
Object Detection là gì? Object Detection (phát hiện đối tượng) có thể mở ra những khả năng mới cho mọi ngành công nghiệp, đồng thời tạo điều kiện phát triển những ứng dụng mà trước đây chưa thể thực hiện. Điều này xuất phát từ thực tế rằng trong rất nhiều tình huống, việc xác định một vật thể có xuất hiện trong hình ảnh hoặc video hay không là vô cùng hữu ích.
Hãy xem xét một kịch bản trong đó bạn đang xây dựng một hệ thống phân tích thể thao. Nếu bạn có thể phát hiện những gì xuất hiện trong luồng video ghi lại một trận đấu, bạn có thể đếm số lượng cầu thủ trong một khu vực, theo dõi thời gian cầu thủ xuất hiện ở các khu vực khác nhau, và nhiều hơn nữa. Từ đó, bạn có thể phân tích mức độ hiệu quả của các pha bóng, đánh giá hiệu suất của cầu thủ, quan sát và phân tích đối thủ nhanh hơn, cùng với rất nhiều ứng dụng khác.
Dưới đây là một ví dụ về việc sử dụng Object Detection trên một sân bóng đá để phát hiện các cầu thủ:
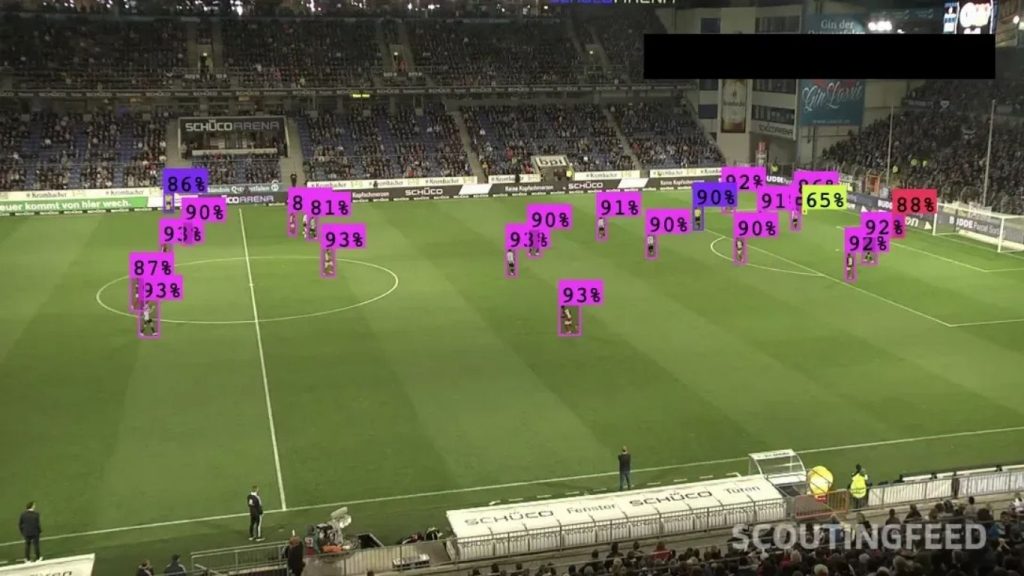
Đây chính là lúc Object Detection phát huy vai trò. Phát hiện đối tượng là một giải pháp thị giác máy tính giúp xác định những gì xuất hiện trong một hình ảnh và vị trí của các đối tượng được phát hiện trong hình ảnh đó. Với phát hiện đối tượng, bạn cũng có thể xác định chính xác vị trí của một vật thể trong hình ảnh, từ đó giúp trả lời các câu hỏi như: “Có người nào xuất hiện trong khu vực bị hạn chế không?” hoặc “Có bộ phận nào xuất hiện ở góc trên cùng của sản phẩm này không?”.
Các trường hợp sử dụng của phát hiện đối tượng rất đa dạng: từ việc xác định lỗi sản phẩm, phát hiện các bất thường trong hình ảnh y tế, nhận diện các vết nứt trên đường ray, cho đến phân tích video để thu thập nhiều thông tin chuyên sâu khác nhau.
Trong hướng dẫn này, chúng ta sẽ thảo luận về Object Detection là gì, cách nó hoạt động, khi nào nên sử dụng và cách phát hiện đối tượng so sánh với các giải pháp thị giác máy tính khác.
Bạn có thể thử một mô hình phát hiện đối tượng với quy trình làm việc sau:
Kéo và thả một hình ảnh mà bạn muốn phát hiện đối tượng. Sau đó, cho biết những đối tượng bạn muốn phát hiện. Chạy quy trình để xem mô hình phát hiện đối tượng hoạt động như thế nào.
Không dài dòng thêm nữa, chúng ta hãy bắt đầu.
>> Tham khảo thêm:
- Các mô hình phát hiện đối tượng trên iOS tốt nhất hiện nay
- Computer Vision Software: Các phần mềm thị giác máy tính miễn phí
- Đếm Đối Tượng Bằng Thị Giác Máy Tính
Object Detection là gì?
Object Detection (còn gọi là phát hiện đối tượng) là một giải pháp thị giác máy tính giúp xác định các đối tượng và vị trí của chúng trong một hình ảnh. Hệ thống phát hiện đối tượng sẽ trả về tọa độ của các đối tượng trong hình ảnh mà nó đã được huấn luyện để nhận diện. Hệ thống cũng sẽ trả về một mức độ tin cậy, thể hiện mức độ chắc chắn của hệ thống về độ chính xác của dự đoán đó.
Hãy cùng xem kết quả từ một mô hình phát hiện sản phẩm:

Trong hình ảnh trên, tất cả các sản phẩm và các khu vực trên kệ không có sản phẩm đều được làm nổi bật bằng các khung hộp. Những khung hộp này là các tọa độ mà hệ thống phát hiện đối tượng (còn gọi là mô hình) cho rằng có đối tượng xuất hiện. Chúng ta gọi các hộp dự đoán này là “hộp giới hạn” trong lĩnh vực thị giác máy tính.
Các con số phần trăm bên cạnh mỗi nhãn cho biết mức độ tin cậy của mô hình đối với tính chính xác của dự đoán. Trong trường hợp này, các nhãn màu vàng cho biết có sản phẩm hiện diện các nhãn màu hồng cho biết có một khoảng trống không có sản phẩm.
Khi bạn đã biết những gì xuất hiện trong một hình ảnh hoặc video, bạn có thể áp dụng các bước xử lý hậu kỳ để rút ra nhiều thông tin giá trị hơn từ dữ liệu hình ảnh. Ví dụ, bạn có thể trả lời các câu hỏi như “Một đối tượng xuất hiện trong video trong bao lâu?” bằng cách sử dụng mô hình thị giác máy tính trên từng khung hình của video và theo dõi thời điểm đối tượng xuất hiện và biến mất.
Bạn cũng có thể trả lời các câu hỏi như:
- Có bao nhiêu đối tượng xuất hiện trong một hình ảnh?
- Một đối tượng xuất hiện bao nhiêu lần trong một hình ảnh?
- Có đối tượng nào xuất hiện trong một khu vực xác định của hình ảnh hoặc video hay không?
>> Tìm hiểu thêm:
- Cách so sánh các mô hình thị giác máy tính một cách trực quan
- 18 cách ứng dụng AI cho ecommerce đạt hiệu quả cao
- Cách tạo chatbot AI bán hàng đa kênh hiệu quả, chi tiết
Cách phát hiện đối tượng hoạt động
Các mô hình phát hiện đối tượng cần được huấn luyện. Điều này đề cập đến một quá trình trong đó một mạng nơ-ron được tạo ra và học các đặc trưng từ hình ảnh. Mạng nơ-ron học các đặc trưng bằng cách được cung cấp nhiều hình ảnh của một đối tượng trong nhiều tình huống khác nhau (ví dụ: nền khác nhau, đối tượng ở các góc độ khác nhau), kèm theo các nhãn tương ứng với đối tượng và vị trí của nó.
Dưới đây là một ví dụ về hình ảnh đã được chú thích cho việc phát hiện đối tượng:

Trong ví dụ này, bạn có thể thấy một hộp tương ứng với vị trí của một đối tượng cụ thể. Hộp này sẽ được sử dụng làm đầu vào cho mạng nơ-ron, cùng với hình ảnh, trong giai đoạn huấn luyện.
Hình ảnh được gán nhãn có thể được thực hiện thủ công, bằng cách sử dụng các nền tảng gán nhãn dữ liệu cho thị giác máy tính có hỗ trợ máy như Roboflow Annotate, hoặc bằng các giải pháp bán tự động như Autodistill. Việc gán nhãn càng chính xác và nhất quán, đồng thời các hình ảnh càng đại diện cho môi trường mà mô hình sẽ được triển khai, thì mô hình sẽ hoạt động càng hiệu quả.
Các đặc trưng này được học và mã hóa trong các “trọng số” (weights) và “độ lệch” (biases), sau đó được lưu lại sau quá trình huấn luyện để sử dụng trong giai đoạn kiểm thử và triển khai thực tế.
Các mô hình có thể học cách nhận diện nhiều đối tượng khác nhau. Tuy nhiên, hầu hết các trường hợp sử dụng trong môi trường sản xuất chỉ yêu cầu nhận diện một vài đối tượng cụ thể. Với Roboflow, bạn có thể đi từ một thư mục hình ảnh đến một mô hình thị giác máy tính được huấn luyện hoàn chỉnh nhanh hơn bao giờ hết.
>>> Xem thêm: Hướng dẫn triển khai AI trong ứng dụng di động đơn giản
Các trường hợp sử dụng phát hiện đối tượng
Phát hiện đối tượng có thể được sử dụng cho bất kỳ bài toán nào mà bạn cần biết liệu một hình ảnh hoặc video có chứa một hoặc nhiều đối tượng cụ thể hay không và các đối tượng đó nằm ở đâu. Bạn cũng có thể sử dụng phát hiện đối tượng khi cần kiểm tra xem một vật thể nào đó có xuất hiện trong hình ảnh hoặc video hay không.
Nhờ tính ứng dụng rộng rãi này, thị giác máy tính đã được áp dụng trong nhiều ngành công nghiệp khác nhau. Hãy cùng điểm qua một vài ngành đang sử dụng phát hiện đối tượng để giải quyết các bài toán thực tế.
Hạ tầng giao thông
Các đơn vị vận hành giao thông có thể sử dụng phát hiện đối tượng để đảm bảo an toàn trên toàn bộ mạng lưới của họ, ví dụ như xác định các chướng ngại vật trên đường ray tàu hỏa hoặc kiểm tra an toàn lao động bằng cách phát hiện xem có người xuất hiện trong khu vực bị hạn chế tại công trường hay không.
Ngành sản xuất thực phẩm
Các nhà sản xuất thực phẩm có thể sử dụng phát hiện đối tượng để phát hiện lỗi và đảm bảo tính toàn vẹn của sản phẩm trước khi được đóng gói và phân phối. Ví dụ, bạn có thể sử dụng thị giác máy tính để đảm bảo rằng đúng loại nắp và bao bì được gắn cho đúng loại sữa chua trong quá trình sản xuất.
Xe tự lái
Trong thập kỷ qua, đã có rất nhiều nghiên cứu nhằm tạo ra những chiếc xe có thể tự lái an toàn. Đằng sau sự đổi mới này chính là thị giác máy tính. Xe tự lái cần có khả năng phát hiện các đối tượng như người đi bộ, đèn giao thông, cọc tiêu giao thông,… để đưa ra quyết định về hành động và lộ trình di chuyển. Các nhà sản xuất ô tô cũng sử dụng phát hiện đối tượng để đảm bảo các bộ phận của mỗi chiếc xe có chất lượng cao và được lắp ráp chính xác.
>> Xem thêm:
- Các nhiệm vụ của thị giác máy tính và cách thực hiện chúng nhanh chóng
- Phân tích hình ảnh bằng AI là gì? Cách AI hiểu và diễn giải hình ảnh
Các mô hình và kiến trúc của phát hiện đối tượng
Trong những năm gần đây, hai kiến trúc phát hiện đối tượng có ảnh hưởng lớn đến lĩnh vực thị giác máy tính là Mạng nơ-ron tích chập (Convolutional Neural Networks – CNNs) và You Only Look Once (YOLO). Cả CNNs và YOLO đều đóng vai trò quan trọng trong việc định hình sự phát triển của thị giác máy tính hiện đại. Bên cạnh đó, các mô hình Transformer cũng ngày càng được ứng dụng rộng rãi trong thị giác máy tính và phát hiện đối tượng.
CNNs học các đặc trưng của hình ảnh thông qua các phép tích chập – một kỹ thuật xử lý hình ảnh trong đó một cửa sổ trượt được áp dụng lần lượt trên từng điểm ảnh. Thông tin thu được từ quá trình này sau đó được đưa vào mạng nơ-ron để tiếp tục xử lý. Hiện nay, CNNs có nhiều biến thể khác nhau, tiêu biểu như R-CNN, Mask R-CNN và Fast R-CNN.
Họ mô hình YOLO có ảnh hưởng rất lớn trong lĩnh vực thị giác máy tính. Được giới thiệu lần đầu vào năm 2014 bởi Joseph Redmon, YOLO vừa là một hướng nghiên cứu và phát triển tích cực, vừa được cộng đồng áp dụng rộng rãi thông qua nhiều triển khai của các nhà phát triển và nhà nghiên cứu. Các phiên bản YOLOv5 và YOLOv8, do đội ngũ Ultralytics phát triển và duy trì, hiện đang được sử dụng để vận hành các mô hình phát hiện đối tượng trong môi trường sản xuất trên phạm vi toàn cầu.
Nếu bạn muốn tìm hiểu sâu hơn về YOLO, có thể tham khảo hướng dẫn đầy đủ về họ mô hình YOLO, trong đó trình bày quá trình phát triển từ những phiên bản kiến trúc đầu tiên cho đến mô hình YOLO11 phổ biến hiện nay.
Trong giai đoạn 2023–2024, các mô hình phát hiện đối tượng theo hướng “zero-shot” ngày càng trở nên nổi bật. Đây là những mô hình có khả năng tiếp nhận một câu lệnh văn bản bất kỳ và xác định các đối tượng liên quan đến câu lệnh đó. Grounding DINO là một trong những ví dụ tiêu biểu. Với Grounding DINO, người dùng có thể cung cấp một mô tả bằng văn bản và hệ thống sẽ xác định các đối tượng tương ứng trong hình ảnh.
Các mô hình zero-shot không yêu cầu tinh chỉnh (fine-tuning) để có thể sử dụng, mặc dù chúng vẫn có thể được tinh chỉnh nhằm đạt hiệu suất cao hơn trong các lĩnh vực hoặc bài toán cụ thể.
Dưới đây là một ví dụ minh họa cách Grounding DINO nhận diện nhiều loại đối tượng khác nhau trong cùng một hình ảnh:

So sánh phát hiện đối tượng với phân loại và phân đoạn hình ảnh
Các mô hình phát hiện đối tượng cho biết hai thông tin cùng lúc: hình ảnh hoặc video có chứa đối tượng hay không, và nếu có thì đối tượng đó nằm ở vị trí nào. Một mô hình phát hiện đối tượng có thể nhận diện nhiều loại đối tượng khác nhau trong cùng một hình ảnh hoặc video.
Điều này trái ngược với phân loại hình ảnh – vốn chỉ có thể gán một nhãn duy nhất đại diện cho hình ảnh. Các mô hình phân loại cho biết hình ảnh thuộc vào một hoặc nhiều danh mục, trong khi các mô hình phát hiện đối tượng có thể cho biết cả nội dung trong hình ảnh và vị trí của từng đối tượng trong hình ảnh.
Trong trường hợp cần xác định vị trí đối tượng chính xác đến từng pixel, phân đoạn hình ảnh là lựa chọn phù hợp. Phân đoạn hình ảnh cũng xác định vị trí của đối tượng trong ảnh, nhưng với mức độ chi tiết cao hơn so với phát hiện đối tượng. Tuy nhiên, độ chính xác này đi kèm một số hạn chế: dữ liệu cần được gán nhãn rất chi tiết và quá trình suy luận (prediction) thường chậm hơn.
>> Tìm hiểu thêm:
- AI nhận diện ảnh là gì? Thuật toán và ứng dụng phổ biến
- Phát hiện đối tượng trong video với RF-DETR
Bắt đầu với phát hiện đối tượng: Mô hình mẫu và các bước thực hiện
Trước khi bắt đầu huấn luyện mô hình của riêng bạn, chúng tôi khuyến khích bạn khám phá các mô hình có sẵn để tự trải nghiệm thị giác máy tính. Dưới đây là một số mô hình bạn có thể thử:
- Football player detection – Phát hiện cầu thủ bóng đá
- Rock paper scissors – Oẳn tù tì (kéo – búa – bao)
- Microsoft COCO (80 objects) – Microsoft COCO (80 đối tượng)
Có nhiều cách tiếp cận khác nhau để bắt đầu với phát hiện đối tượng. Một lộ trình phổ biến là sử dụng các công cụ như Roboflow, giúp bạn làm quen với quy trình xây dựng mô hình phát hiện đối tượng mà không cần viết mã. Nếu bạn có kinh nghiệm lập trình, bạn có thể bắt đầu bằng cách huấn luyện mô hình thị giác máy tính của riêng mình.
Các bước bạn cần thực hiện để tạo mô hình phát hiện đối tượng đầu tiên:
- Bước 1: Xác định đối tượng bạn muốn phát hiện
- Bước 2: Thu thập dữ liệu cho dự án
- Bước 3: Gán nhãn dữ liệu bằng bounding boxes hoặc đa giác
- Bước 4: Huấn luyện mô hình phát hiện đối tượng bằng một mô hình như Ultralytics YOLOv8
- Bước 5: Kiểm thử mô hình.
Roboflow cung cấp nhiều hướng dẫn giúp bạn thực hiện quy trình này một cách thuận tiện. Hướng dẫn dành cho người mới bắt đầu của Roboflow cho phép bạn huấn luyện mô hình phát hiện đối tượng mà không cần viết mã. Bên cạnh đó, các hướng dẫn “Cách đào tạo” của Roboflow, chẳng hạn như “Cách đào tạo YOLOv8”, sẽ hướng dẫn chi tiết từng bước để huấn luyện mô hình thị giác máy tính bằng mã nguồn.
Các hướng dẫn này được kèm theo sổ tay tương tác, tức là các tài liệu chứa mã nguồn kết hợp với phần giải thích bằng văn bản, giúp bạn dễ dàng thực hành và huấn luyện mô hình.
>> Tìm hiểu thêm:
- Top 5 thư viện Python cho thị giác máy tính – So sánh sự khác nhau
- Những trình soạn thảo mã cho thị giác máy tính tốt nhất 2026
Ứng dụng phát hiện đối tượng trong thực tế
Object Detection là một giải pháp thị giác máy tính được sử dụng rộng rãi trên toàn thế giới. Từ việc phát hiện lỗi trên sản phẩm, đảm bảo an toàn tại các công trường xây dựng cho đến việc điều khiển xe tự hành, phát hiện đối tượng có thể hỗ trợ trong nhiều ứng dụng.
Với hệ thống phát hiện đối tượng, bạn có thể xác định những gì có trong hình ảnh hoặc video và vị trí của các đối tượng trong hình ảnh. YOLO và CNN là hai kiến trúc phổ biến nhất được sử dụng cho phát hiện đối tượng, với YOLO – đặc biệt là YOLOv5 và YOLOv8 của Ultralytics – được sử dụng rộng rãi và phổ biến trong ngành công nghiệp.
Các mô hình phát hiện đối tượng học cách nhận diện đối tượng bằng cách được hiển thị các hình ảnh có nhãn tương ứng với vị trí của đối tượng mà bạn muốn nhận diện trong hình ảnh.
Roboflow cung cấp tất cả các công cụ cần thiết để chuyển từ ý tưởng thành mô hình thị giác máy tính được đào tạo đầy đủ. Bạn có thể sử dụng Roboflow Universe để tìm hình ảnh có nhãn để sử dụng trong dự án, Roboflow Annotate để gắn nhãn dữ liệu của riêng bạn, Roboflow Train để đào tạo mô hình và Deploy để triển khai mô hình trên nhiều thiết bị, từ iOS đến GPU NVIDIA.
>>> Nguồn tham khảo: What Is Object Detection? How It Works and Why It Matters
TOT là đơn vị tiên phong trong hành trình chuyển đổi số. Chúng tôi mang đến giải pháp thiết kế website, mobile app và viết phần mềm theo yêu cầu với dịch vụ linh hoạt, tối ưu theo đúng nhu cầu của doanh nghiệp.
Lấy cảm hứng từ triết lý “Công nghệ vì con người”, TOT giúp doanh nghiệp vận hành hiệu quả hơn, nâng tầm trải nghiệm khách hàng và tạo dấu ấn bền vững cho thương hiệu.
Thông tin liên hệ TopOnTech (TOT):
📞 Hotline/WhatsApp/Zalo: 0906 712 137
✉️ Email: long.bui@toponseek.com🏢 Địa chỉ:31 Đường Hoàng Diệu, Phường Xóm Chiếu, TP. Hồ Chí Minh, Việt Nam







