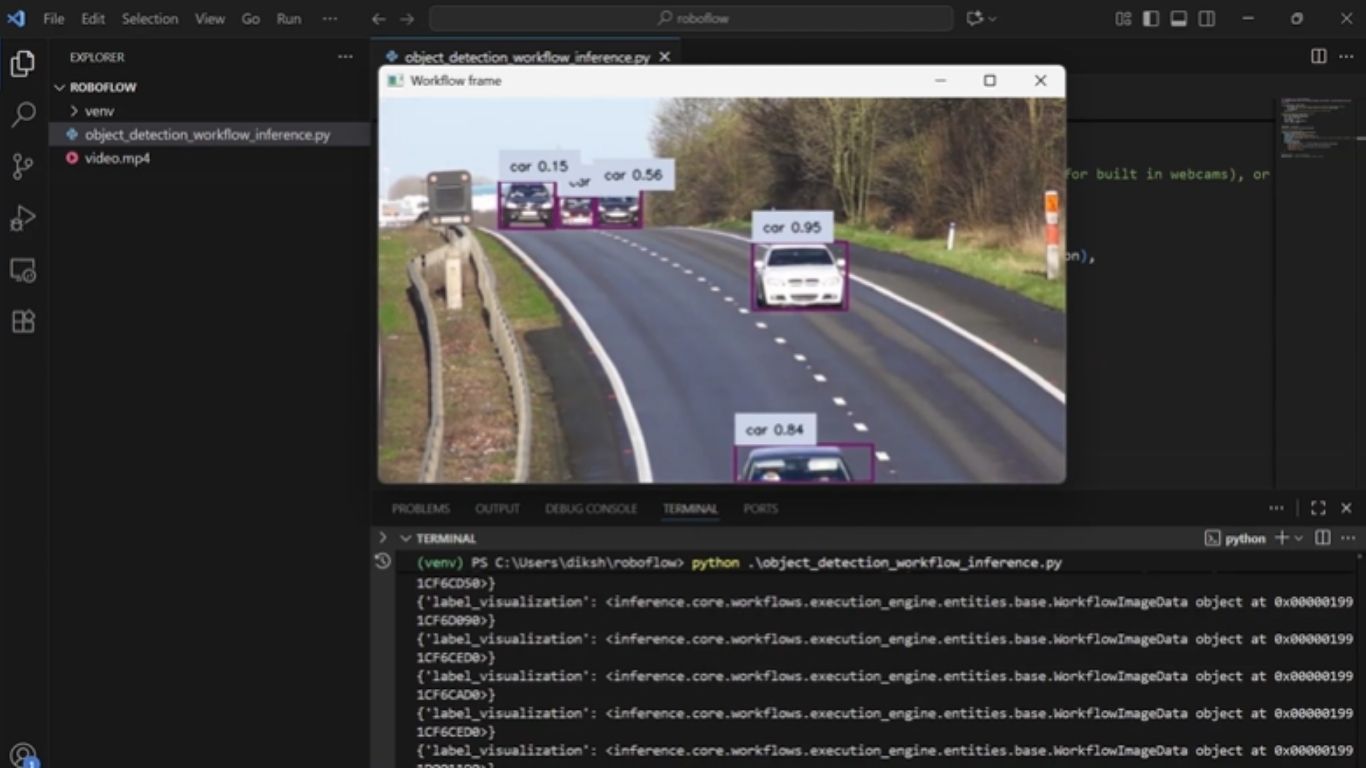
print(f"Final video saved at {output_path}")Khi chạy script trên với video mẫu ở chất lượng SD, chúng ta quan sát thấy tất cả ô tô trong video đều được phát hiện, và workflow phát hiện đối tượng trong video đã xử lý tốt khi bỏ qua một chiếc xe máy chỉ xuất hiện thoáng qua ở giây thứ 0:36. Kết quả được minh họa như dưới đây.
Trong video này, mô hình liên tục phát hiện từng chiếc xe, đạt độ chính xác cao hơn khi xe ở gần camera và thấp hơn khi xe ở xa.
Các ứng dụng thực tế của phát hiện đối tượng trong video
- Phát hiện người đi bộ, phương tiện và chướng ngại vật trong hệ thống lái xe tự hành.
- Giám sát không gian công cộng phục vụ an ninh và quan sát.
- Phát hiện lỗi hoặc bất thường trong dây chuyền sản xuất và kiểm soát chất lượng.
- Theo dõi đối tượng và vận động viên trong phân tích thể thao.
- Bảo tồn động vật hoang dã và giám sát môi trường.
>>> Xem thêm: Hướng dẫn cách sử dụng Google AI Studio hiệu quả, nhanh chóng
Nâng cao độ chính xác của phát hiện đối tượng với Segmentation sử dụng RF‑DETR Seg
Phát hiện đối tượng chỉ ra các đối tượng trong một ảnh hoặc một khung hình video và cung cấp các bounding box bao quanh chúng. Tuy nhiên, trong một số ứng dụng như chẩn đoán hình ảnh y khoa, ảnh vệ tinh hoặc chỉnh sửa ảnh chi tiết, người ta cần độ chính xác cao hơn ở mức pixel. Đây là lúc phân đoạn đối tượng (object segmentation) trở nên cần thiết.
Phân đoạn đối tượng giúp máy tính vẽ chính xác đường viền và hình dạng của từng đối tượng trong ảnh, thu được các đường bao chi tiết thay vì chỉ là các hộp giới hạn đơn giản.

Giống như phát hiện đối tượng trong video, segmentation cũng được thực hiện nhờ các mô hình học máy dự đoán cả nhãn lẫn biên giới chính xác cho từng đối tượng.
Một trong những mô hình phân đoạn đối tượng như vậy là RF‑DETR Seg. RF‑DETR Seg (Preview) nhanh gấp ba lần và chính xác hơn mô hình phân đoạn lớn nhất hiện tại là YOLO11 khi được đánh giá trên bộ Microsoft COCO Segmentation, qua đó thiết lập kỷ lục state‑of‑the‑art (SOTA) thời gian thực mới cho bộ đánh giá chuẩn của ngành này.
RF‑DETR Seg cho phép chúng ta tạo các mặt nạ ảnh (image masks), từ đó thực hiện phân đoạn đối tượng chính xác phục vụ các tác vụ như chỉnh sửa ảnh, phân tích y khoa, AR/VR, theo dõi đối tượng và huấn luyện mô hình học máy.
Kết luận về phát hiện đối tượng trong video
Trong bài viết này, chúng ta đã minh họa cách RF‑DETR mang lại khả năng phát hiện đối tượng trong video với độ chính xác cao, cung cấp các bounding box chi tiết cho từng đối tượng. Khi kết hợp với Roboflow Workflows, bạn có thể dễ dàng thiết kế, cấu hình và triển khai các workflow có khả năng phát hiện, gán nhãn và theo dõi đối tượng một cách liền mạch.
Đối với các ứng dụng đòi hỏi độ chính xác cao hơn nữa, RF‑DETR Seg mang đến phân đoạn đối tượng ở mức pixel, mở ra nhiều khả năng nâng cao trong chỉnh sửa hình ảnh, chẩn đoán hình ảnh y khoa và các dự án AR/VR.
Với các khối xây dựng mô-đun và hệ thống workflow linh hoạt của Roboflow, việc tạo ra các giải pháp thị giác máy tính ứng dụng AI đặc biệt cho các bài toán phát hiện đối tượng trong video chưa bao giờ dễ dàng đến thế.
Nguồn tham khảo: Video Object Detection with RF-DETR
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Hoàng Diệu, Phường 12, Quận 4, Thành phố Hồ Chí Minh, Việt Nam







