
Thị giác máy tính (Computer Vision – CV) là một lĩnh vực của trí tuệ nhân tạo và khoa học máy tính, tập trung vào việc giúp máy tính có thể “nhìn”, diễn giải và hiểu thông tin trực quan từ thế giới, tương tự như cách con người sử dụng mắt và não bộ để hiểu hình ảnh và video.
Về bản chất, nhiệm vụ của thị giác máy tính bao gồm việc phân tích và xử lý hình ảnh hoặc luồng video nhằm trích xuất thông tin có ý nghĩa, chẳng hạn như nhận diện vật thể, phát hiện chuyển động, nhận dạng khuôn mặt, đọc văn bản hoặc hiểu bối cảnh của một khung cảnh.
Trong bài viết này, chúng tôi khám phá các nhiệm vụ chính của thị giác máy tính, bao gồm: phát hiện đối tượng (object detection), phân loại hình ảnh (image classification), phân đoạn hình ảnh (image segmentation), phân tích đa phương thức (multimodal analysis), ước lượng điểm đặc trưng (keypoint estimation), ước lượng độ sâu (depth estimation) và nhận dạng ký tự quang học (optical character recognition). Đồng thời, bài viết cũng minh họa cách bạn có thể dễ dàng thực hiện các nhiệm vụ này bằng Roboflow Workflows.
>>> Xem thêm:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Vertex AI là gì? Nền tảng học máy của Google Cloud
- 18 cách ứng dụng AI cho ecommerce đạt hiệu quả cao
Roboflow Workflows là gì?
Roboflow Workflows là một nền tảng mã thấp (low-code), mã nguồn mở, giúp đơn giản hóa quá trình xây dựng và triển khai các ứng dụng AI thị giác. Với Workflows, bạn có thể thiết kế trực quan các pipeline thị giác máy tính bằng cách kết nối nhiều nhiệm vụ khác nhau thành các khối mô-đun. Video bên dưới minh họa tất cả các khối có thể được thêm vào một workflow của Roboflow:
Khả năng của Roboflow Workflows
- Thiết kế pipeline trực quan với các nhiệm vụ dễ tìm kiếm và dễ kéo thả
- Kết nối nhiều nhiệm vụ thị giác máy tính dưới dạng các khối mô-đun
- Mã thấp, có thể tùy chỉnh và hỗ trợ tích hợp Python khi cần
- Tích hợp sẵn các khối tiền xử lý, hậu xử lý và trực quan hóa
- Xử lý hình ảnh và luồng video theo thời gian thực
- Mã nguồn mở, có thể mở rộng với các mô hình tùy chỉnh
- Triển khai linh hoạt trên thiết bị cục bộ, đám mây hoặc thiết bị biên (edge)
- Giám sát và gỡ lỗi với các đầu ra trung gian
- Hỗ trợ cộng tác và chia sẻ workflow
Ví dụ về một Roboflow Workflow
Ví dụ bên dưới minh họa một Roboflow Workflow kết hợp các khối Object Detection và Image Segmentation (sử dụng mô hình Segment Anything 2), cùng với các khối khác của Roboflow, nhằm làm mờ nền của một hình ảnh:
Bạn có thể thử workflow cụ thể này tại đây.
Khám phá các nhiệm vụ chính của thị giác máy tính
Dưới đây là các nhiệm vụ quan trọng của thị giác máy tính được thực hiện bằng Roboflow Workflows.
Phát hiện đối tượng
Phát hiện đối tượng là một nhiệm vụ của thị giác máy tính tập trung vào việc xác định và định vị các đối tượng trong hình ảnh hoặc video. Nhiệm vụ này không chỉ phân loại các đối tượng xuất hiện mà còn xác định chính xác vị trí của chúng.
Thông thường, phát hiện đối tượng dựa trên một mô hình học máy để dự đoán tọa độ bounding box và nhãn cho các đối tượng. Mô hình này có thể nhận diện nhiều đối tượng khác nhau trong cùng một hình ảnh hoặc khung hình.
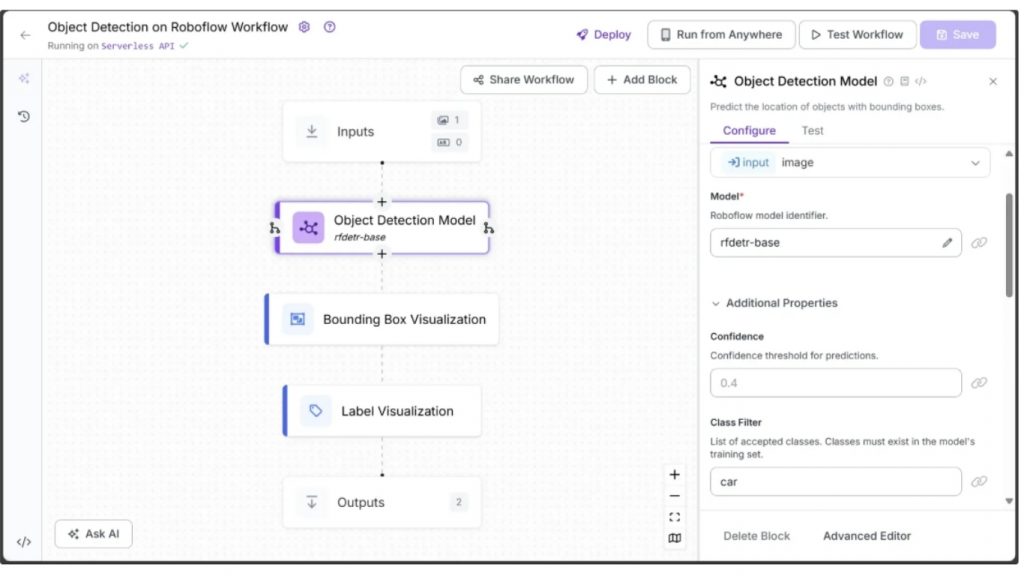
Roboflow Workflow bên dưới minh họa RF-DETR, một mô hình phát hiện đối tượng thời gian thực dựa trên transformer, đang phát hiện một “car” trong hình ảnh.
Workflow phát hiện đối tượng cũng tích hợp các khối trực quan hóa, sử dụng Bounding Box Visualization để vẽ khung bao và Label Visualization để hiển thị nhãn đối tượng cùng với điểm tin cậy:
Trong kết quả đầu ra ở trên, mô hình phát hiện đối tượng chỉ phát hiện một chiếc xe, do “car” là lớp duy nhất được chỉ định trong tham số Class Filter của RF-DETR. Tham số này, có trong nhiều mô hình phát hiện đối tượng như RF-DETR và các biến thể của YOLO, kiểm soát các đối tượng mà mô hình sẽ phát hiện trong quá trình suy luận (inference).
Class Filter có thể được thiết lập:
- Chỉ một lớp
- Một danh sách các lớp
- Hoặc để trống để phát hiện tất cả các lớp
Tất cả các lớp được chỉ định phải thuộc tập lớp của COCO dataset.
- Nếu cung cấp một lớp duy nhất từ COCO dataset, chỉ các đối tượng thuộc lớp đó được phát hiện.
- Nếu không chỉ định lớp nào, tất cả các đối tượng trong hình ảnh thuộc COCO dataset sẽ được phát hiện.
- Nếu cung cấp một danh sách các lớp COCO, chỉ các đối tượng thuộc những lớp đó mới được nhận diện.
Bạn cũng có thể huấn luyện các mô hình phát hiện đối tượng như RF-DETR và YOLO trên dataset tùy chỉnh để phát hiện các đối tượng ngoài các lớp COCO được định nghĩa sẵn. Một bài viết hướng dẫn cách huấn luyện RF-DETR trên dataset tùy chỉnh, trong khi một bài viết khác trình bày cách huấn luyện YOLO với dữ liệu riêng.
Ngoài ra, Roboflow Workflows còn cung cấp nhiều mô hình phát hiện đối tượng khác nhau, cho phép bạn lựa chọn mô hình phù hợp nhất với từng trường hợp sử dụng và chuyên môn cụ thể.
>>> Xem thêm các bài viết khác:
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất 2025
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất

Trong kết quả đầu ra ở trên, mô hình phát hiện đối tượng chỉ phát hiện một chiếc xe, do “car” là lớp duy nhất được chỉ định trong tham số Class Filter của RF-DETR. Tham số này, có trong nhiều mô hình phát hiện đối tượng như RF-DETR và các biến thể của YOLO, kiểm soát các đối tượng mà mô hình sẽ phát hiện trong quá trình suy luận (inference).
Class Filter có thể được thiết lập:
- Chỉ một lớp
- Một danh sách các lớp
- Hoặc để trống để phát hiện tất cả các lớp
Tất cả các lớp được chỉ định phải thuộc tập lớp của COCO dataset.
- Nếu cung cấp một lớp duy nhất từ COCO dataset, chỉ các đối tượng thuộc lớp đó được phát hiện.
- Nếu không chỉ định lớp nào, tất cả các đối tượng trong hình ảnh thuộc COCO dataset sẽ được phát hiện.
- Nếu cung cấp một danh sách các lớp COCO, chỉ các đối tượng thuộc những lớp đó mới được nhận diện.
Bạn cũng có thể huấn luyện các mô hình phát hiện đối tượng như RF-DETR và YOLO trên dataset tùy chỉnh để phát hiện các đối tượng ngoài các lớp COCO được định nghĩa sẵn. Một bài viết hướng dẫn cách huấn luyện RF-DETR trên dataset tùy chỉnh, trong khi một bài viết khác trình bày cách huấn luyện YOLO với dữ liệu riêng.
Ngoài ra, Roboflow Workflows còn cung cấp nhiều mô hình phát hiện đối tượng khác nhau, cho phép bạn lựa chọn mô hình phù hợp nhất với từng trường hợp sử dụng và chuyên môn cụ thể.
Các trường hợp sử dụng của phát hiện đối tượng
- Phát hiện người đi bộ, phương tiện và chướng ngại vật trong xe tự hành
- Giám sát không gian công cộng cho mục đích an ninh và giám sát
- Phát hiện lỗi hoặc bất thường trong sản xuất và kiểm soát chất lượng
- Xác định khối u hoặc các bất thường trong hình ảnh y tế
- Theo dõi đối tượng và vận động viên trong phân tích thể thao
Phân loại hình ảnh
Phân loại hình ảnh là một nhiệm vụ của thị giác máy tính trong đó mô hình được huấn luyện để gán một nhãn hoặc danh mục cho toàn bộ hình ảnh. Khác với phát hiện đối tượng – nơi xác định vị trí của đối tượng trong ảnh (bằng bounding box) – phân loại hình ảnh chỉ tập trung vào việc xác định nội dung có trong ảnh.
Phân loại hình ảnh có thể là:
- Single-label: mỗi hình ảnh chỉ thuộc một danh mục
- Multi-label: một hình ảnh có thể thuộc nhiều danh mục cùng lúc
Roboflow Workflows cung cấp các block cho cả phân loại single-label và multi-label.
Phân loại đơn nhãn
Roboflow Workflow bên dưới minh họa việc sử dụng một mô hình phân loại single-label đã được huấn luyện sẵn từ Roboflow Universe, có tên bird-species-detector/851, dùng để xác định loài chim trong một hình ảnh.
Workflow phân loại single-label cũng sử dụng block Classification Label Visualization để hiển thị nhãn dự đoán cùng với điểm tin cậy trực tiếp trên hình ảnh:
>>> Xem thêm: Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow
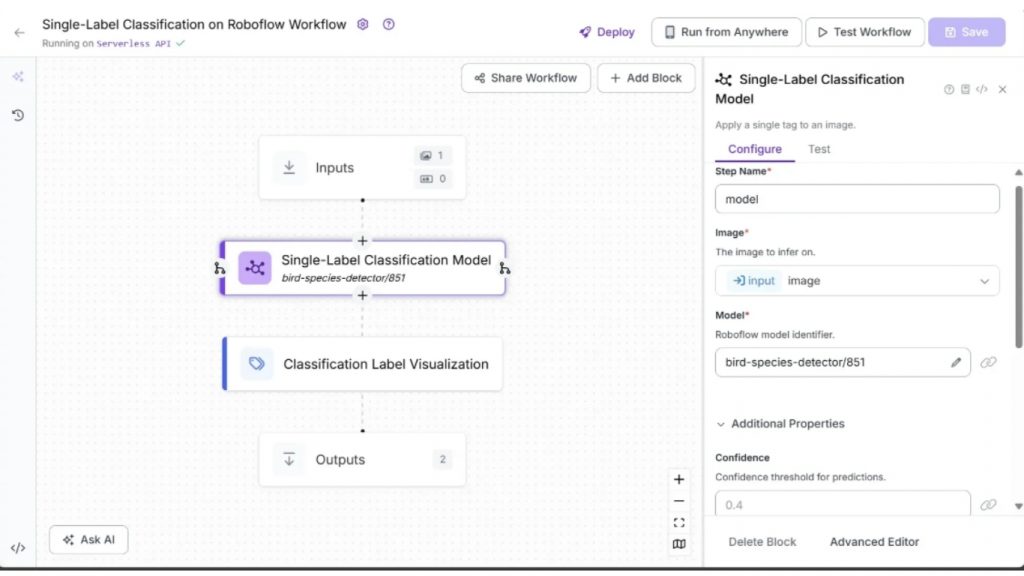

Kết quả đầu ra chứa một nhãn phân loại duy nhất – loài chim – cùng với điểm tin cậy, tất cả đều được hiển thị thông qua block Classification Label Visualization.
Phân loại đa nhãn
Roboflow Workflow bên dưới minh họa việc sử dụng một mô hình phân loại đa nhãn từ Roboflow Universe, có tên power-grid-inspection-wknni/1, có khả năng nhận diện nhiều thành phần khác nhau của lưới điện trong cùng một hình ảnh.
Workflow phân loại multi-label cũng sử dụng block Classification Label Visualization để hiển thị các nhãn dự đoán cùng với điểm tin cậy trên hình ảnh:
>>> Xem thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Các mô hình phát hiện đối tượng tốt nhất năm 2025


Kết quả đầu ra chứa nhiều nhãn phân loại tương ứng với các thành phần của lưới điện, kèm theo điểm tin cậy, tất cả đều được hiển thị bởi block Classification Label Visualization.
Roboflow Universe cung cấp nhiều block phân loại đã được huấn luyện sẵn, bao gồm cả single-label và multi-label. Bạn cần star các mô hình này để có thể sử dụng chúng trong workflow của mình.
Các trường hợp sử dụng của phân loại hình ảnh
- Chẩn đoán bệnh bằng cách phân loại hình ảnh y tế như X-quang hoặc MRI
- Phân loại sản phẩm trên các nền tảng thương mại điện tử để tìm kiếm và gợi ý
- Phát hiện spam hoặc nội dung không phù hợp trong hình ảnh trên mạng xã hội
- Nhận diện loài cây hoặc đánh giá sức khỏe cây trồng trong nông nghiệp
- Nhận dạng khuôn mặt cho mục đích xác thực
Phân đoạn hình ảnh
Phân đoạn hình ảnh là một nhiệm vụ của thị giác máy tính chia hình ảnh thành các vùng hoặc nhóm pixel để phân tích chi tiết, trong đó mỗi pixel được gán một nhãn thay vì chỉ gán nhãn cho toàn bộ ảnh hoặc sử dụng bounding box như trong phân loại hay phát hiện đối tượng. Điều này cho phép máy tính xác định chính xác hình dạng và ranh giới của các đối tượng trong ảnh.
Trong thị giác máy tính, phân đoạn hình ảnh được thực hiện bằng các mô hình như Segment Anything Model 2 (SAM 2), YOLOv11 Instance Segmentation và nhiều mô hình khác.
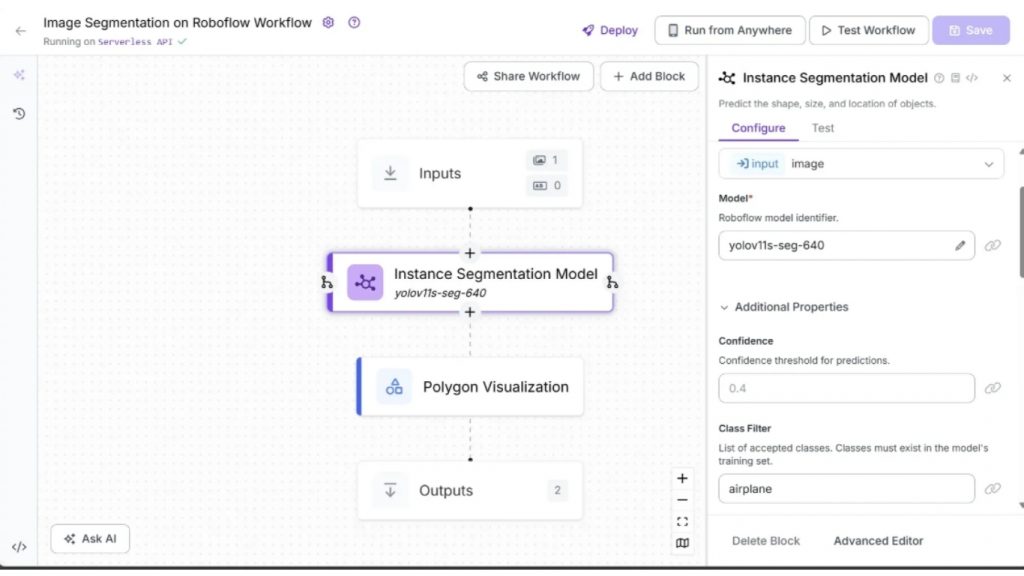
Roboflow Workflow bên dưới minh họa việc sử dụng mô hình YOLOv11 Instance Segmentation để thực hiện phân đoạn hình ảnh.
Workflow phân đoạn hình ảnh cũng sử dụng block Polygon Visualization để vẽ đường bao các vùng đã được phân đoạn trên hình ảnh:
>>> Xem thêm:
- TOP 20 công cụ Chat AI tiếng Việt miễn phí thông minh phổ biến
- TOP 25 công cụ AI miễn phí, phổ biến, tốt nhất hiện nay
Đầu vào và đầu ra của workflow được hiển thị bên dưới:

Trong kết quả đầu ra ở trên, mô hình instance segmentation chỉ phân đoạn máy bay, do “airplane” là lớp duy nhất được chỉ định trong tham số Class Filter của mô hình YOLOv11 Instance Segmentation.
Tương tự như các biến thể YOLO dùng cho phát hiện đối tượng, tham số Class Filter trong YOLOv11 Instance Segmentation (nếu được sử dụng) phải tương ứng với các lớp trong COCO dataset.
Để phát hiện thêm các lớp khác, bạn có thể fine-tune các mô hình phân đoạn trên dataset tùy chỉnh. Nhiều mô hình phân đoạn đã được fine-tune sẵn hiện có trên Roboflow Universe.
Các trường hợp sử dụng của Phân đoạn hình ảnh
- Phát hiện và khoanh vùng khối u, cơ quan hoặc mô trong hình ảnh y tế
- Tách đối tượng tiền cảnh khỏi hậu cảnh để chỉnh sửa ảnh
- Phân đoạn phương tiện, người đi bộ và vật thể trong phân tích giao thông và an toàn
- Phát hiện lỗi ở mức pixel trong sản xuất để kiểm soát chất lượng
Phân tích đa phương thức
Các Mô hình Ngôn ngữ Lớn (LLMs) như GPT-4o, Google Gemini và Anthropic Claude đã vượt xa việc chỉ xử lý văn bản. Hiện nay, các mô hình này mang tính đa phương thức, có khả năng hiểu ngữ cảnh và tích hợp nhiều loại đầu vào khác nhau, bao gồm hình ảnh và video bên cạnh văn bản.
Khả năng này cho phép chúng giải quyết nhiều nhiệm vụ của thị giác máy tính, như phát hiện đối tượng, nhận dạng văn bản, tạo mô tả ảnh (captioning), trả lời câu hỏi dựa trên hình ảnh (VQA), đồng thời kết hợp khả năng suy luận.
Các LLM có khả năng đa phương thức này được gọi chung là Large Multimodal Models (LMMs), và việc sử dụng năng lực suy luận của chúng để thực hiện các tác vụ phức tạp được gọi là phân tích đa phương thức.
Roboflow Workflow bên dưới minh họa việc sử dụng Google Gemini, cùng với Gemini API key, để thực hiện tạo mô tả hình ảnh (image captioning):
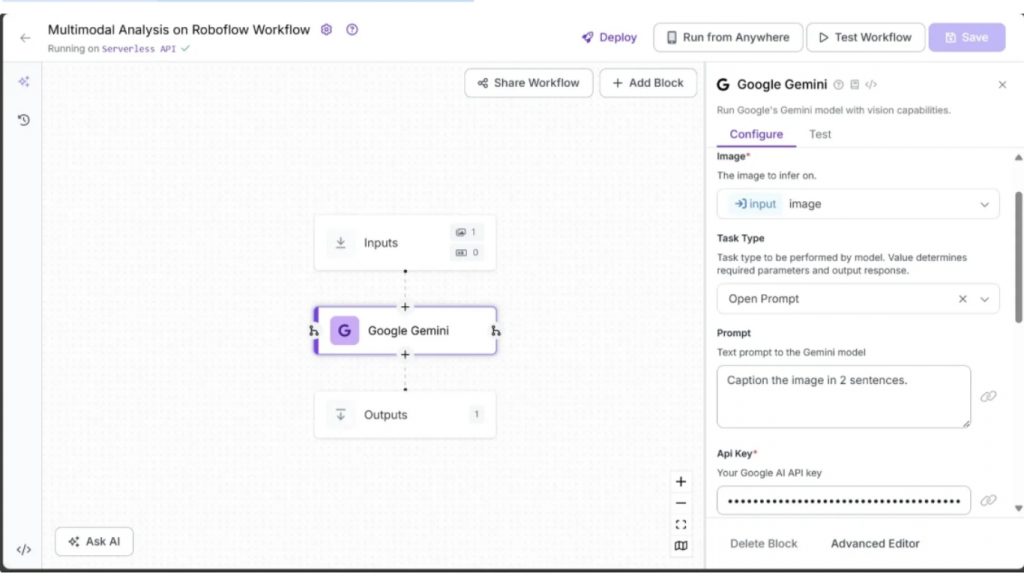
Kết quả khi chạy mô hình được minh họa bằng ảnh dưới đây:

Produces the output below:
“This is a well-lit kitchen featuring a white farmhouse sink with a matte black faucet under two windows, allowing natural light to flood the space. Wooden countertops and open shelves adorned with glassware and mugs add warmth and character to the room.“
Tương tự các block Google Gemini, Roboflow Workflows còn cung cấp nhiều LMM khác như GPT-4o, QwenVL, CogVLM và nhiều mô hình khác, có thể dễ dàng thay thế lẫn nhau mà không cần viết code để thực hiện phân tích đa phương thức.
Các trường hợp sử dụng của phân tích đa phương thức
- Trả lời câu hỏi về hình ảnh bằng cách kết hợp nội dung thị giác và truy vấn văn bản
- Tạo mô tả chi tiết cho hình ảnh dựa trên cả ngữ cảnh hình ảnh và văn bản
- Thực hiện suy luận thị giác, như xác định mối quan hệ giữa các đối tượng trong ảnh
- Trợ lý AI tương tác hiểu cả hình ảnh và văn bản để đưa ra phân tích hoặc giải thích
- Chuyển nội dung thị giác thành mô tả văn bản nhằm hỗ trợ khả năng tiếp cận
Ước lượng điểm đặc trưng
Phát hiện keypoint là một nhiệm vụ của thị giác máy tính nhằm xác định các điểm có ý nghĩa hoặc “điểm mốc” trong hình ảnh, thay vì phát hiện toàn bộ đối tượng. Các điểm này thường đại diện cho các bộ phận cấu trúc hoặc chức năng, chẳng hạn như khớp cơ thể trong ước lượng tư thế, đặc điểm khuôn mặt trong nhận dạng, hoặc các mốc giải phẫu trong hình ảnh y tế.
Quy trình này thường bao gồm việc đưa hình ảnh qua một mô hình học sâu để trích xuất các keypoint. Các mô hình như YOLO-NAS giúp tối ưu hiệu quả bằng cách kết hợp phát hiện đối tượng nhanh với ước lượng keypoint trong cùng một pipeline.
Ví dụ, YOLO-NAS có thể phát hiện một người trong ảnh và đồng thời xuất ra vị trí của khuỷu tay, đầu gối và các khớp khác, phục vụ cho các ứng dụng như ước lượng tư thế người, nhận dạng cử chỉ và thực tế tăng cường.
Roboflow Workflow bên dưới minh họa việc sử dụng YOLO-NAS Pose làm mô hình phát hiện keypoint trên một hình ảnh.
Workflow ước lượng keypoint cũng sử dụng block Keypoint Visualization để vẽ các liên kết dạng khung xương, thể hiện cấu trúc cơ thể người trên hình ảnh:
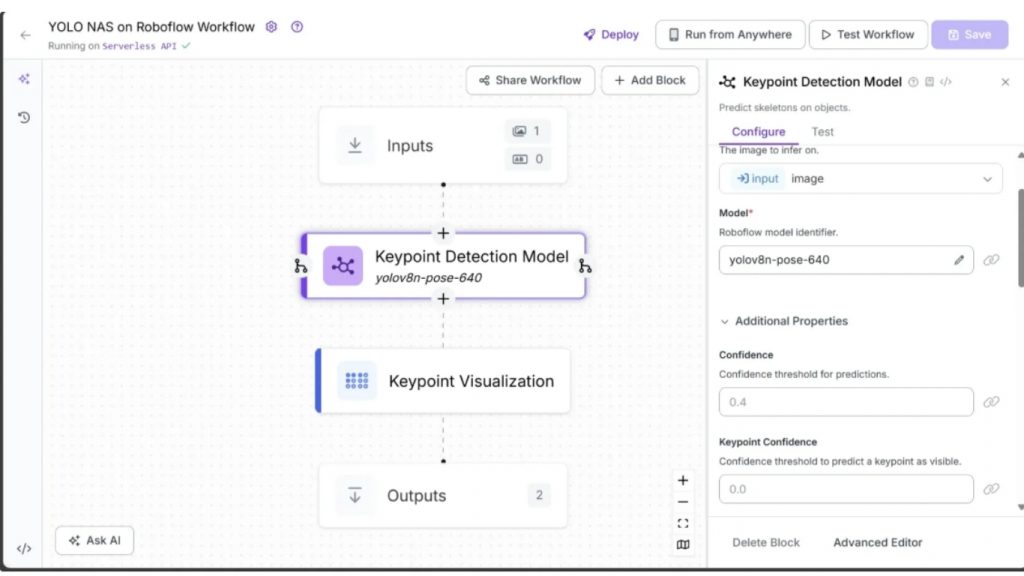
Đầu vào và đầu ra của workflow được hiển thị bên dưới:

Trong kết quả đầu ra, block Keypoint Visualization sử dụng các keypoint do YOLO-NAS Pose phát hiện để vẽ các cạnh tạo thành bộ khung xương, minh họa các bộ phận cơ thể của vận động viên tennis như mũi, mắt, vai, khuỷu tay, hông và nhiều bộ phận khác. Block này cũng có thể vẽ trực tiếp các điểm tại vị trí keypoint được phát hiện.
Các trường hợp sử dụng của Ước lượng điểm đặc trưng
- Ước lượng tư thế người cho nhận dạng hoạt động và phân tích thể thao
- Theo dõi chuyển động cơ thể trong vật lý trị liệu và phục hồi chức năng
- Nhận dạng cử chỉ cho tương tác người–máy và ứng dụng AR/VR
- Phát hiện mốc khuôn mặt để phân tích biểu cảm, cảm xúc và hoạt họa khuôn mặt
- Motion capture cho ngành điện ảnh, hoạt hình và game
Ước lượng độ sâu
Ước lượng độ sâu là một nhiệm vụ của thị giác máy tính nhằm xác định khoảng cách của các đối tượng trong hình ảnh so với camera. Không giống như phát hiện hay phân đoạn – vốn tập trung vào “cái gì” và “ở đâu” – ước lượng độ sâu dự đoán mỗi điểm hoặc pixel cách camera bao xa. Kết quả thường được biểu diễn dưới dạng bản đồ độ sâu (depth map), trong đó pixel sáng hơn biểu thị vật thể gần hơn và pixel tối hơn biểu thị vật thể xa hơn.
Roboflow Workflow bên dưới minh họa việc sử dụng block Depth Estimation để ước lượng độ sâu của một hình ảnh. Khác với các workflow trước, các workflow sử dụng Depth Estimation phải được chạy trên Dedicated Deployment hoặc thiết bị cục bộ thông qua Inference Server.
Bạn có thể chạy workflow này trên thiết bị cục bộ bằng cách fork workflow ước lượng độ sâu và làm theo hướng dẫn trong phần “Setup Your Roboflow Workflow” của bài viết.

Đầu vào và đầu ra của workflow ước lượng độ sâu được hiển thị bên dưới:

Trong kết quả đầu ra, các đối tượng gần camera như cầu thủ sút bóng và quả bóng có màu sáng hơn trên bản đồ độ sâu, trong khi các đối tượng xa hơn như trọng tài, hậu vệ và đồng đội của cầu thủ có màu tối hơn.
Các trường hợp sử dụng của Ước lượng độ sâu
- Giúp xe tự hành nhận thức khoảng cách và tránh chướng ngại vật
- Nâng cao trải nghiệm thực tế tăng cường (AR) nhờ hiểu độ sâu không gian
- Cải thiện khả năng lấy nét và làm mờ hậu cảnh trong nhiếp ảnh
- Hiểu bối cảnh cảnh vật trong hệ thống giám sát và an ninh
- Đo kích thước và khoảng cách đối tượng trong kiểm tra công nghiệp
Nhận dạng ký tự quang học
Nhận dạng ký tự quang học (OCR) là một nhiệm vụ của thị giác máy tính dùng để phát hiện và trích xuất văn bản từ hình ảnh, tài liệu quét hoặc khung hình video, sau đó chuyển đổi thành văn bản có thể xử lý bằng máy.
OCR đóng vai trò cầu nối giữa văn bản trực quan và dữ liệu số, cho phép máy móc hiểu và xử lý chính xác văn bản mà con người nhìn thấy trong hình ảnh.
Roboflow Workflows cung cấp nhiều block workflow có khả năng xử lý OCR, bao gồm nhưng không giới hạn ở Florence-2, Qwen2.5-VL và Google Gemini.
Roboflow Workflow bên dưới minh họa việc sử dụng Google Gemini, cùng với Gemini API key, như một block workflow để thực hiện OCR trên hình ảnh.

Chạy workflow OCR trên hình ảnh dưới đây:

Produces the output below:
Further information may be obtained M.A., Fellow and Lecturer in Chemistry, from Prof. A. Gilligan, D.Sc., Department Leeds, and from Mr. A. H. Worrall, M.A., College, Jersey.
Trong kết quả trên, Google Gemini thực hiện OCR với độ chính xác cao, thậm chí vẫn giữ đúng xuống dòng và khoảng cách của văn bản gốc trong hình ảnh.
Các trường hợp sử dụng của Nhận dạng ký tự quang học
- Chuyển đổi sách in, báo chí và tài liệu lưu trữ thành định dạng số có thể tìm kiếm
- Tự động hóa nhập liệu từ hóa đơn, biên lai và biểu mẫu có cấu trúc
- Trích xuất và xác minh thông tin từ giấy tờ tùy thân như hộ chiếu, bằng lái
- Hỗ trợ công cụ tiếp cận bằng cách đọc văn bản từ hình ảnh cho người khiếm thị
- Dịch văn bản theo thời gian thực từ biển báo, menu hoặc tài liệu
Khám phá các nhiệm vụ chính của thị giác máy tính: Kết luận
Trong bài viết này, chúng ta đã khám phá các nhiệm vụ cốt lõi của thị giác máy tính, bao gồm: phát hiện đối tượng, phân loại hình ảnh, phân đoạn hình ảnh, phân tích đa phương thức, ước lượng điểm đặc trưng, ước lượng độ sâu và nhận dạng ký tự quang học (OCR).
Với Roboflow Workflows, những nhiệm vụ phức tạp này có thể được thực thi hiệu quả thông qua các pipeline không cần hoặc rất ít code, giúp lập trình viên và doanh nghiệp khai thác sức mạnh của AI thị giác mà không đòi hỏi chuyên môn lập trình sâu.
Nguồn tham khảo: Top Computer Vision Tasks and How to Do Them Fast
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Hoàng Diệu, Phường 12, Quận 4, Thành phố Hồ Chí Minh, Việt Nam







