
Trong thập kỷ qua, học máy (Machine Learning – ML) đã chuyển mình từ một đề tài nghiên cứu học thuật thuần túy trở thành ưu tiên hàng đầu của các doanh nghiệp trên toàn cầu. Thay vì thiết lập những quy tắc điều kiện (if-else) cứng nhắc, các kỹ sư hiện nay cung cấp dữ liệu mẫu cho thuật ngữ toán để hệ thống tự động nhận diện các quy luật. Khi được triển khai hiệu quả, học máy không chỉ giúp tối ưu hóa chi phí mà còn mở ra những nguồn doanh thu mới.
Học máy (Machine Learning) là gì?
Hãy tưởng tượng cách bạn dạy một đứa trẻ nhận biết con mèo. Thay vì đưa ra các quy tắc khô khan như: “nếu động vật có 4 chân + có đuôi + có ria mép → là con mèo”, bạn sẽ cho đứa trẻ xem thật nhiều ảnh về loài mèo. Theo thời gian, đứa trẻ sẽ tự nhận diện các đặc điểm chung và áp dụng kiến thức đó để nhận biết những con mèo khác mà chúng chưa từng thấy.
Học máy vận hành theo cơ chế tương tự. Đây là loại phần mềm có khả năng học từ các ví dụ thực tế để đưa ra dự đoán hoặc quyết định mà không cần lập trình chi tiết cho từng trường hợp cụ thể. Nói ngắn gọn, nếu các hệ thống dựa trên quy tắc phụ thuộc vào logic “if-else” cứng nhắc, thì hệ thống học máy có khả năng thích ứng linh hoạt. Chúng tự tinh chỉnh các tham số nội tại khi tiếp nhận thêm nhiều dữ liệu.
Thực tế, học máy hiện diện trong đời sống hàng ngày của bạn nhiều hơn bạn tưởng. Từ việc hòm thư điện tử tự động chặn tin nhắn rác đến việc Netflix gợi ý các bộ phim phù hợp với sở thích, tất cả đều là những ứng dụng thực tế của học máy.
>>> Xem thêm các bài viết khác:
- Top 7 Công cụ Theo dõi Đối tượng Mã nguồn mở Tốt Nhất
- Top 5 trình soạn thảo mã cho thị giác máy tính tốt nhất
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
Các loại học máy
Mỗi bài toán khác nhau sẽ phù hợp với những chiến lược học máy khác nhau. Việc lựa chọn phương pháp phù hợp với dữ liệu sẵn có, ngân sách và thời gian triển khai là yếu tố rất quan trọng. Dưới đây là các loại học máy phổ biến cần cân nhắc.
Học có giám sát
Học có giám sát là loại hình mà hầu hết mọi người nghĩ đến khi nhắc tới học máy. Mô hình học trực tiếp từ dữ liệu đã được gán nhãn, ánh xạ đầu vào (x) với kết quả đầu ra đã biết (y). Với tập dữ liệu bao gồm hình ảnh hoặc dữ liệu kèm theo nhãn chính xác, học có giám sát đặc biệt hiệu quả cho các bài toán như phân loại và phát hiện đối tượng.
Ví dụ điển hình bao gồm: phê duyệt hoặc từ chối hồ sơ tín dụng, phân loại hóa đơn đã thanh toán hay chưa, phát hiện gian lận, hoặc phát hiện một con ốc vít bị thiếu trên dây chuyền sản xuất.
Học không giám sát
Học không giám sát tiếp cận theo hướng hoàn toàn khác. Thay vì cần dữ liệu có nhãn, mô hình sẽ tìm kiếm cấu trúc tiềm ẩn trong dữ liệu chưa được gán nhãn. Dữ liệu đầu vào có thể là giao dịch khách hàng, hình ảnh hoặc log từ cảm biến.
Từ đó, mô hình tiến hành phân cụm hoặc nhóm dữ liệu để khám phá các mẫu ẩn. Phương pháp này đặc biệt hữu ích trong việc phân khúc khách hàng theo hành vi hoặc phát hiện bất thường, chẳng hạn như các lô hàng bất thường trong dữ liệu logistics.
Học bán giám sát
Học bán giám sát kết hợp ưu điểm của cả học có giám sát và không giám sát. Với một lượng nhỏ dữ liệu đã gán nhãn và một tập lớn dữ liệu chưa gán nhãn, mô hình vẫn có thể đạt độ chính xác cao mà không cần tốn chi phí gán nhãn toàn bộ dữ liệu.
Một ví dụ thực tế là chỉ cần gán nhãn khoảng 5% số khung hình video, trong khi mô hình tự học từ phần lớn dữ liệu chưa gán nhãn còn lại. Cách này giúp giảm đáng kể thời gian và chi phí gán nhãn, đồng thời vẫn cải thiện hiệu suất mô hình.
>>> Xem thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Các mô hình phát hiện đối tượng tốt nhất
Học tự giám sát
Học tự giám sát đã trở thành nền tảng quan trọng của trí tuệ nhân tạo hiện đại. Thay vì phụ thuộc vào các nhãn dữ liệu có sẵn, các mô hình sẽ tự huấn luyện dựa trên các “nhiệm vụ tiền đề” được thiết kế để học các biểu diễn dữ liệu hữu ích.
Phương pháp này đặc biệt mạnh khi xử lý các tập dữ liệu khổng lồ không được dán nhãn, chẳng hạn như các kho lưu trữ hình ảnh hoặc video. Ví dụ, học tương phản giúp huấn luyện trước các mạng xương sống, sau đó có thể tinh chỉnh cho các tác vụ hạ nguồn với lượng dữ liệu dán nhãn ít hơn đáng kể.
Học chuyển giao và mô hình nền tảng
Học chuyển giao và các mô hình nền tảng giúp rút ngắn thời gian phát triển bằng cách bắt đầu từ các mô hình đã được huấn luyện sẵn và điều chỉnh chúng cho các miền dữ liệu mới. Kỹ sư có thể fine-tune mô hình hoặc sử dụng các adapter nhẹ như LoRA để chuyên biệt hóa mô hình cho môi trường triển khai cụ thể.
Cách tiếp cận này giúp việc huấn luyện nhanh hơn, rẻ hơn và chính xác hơn, đặc biệt khi dữ liệu gán nhãn bị hạn chế. Ví dụ, bạn có thể điều chỉnh RF-DETR cho hệ thống camera trong kho hàng chỉ với một tập dữ liệu tương đối nhỏ.
Học tăng cường
Học tăng cường tập trung vào việc học thông qua phản hồi. Thay vì nhãn cố định, mô hình nhận được phần thưởng cho những hành động giúp nó tiến gần hơn đến mục tiêu. Cơ chế này đặc biệt phù hợp với các bài toán điều khiển và robot.
Hãy tưởng tượng một cánh tay robot liên tục tinh chỉnh chuyển động để giảm số linh kiện bị rơi, một xe tự hành cải thiện chính sách lái xe, hoặc một tác nhân AI học cách chơi game thông qua thử và sai. Tất cả đều là những ví dụ tiêu biểu của học tăng cường trong thực tế.
>>> Xem thêm: Low Code là gì? Giải pháp phát triển phần mềm và xu hướng tương lai
Cách chọn chiến lược học máy phù hợp
Hãy bắt đầu từ nguồn dữ liệu hiện có của bạn. Nếu dữ liệu đã được gán nhãn đầy đủ (chẳng hạn như hình ảnh sản phẩm lỗi và không lỗi), thì học máy có giám sát là lựa chọn phù hợp nhất, vì mô hình có thể học trực tiếp mối quan hệ giữa dữ liệu đầu vào và kết quả đầu ra.
Ngược lại, nếu bạn có khối lượng lớn dữ liệu thô như video từ camera nhưng chưa có nhãn, hãy áp dụng học máy không giám sát để tự động nhóm dữ liệu và phát hiện các điểm bất thường, sau đó chỉ gán nhãn cho những trường hợp cần thiết.
Khi chi phí gán nhãn cao, các phương pháp học bán giám sát hoặc tự giám sát sẽ giúp giảm đáng kể công sức chú thích dữ liệu mà vẫn đảm bảo độ chính xác của mô hình. Nếu cần triển khai nhanh, bạn nên tận dụng mô hình nền tảng có sẵn và tinh chỉnh (fine-tune) cho bài toán cụ thể để rút ngắn thời gian huấn luyện.
Với các bài toán động, đòi hỏi ra quyết định liên tục theo thời gian như robot gắp – đặt trong nhà máy, học tăng cường là hướng tiếp cận phù hợp để tối ưu hiệu quả trong dài hạn.
>>> Xem thêm:
- TOP 20 công cụ Chat AI tiếng Việt miễn phí thông minh phổ biến
- TOP 25 công cụ AI miễn phí, phổ biến, tốt nhất hiện nay

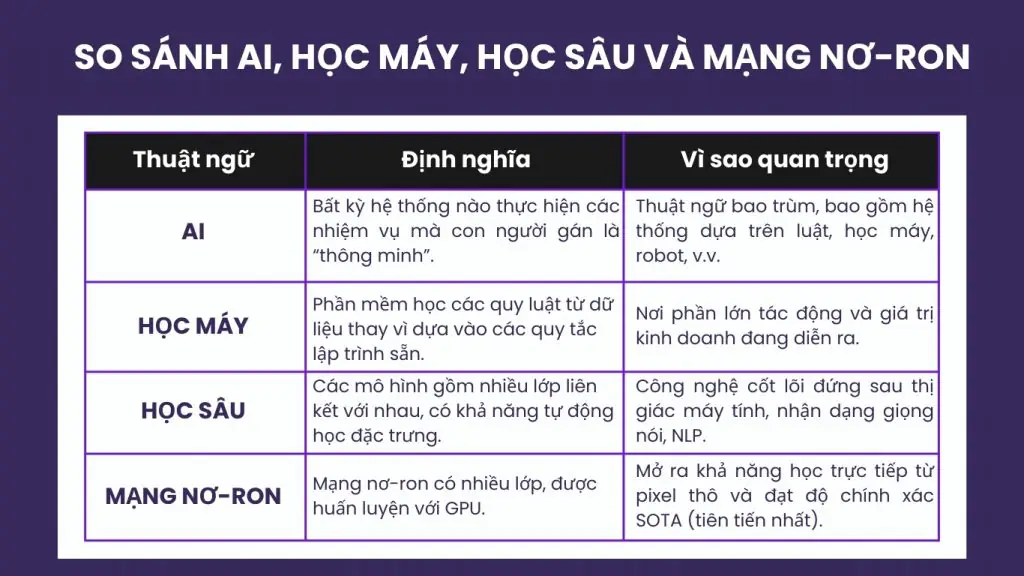
Sự khác nhau giữa học máy, trí tuệ nhân tạo (AI), deep learning và mạng nơ-ron
Trí tuệ nhân tạo là khái niệm bao trùm, dùng để chỉ các hệ thống có khả năng thực hiện những nhiệm vụ được xem là “thông minh”, chẳng hạn như nhận thức, suy luận hoặc ra quyết định. Học máy là một nhánh con của AI, tập trung vào các hệ thống phần mềm có khả năng tự học quy luật từ dữ liệu, thay vì dựa vào logic được lập trình thủ công bằng các câu lệnh if–else cố định.
Bên trong học máy, mạng nơ-ron là các mô hình được cấu tạo từ nhiều lớp kết nối có trọng số, cho phép hệ thống tự động học biểu diễn dữ liệu. Học sâu là tập hợp các mạng nơ-ron có nhiều lớp ẩn, cho phép huấn luyện end-to-end trực tiếp từ dữ liệu thô như hình ảnh, âm thanh hoặc văn bản, đồng thời thay thế phần lớn các bước trích xuất đặc trưng thủ công trước đây.
>>> Xem thêm:
- Xây dựng quy trình Vision AI nghiên cứu khoa học
- Vertex AI là gì? Nền tảng học máy của Google Cloud
Ngày nay học máy hoạt động như thế nào?
Việc tạo ra giá trị từ machine learning không phải là xây dựng một mô hình duy nhất rồi coi như hoàn thành. Đây là một quy trình có kỷ luật. Các đội ngũ ngày nay thường bắt đầu từ mục tiêu kinh doanh, thiết lập tiêu chuẩn dữ liệu rõ ràng, sau đó triển khai theo các vòng lặp gồm huấn luyện – đánh giá – triển khai – giám sát, với khả năng tái lập được tích hợp ngay từ đầu.
Hai xu hướng lớn định hình vòng đời học máy hiện nay:
- Học máy lấy dữ liệu làm trung tâm: chất lượng và độ bao phủ của dữ liệu quan trọng hơn độ phức tạp của mô hình.
- Sự nổi lên của mô hình tiền huấn luyện và mô hình nền tảng: giúp rút ngắn thời gian huấn luyện và giảm chi phí, nhưng vẫn đòi hỏi dữ liệu sạch, gán nhãn tốt và quy trình vận hành bài bản.
Ở mức thực tế, vòng đời học máy bắt đầu bằng việc xác định rõ bài toán dưới góc độ kinh doanh. Ví dụ: bạn muốn giảm tỷ lệ lỗi sản phẩm hay tăng thông lượng sản xuất? Từ đó, dữ liệu phù hợp được thu thập, gán nhãn nhất quán và kiểm soát chất lượng chặt chẽ.
Dữ liệu này được đưa vào quá trình huấn luyện, nơi mô hình học từ các ví dụ và được đánh giá trên tập dữ liệu giữ lại để đảm bảo khả năng tổng quát hóa trong môi trường thực tế – chứ không chỉ “đẹp trên phòng thí nghiệm”.
Khi mô hình đạt hiệu suất tốt, trọng tâm chuyển sang triển khai: đóng gói để chạy trên cloud, edge hoặc on-premise, tùy thuộc vào yêu cầu về quyền riêng tư, độ trễ và phần cứng. Tuy nhiên, triển khai không phải là điểm kết thúc. Các nhóm cần đầu tư vào giám sát và cải tiến liên tục – theo dõi hiệu suất theo thời gian, phát hiện điểm yếu và cập nhật mô hình khi dữ liệu, điều kiện và nhu cầu kinh doanh thay đổi.
>>> Xem thêm: Xây Dựng Mô Hình Ngôn Ngữ Thị Giác với Next.js & Roboflow

Các nhóm mô hình học máy phổ biến
Không tồn tại một mô hình học máy “tốt nhất” cho mọi bài toán. Lựa chọn phù hợp phụ thuộc vào dữ liệu, ràng buộc và mục tiêu của bạn. Trên thực tế, bạn nên bắt đầu với các mô hình đơn giản cho dữ liệu dạng bảng, chuyển sang mạng sâu khi dữ liệu phi cấu trúc hoặc khi độ chính xác đã chạm trần. Đồng thời, luôn cân nhắc các yếu tố như khả năng giải thích, độ trễ và quy mô dữ liệu.
Hồi quy tuyến tính và logistic
Hồi quy tuyến tính và hồi quy logistic là những mô hình cơ bản và đơn giản nhất để bắt đầu, đặc biệt phù hợp với dữ liệu dạng bảng. Chúng có tốc độ huấn luyện nhanh, dễ diễn giải và dễ triển khai, nên rất thích hợp làm bước khởi đầu trong một dự án xây dựng mô hình.
Tuy nhiên, hạn chế của các mô hình này nằm ở khả năng biểu diễn: chúng chỉ nắm bắt được các mối quan hệ tương đối đơn giản. Vì vậy, dù tạo ra một baseline tốt, chúng hiếm khi là giải pháp cuối cùng trong các bài toán phức tạp.
Tổ hợp mô hình cây
Các phương pháp dựa trên cây như Decision Tree, Random Forest và XGBoost thường là bước nâng cao tiếp theo. Chúng xử lý tốt nhiều loại đặc trưng khác nhau và cho độ chính xác cao ngay từ đầu, ngay cả khi không cần quá nhiều bước xây dựng đặc trưng phức tạp.
Hạn chế chính của các mô hình này nằm ở khâu triển khai: các tổ hợp cây thường khó tối ưu cho môi trường độ trễ thấp, đặc biệt khi chạy trên thiết bị biên.
Máy vector hỗ trợ
Máy vector hỗ trợ (Support Vector Machines – SVM) và các phương pháp kernel hoạt động rất hiệu quả trên các bộ dữ liệu dạng bảng có quy mô nhỏ, nơi chúng có thể xây dựng ranh giới phân loại rõ ràng và khả năng tổng quát hóa tốt.
Tuy nhiên, khi quy mô dữ liệu tăng lên, các hạn chế bắt đầu xuất hiện: quá trình huấn luyện và suy luận trở nên chậm, đồng thời khả năng diễn giải của mô hình cũng giảm. Vì vậy, SVM phù hợp hơn với các bài toán nhỏ, phạm vi hẹp, thay vì các hệ thống lớn, phức tạp ở quy mô doanh nghiệp.
Mô hình xác suất và đồ thị
Các mô hình xác suất và đồ thị rất mạnh trong các bài toán liên quan đến sự không chắc chắn có cấu trúc. Chúng mang lại mức độ giải thích cao và mô hình hóa được những mối quan hệ phức tạp.
Đổi lại, chúng phức tạp hơn trong huấn luyện và yêu cầu xử lý toán học, tính toán cẩn thận, khiến việc áp dụng thực tế chậm hơn.
Mạng Nơ-ron
Mạng nơ-ron đã trở thành lựa chọn hàng đầu cho dữ liệu phi cấu trúc như hình ảnh, âm thanh, văn bản và dữ liệu đa phương thức. Chúng học đặc trưng theo kiểu end-to-end, loại bỏ nhu cầu feature engineering thủ công.
Điểm yếu nằm ở chi phí huấn luyện cao: cần lượng lớn dữ liệu có nhãn và tinh chỉnh cẩn thận để đạt hiệu suất tối ưu.
Quy tắc thực tiễn: hãy ưu tiên các phương pháp đơn giản cho dữ liệu có cấu trúc, và chuyển sang mô hình sâu khi dữ liệu phi cấu trúc hoặc khi các phương pháp cơ bản không còn cải thiện được hiệu suất.
Học sâu (Deep Learning) là gì?
Deep Learning (học sâu) là một nhánh của học máy sử dụng mạng nơ-ron nhiều lớp để tự động học đặc trưng trực tiếp từ dữ liệu thô như pixel hình ảnh, sóng âm thanh hoặc các token văn bản, thay vì phụ thuộc vào các quy tắc hay đặc trưng được thiết kế thủ công.
Học sâu bắt đầu phát triển mạnh vào cuối những năm 2000 và đầu 2010, khi ba yếu tố quan trọng cùng hội tụ:
- Sự sẵn có của các tập dữ liệu lớn đã được gán nhãn,
- Sự phát triển của GPU và các phần cứng tăng tốc,
- Những cải tiến về kiến trúc mô hình, giúp việc huấn luyện mạng sâu trở nên ổn định, nhanh hơn và đủ khả năng đưa vào các hệ thống thực tế.
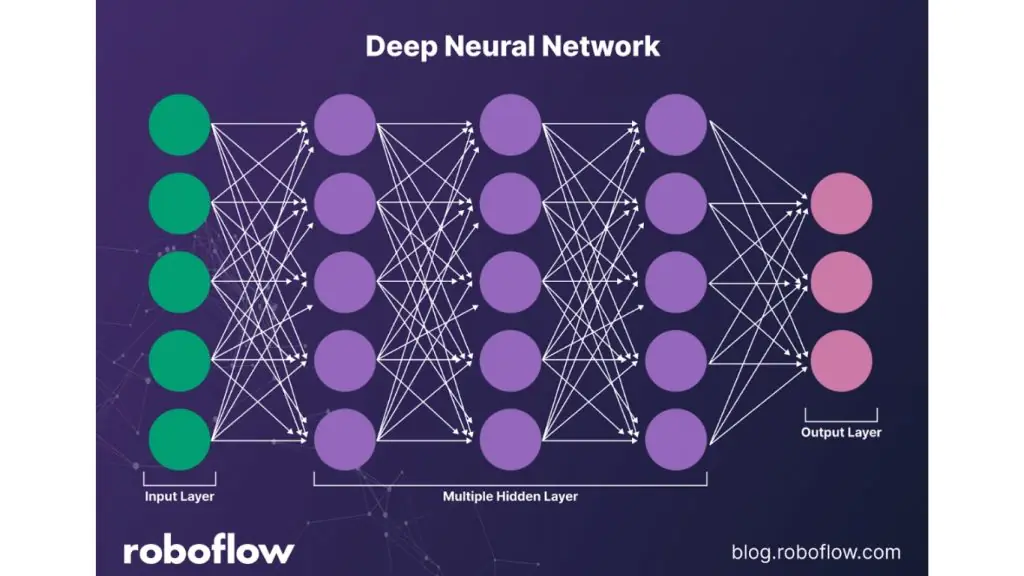
Cách mạng nơ-ron sâu hoạt động như thế nào?
Ở cấp độ tổng quát, một mạng nơ-ron sâu được xây dựng bằng cách xếp chồng nhiều lớp tính toán đơn giản – bao gồm các phép biến đổi tuyến tính kết hợp với hàm kích hoạt phi tuyến. Mỗi lớp sẽ chuyển đổi biểu diễn dữ liệu thành dạng có ý nghĩa hơn: trong thị giác máy tính, pixel được chuyển thành cạnh, cạnh thành kết cấu, kết cấu thành bộ phận, và cuối cùng là đối tượng hoàn chỉnh.
Trong xử lý ngôn ngữ, nguyên lý này cũng tương tự: ký tự tạo thành từ, từ tạo thành cụm từ, và cụm từ tạo nên ý nghĩa. Quá trình huấn luyện dựa trên lan truyền ngược để xác định mức độ đóng góp của từng trọng số vào sai số, sau đó sử dụng gradient descent để điều chỉnh các trọng số đó. Qua mỗi vòng lặp, mô hình học máy dần giảm sai lệch và đưa ra dự đoán chính xác hơn.
Vì sao các đội ngũ chọn học sâu?
Các đội ngũ kỹ thuật lựa chọn học sâu khi cần xử lý dữ liệu phi cấu trúc như hình ảnh, video, giọng nói hoặc văn bản tự do. Không giống các phương pháp truyền thống, hiệu năng của học máy dựa trên mạng nơ-ron sâu sẽ tiếp tục cải thiện khi dữ liệu và tài nguyên tính toán tăng lên.
Bên cạnh đó, sự phát triển của transfer learning và foundation models giúp việc thích nghi các mô hình đã được huấn luyện sẵn cho các bài toán cụ thể trở nên nhanh chóng và tiết kiệm chi phí hơn. Học sâu còn hỗ trợ huấn luyện đầu-cuối, giảm sự phụ thuộc vào các bước thủ công và đặc trưng thiết kế cứng nhắc, từ đó tạo ra các hệ thống học máy ổn định và bền vững hơn trong môi trường thực tế
Những gì cần có để triển khai học sâu?
Để vận hành học sâu hiệu quả, không chỉ cần một mô hình lớn. Chất lượng và độ bao phủ của dữ liệu quan trọng không kém số lượng dữ liệu. Ngân sách tính toán cần được lên kế hoạch cẩn thận, bao gồm tài nguyên GPU, giới hạn phần cứng biên, và yêu cầu độ trễ.
Ngoài ra, các nhóm thành công thường áp dụng nghiêm ngặt các thực hành MLOps như: quản lý phiên bản dữ liệu, đảm bảo khả năng tái lập thí nghiệm, và giám sát mô hình sau khi triển khai để phát hiện sớm hiện tượng trôi dữ liệu hoặc suy giảm hiệu suất.
Một lần học của mạng nơ-ron sâu diễn ra như thế nào?
Trong một lượt huấn luyện, mạng nơ-ron sâu thực hiện phép tổng có trọng số trên đầu vào, sau đó đưa kết quả qua các hàm kích hoạt phi tuyến như ReLU hoặc GELU, và tiếp tục qua các lớp chồng lên nhau. Các tham số và hệ số bias quyết định mức độ ảnh hưởng của đầu vào đến đầu ra.
Quá trình lan truyền ngược sẽ tính gradient của hàm mất mát (ví dụ: cross-entropy hoặc IoU/Dice) đối với từng trọng số. Các thuật toán tối ưu như SGD hoặc Adam sử dụng gradient này để cập nhật mô hình. Để giữ quá trình huấn luyện ổn định và tránh overfitting, các kỹ thuật như batch normalization, layer normalization, dropout, weight decay và data augmentation thường được áp dụng.
Mở rộng với transfer learning và foundation models
Các mạng học sâu có khả năng xấp xỉ những hàm cực kỳ phức tạp, vì vậy chúng đang là nền tảng cho các hệ thống tối tân hiện nay trong thị giác máy tính, xử lý ngôn ngữ, giọng nói, hệ thống gợi ý và AI đa phương thức. Ngày càng ít đội ngũ phải xây dựng mô hình từ đầu.
Thay vào đó, họ tận dụng các mô hình đã được huấn luyện sẵn bằng cách tinh chỉnh (fine-tune) một phần nhỏ ở đầu ra, hoặc áp dụng các kỹ thuật nhẹ như LoRA hay QLoRA. Cách tiếp cận này giúp giảm đáng kể lượng dữ liệu và tài nguyên tính toán, trong khi vẫn đạt được hiệu suất ở mức sẵn sàng cho môi trường sản xuất.
Thông lượng, độ trễ và triển khai
Cuối cùng, các kiến trúc hiện đại như Transformer được thiết kế để tận dụng khả năng song song hóa, giúp huấn luyện và triển khai hiệu quả trên phần cứng ngày nay. Khi triển khai ở môi trường biên, các kỹ thuật như quantization cùng runtime tối ưu như ONNX hoặc TensorRT giúp mô hình học máy đáp ứng các yêu cầu nghiêm ngặt về độ trễ trong thực tế.
Sự kết hợp giữa khả năng mở rộng, tính linh hoạt và sẵn sàng triển khai chính là lý do học sâu tiếp tục trở thành phương pháp mặc định để giải quyết những bài toán học máy phức tạp nhất hiện nay.
Các kiến trúc Deep Learning
Với cách hiểu này, câu hỏi tiếp theo là kiến trúc học sâu nào phù hợp nhất với bài toán và các ràng buộc của bạn. Các phần dưới đây tóm lược những họ kiến trúc phổ biến nhất, lý do chúng hoạt động hiệu quả và những tình huống mà chúng phát huy thế mạnh.
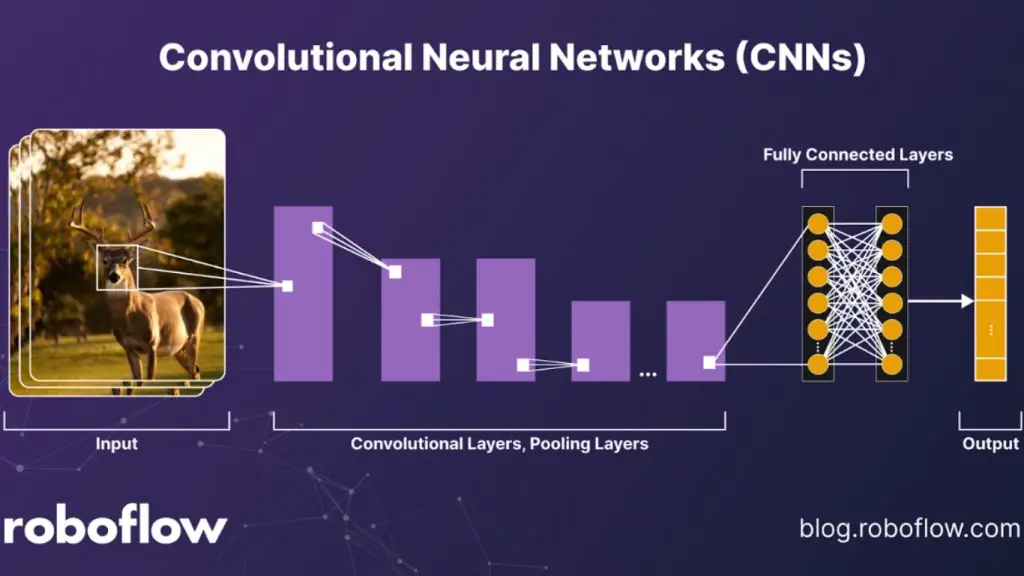
Mạng Nơ-ron tích chập (CNNs)
Mạng nơ-ron tích chập (CNNs) vẫn là nền tảng cốt lõi của thị giác máy tính hiện đại. Bằng cách áp dụng các bộ lọc tích chập với trọng số dùng chung trên toàn bộ ảnh, CNNs có khả năng phát hiện các mẫu cục bộ như cạnh, góc và kết cấu.
Các lớp pooling giúp tăng tính bất biến theo không gian, cho phép nhận dạng cùng một đối tượng ngay cả khi vị trí của nó thay đổi trong khung hình. Nhờ hiệu quả tham số cao và thiên kiến quy nạp về tính cục bộ, CNNs đặc biệt phù hợp với dữ liệu hình ảnh.
Các kiến trúc như ResNet, RegNet và EfficientNet thống trị các bài toán phân loại, trong khi U-Net và Mask R-CNN nổi bật trong các tác vụ phân đoạn ảnh. CNNs được ứng dụng rộng rãi trong phát hiện lỗi sản xuất, giám sát tuân thủ PPE, phân tích bố cục tài liệu kết hợp OCR, và chẩn đoán hình ảnh y tế.
Hạn chế chính của CNNs là khó mô hình hóa phụ thuộc dài hạn nếu không bổ sung các cơ chế như tích chập giãn hoặc attention, và chúng có thể gặp khó khăn khi xử lý dữ liệu đa phương thức có tính đa dạng cao.
>>> Xem thêm: Ứng dụng AI trong bán hàng online: TOP 10 công cụ AI & cách triển khai hiệu quả
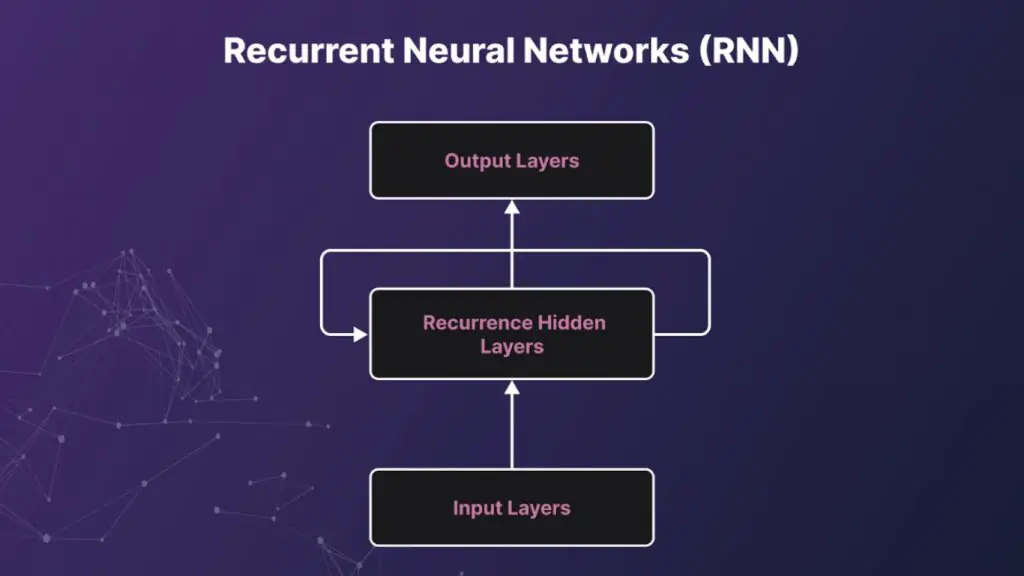
Mạng Nơ-ron hồi tiếp (RNNs: LSTM/GRU)
Mạng nơ-ron hồi tiếp (RNNs), bao gồm LSTM và GRU, xử lý dữ liệu chuỗi theo từng bước thời gian, đồng thời duy trì một trạng thái ẩn (hidden state) để tóm tắt thông tin quá khứ.
Các cơ chế cổng cho phép mô hình quyết định nên ghi nhớ hay quên thông tin theo thời gian, khiến RNNs đặc biệt phù hợp với tín hiệu chuỗi gọn nhẹ và dữ liệu chuỗi thời gian. Chúng cũng phù hợp cho các kịch bản chạy ở biên, nơi suy luận theo luồng với độ trễ thấp là yếu tố quan trọng.
Tuy nhiên, RNNs gặp hạn chế với ngữ cảnh dài do hiện tượng tiêu biến hoặc bùng nổ gradient, và bản chất tuần tự khiến chúng khó mở rộng huấn luyện so với các kiến trúc có thể song song hóa. Dù vậy, RNNs vẫn hữu ích trong dự báo dữ liệu cảm biến, phát hiện từ khóa, NLP cổ điển, và mô hình chuỗi nhẹ trên thiết bị nhúng.
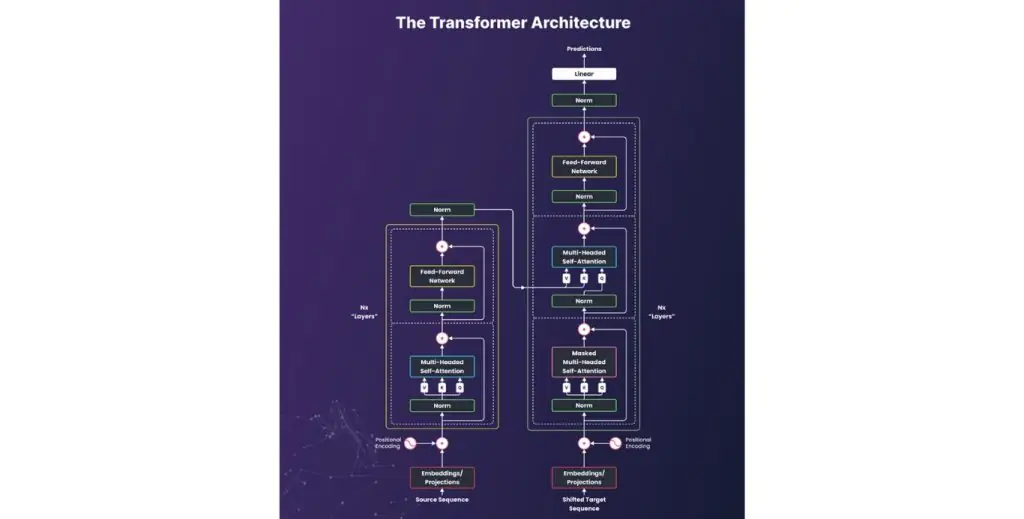
Transformers (Cơ chế tự chú ý – Self-Attention)
Transformers đã thay thế hồi tiếp bằng cơ chế tự chú ý, cho phép mô hình đánh trọng số cho bất kỳ phần nào của đầu vào khi tạo ra đầu ra. Đột phá này mở ra khả năng song song hóa quy mô lớn, đồng thời hỗ trợ lập luận dài hạn trên văn bản, hình ảnh và âm thanh.
Hiện nay, Transformers xác lập chuẩn mực cao nhất trong xử lý ngôn ngữ (LLMs), thị giác máy tính (ViTs, DETR) và các ứng dụng đa phương thức như mô hình ảnh–văn bản. Chúng mở rộng hiệu quả theo dữ liệu và tài nguyên tính toán, đồng thời chuyển giao tốt giữa các miền dữ liệu.
Đánh đổi lớn nhất là chi phí tính toán: attention thuần có độ phức tạp bậc hai theo độ dài chuỗi, đòi hỏi các tối ưu như windowing, attention thưa, FlashAttention hoặc kiến trúc lai. Trên thiết bị biên, Transformers cũng khá nặng, dù lượng tử hóa và chưng cất mô hình có thể giảm tải. Hiện nay, chúng vận hành trợ lý hội thoại, hiểu tài liệu, đầu DETR cho phát hiện và phân đoạn, hiểu video, và các hệ thống truy hồi – xếp hạng quy mô lớn
Mô hình không gian trạng thái (State Space Models – SSMs/Mamba)
State Space Models (SSMs), đặc biệt là các biến thể “chọn lọc” hiện đại như Mamba, đang nổi lên như một lựa chọn thay thế cho Transformers trong mô hình hóa chuỗi. Các mô hình này tiến hóa trạng thái học được theo cách tuyến tính qua các vị trí, mang lại hiệu quả xử lý luồng và thông lượng cao trong khi vẫn xử lý được ngữ cảnh dài.
Nhờ phù hợp tự nhiên với ứng dụng thời gian thực, SSMs hấp dẫn trong xử lý giọng nói, âm thanh, mã nguồn, và các bài toán LLM mới nổi nơi tốc độ và độ dài ngữ cảnh là then chốt.
Tuy nhiên, hệ sinh thái của SSMs còn non trẻ so với Transformers và thực tiễn tốt nhất vẫn đang hoàn thiện. Hiệu năng có thể khác nhau giữa các tác vụ, vì vậy kiến trúc lai thường được sử dụng. Dù vậy, SSMs đang thu hút sự chú ý như một hướng đi thông lượng cao, tiết kiệm bộ nhớ cho mô hình chuỗi.
Autoencoders và Autoencoders biến phân (VAEs)
Autoencoders nén dữ liệu vào không gian tiềm ẩn rồi tái tạo lại đầu vào, rất hữu ích cho giảm chiều dữ liệu và phát hiện bất thường. Autoencoders biến phân (VAEs) bổ sung tiên nghiệm xác suất lên không gian tiềm ẩn, giúp tăng khả năng khái quát hóa. Cả hai đặc biệt hiệu quả khi thiếu nhãn rõ ràng, vì có thể học biểu diễn trực tiếp từ dữ liệu.
Đánh đổi là chất lượng tái tạo: kết quả có thể quá mượt, và các kết cấu phức tạp dễ bị underfit. Trong thực tế, autoencoders và VAEs thường dùng cho phát hiện bất thường công nghiệp (học trạng thái “bình thường” và phát hiện sai lệch), cũng như nén dữ liệu và khử nhiễu.
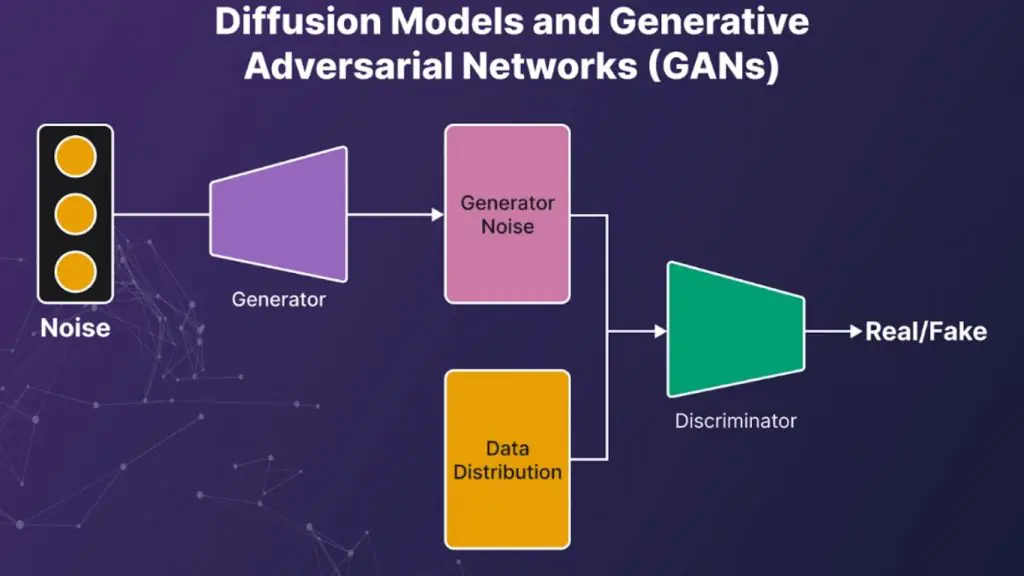
Mô hình khuếch tán và mạng đối sinh (GANs)
Diffusion models và GANs dẫn đầu trong mô hình sinh. Diffusion hoạt động bằng cách khử nhiễu dần từ nhiễu ngẫu nhiên về dữ liệu có cấu trúc, trong khi GANs cho hai mạng generator và discriminator đối kháng để sinh mẫu chân thực.
Các mô hình này tạo ra ảnh và video độ trung thực cao, hỗ trợ in-painting, siêu phân giải, và tạo dữ liệu tổng hợp để tăng cường huấn luyện.
Diffusion thường chậm khi suy luận nếu không được tăng tốc, còn GANs có thể khó ổn định khi huấn luyện. Dù vậy, cả hai được sử dụng rộng rãi trong công cụ sáng tạo, mô phỏng các tình huống hiếm, và pipeline tăng cường dữ liệu tổng hợp nhằm giảm thiên lệch và cải thiện mô hình hạ nguồn.
Mạng Nơ-ron đồ thị (GNNs)
Mạng nơ-ron đồ thị (GNNs) hoạt động trực tiếp trên cấu trúc đồ thị gồm đỉnh và cạnh, truyền thông điệp dọc theo các kết nối để học mẫu quan hệ. Thế mạnh của GNNs là mô hình hóa mối quan hệ, thay vì chỉ xử lý từng thực thể độc lập, khiến chúng đặc biệt phù hợp cho chuỗi cung ứng, khám phá thuốc, phát hiện gian lận, hệ gợi ý, và tối ưu hóa lộ trình.
Việc mở rộng GNNs lên đồ thị rất lớn là thách thức, thường đòi hỏi batching và lấy mẫu cẩn thận. Dù vậy, khả năng lập luận trên cấu trúc quan hệ giúp GNNs trở thành lựa chọn không thể thiếu trong các lĩnh vực mà kết nối quan trọng không kém dữ liệu đơn lẻ.
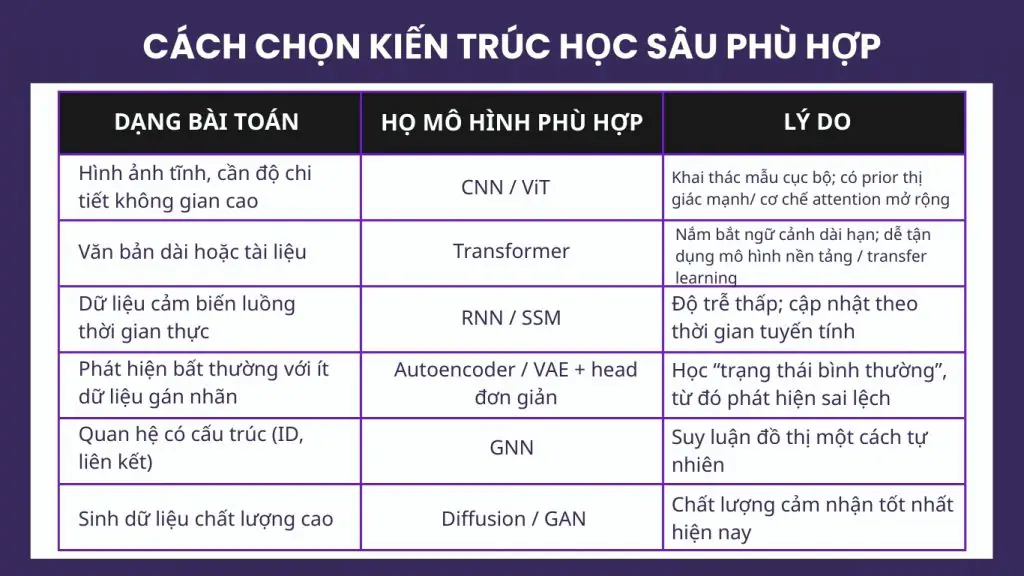
Cách chọn kiến trúc học sâu phù hợp
Các trường hợp ứng dụng học máy trong doanh nghiệp
Một trong những ứng dụng có tác động mạnh mẽ nhất của học máy trong doanh nghiệp là thị giác máy tính (computer vision). Khác với học máy truyền thống dựa trên dữ liệu dạng bảng (hàng và cột), các mô hình thị giác học được mẫu không gian như cạnh, kết cấu, hình dạng – và thường cả tín hiệu theo thời gian như chuyển động hoặc sự liên tục giữa các khung hình video.
Về bản chất, thị giác máy tính mang lại cho phần mềm khả năng “nhìn thấy” – biến các lưới pixel thô thành đặc trưng (features), rồi từ đó tạo ra các dự đoán để hỗ trợ ra quyết định theo thời gian thực. Nhờ vậy, nhà máy có thể phát hiện lỗi khi sản phẩm vừa ra khỏi dây chuyền, nhà bán lẻ có thể tự động giám sát kệ hàng, và doanh nghiệp logistics có thể theo dõi pallet trong kho.
Trong phần tiếp theo, chúng ta sẽ tìm hiểu 5 nhiệm vụ thị giác máy tính phổ biến nhất và cách chúng chuyển hóa thành giá trị kinh doanh thực tiễn.
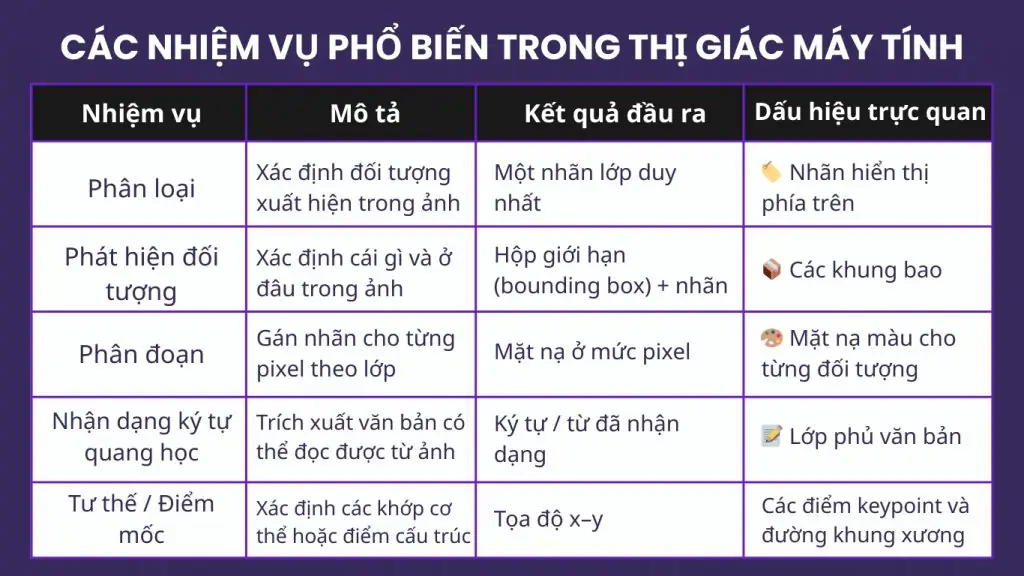
1. Phân oại
Phân loại trả lời câu hỏi: “Trong hình ảnh này có gì?”
Mô hình phân loại dự đoán một nhãn duy nhất hoặc đôi khi là một danh sách các nhãn có xác suất calo nhất cho mỗi hình ảnh hoặc khung hình. Cách tiếp cận này đặc biệt hiệu quả cho các bài toán kiểm tra có/không, cổng kiểm soát chất lượng như đạt/không đạt, hoặc các tác vụ phân loại nhanh ban đầu. Đây là phương pháp đơn giản nhưng hiệu quả để xác định một đối tượng có đáp ứng yêu cầu hay không trước khi xử lý tiếp.
2. Phát hiện đối tượng
Phát hiện đối tượng tiến thêm một bước bằng cách trả lời: “Cái gì và ở đâu?” Thay vì gán một nhãn cho toàn bộ hình ảnh, các mô hình phát hiện xác định từng đối tượng riêng lẻ và vẽ hộp bao (bounding box) xung quanh chúng, kèm theo nhãn lớp. Điều này khiến phát hiện đối tượng trở nên lý tưởng cho các bài toán như đếm linh kiện, xác định vị trí lỗi, hoặc phát hiện nơi các thành phần cụ thể xuất hiện trên dây chuyền sản xuất.
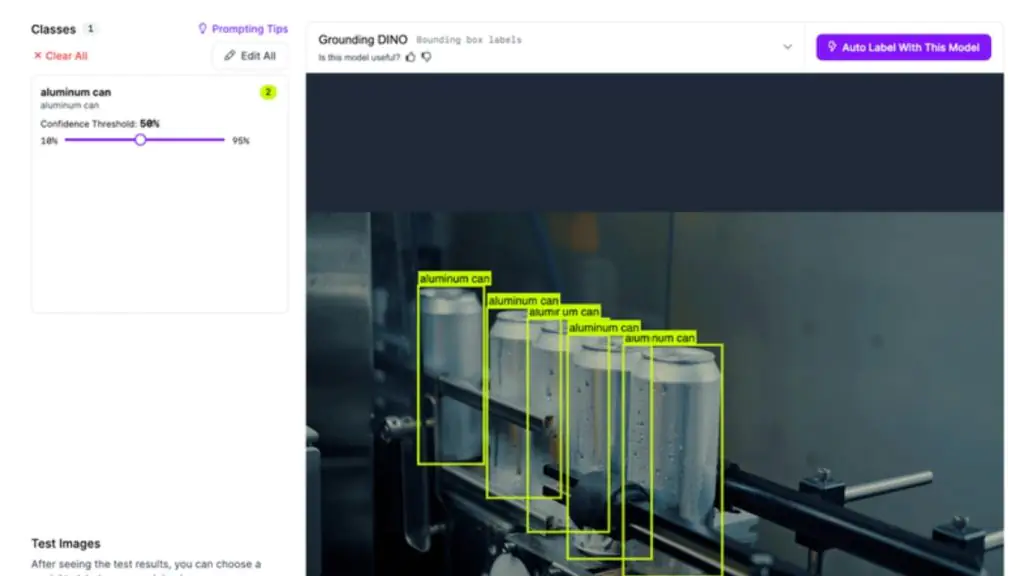
Tự động gán nhãn lon nhôm bằng Auto Label trong Roboflow. (Nguồn: Roboflow)
ALT: Tự động gán nhãn lon nhôm bằng Auto Label trong Roboflow
3. Phân đoạn
Phân đoạn đi sâu hơn nữa bằng cách dự đoán pixel nào thuộc về đối tượng nào. Mô hình trả về các mặt nạ chính xác đến từng pixel, có thể ở cấp lớp (phân đoạn ngữ nghĩa) hoặc cấp đối tượng riêng lẻ (phân đoạn instance). Đây là yếu tố then chốt trong các tình huống mà hình học hoặc diện tích đóng vai trò quan trọng, chẳng hạn như đo độ phủ sơn, phát hiện vết tràn, hoặc tính toán diện tích vùng bị hư hại.
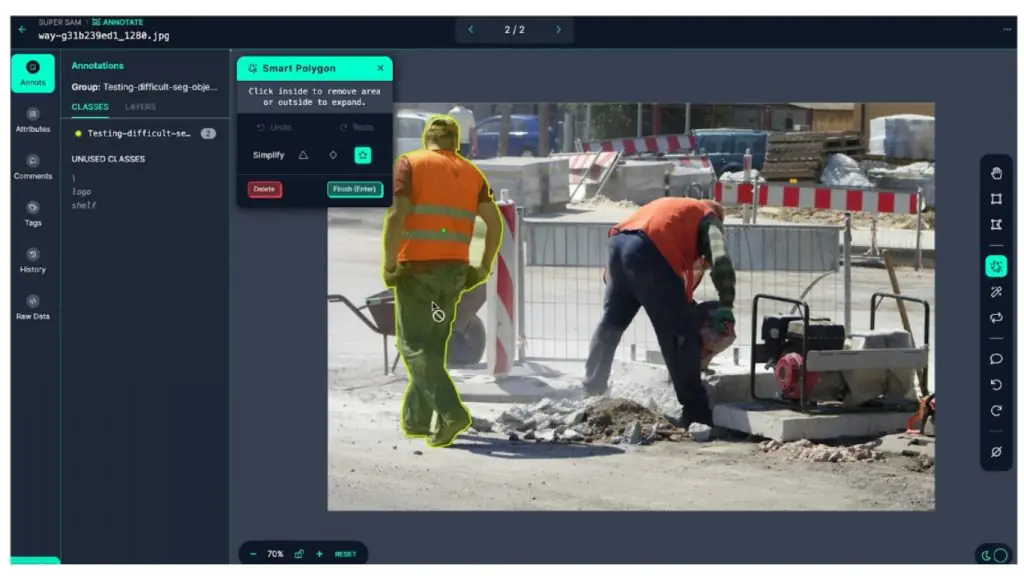
4. Nhận dạng ký tự quang học
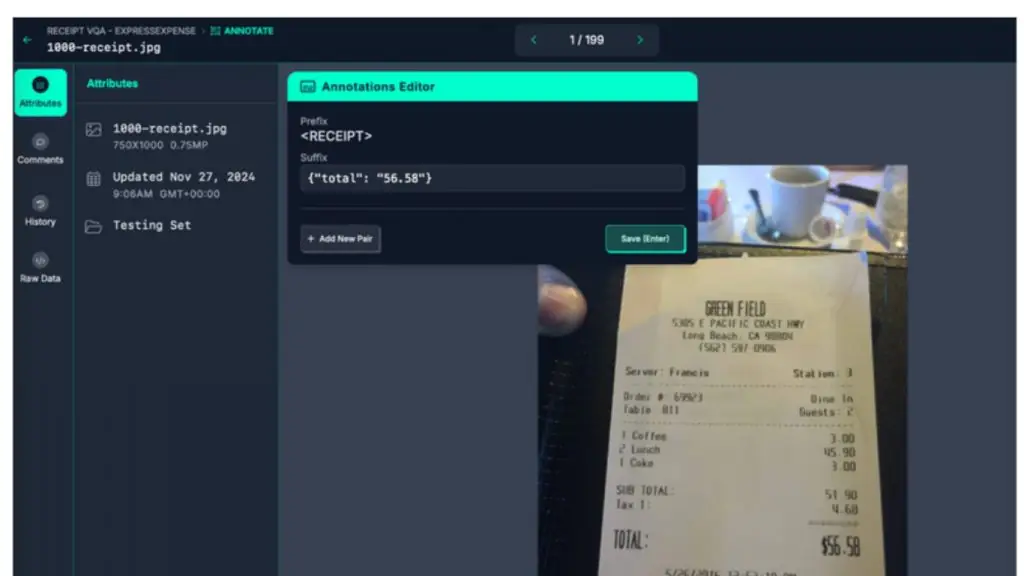
OCR tập trung vào văn bản và trả lời câu hỏi: “Có nội dung chữ gì trong hình?” Các mô hình OCR phát hiện vùng chứa chữ và sau đó chuyển đổi hình ảnh thành ký tự, từ, hoặc dòng văn bản. OCR được ứng dụng rộng rãi để đọc nhãn, vận đơn, giấy tờ tùy thân, mã lô, biển báo, hoặc đồng hồ đo. Với Roboflow, bạn có thể gán nhãn các tập dữ liệu OCR đa phương thức và huấn luyện mô hình xử lý tốt sự đa dạng thực tế về phông chữ, nền và điều kiện ánh sáng.
5. Ước lượng tư thế/điểm mốc
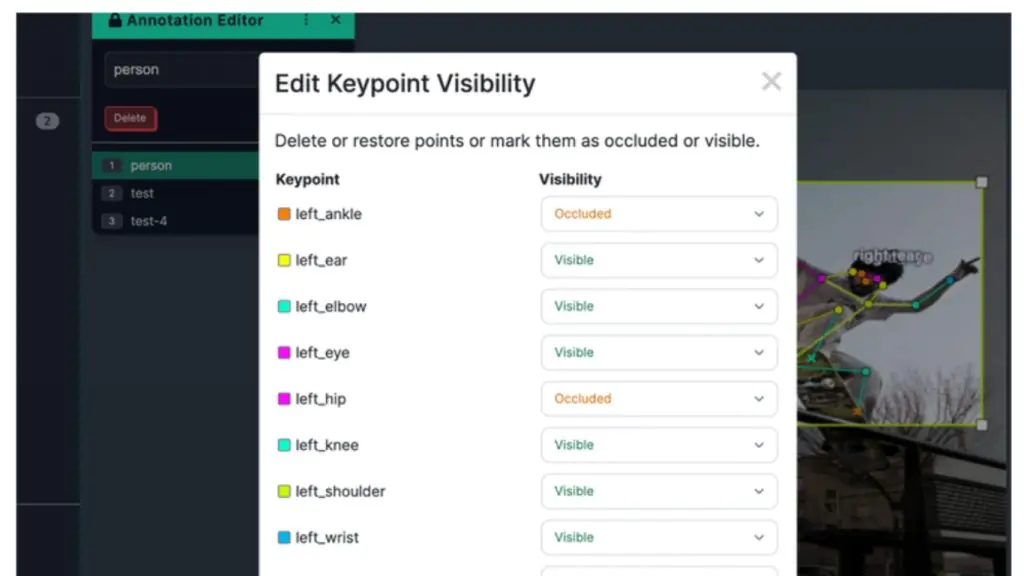
Các mô hình pose và keypoints giúp trả lời câu hỏi: “Các bộ phận hoặc con người đang được căn chỉnh như thế nào?” Thay vì hộp bao hay mặt nạ, chúng dự đoán các điểm mốc cụ thể — ví dụ như khớp cơ thể người hoặc điểm định vị trên thiết bị. Những điểm mốc này cho phép đo tư thế, kiểm tra độ chính xác lắp ráp, hoặc xác minh việc sử dụng đồ bảo hộ lao động. Từ an toàn nơi làm việc đến lắp ráp robot, ước lượng tư thế mang lại góc nhìn chi tiết về cách các đối tượng được định vị trong không gian.
Bạn có thể kết hợp nhiều nhiệm vụ (ví dụ: phát hiện + phân loại + phân đoạn) để xây dựng các quy trình nâng cao hơn như hệ thống an toàn thời gian thực, hiểu tài liệu tự động, hoặc điều hướng robot thông minh.
Dưới đây là một số trường hợp ứng dụng điển hình của học máy trong thị giác máy tính:
- Sản xuất và kiểm soát chất lượng: Phát hiện linh kiện bị thiếu (phát hiện đối tượng – detection), phân loại mức độ lỗi bề mặt (phân đoạn – segmentation), và kiểm tra đạt/không đạt (phân loại – classification).
- Kho bãi và logistics: Đếm pallet/bưu kiện, xác minh nhãn và ký tự bằng OCR (nhận dạng ký tự quang học), và kiểm tra căn chỉnh hàng hóa (ước lượng tư thế/điểm mốc – pose/keypoints).
- Phân tích bán lẻ: Kiểm tra tình trạng hàng trên kệ, đo độ dài hàng chờ , và đánh giá tuân thủ planogram.
- Xây dựng và an toàn lao động: Kiểm tra trang bị bảo hộ cá nhân PPE, phát hiện nguy cơ tại công trường, và cảnh báo xâm nhập khu vực cấm).
- Xử lý tài liệu và nghiệp vụ văn phòng: Hóa đơn, giấy tờ tùy thân và biểu mẫu (OCR kết hợp detection), xác thực dữ liệu trường thông tin (hậu xử lý bằng rule).
Vì sao học máy quan trọng với doanh nghiệp của bạn?
Học máy không còn là một dự án nghiên cứu thử nghiệm. Ngày nay, học máy chính là động cơ tạo ra lợi thế cạnh tranh cho doanh nghiệp trong hầu hết mọi ngành nghề. Machine Learning giúp phần mềm tự học các mẫu dữ liệu và đưa ra quyết định ở quy mô lớn, từ dự báo nhu cầu đến phát hiện lỗi sản xuất.
Khi tìm hiểu cách áp dụng học máy vào doanh nghiệp, thị giác máy tính thường là điểm khởi đầu thực tế và hiệu quả nhất. Vision AI kết nối trực tiếp với hoạt động vận hành cốt lõi: sản phẩm, dây chuyền, tài sản vật lý và chuyển đổi dữ liệu hình ảnh thô thành insight có thể hành động ngay.
Nguồn tham khảo: What Is Machine Learning and Why It Matters Now
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com
🏢 Địa chỉ: 31 Hoàng Diệu, Phường 12, Quận 4, Thành phố Hồ Chí Minh, Việt Nam







